Redis Data Integration
This is the first General Availability version of Redis Data Integration (RDI).
RDI's purpose is to help Redis customers sync Redis Enterprise with live data from their slow disk based databases in order to:
- Meet the required speed and scale of read queries and provide an excellent and predictable user experience.
- Save resources and time when building pipelines and coding data transformations.
- Reduce the total cost of ownership by saving money on expensive database read replicas.
RDI currently supports two scenarios:
-
Ingest scenario: RDI mirrors the application's primary database to Redis using a change data capture (CDC) tool. RDI transforms the database model and types to a Redis model and types. This scenario is useful when the application database is not performant and scalable enough to serve the read queries. RDI helps you offload all read queries to Redis.
Note:Ingest is supported with Redis database or CRDB (Active Active Replication) targets.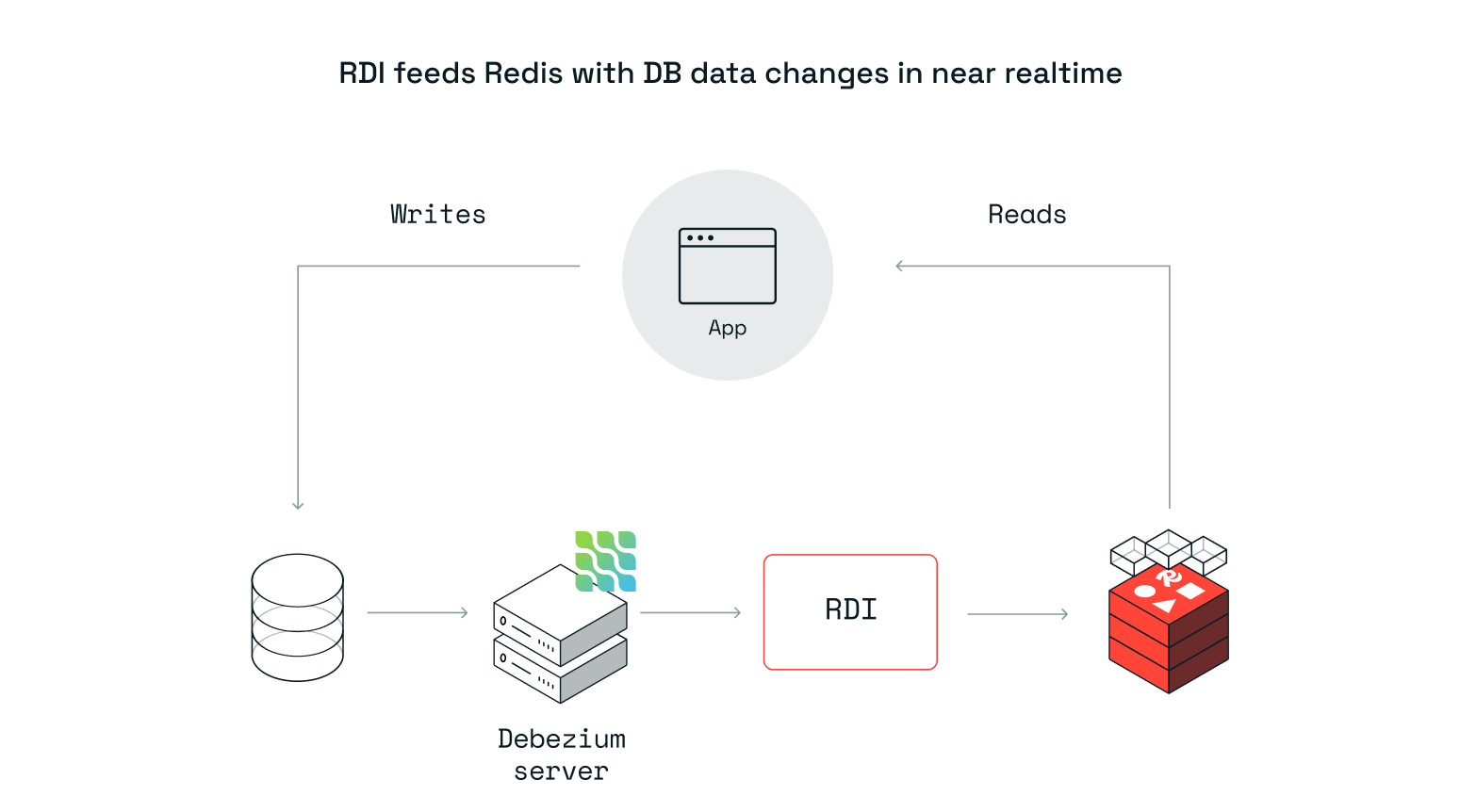
-
Write-behind scenario (Preview): RDI applies data changes in Redis to one or more downstream data stores. RDI can map and transform Redis types and models to downstream types and models. This scenario is useful when the application needs fast writes and reads for some of the queries, but has to provide data to other downstream services that need them in different models for other uses.
Note:Write-behind is not supported with CRDB (Active Active Replication)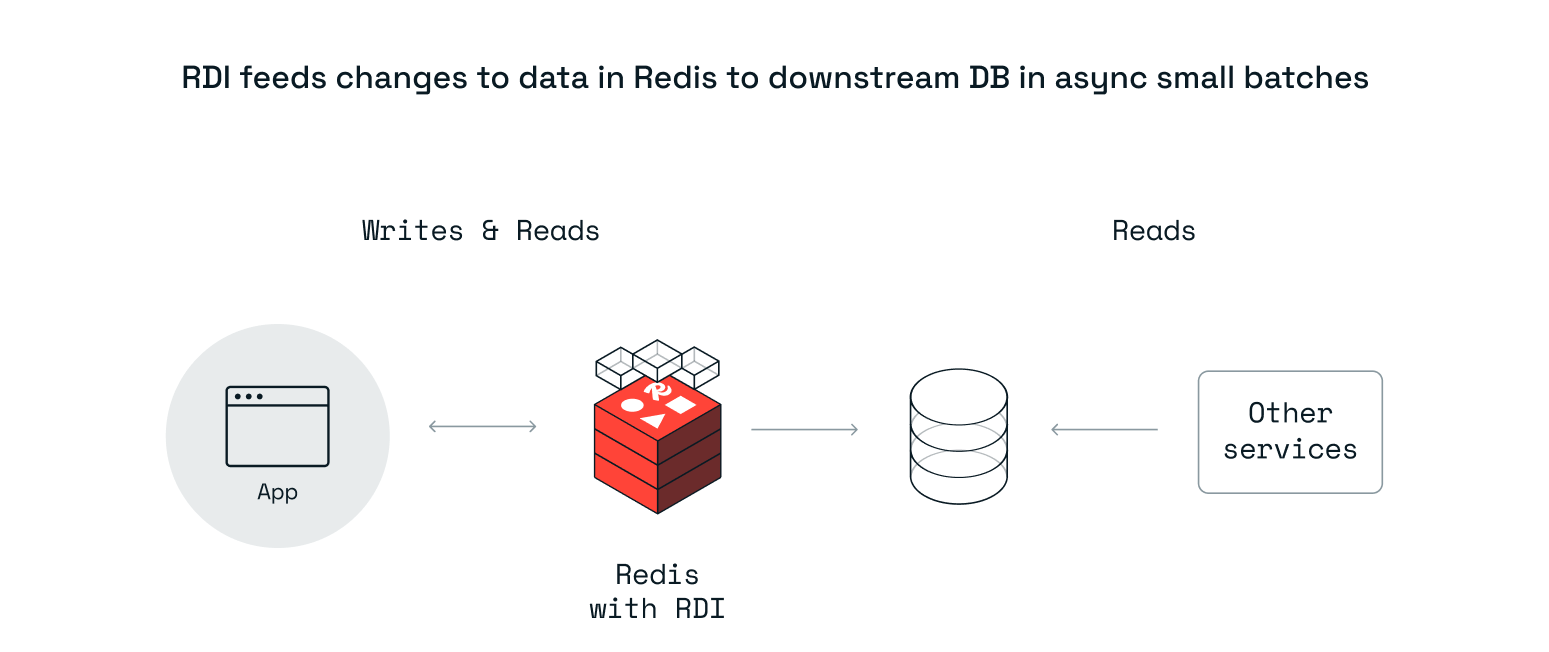
See the Ingest architecture guide and the Write-behind architecture guide for more information.
Supported sources (ingest)
RDI supports the following database sources using Debezium Server connectors:
| Database | Versions |
|---|---|
| Oracle | 12c, 19c, 21c |
| MariaDB | >= 10.5 |
| MySQL | 5.7, 8.0.x |
| Postgres | 10, 11, 12, 13, 14, 15 |
| SQL Server | 2017, 2019 |
| Google Cloud SQL MySQL | 8.0 |
| Google Cloud SQL Postgres | 15 |
| Google Cloud SQL SQL Server | 2019 |
| Google Cloud AlloyDB for PostgreSQL |
Supported targets (write-behind)
| Database |
|---|
| Oracle |
| MariaDB |
| MySQL |
| Postgres |
| SQL Server |
| Cassandra |
Features
RDI is an enterprise-grade product with an extensive set of features.
Performance and scalability
- Up to two seconds from source to target
- Multi-shard support (each shard supports 28K ops/sec)
Resiliency, high availability, and data delivery guarantees
- At least once guarantee, end to end
- Data in transit is replicated to replica a shard
- Data persistence (see Redis AOF)
- A back-pressure mechanism that prevents cascading failures
- Reconnect on failure and write retries
Developer tools and data transformation
- Declarative data filtering, mapping, and transformations
- Support for SQL and JMESPath expressions in transformations
- Additional JMESPath custom functions, simplifying transformation expressions
- Transformation jobs validation
- Zero downtime pipeline reconfiguration
- Hard failures routing to dead-letter queue stream for troubleshooting
- Trace tool
Operator tools and lifecycle management
- CLI with built-in help and validations
- Installation using CLI
- Zero downtime upgrade of RDI
- Status tool for health and data provenance
- Monitoring using Prometheus and Grafana