Blog
Bee-Queue: a Redis-based distributed queue
Original post by Eli Skeggs (eli@mixmax.com)
We’re excited to announce the v1.0 release of Bee-Queue: a fast, lightweight, robust Redis-backed job queue for Node.js. With the help of Bee-Queue’s original author, Lewis Ellis, we revived the project to make it the fastest and most robust Redis-based distributed queue in the Node ecosystem. Mixmax is using Bee-Queue in production to process tens of millions of jobs each day.
Bee-Queue is meant to power a distributed worker pool and was built with short, real-time jobs in mind. Scaling is as simple as running more workers, and Bee-Queue even has a useful interactive dashboard that we use to visually monitor job processing.
Here is how Bee-Queue v1.0 compares to other Redis-based job queues in the Node ecosystem (including its own prior v0.x release):
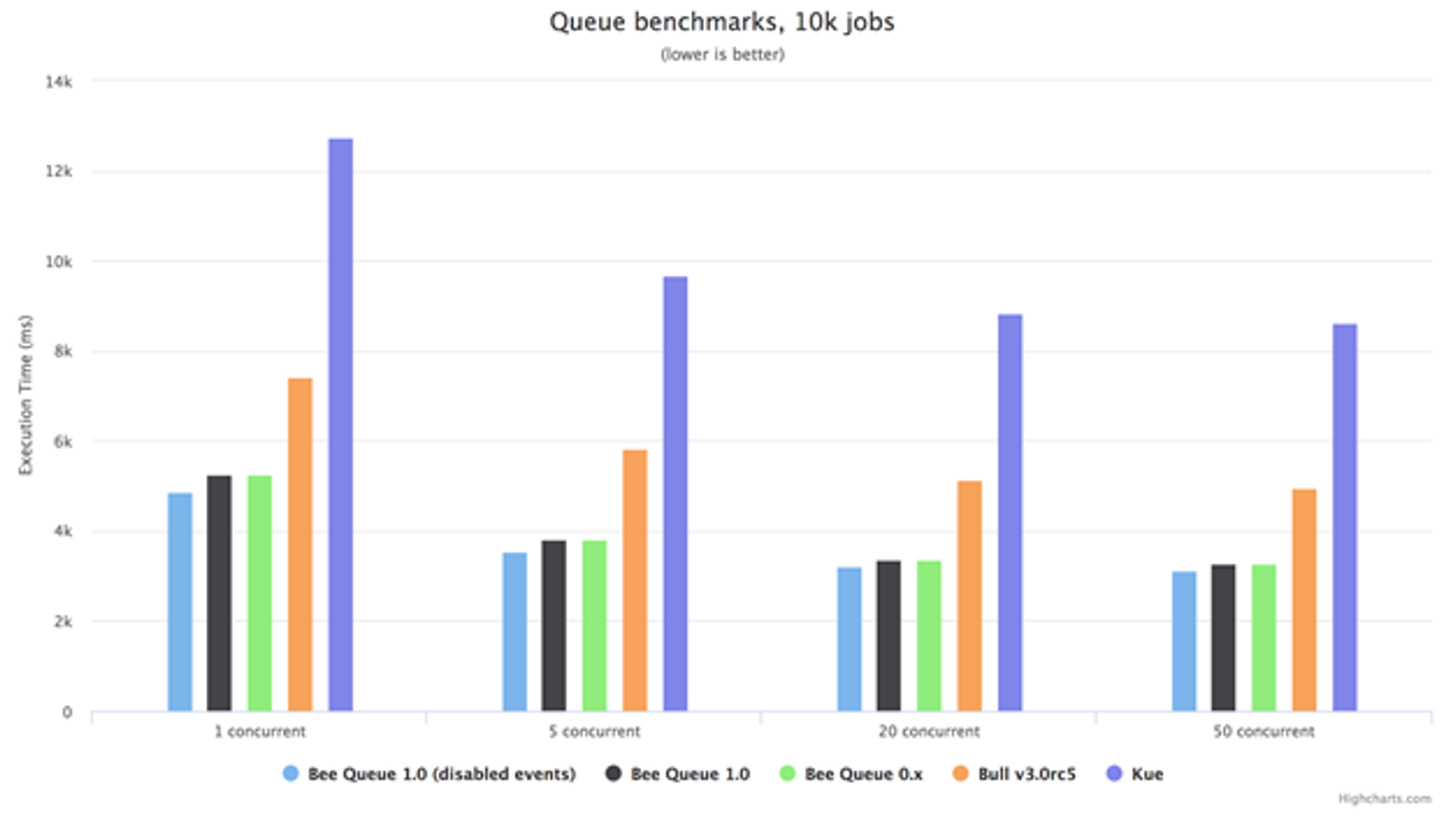
Why Bee-Queue?
So, why another job queue in the Node.js ecosystem? Up until now, Mixmax had been using a similar queue, Bull. Bull served us well for a year, but there was a race condition that resulted in some jobs being double processed, causing major problems at scale. That race condition was fixed in Bull v3, but unfortunately v3 also experienced a significant performance regression over v2. We were faced with the decision to move entirely to a different queue such as RabbitMQ or start over and write our own simple high-performance Redis-based queue.
Why Redis?
We decided to stick with Redis over other messaging frameworks (such as RabbitMQ) because of how easy it is to work with and how much performance we could get for a low cost. With Redis, we can easily scale our Redis cluster to meet our ever-growing demand, now at a tens of million of jobs an hour. Redis also gives us the benefit of keeping our traffic inside our network VPC – a core security requirement for all our sensitive data. We’re big fans of Redis at Mixmax so everyone on the team has experience working with it.
With this in mind, we decided to pursue building our own lightweight queue based on Redis that did only what we needed it to, in order to make performance a priority. Before starting the project from scratch, we rediscovered Bee-Queue, having first seen it a couple years ago. We evaluated its codebase again and quickly realized that it’d be a great platform to build upon. Building on an existing queue saved us weeks of implementation time; we refreshed the codebase, identified the missing features we needed, and added those with the help of the original author, Lewis.
Successful launch
We released Bee-Queue v1.0 this week and have switched over to using it entirely instead of Bull. All our production traffic is now flowing over Bee-Queue and we haven’t seen any problems. Resource usage has declined dramatically, measured by lower Node.js and requiring few Redis resources. We were also able to repurpose existing tooling from our Bull days to work with Bee-Queue. Building up Bee-Queue to serve our needs ended up taking the least amount of time, since we didn’t need to rewrite any application code or even change our existing monitoring infrastructure, which was already built to sit on top of Redis.
Bee-Queue is now hosted in a new Github organization that we co-maintain with Lewis. We encourage you to check it out and contribute, or if you’re looking for a more fully-featured queue, check out Bull. Our goal with Bee-Queue is to keep it small with performance and stability being the top priorities.
If you’re a fan of Redis and enjoy working on problems like these, come work with us! mixmax.com/careers
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.