Be the first to see our latest product releases—virtually—at Redis Released: Worldwide.
Be the first to see our latest product releases—virtually—at Redis Released: Worldwide.
Register now
Be the first to see our latest product releases—virtually—at Redis Released: Worldwide.
Register now
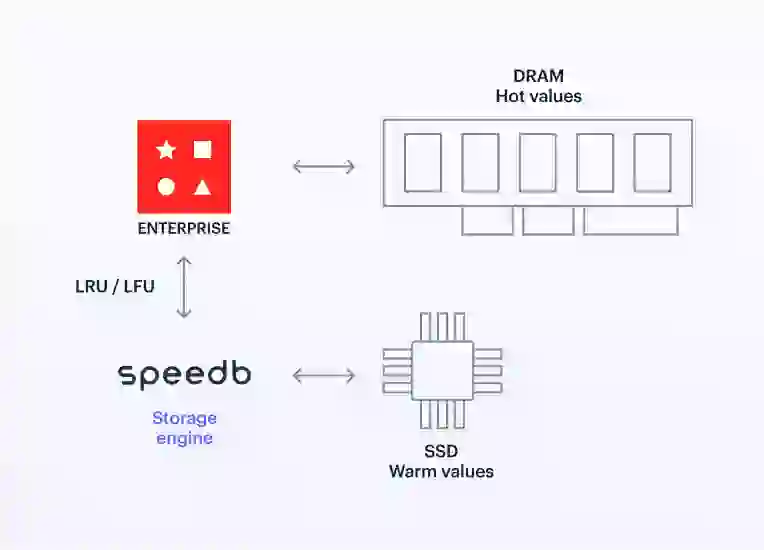
Redis uses DRAM to store data as long as it fits in the available memory. But DRAM is finite and expensive; those limitations present a barrier to developing and operating applications that rely on large datasets, such as fraud detection, user profile management and cybersecurity.
Redis Enterprise’s auto tiering lets you use solid state drives (SSDs) to extend databases beyond DRAM capacity, so you can build applications that require large datasets using the same Redis API. Using SSDs can reduce infrastructure costs by up to 70% compared to only DRAM deployments.
Redis Enterprise’s auto tiering is based on a high-performance storage engine (Speedb) that manages the complexity of using SSDs and DRAM as the total available memory for databases in a Redis Enterprise cluster. This implementation offers a performance boost of up to 10K operations per second per core of the database, doubling the performance of Redis on Flash.


Application data has its own life cycle. Frequently used data, called hot data, belongs in the fastest memory level to deliver a real-time user experience. Data that is accessed less frequently, called warm data, can be kept in a slightly slower memory tier.
In most applications, only a portion of the whole dataset is hot data. A large percentage is on standby for when it is needed. However, moving data between tiers is hard. Auto tiering maintains hot data in DRAM, keeps warm data in SSDs, and transfers data between tiers automatically. By combining the flexibility of Redis with SSDs’ large capacity, we enhance Redis Enterprise’s real-time data management capabilities. End result: Your applications achieve more and run faster, even when they call upon vast data collections.
Auto tiering is particularly beneficial when you must provide high-speed data processing over a large volume of data. Maintaining all the data in DRAM can be costly, particularly if you deal with both hot and warm data.
To distinguish between the two: The data generated by active customers who make frequent purchases generally is considered hot data. In contrast, dormant users–existing customers who have not logged in for a while but could show up anytime–count as warm data. You want to keep their data around somewhere, but it’s okay if it takes a little extra time to retrieve it.
Conditions can rapidly change, such as when a prior user returns to make a new purchase. Regardless of the change, an enterprise application must respond with speed and agility.
In such circumstances, auto tiering automatically adjusts the working set. It moves the required data into DRAM for real-time processing and evicts unused data into SSDs for later use.
Redis Enterprise’s auto tiering allows developers to adjust the DRAM-to-SSD ratio without changing the database’s memory quota. This maintains an optimum storage space to keep hot or active datasets in memory and the warm data in SSD to maintain a lower total cost of ownership (TCO), because DRAM and SSDs have significant cost differences.
When a dataset is large, and the cost of in-memory storage becomes cumbersome, you can configure SSD space for the data that is accessed less frequently. That helps you keep an adequate ratio of DRAM (for throughput and reduced latency) and SSD storage (for warm extended datasets and optimum TCO). Conversely, when an application requires more performance, better throughput, or reduced latency, you can add more DRAM to keep more hot data in the working dataset.

Start today for free with Redis Cloud

Download Redis Enterprise