Blog
How to build a language processing pipeline using AI with Redis
Confirmation bias is a problem that all medical professionals have to wrestle with. Not being able to consider different ideas that challenge pre-existing views blights their ability to entertain a new diagnosis in the face of an established one.
This is a problem rooted in medical literature, where professionals are more likely to lean towards articles that support their pre-existing views. Diversity of opinion is crucial to moulding a holistic perspective capable of delivering effective diagnoses.
In response, a language processing machine learning pipeline was created by this Launchpad App to weed out confirmation bias in medical literature. Using Redis, the Launchpad App created a pipeline that was able to translate text into a knowledge graph through the efficient transmission of data.
Let’s investigate how the team was able to achieve this. But before we dive in, make sure to check out all of the different and innovative apps we have on the Launchpad.
- What will you build?
- What will you need?
- Architecture
- Getting Started
- Navigating the Redis Knowledge Graph site
- Conclusion
1. What will you build?
Let’s explore how you can build a pipeline for Natural Language Processing (NLP) using Redis.
We’ll reveal how Redis was used to bring this idea to life by highlighting each of the components used as well as unpacking their functionality.
2. What will you need?
- Python 3.6: robust, powerful and fast programming language
- Redis Streams: manages data consumption from cord-19 and transmits data to RedisGears
- RedisGears: pre-processes existing articles from cord-19
- RedisGraph:stores information that’s processed from RedisGears
- RedisAI: carries out deep learning/machine learning models to manage data in RedisGears
- Cord-19: is a growing resource of scientific papers on Covid-19 and related historical coronavirus research. It’s designed to enhance the development of text mining and information retrieval systems over its in-depth collection of metadata and structured full-text papers.
3. Architecture
NLP Pipeline 1: Turning Text into a Knowledge Graph
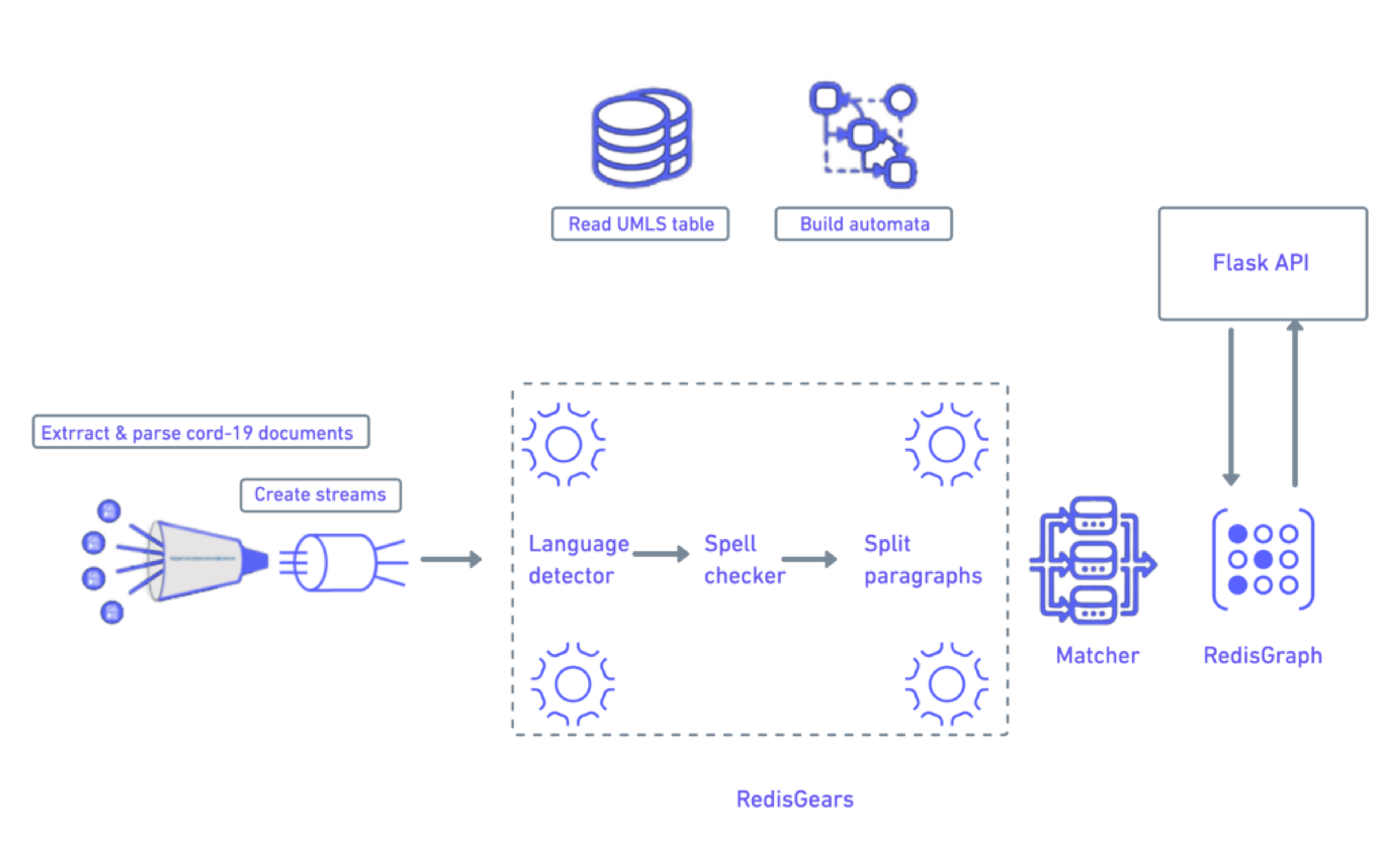
From start to finish, Redis is the data fabric of this pipeline. Its function is to turn text into a knowledge graph. Let’s have a quick overview of what a knowledge graph is and its function in this project.
What is a knowledge graph?
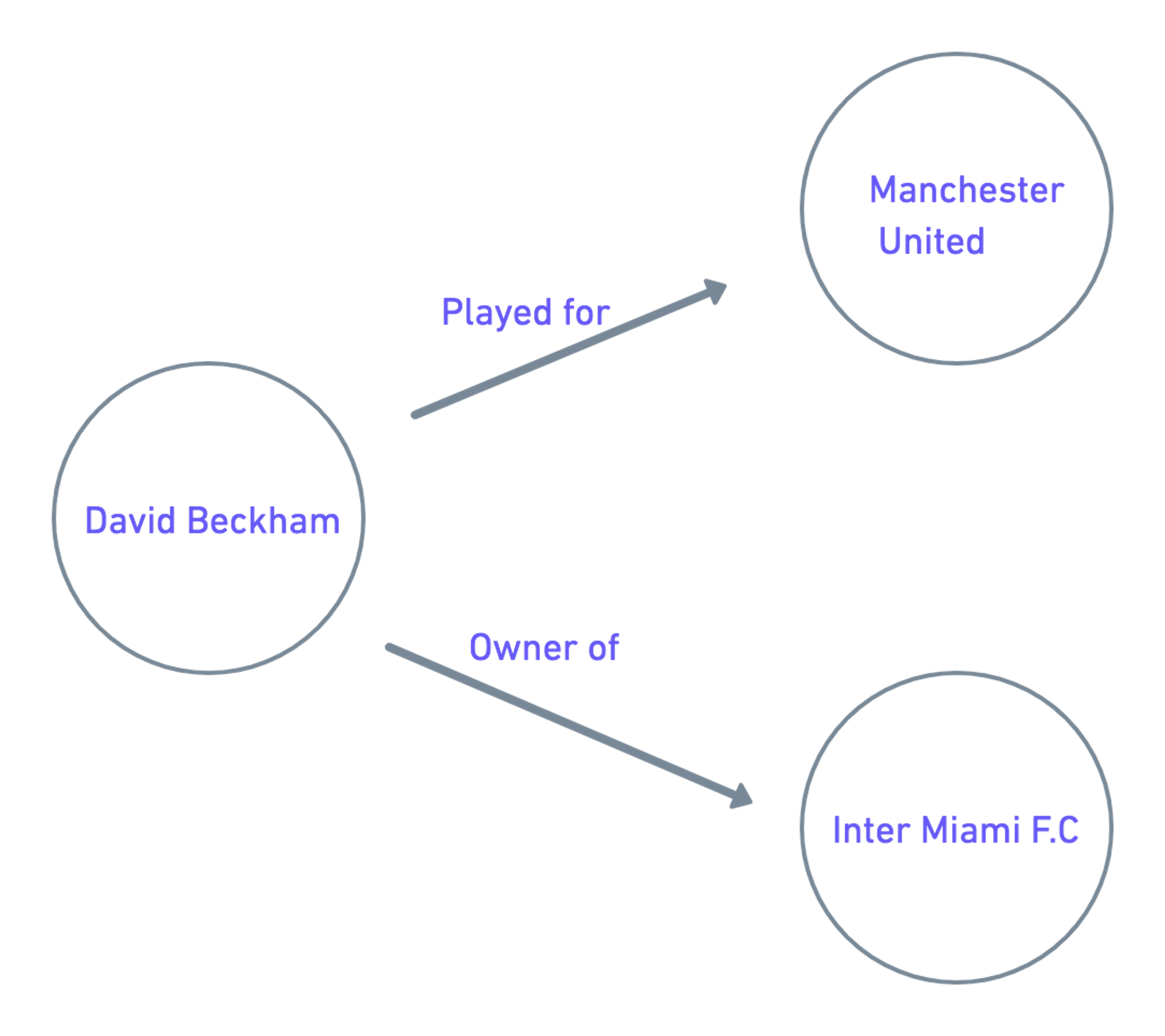
Systems today go beyond storing folders, files and web pages. Instead, they’re cobwebs of complexity that are composed of entities, such as objects, situations or concepts. A knowledge graph will highlight each of their properties along with the relationship between them. This information is usually stored in a graph database and visualized as a graph structure.
What are the components of a knowledge graph?
A knowledge graph is made up of 2 main components:
- Nodes: represents an object, place, person or concept
- Edges: defines the relationship between nodes
Below is an example of how nodes and edges are used to integrate data.
How it works
- Ingest documents: Cord-19 documents are parsed and taken out of body_text. These are then saved under paragraphs in Redis Cluster.
- Detect language: RedisGears registers key readings from the text and discards any of the medical literature that’s not in English.
- Split paragraphs into sentences: paragraphs are then mapped into a sentence.
- Spell checker: symspell library and its map are used to process outputs and save them into hash.
- Matcher: pre-build Aho-Corasick automata is then used to match incoming words to medical concepts using UMLS Methathesaurus
- Populate RedisGraph: matched sentences are then loaded into edges RedisGraph with Nodes being Concept (CUI)
- Front-end repository: sourcecode for this project and upcoming VR/AR
- Flask API server: Just simple Flask API server to query RedisGraph
In the first pipeline, you’ll discover how to create the knowledge graph for medical literature by using a medical dictionary. This processes information using RedisGears and stores it in RedisGraph.
First, use the below code to unzip and parse metadata.zip, where names of files, titles and years are extracted into HASH:
The following code works by reading JSON files – samples in the data/sample_folder: the-pattern-platform/RedisIntakeRedisClusterSample.py
It also parses JSON into String:
And the following code is the main pre-processing task that uses RedisGears: the-pattern-platform/gears_pipeline_sentence_register.py
It also listens to updates on paragraphs: key:
This uses RedisGears and HSET/SADD.
How to turn sentences into edges (Sentence) and nodes(Concepts) using the Aho-Corasick algorithm
The first step is to use the following code:
The next line of code will create a stream on each shard:
Below is to increase the sentence score:
How to populate RedisGraph from RedisGears
the-pattern-platform/edges_to_graph_streamed.py works by creating nodes, edges in RedisGraph, or updating their ranking:
How to query RedisGraph data during API calls
the-pattern-api/graphsearch/graph_search.py
Edges with years node ids, limits and years:
Nodes:
Next use the following code to find the most scored articles:
Using the most humorous code in the pipeline
Show the below code to your security architect:
This is necessary because RedisGears doesn’t support the submission of projects or modules.
NLP pipeline 2: BERT QA
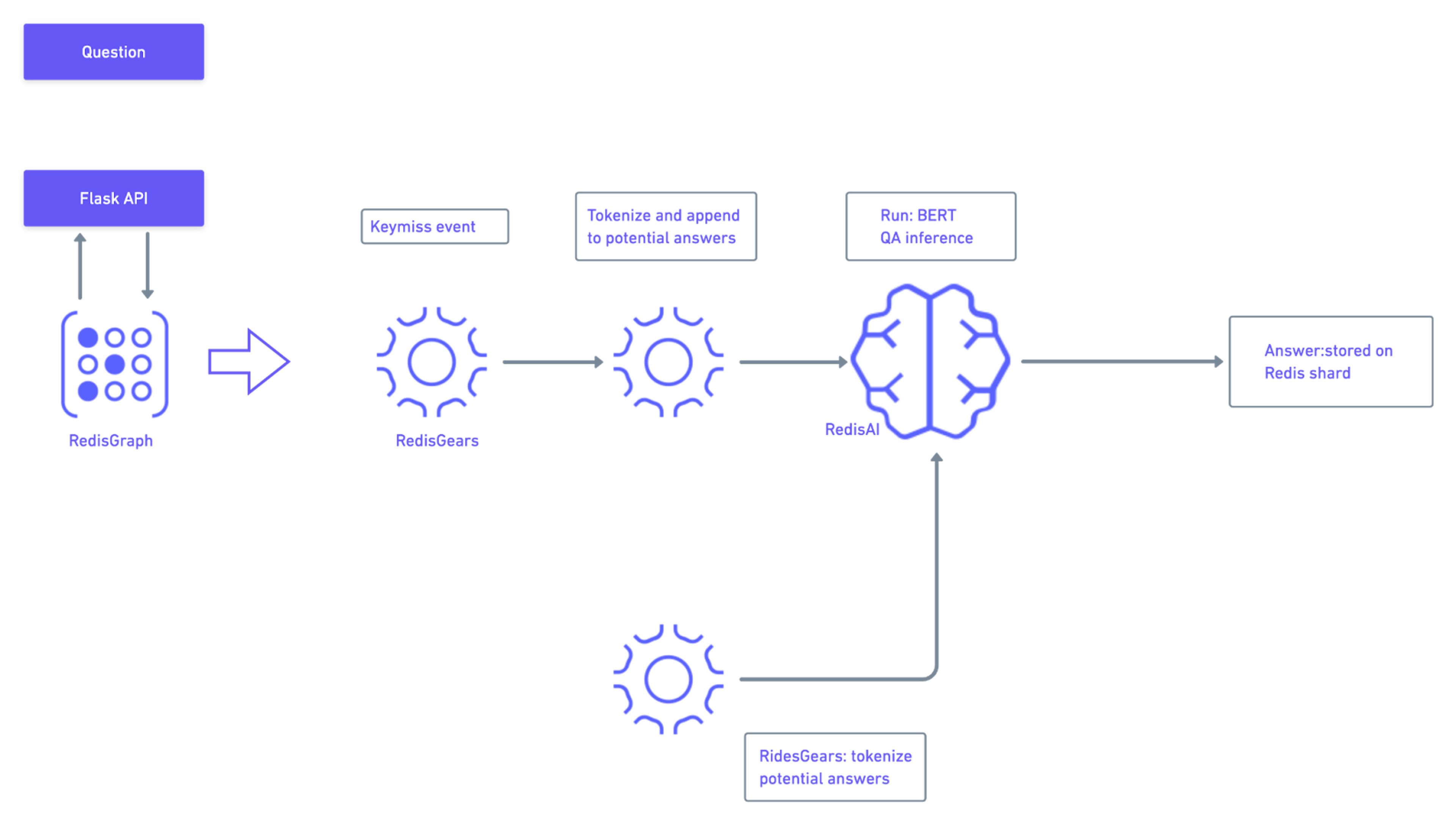
BERT stands for Bidirectional Encoder Representations from Transformers. It was created by researchers at Google AI and is a world leader in processing national language tasks, including Question Answering (SQuAD v1.1.), Natural Language Inference (MNLI) and others.
Below are some popular use cases of the BERT model:
- Next sentence prediction text: this happens when your Gmail autocompletes your sentences.
- Text summarization: provides concise yet meaningful summaries of lengthy articles.
- Question answering: automatically answers questions by users in a natural language
- Text classification: categorizes text into organized groups to make content easier to access and understand.
The most advanced code is in the-pattern-api/qasearch/qa_bert.py. This queries the RedisGears + RedisAI cluster, providing users with a question:
This queries bertqa prefix on shard {5MP} wherePMC140314.xml:{5M5}:44 (see below)is the key of pre-tokenized REDIS AI Tensor (potential answer) and “When air samples collected?” is the question from the user.
RedisGears then captures the keymiss event the-pattern-api/qasearch/qa_redisai_gear_map_keymiss_np.py:
RedisGears then runs the following:
- redisAI.getTensorFromKey
- redisAI.createModelRunner
- redisAI.createTensorFromBlob
- redisAI.modelRunnerAddInput
- redisAI.modelRunnerRunAsync in async/await
For the non-blocking main thread mode, models are preloaded on each shard using AI.modelset in the-pattern-api/qasearch/export_load_bert.py.
NLP Pipeline 3: T5 for Summarization
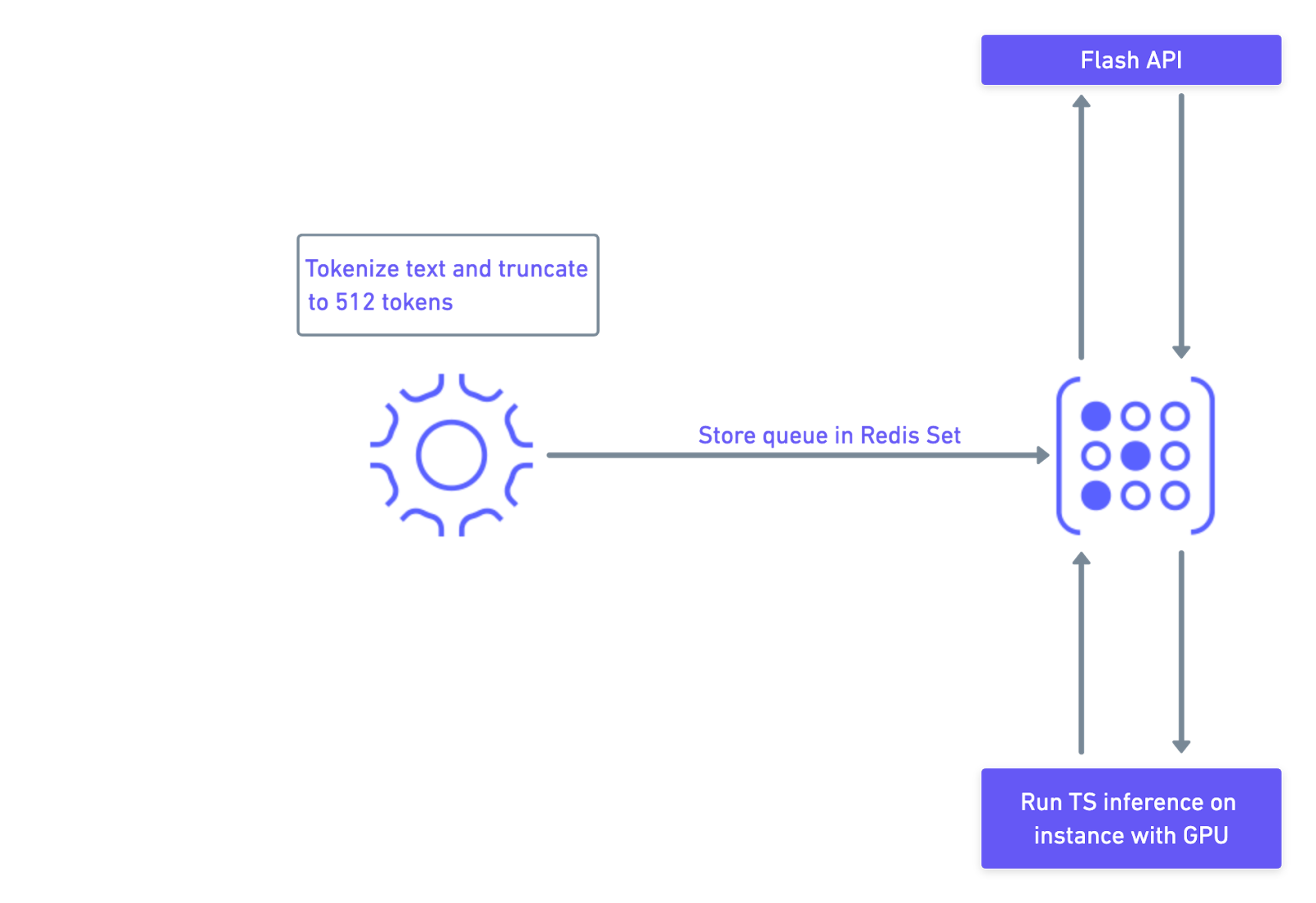
Summarization works by running on sentence: prefix and running t5-base transformers tokenizer, saving results in RedisGraph using simple SET command and python.pickle module, adding summary key (derived from article_id) into:
The following subscribes to queue running simple SET and SREM commands:
This will then update hash in RedisGraph:
4. Getting started
Redis provides rgcluster Docker image as well as redis-cluster script. It’s important to make sure that the cluster is deployed in high availability configuration. Each master has to have at least one replica. This is because masters will have to be restarted when you deploy your machine learning models.
If masters is restarted, and there isn’t a replica, then the cluster will become a failed state and you’ll have to manually recreate it.
Other parameters include execution time and memory. Dirt models are 1.4 GB in memory and that’s where you’re required to include proto buffer memory. You also need to increase execution time for both cluster and gears chart because all tasks are computationally extensive, so you need to make sure that the time-outs are accommodated for.
Step 1. Prerequisite
Make sure that you install virtualenv in your system, Docker and Docker compose.
Step 2. Clone the repository
Wait for a bit and then check the following:
RedisGraph has been populated:
Whether if the API responds
Step 3: Start the UI
Step 4. Question Answering API
Note: this will download and pre-load 1.4 GB BERT QA model on each shard. Because of its size, there’s a chance that it might crash on a laptop. Validate by running:
Step 5: Summarizing the pipeline
Go to the repository on RedisGears cluster from “the-pattern” repo:
This task may time out, but you can safely re-run everything.
On the GPU or server, configure NVidia drivers:
Configure access from instance to RedisGraph docker image (or use Redis Enterprise)
Walkthrough
While RedisGears allows you to deploy and run machine learning libraries like spacy and BERT transformers, the solution below adopts a simpler approach:
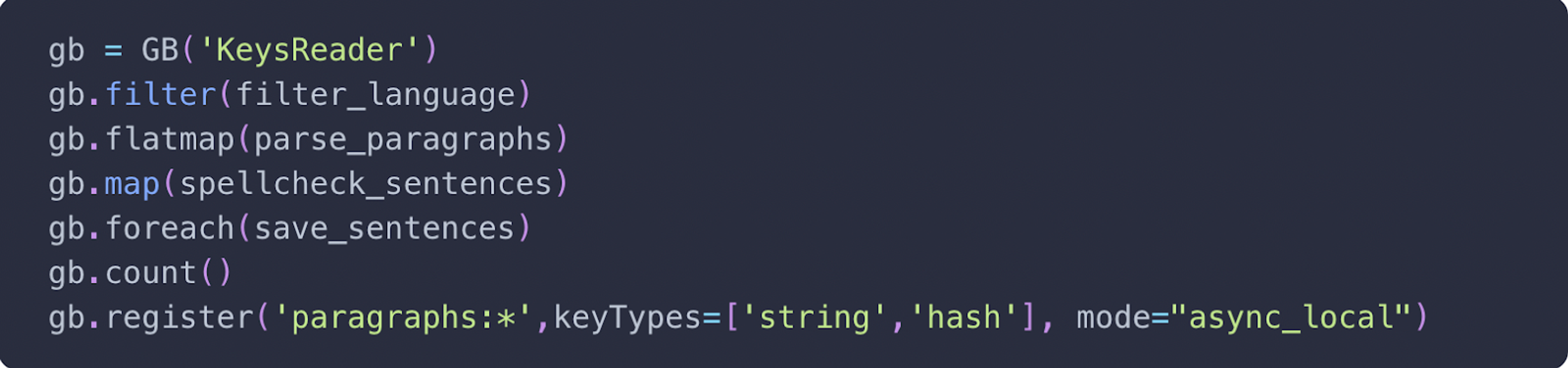
Here’s a quick overview of the overall pipeline: The above 7 lines allow you to run logic either in a distributed cluster or on a single machine using all available CPUs. As a side note, no changes are required until you need to scale over more than 1000 nodes.
Use KeysReader registered for namespace paragraphs for all strings or hashes. Your pipeline will need to run in async mode. If you’re a data scientist, we would recommend using gb.run to help ensure that RedisGears works and that it will run in batch mode. It will then run in batch mode. Afterwards, change it to register to capture new data.
By default, functions will return to output, hence the need for count () – to prevent fetching the whole dataset back to the command issuing machine (90 GB for Cord19).
Overall, pre-processing is a straightforward process. You can access the full code here.
Important things to keep in mind
- The node process can only save locally. We don’t move data, anything you want to save should have a hashtag. For example, to add to the set of processed_docs, use the following:

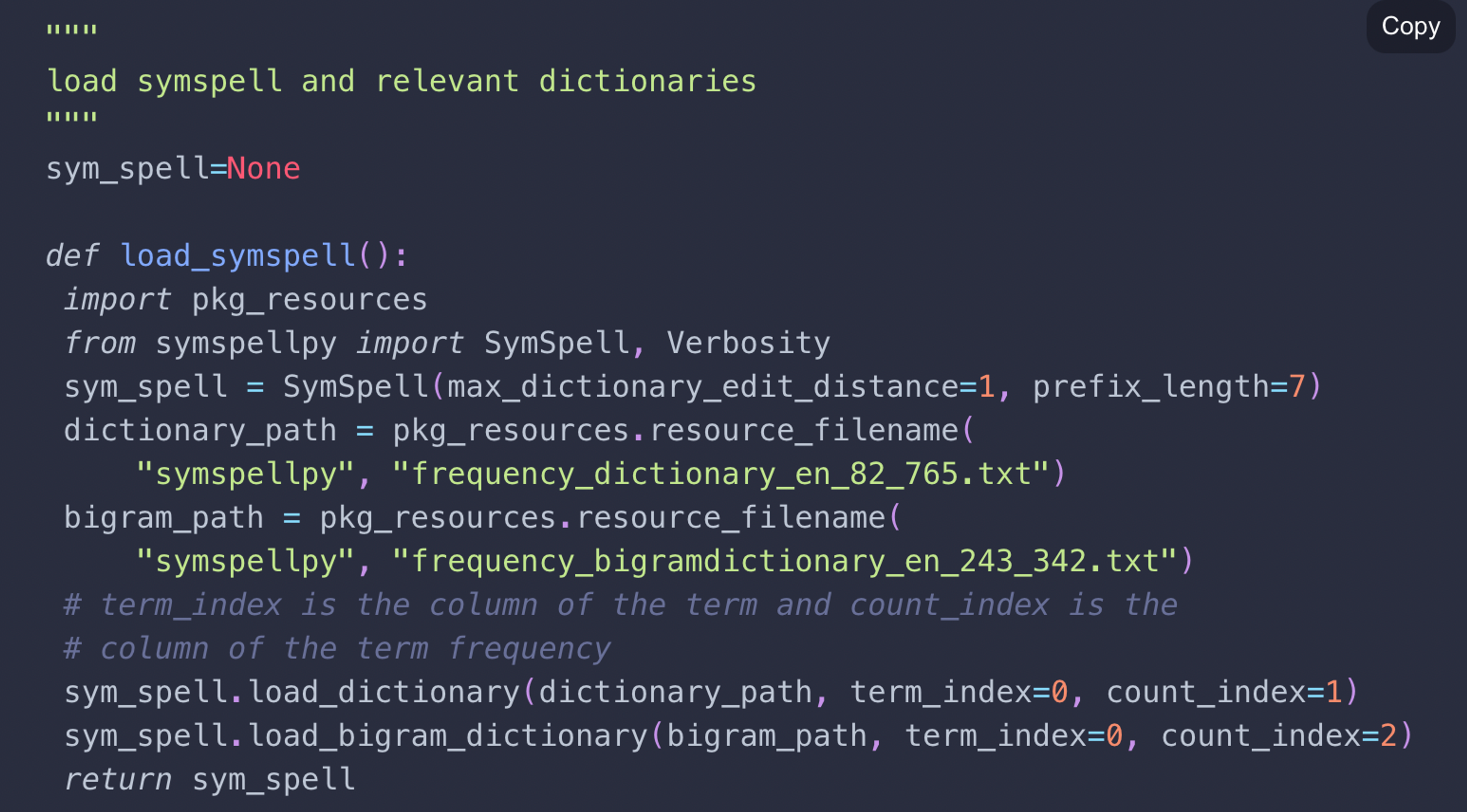
- Make sure to load external libraries into the computational threat. For example, symspell requires additional dictionaries and needs two steps to load:
You can build Aho-Corasick automata directly from UMLS data. Aho-Corasick will allow you to match incoming sentences into pairs of nodes, and present sentences as edges in a graph. The Gears related code is simple:
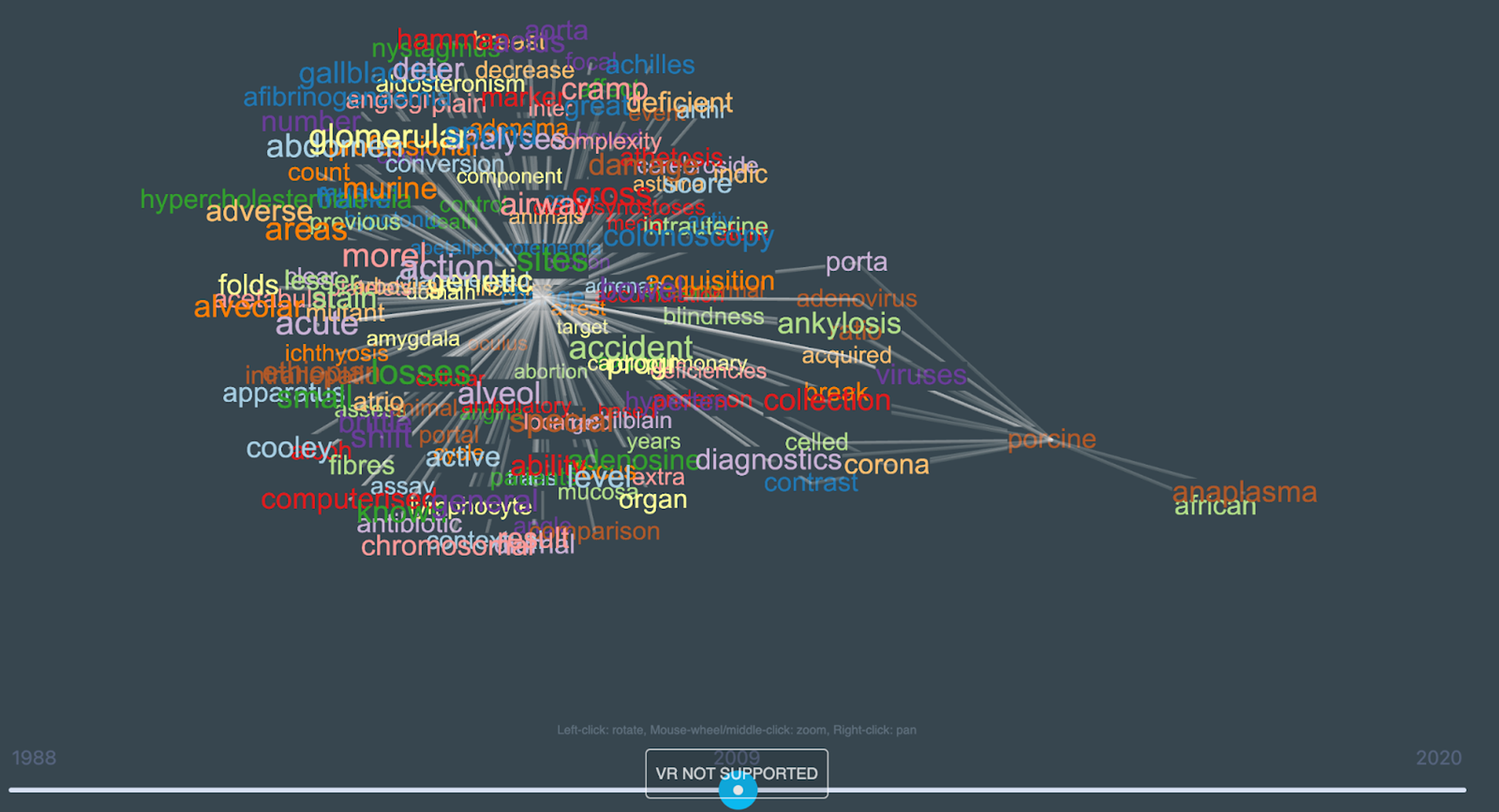
5. Navigating the Redis Knowledge Graph site
The Redis Knowledge Graph is designed to create knowledge graphs based on long and detailed queries.
Preliminary step: Select ‘Get Started’ and choose either ‘Nurse’ or ‘Medical student.”
Step 1: Type in your query into the search bar
Step 2: Select the query that’s most relevant to your search
Step 3: Browse between the different nodes and change the dates of your search with toggle bar at the bottom
Conclusion: Eliminating confirmation bias with Redis
Using Redis, the Launchpad App created a pipeline which helps medical professionals navigate through medical literature without suffering from confirmation bias. The tightly integrated Redis system promoted a seamless transmission of data between components, giving birth to a knowledge graph for medical professionals to utilize.
You can discover more about the ins and outs of this innovative application by visiting the Redis Launchpad. When you’re there, you might also want to browse around our exciting range of applications that we have available.
You can head over to the Launchpad to discover more about the application along with many others in our exciting collections of apps.

Who created this application?
Alexander Mikhalev

Alexander is a passionate researcher and developer who’s always ready to dive into new technologies and develop ‘new things.’
Make sure to visit his GitHub page to see all of the latest projects he’s been involved in.
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.