Blog
The Redis Labs Experience at Spark Summit East, February 2017

As Gold sponsors of this year’s Spark Summit East, the team from Redis was excited to spend time in one our country’s oldest cities, Boston. Flying out from our headquarters in sunny Mountain View, CA, we had no idea what we were in for. The diversion mid-flight to Chicago for a medical emergency should have been a sign that this would be an interesting journey.
Spark Summit Day One went off without a hitch. With just under 2,000 attendees, the conference and expo areas where filled with Spark developers anxious to network and learn.
Along with our partner, Databricks, the Redis team stayed busy with prospects and customers demonstrating how Databrick’s cloud-based Spark workspace integrates with Redise Cloud. This integration enables Databricks users to serve Spark processes and SQL queries with Redise Cloud while allowing RediseCloud users to instantly run analytics processing using Databricks’ cloud-based Spark clusters. (see diagram below)
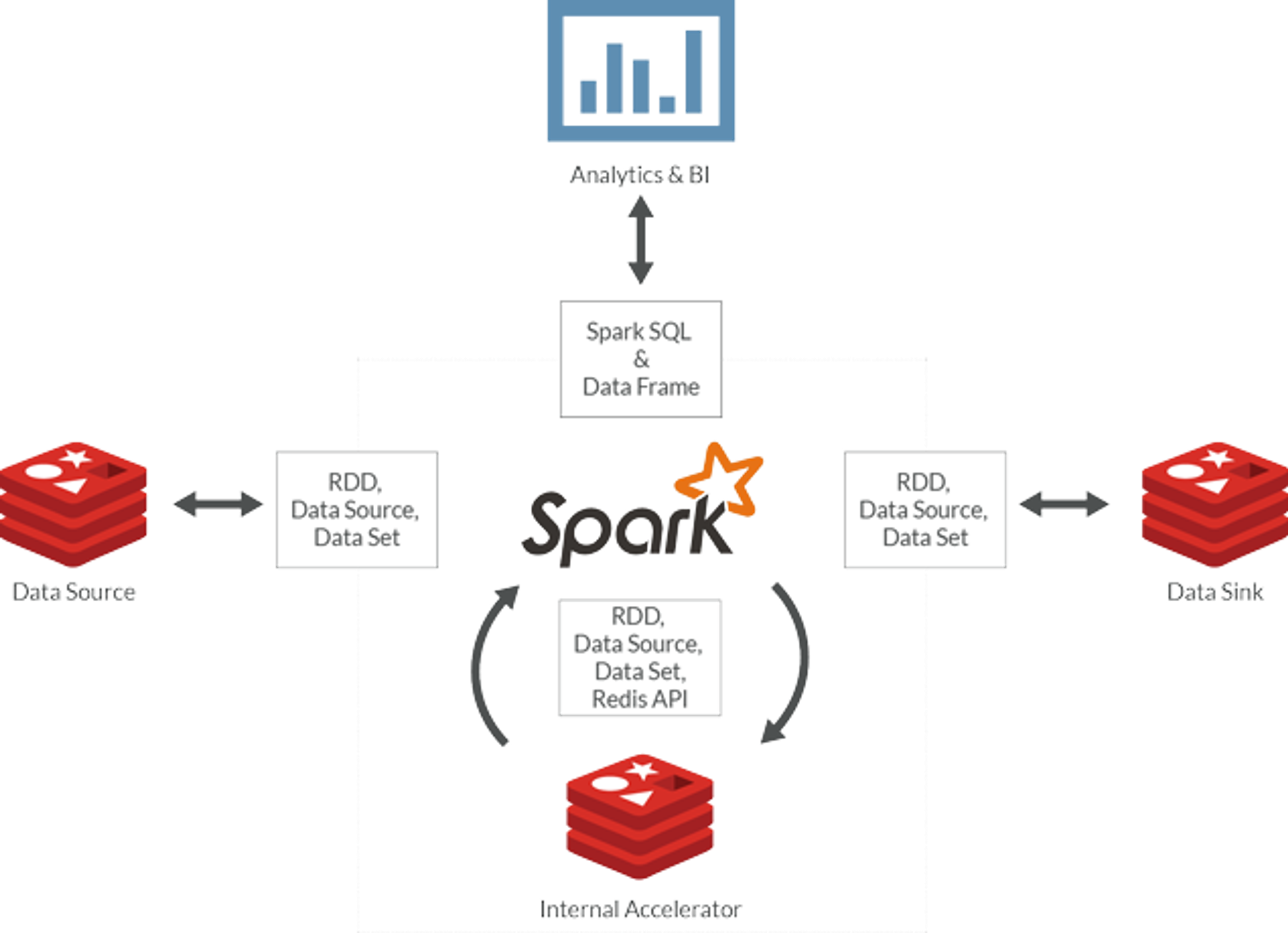
Joint customers benefit from being able to access the power of Spark integrated with the real-time high performance of Redis. Analytics can shift from being post-facto to inline and instantaneous with the combination of these two powerful big data engines.
We also showed off our Redis-ml module which includes native datatypes for storing and serving machine learning models generated by frameworks such as Apache Spark. As companies make machine learning an integral part of their business, Redis and Redis-ml play a critical role in production implementations.
Day One of Spark Summit wrapped up with an energetic cocktail reception in the Expo Hall. The Redis northeast sales team headed out to dinner with customers, and the partner team ventured out to experience one of Boston’s many great restaurants with another Redis’ partner, Accenture. And while the weather on Wednesday felt cold to us Californians, the locals said 50 degrees was down right balmy for February.
Enter a blizzard. A little snow never hurt anyone. Around 6:00 am on Thursday, I was awakened by strong winds and snow pounding against my window on the 9th floor of the Back Bay Hilton. By mid-afternoon, we were in the middle of a powerful blizzard that brought several feet of new snow up and down the coast.

Fortunately, the Hilton is right across the street from the Hynes Convention Center so we only had to venture a few hundred feet outside. Surprisingly, Day Two of the Summit was only slightly less busy than Day One.
Our team remained busy throughout Day Two of the summit. The Redis staff was excited to walk several Fortune 500 prospects through the impressive results of the latest Redis-Spark Time Series benchmark. This Redis’ benchmark using time-series data shows that running Spark on Redis as a data store results in 135 times faster processing compared to Spark using HDFS, and 45 times faster processing compared to Spark using Tachyon as an off-heap data store or Spark storing the data on-heap.
Day Two ended with another evening of superb dinners with prospects. A few of us decided to brave the weather, jump on the subway, and head over to TD Garden to see our San Jose Sharks take on the Boston Bruins. After a quick stop at Four’s Sports Bar, we found ourselves in the Garden, admiring all of the championship banners hanging from the rafters. The hockey game did not turn out well for the Sharks in the end, but we had a great time and made some new friends along the way.

By Friday morning, the sun was back out and we headed off to the airport. Fortunately, the folks at Logan International are some of the best in the world in dealing with snow and ice, and our flights back to SFO departed safely, and on-time.
Thanks to all of the great folks at Databricks for organizing a fantastic event. We are already looking forward to RedisConf 2017 in May, and Spark Summit in June – both in San Francisco. And safe to say, there is no snow in the forecast.
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.