
The 7th principle, as laid out in the Redis Manifesto, really aligns with my beliefs and views, and probably those of all engineers (regardless of experience). There’s little in this world as satisfying as that rush of excitement you get from devising a clever way to do something new and/or better. This joyous rush, in turn, can and often does lead to developing a serious addiction, as recognized by Donald Knuth (“premature optimization is the root of all evil”) and Randall Munroe (e.g. http://xkcd.com/1205/, http://xkcd.com/1445/ and http://xkcd.com/1319/) long ago.
I found out, however, that by exercising common sense and cold logic every time I get an urge to embark on an optimization quest, I can keep my addiction satisfied and controlled. This post is about three such urges from the a past week.
Optimizing by Sharing Knowledge
As an advocate for Open Source Software and a decent netizen at large, I strive to assist others in everything Redis-related. Sure, Redis can be used a dumb key-value store but it is so much more that it practically begs to be used intelligently.
So it was during my daily patrolling of the internets that I came across this SO question and started to answer it. In my reply, I deliberately left out the details on how one would go about scanning a big list – the OP appeared to be a beginner and I didn’t think he’d grok it – but I still got that tingle of joy because I had helped someone do something better. Hopefully, I’d also encouraged him to learn and understand the commands he was using before diving into coding (and perhaps I also saved the world some CPU and network resources along the way).
Optimizing by Exploration
While that SO question by itself isn’t something to write home about — or blog about (although I just did) — it got me thinking about that missing LSCAN command. There’s SCAN for scanning the keyspace, HSCAN for Hashes, SSCAN for Sets and ZSCAN for Sorted Sets but nothing for Lists. Since Redis’ Lists (and Quicklists) are regular lists (or linked lists of ziplists), randomly accessing their elements is done in O(N) complexity. Having an efficient LSCAN command means implementing Redis Lists differently, and since there are no free lunches there is a price to pay. Lists are good (i.e. O(1)) for pops and pushes, and given principles #3 (“Fundamental data structures for a fundamental API”) and #5 (“We’re against complexity”) of the Manifesto, if you’re using a List and need to scan it from one end to another, then you probably shouldn’t have used a List in the first place.
But, for the sake of argument and just for giggles, can you somehow do what LSCAN would do (had it been there in the first place)? Interesting question… well, sure you can. For starters, if you’re not worried about consistency due to concurrency, you can easily use a loop with RPOPLPUSH and keep a count to traverse the list more efficiently. Of course, if concurrency is a concern, you’ll probably need to find some way to duplicate the list and traverse the copy safely.
So how does one go about duplicating a list with 10 million elements? Lets first create such a list (all testing done in a VM on a laptop so YMMV):
A fast copy will need to be done on the server, so the naive way to copy the list would be to write a Lua script that will pop elements one by one and push them back to the original and the destination. I wrote such a script and tested it on that longish list…
It took forever to run and yielded the expected “Lua slow script detected” message in the log:
23 seconds is way too long, and while you could batch some of the calls to LPUSH, maybe LRANGE is a better approach:
11 seconds is much better than 23, but how about SORTing it – would that be faster? Probably, lets check it out:
An impressive improvement – only 2.248 seconds and about 10 times faster than popping and pushing, but can we do even better? Lemme check if Redis has any COPY, DUPLICATE or CLONE commands… Nope, the closest that there is is MIGRATE, but it only accepts a single key name. But wait! [lightbulb] What about DUMP and its complementary RESTORE… could it be?
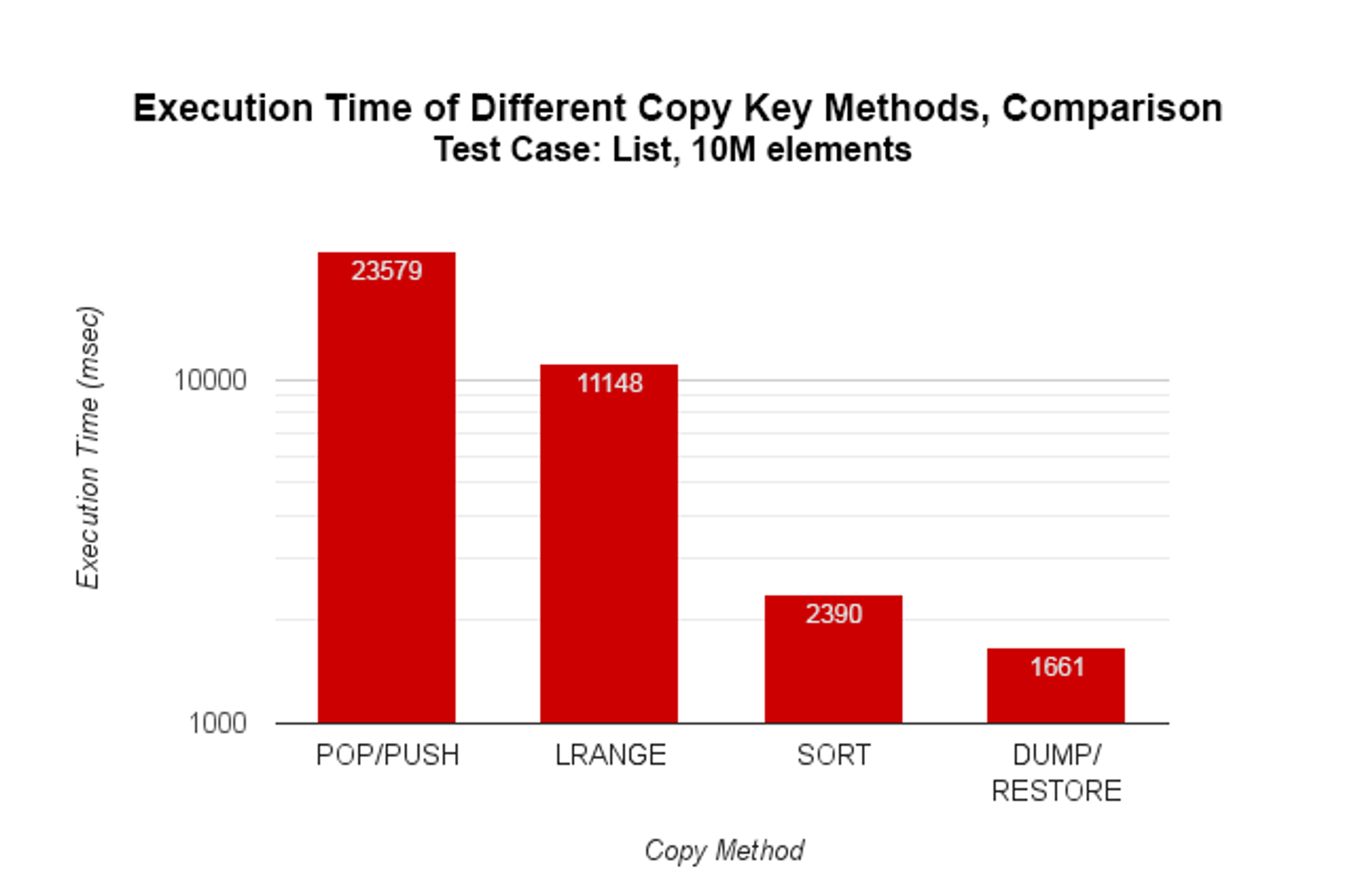
That’s a really nice trick – copying by dumping and restoring is much faster because you bypass all of the data structure’s management logic (sort of like good ol’ POKE in BASIC, and the furthest you can go until pointers to values are introduced to Redis :P). It is almost 20-times better than the naive approach and in theory it should work for any data type – Lists, Hashes, Sets and Sorted Sets. I’ll have to remember this little hack for when I need to copy values quickly.
Optimizing by Hacking
But hold on! There’s even something nastier I can think of – how about making Redis go faster than Redis? What if someone wrote a piece of code that could spew out Redis-compatible value serializations, like DUMP does? With that functionality, you could load data to Redis really really really fast. Short of trying to write directly to Redis process’ memory space, this approach could potentially outperform any conventional RESP-based client by moving some of Redis’ load to the client itself. Exciting!
I know of at least one such code, so now I’m really tempted to have a look at DUMP‘s implementation [insert link] and see if I can rip it out and port it, lets say for a Hashmap. Then I could test loading JSONs by preprocessing and injecting their final serializations directly instead of using HMSET. The possibilities are really endless, but so is the amount of effort needed to make it happen. And even that works and is relatively bug-free (yeah, right), I’ll be relying on Redis’ internal private API, so the potential for breakage is huge. And those concerns aside, it just feels wrong. Perhaps a better direction is to embed Redis in the client app and implement Master<->Master replication to sync between the local and remote instances…
So I stop here, leaving my train of thought still on its tracks, and the large part of my wild optimization fantasies unfulfilled. I told you that I can control my addiction to joy, common sense finally pulled the emergency brake and this is the proof. But nonetheless, the other day Salvatore told me (on a different matter altogether) that: “Breaking things is good, the quintessence of hacking :-)”, so perhaps I should…
Questions? Feedback? Feel free to tweet or email me – I’m highly available 🙂
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.