
New technologies come and go quicker than the seasons. Sometimes it’s hard, as a developer, to know which tools are worth knowing about and learning how to use, and which will seem like last year’s news in only two months. Project Jupyter however, is definitely worth taking the time to learn about. They’ve been creating tools to help developers for almost a decade. Their Executive and Software Steering Councils include folks from top-notch companies like AWS, Netflix, and Apple. They also recognize distinguished contributors every year. The classic Jupyter Notebooks have trickled into education and learning for good reason. So if you’ve been a developer recently, you’ve probably heard of or even used Jupyter Notebooks. Maybe you’ve even used JupyterLab and the advanced tools it offers. But if not, what are Jupyter Notebooks and JupyterLab, and why are these tools useful?
So why is it useful for Vector Search?
To start off with the important stuff, if you have some data that you want to vectorize, and you want to try out different models, and you want to try out different types of similarities; what easier way to change things up on the fly than with a tool that lets you run individual cells without re-running the processing or the imports or the other things that you don’t want to change? With the incremental development these products allow, you can import new libraries halfway through your code and try them out cell by cell without committing too much time and energy.
Project Jupyter has put out quite a few tools over the years that make incremental changes and tweaking of models incredibly easy. One of the coolest features is widgets that actually let you use sliders to adjust variable inputs and show the changes in real time to any graphs or outputs from the function.
If you want to get started right away using Jupyter, Redis, and vector search, you can check out a demo on GitHub that’ll get you started.
Project Jupyter
The name “Jupyter” is a combination of three programming languages it initially supported: Julia, Python, and R. However, its scope has since expanded to accommodate a myriad of languages with multiple kernels (the things that run the code in the Notebooks) available from Project Jupyter.
Jupyter has grown to be commonplace in education settings, with the flexibility and interactivity having a huge appeal to students and educators alike. Being able to show students what different variables, different sorting, etc. does to a single dataset with just one cell needing to be run. Through Jupyter Notebooks, the combination of text, code, and visualizations can allow educators to teach in an interactive and quickly adaptable way.
At its core, Project Jupyter provides an interactive computing environment that facilitates a seamless integration of code, data, and visualizations. This project is not just about creating tools; it’s about fostering a culture of open, collaborative, and reproducible research.
Jupyter Notebooks
The Jupyter Notebook is the flagship product of Project Jupyter. It is an open document format that allows users to create and share documents that contain code, equations, visualizations, and narrative text. Notebooks are accessible through a web-based interface, making it platform-independent and easily shareable across different devices. These Notebooks are a useful tool for any developer to have in their toolbelt. They make development an incremental process, saving developers the frustration of having to run their entire program or script again when they get a line of code wrong. Instead a Jupyter Notebook can run code in segments, saving the state at each segment so we don’t have to reload a dataset every time we want to try something different. While the data loading problem would also be solved with a vector database, like Redis, there are numerous other benefits to this step by step running of code.
A Jupyter Notebook is organized into cells, each of which can contain code, text, or multimedia elements. This structure provides a natural way to break down complex problems into manageable, modular components. These cells can be run individually, in a sequential manner or not, showing users exactly what’s changing with each cell. Skipping a cell can be especially useful in demonstrating why a step is needed and is done easily with this cell structure. Seeing each intermediary result can really enhance the exploratory nature of learning data science. While many debuggers offer step by step code execution features, a still uncommon feature is being able to go backwards in time. But Jupyter allows you to! You’re able to change the last cell, and by re-running just the last cell, you’re able to essentially go backwards in time (as far as your program is concerned at least) to before it had been run at all. It’s not only the last cell either, you’re able to pick up at any point in your Notebook and change things from there on, without rerunning preceding cells. This benefit alone is huge, and has saved me plenty of time with debugging and making changes to programming logic, where I’ve been able to fiddle with a for loop by itself instead of having to run an entire Python script.
Another great feature of the Notebooks are the rich visualization capabilities, supporting the integration of interactive charts, graphs, and other visual elements. This makes data exploration and analysis more intuitive and insightful. With the integration of libraries like Matplotlib, Plotly, and Seaborn, users can generate high-quality visualizations directly within the notebook environment.
JupyterLab
While Jupyter Notebooks laid the foundation for interactive computing, JupyterLab represents the next evolutionary step. JupyterLab is an extensible environment that provides a flexible and powerful interface for interactive computing. It retains the key features of Jupyter Notebooks but introduces a more modular and extensible architecture.
One of the strengths of JupyterLab lies in its extensibility. Users can customize their environment by installing extensions that add new features and functionality. This extensibility fosters innovation, enabling the community to develop and share tools that cater to specific needs, from enhanced text editing to advanced data visualization. These extensions include, but are not limited to, rendering different file types like DMN, coding assistance with Language Server Protocol, a GUI-style Python code generator, and even packages that will turn your Notebooks into slideshows with slides for text, code, and images. There are also sites like Binder that will turn a GitHub repository into a “binder” full of them that can make your entire repo reproducible by anyone.
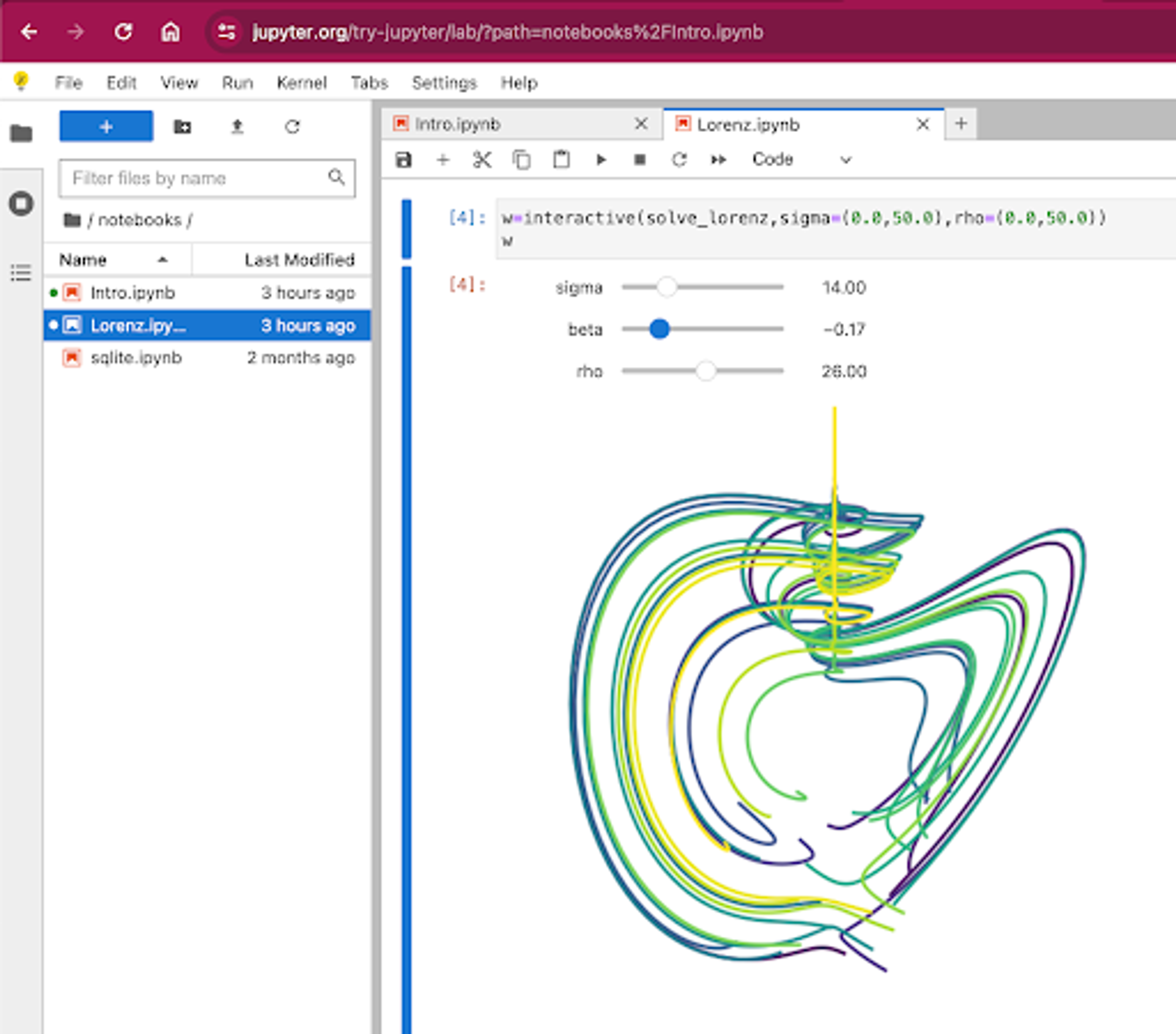
Another big advancement since the Notebooks was the introduction of the interactive widgets. The example shown above is from Project Jupyters own try it out demonstration. Here the “solve_lorenz” is a function defined in a cell above, but gets used here with the interactive widget to show the variable ranges. These sliders can be moved with a mouse click and drag, with the resulting plot being updated each time the slider is moved. This visualization is insanely cool, and the tool can be insanely useful. Instead of calling a function with the variables you think you want, these sliders allow you to mess around with the inputs in a fun and engaging way. How quickly the visualization gets updated with new parameters also gives a peek into how much compute power there is behind Jupyter projects.
In conclusion
Project Jupyter transcends the ephemeral nature of many tech trends, offering a platform that not only facilitates but also inspires innovation. Its integration with Redis for vector search tasks exemplifies the potential for Jupyter to adapt and thrive in the face of evolving computational challenges. For developers and data scientists alike, investing time in mastering Jupyter and exploring its applications in conjunction with Redis is not just beneficial but essential for staying at the forefront of technological advancement.
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.