Blog
Build Intelligent Apps with New Redis Vector Similarity Search

On a recent family trip to Switzerland, my son took a photo on his smartphone as we walked through the lovely Lavaux Vineyard Terraces.

Using Google Lens, he was able to use the image to quickly look up the fascinating history of this UNESCO World heritage site. Google Lens allows users to “search what they see” around them by using a technology known as Vector Similarity Search (VSS), an AI-powered method to measure the similarity of any two pieces of data, images included.
VSS empowers developers to build intelligent applications with powerful features such as “visual search” or “semantic similarity”—all with just a few lines of code. The best part is that you don’t need to be an Artificial Intelligence (AI) or machine learning (ML) expert to do it. In fact, it’s easier than ever with Redis Vector Similarity Search, a new capability we just released that turns Redis into a vector database.
What is VSS? Want to try it out? Read on!
What is Vector Similarity Search (VSS)?
As noted, VSS is an advanced search method used to measure the similarity between different pieces of data. While it works well with structured data, VSS really shines when comparing similarity in unstructured data, such as images, audio, or long pieces of text. For example, using VSS and a touch of AI/ML (more about this in the next section), you can take a pair of images and generate vectors for each of them. These vectors—or, more precisely, vector “embeddings”—encode features of each image as a 1-dimensional array of numbers. These embeddings can be compared to one another to determine visual similarity between them. The “distance” between any two embeddings represents the degree of similarity between the original images—the “shorter” the distance between the embeddings, the more similar the two source images.
How do you generate vectors from images or text?
Here’s where AI/ML come into play.
The wide availability of pre-trained machine learning models has made it simple to transform almost any kind of unstructured data (image, audio, long text) into a vector embedding. For example, Hugging Face, a startup focused on natural-language understanding (NLU), provides free access to hundreds of state-of-the-art models that transform raw text data into its vector representation (embedding).
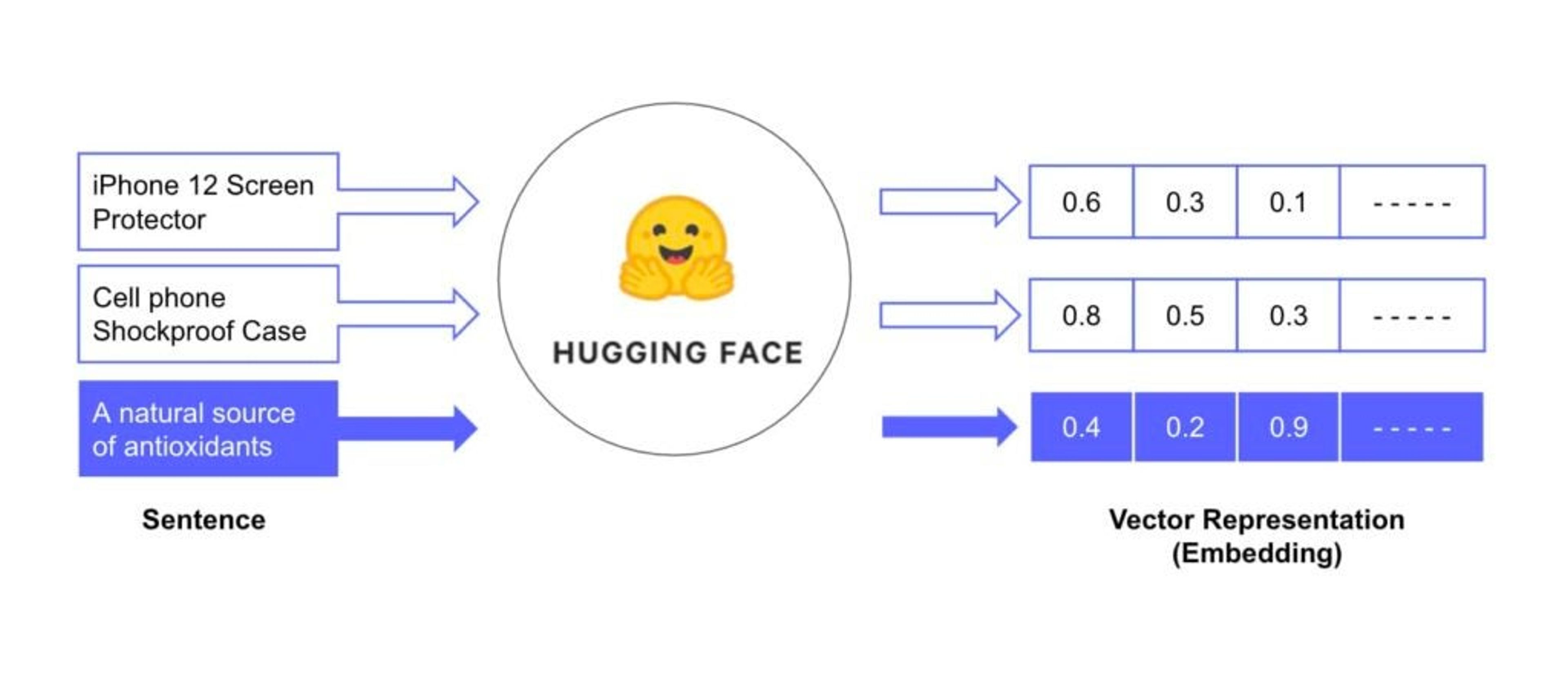
The clever trick of these models is that the embeddings generated for two sentences will be “close” to each other only when the meaning of the sentences is semantically similar.
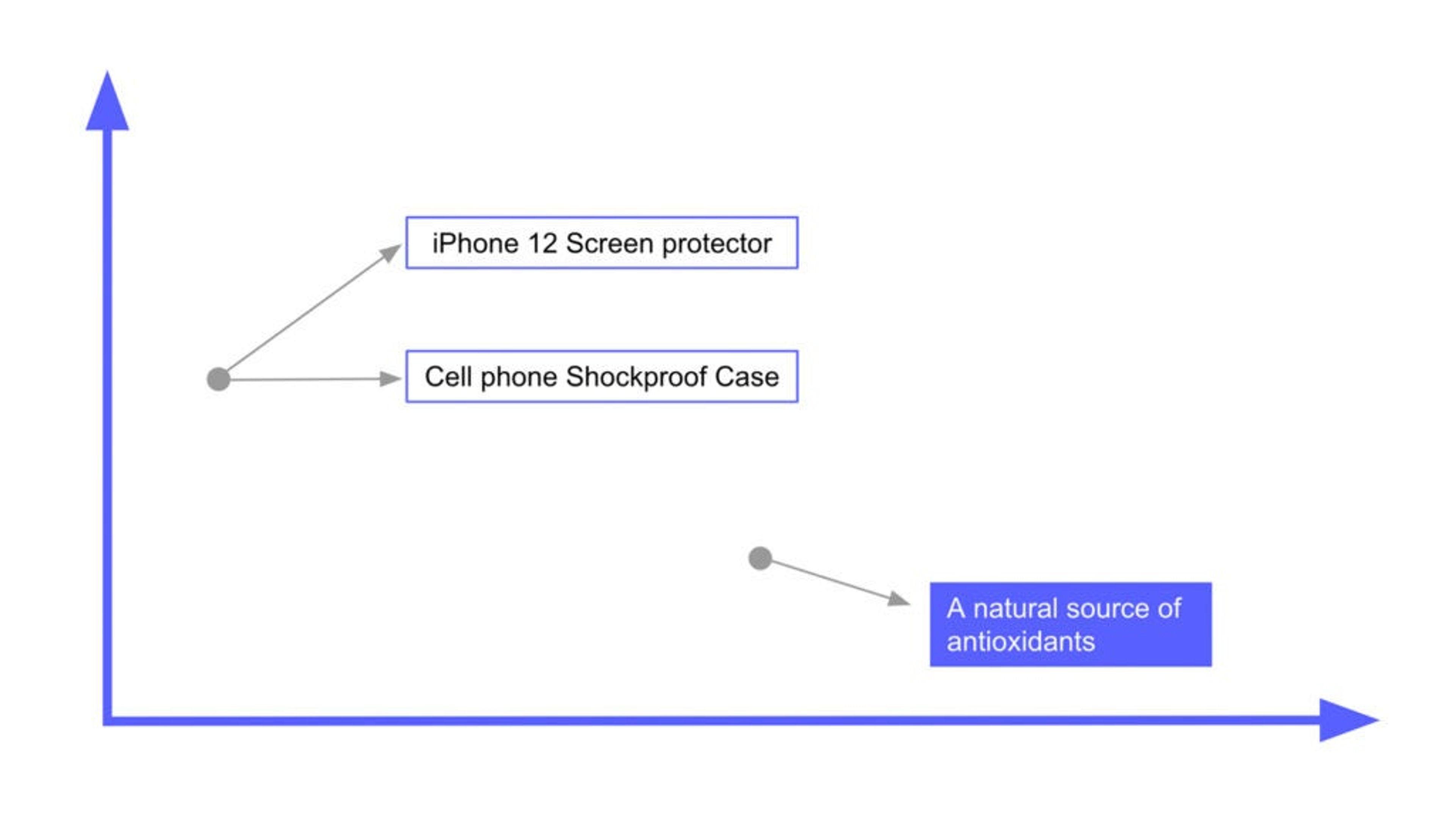
Figure 1. Simplified representation of vector embeddings in a 2D vector space
In Fig. 1 above, you get a sense of how the embeddings for sentences are related. If you look at embeddings generated for sentences related to a “mobile phone,” you’ll notice that they are “close” to each other (see top left part of the diagram). More important, both of these embeddings are noticeably distant from the embedding generated for a sentence that relates to a food supplement product (lower right part of the diagram). The “distance” between the embeddings acts as a proxy for their semantic similarity. There are even models that capture semantic similarity for sentences in multiple languages.
In the computer vision world, there is an equivalent: Torchvision, a PyTorch library for computer vision, offers a number of pre-trained models that can be used to generate a vector for a given image. In a similar fashion to Hugging Face models, the Torchvision-generated embeddings for two images will be close to one another only when the images are visually similar.
Developers can leverage these freely available models into their applications.
But generating the vector representations or embeddings is only the first step. You need a database to store the vectors, index them, and perform Vector Similarity Search.
Redis as a vector database
At the core of Vector Similarity Search is the ability to store, index, and query vector data. These are the essential capabilities needed in a vector database.
Our VSS capability is built as a new feature of the RediSearch module. It allows developers to store a vector just as easily as any other field in a Redis hash. It provides advanced indexing and search capabilities required to perform low-latency search in large vector spaces, typically ranging from tens of thousands to hundreds of millions of vectors distributed across a number of machines.
In short, this new RediSearch feature turns Redis into the powerful real-time, in-memory vector database your app needs.
OK, so how do I build visual or semantic search similarity into my application?
Get hands on with our Redis VSS demo
If you have Docker and a little knowledge of Python, you can take Redis VSS for a spin on a container and play around with a realistic dataset. The Redis VSS demo provides step-by-step guidance to get you started.
You will start a Docker container with Redis VSS and go through several Jupyter Notebooks showing you how to generate, load, index, and query vectors generated from product images and text descriptions.
You will be using the Amazon Berkeley Object (ABO) dataset, which contains text and images for hundreds of thousands of products listed on Amazon.
In the demo you will find four Jupyter notebooks illustrating the key elements needed to build visual and semantic similarity into your app. These are:
- Generate vector embeddings for product images and text descriptions in the ABO dataset.
- Create an index for the vector data.
- Load vectors, along with other product data, into Redis hashes.
- Run visual and semantic similarity queries.
Give it a try and have some fun with it. We’d love to hear how your first experience with Redis VSS went.
Please join our #VSS channel on Discord. We’ll be happy to answer any questions you may have about VSS and its potential applications.
Want to try Redis VSS at scale?
Sign up for our hosted private preview program.
During private preview, we are working with a selected number of customers with a clear use case and lots of data. We’ll provide you with resources to try VSS out at scale. In return, we’ll ask you to share your feedback about the experience.
Reach out to us on Discord and let’s get the conversation started.
Additional resources
- Learn more about RediSearch:RediSearch 2.0 lets you build modern apps with interactive search experiences
- Complete Redis University course RU203: Querying, Indexing, and Full-Text Search
- See the Redis VSS features available in private preview.
- Find out about RedisJSON powered by RediSearch: Public Preview & Performance Benchmarking
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.