Blog
Turbocharge Cloud Spanner with Redis Enterprise Active-Active for Global Real-Time Applications


Redis Enterprise’s Active-Active Geo-Distribution and Google Cloud Spanner’s replication work together to provide a unified real-time data layer for geo-distributed applications. Here’s how they connect and the benefits the tech provides.
Designing and developing a geo-distributed application can be complicated. Applications that span multiple geographic locations have multiple requirements, and sometimes those get in the way of one another. Geo-distributed applications need high availability, resiliency, compliance, and performance across remote distances.
Ensuring data consistency in these database systems across multicloud regions should be a critical feature in the underlying database technologies. And it should not be a developer’s concern.
In this blog post, we discuss the combination of Redis Enterprise’s Active-Active Geo-Distribution and Google Cloud Spanner’s replication, which together provide a resilient, globally-consistent data layer for geo-distributed real-time applications.
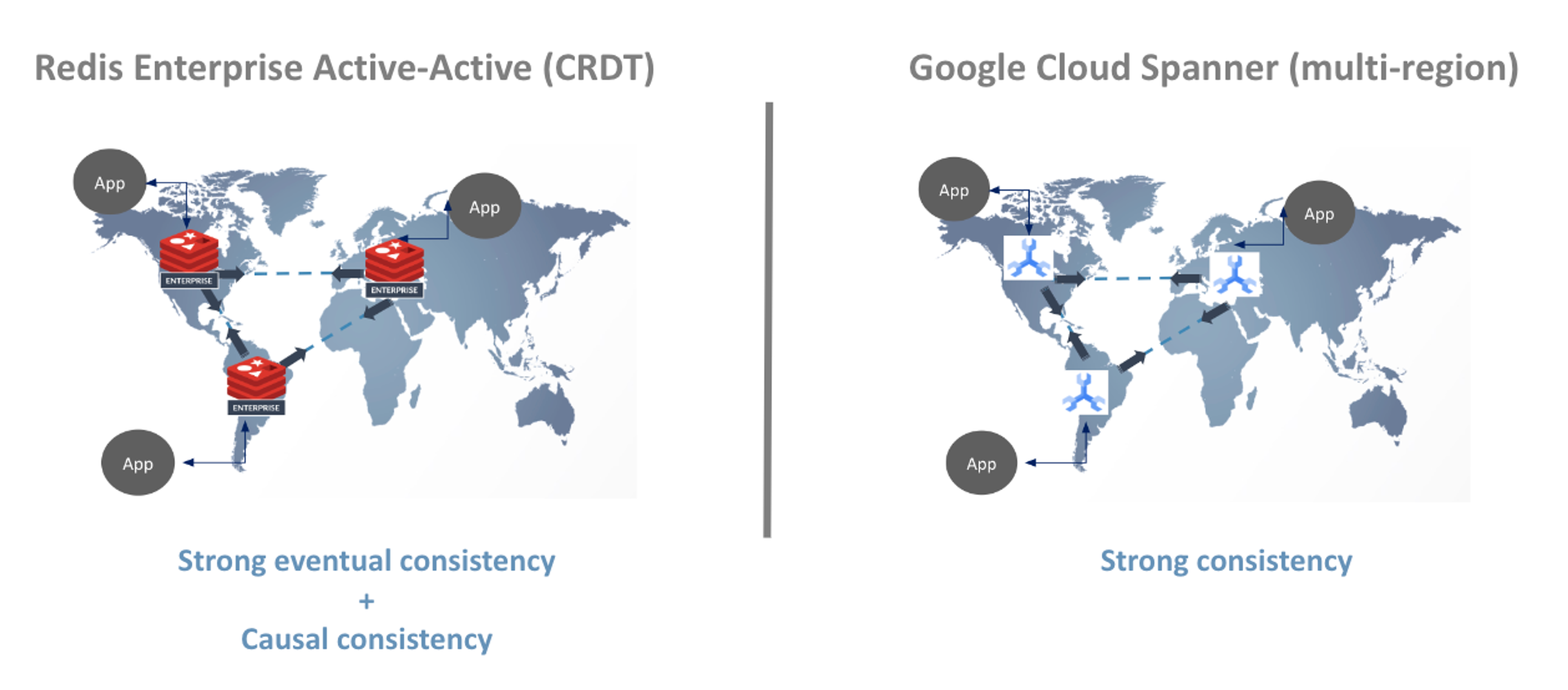
Cloud Spanner is a fully-managed database service. It’s part of Google Cloud’s effort to bring ACID-based consistency, SQL relational database capabilities, and synchronized replication among geographical locations to the masses. Cloud Spanner supports mission-critical applications, and it complies with relational database services by offering transactional consistency at a global scale, schemas, SQL (ANSI 2011 with extensions), and automatic, synchronous replication for five-nines SLA high availability.
That syncing feeling
A data layer generally consists of multiple database technologies. They may include an in-memory database serving as the front-end cache to improve speed and performance, and also a traditional relational database or a NoSQL database to persist data in the backend system of record.
Redis Open Source is powerful, but it falls short on various enterprise-grade features like multi-region deployments, particularly when it’s used in a front-end cache for multi-region Cloud Spanner topology.
As the following schematic diagram illustrates, an application deployed in two different geographic regions (us-east1 and us-west1) may behave erratically in the event of simultaneous cache reads and writes.
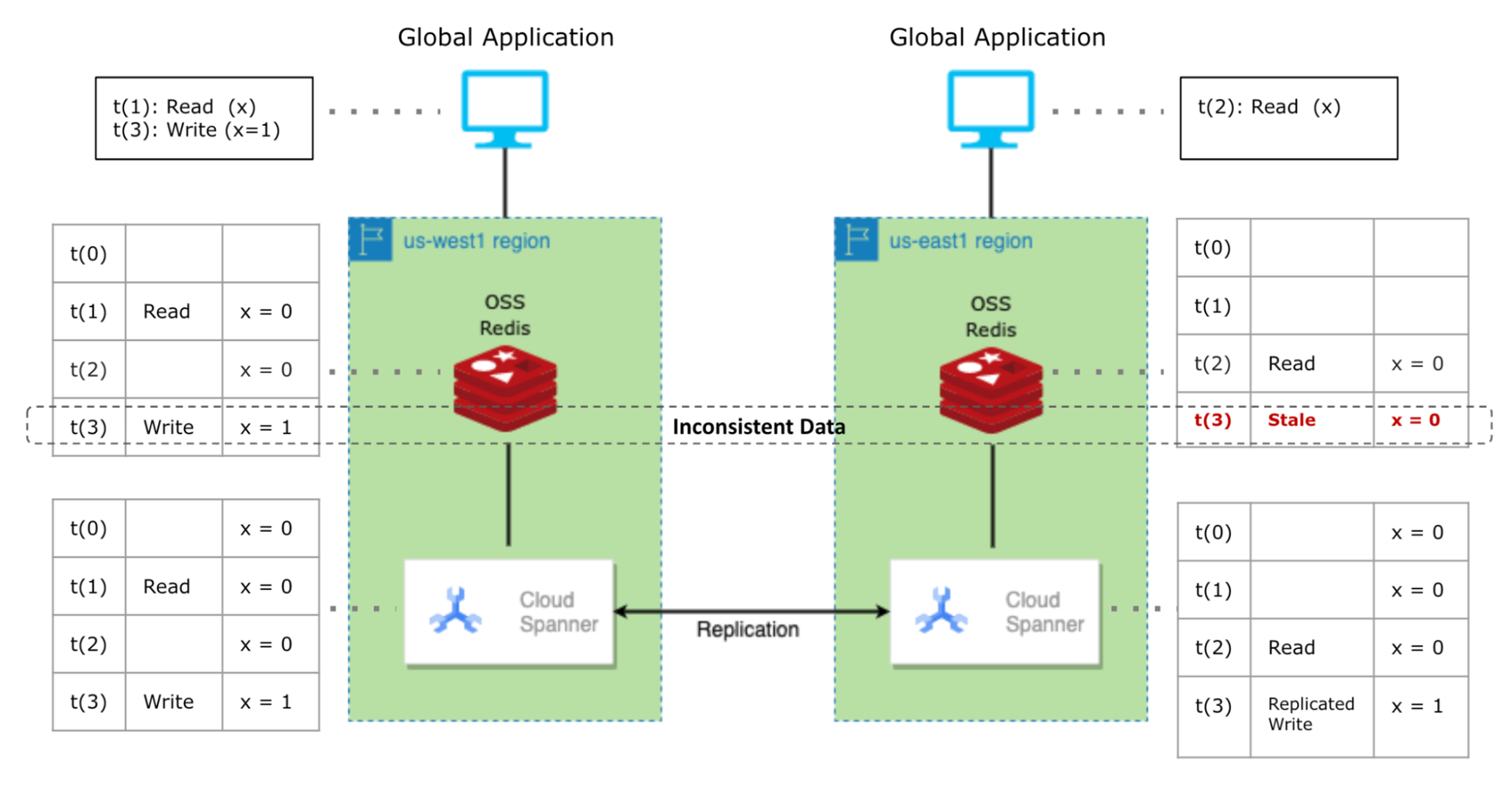
Redis OSS Cache for Cloud Spanner
Imagine that this application architecture is meant to support a globally distributed real-time event booking and ticketing system. Outdated information could cause losses in business and poor customer experience.
It’s not a hypothetical example. Not long ago, one ticketing service provider experienced a major setback when its system acted on outdated information. As a result, concertgoers from different regions received contrived ticket prices due to an inconsistent number of available tickets for correct dynamic pricing calculations.
How can that happen? Here’s the process.
Let’s say a popular concert is coming up for, say, Ariana Grande. Both the U.S.-west and U.S.-east databases have the correct number of tickets listed in the inventory. So far, so good.
- At time = t(0), x has a value of the number of available Ariana Grande concert tickets for sale in Cloud Spanner; let’s say that’s 100 remaining tickets. But it’s a popular concert, and tickets sell fast. At time = t(1), the ticketing system has a cache-miss in the us-west1 region; the requested data isn’t found in the cache. Our x is stored on the Redis OSS instance with the value of available tickets for sale. In other words, the ticketing application says there are 100 seats remaining, according to us-west data.
- At time = t(2), the ticketing system has a cache-miss in the us-east1 region. Now x is stored on the Redis OSS instance with the value of the correct number of available tickets for sale (still 100 seats).
But then there’s a caching mismatch. Someone on the west coast buys 20 tickets, but the east coast database doesn’t get the update. The west coast database says there are 80 tickets available, but the east coast still says 100.
That doesn’t matter much if nobody buys the tickets. But this is Ariana Grande, so you know the concert will sell out.
- That is, a write operation on x in the us-west1 region (20 seats sold!) changes the number of available tickets. The Cloud Spanner instances on both regions now have the same and correct value of x with its cross-region replication capability.
In our cache-aside example, the value of x has an outdated value of available tickets for sale (still 100 seats) in the Redis OSS instance in the us-east1 region. Now, a problem arises on the next read operation on x (available tickets for sale) in the us-east1 region when someone on the east coast tries to buy those seats. That’s because x still has the old and outdated value even though the Cloud Spanner instances in both regions have the correct value.
With our solution in place, this just won’t happen. The two of us keep things in sync. Nobody has to cry — or get into a drunken fight at the concert over those seats.
The fix? Redis Enterprise
Redis Enterprise can solve this problem thanks to the native support of active-active geo-replication. Using this feature, Redis Enterprise can serve as a cross-region distributed cache to ensure data consistency across regions. That guarantees stronger consistency both in the caching layer and in the system of record.
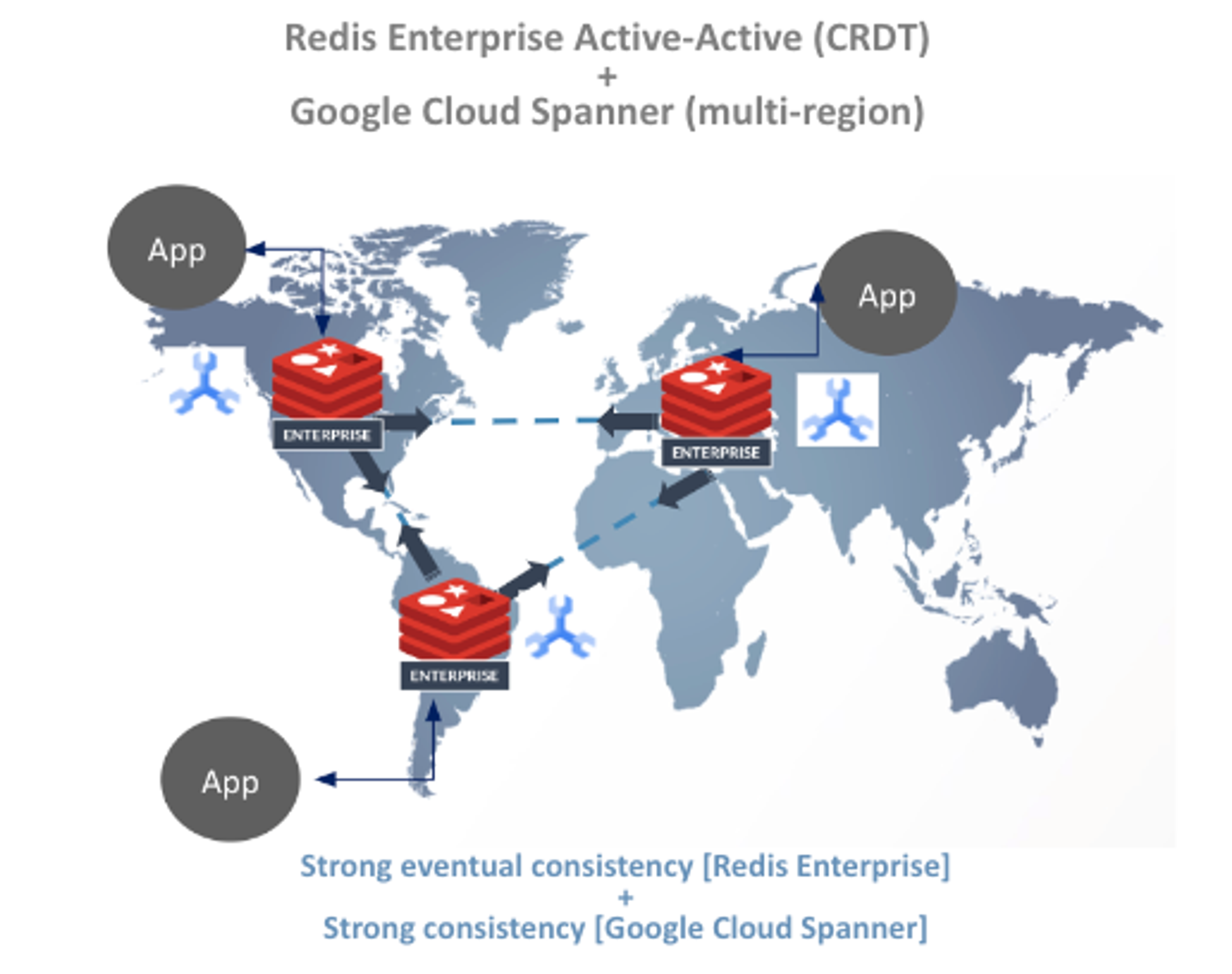
Distributed Redis Enterprise Cache for Google Cloud Spanner
Better yet: No additional development work is required to use Redis Enterprise’s native Active-Active Geo-Duplication. Each Redis Enterprise cluster supports local read and write operations with under one-millisecond latency, and it works harmoniously with the underlying Cloud Spanner instance in each cloud region. Without you doing anything special, data is automatically replicated among Redis Enterprise clusters. Frequent data-read access is offloaded to Redis Enterprise to improve application response time as well as to optimize overall data access costs.
More importantly, Redis Enterprise’s Active-Active feature in Google Cloud Marketplace supports five nines SLAs as Cloud Spanner does in multi-region deployments. End result? Better price performance with no maintenance downtime.
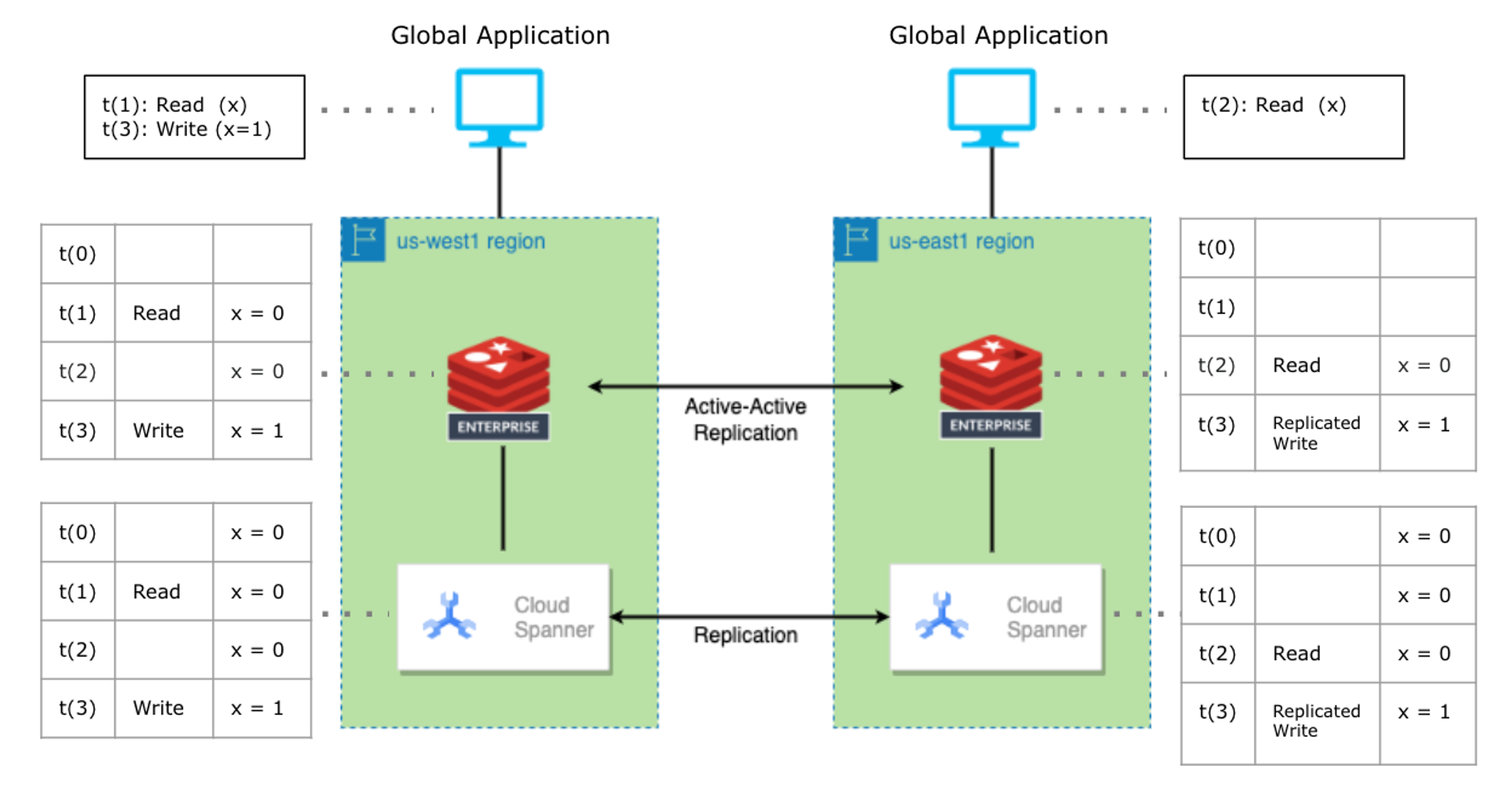
Distributed Redis Enterprise Cache for Cloud Spanner
Active-Active Geo-Distribution is achieved by implementing conflict-free replicated data types (CRDTs) in Redis Enterprise using a global database that spans multiple clusters and conflict-free replicated databases (CRDBs).
You can use this kind of deployment topology across different industries to solve well-known problems. For instance:
- Disaster recovery
- Distributed session management across geographies
- Distributed applications spanning multiple geographies
Who needs this? A short survey of industry trends
Since its inception in 2017, customers in retail, financial services, and gaming industries have used Cloud Spanner to support applications requiring robust consistency and unlimited scalability. Which, admittedly, is everything.
One such example is the retail industry, where electronic commerce has been reinventing itself since Pizza Hut set up the first online ordering website in 1994. The COVID-19 pandemic forced retailers to rethink how retailers could reach and serve customers, such as quickly implementing curbside delivery systems. And despite the increase in online purchases, shoppers expect real-time responses.
Those business endeavors require a software foundation on which to build new retail features. New players are democratizing the e-commerce software stack with headless e-commerce platforms that support microservices architecture, API-first, cloud-native, and headless (MACH) principles. And it has to work across all geographic regions, from retailer warehouses to the supply chains that support their inventory.
The financial services industry has its own challenges, such as ever-changing regulatory requirements, cybersecurity woes, and business model adjustments – each of which affects technology budgets. Interactions between bank institutions, fintech, and regulatory bodies must run flawlessly.
Here, too, the industry must respond to increased demands. The pandemic increased digital payments usage, according to The World Bank. About two-thirds of adults worldwide now make or receive digital payments, with the share in developing economies growing from 35% in 2014 to 57% in 2021, according to the report.
The video gaming industry is healthy and growing – but it, too, has to deal with market shifts, such as changes in spending habits pre- and post-COVID lockdowns. Again, the companies that bring out super-popular games (such as Splatoon 3) present technical challenges to the underlying application infrastructure platform. It takes a lot of computational power to support a worldwide game launch with millions of online players, multiplayer support, and in-game purchases.
Redis is used extensively in these three industries, among so many more. The enterprise capabilities provide the data models required to build software that stands up to user demand. That’s true whether it’s to leverage native data structures like string, set, and hash as a simple cache for storing application data, hash for storing user profiles, sorted-set for tracking top 10 spenders during an online sale event, hash for externalizing the sessions in a microservices architecture, set or hash for tracking the buying behavior of a user. The possibilities are endless as the business requirement at hand stimulates the power of Redis Enterprise and drives its consumption.
For instance, RedisJSON, along with RediSearch, can be used to model product catalogs, shopping carts, and order details in a retail application. They can also model retail bank accounts, securities portfolios in trading applications, and nominee details for a retail banking application. In a game, the same combination of JSON and search modules can be used to store players’ game inventory, player profiles, and player matchmaking data.
One well-known Google Cloud customer is using Redis Enterprise to store user information and application critical data along with Google Cloud Spanner as primary storage deployed in two regions. By deploying Spanner and Redis Enterprise in multi-region topology, they are achieving two objectives: Global datastore and caching engine for the organization’s distributed workload, and disaster recovery concerns with ultra-fast failover time, reduced complexity, and best Recovery Point Objective (RPO) and Recovery Time Objective (RTO) guarantees.
The scale-out and the scale-in process is also seamless. By adding new nodes, it is possible to scale from 100,000 requests per second to 1 million requests per second, even during high-demand days such as Black Friday. You just pay for the capacity you use.
Want to learn more?
We have extensive information about Redis Enterprise’s Active-Active Geo-Distribution and Google Cloud Spanner. To learn about the state of your current cache strategy, take a five-minute assessment to receive practical recommendations.
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.