
We are happy to announce the release of the first milestone in the development of RediSearch 2.0. RediSearch is a real-time search engine that lets you query your Redis data to answer a wide variety of complex questions.
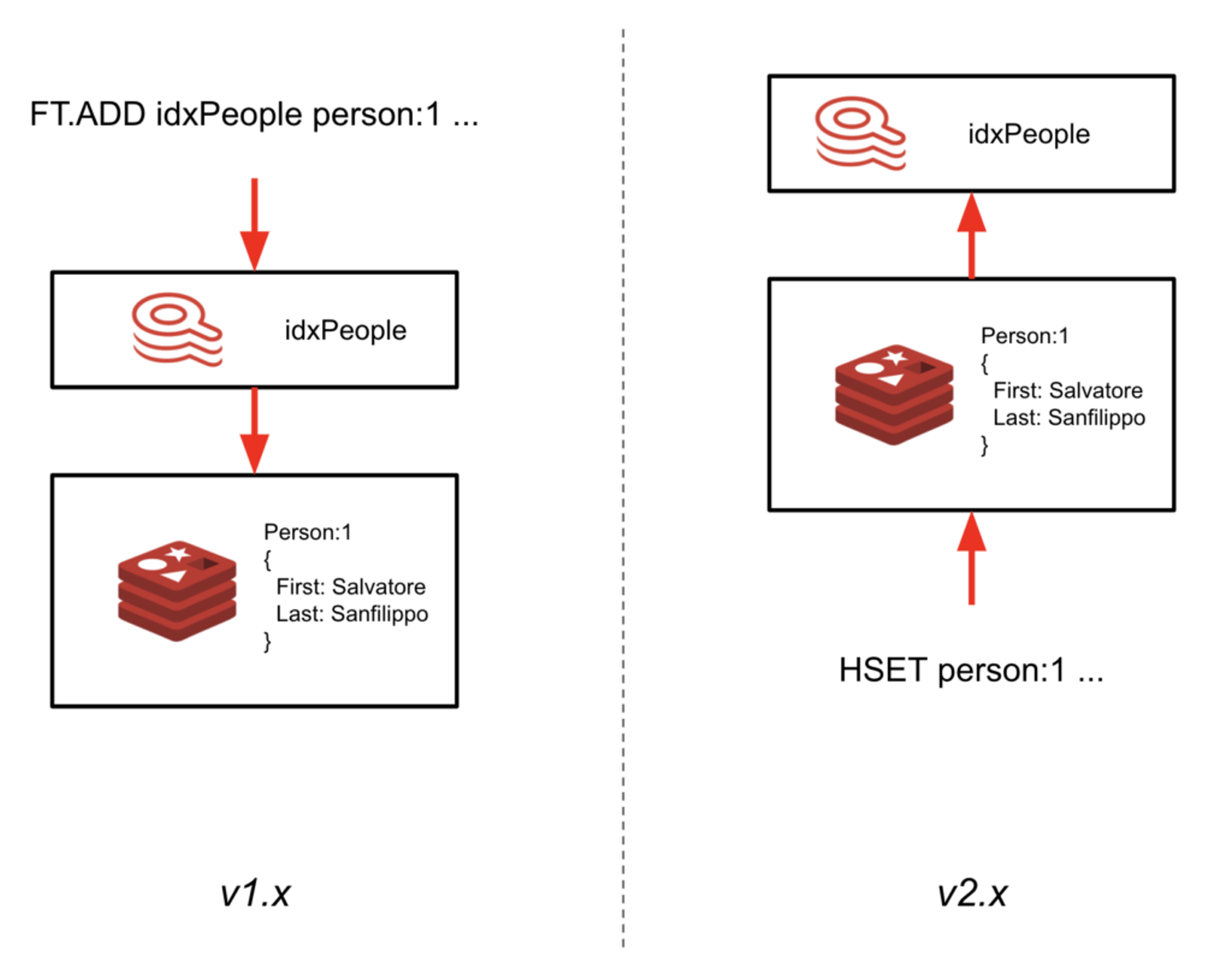
This milestone, dubbed 2.0-M01, marks the re-architecture of the way indices are kept in sync with the data. Instead of having to write data through the index (using the FT.ADD command), RediSearch will now follow the data written in hashes and automatically index it.
The big advantage here is that you can now add RediSearch to your existing Redis instance and create a secondary index without having to update your application code. This lets you immediately start using RediSearch on your existing data, simply by loading the RediSearch module and defining the schema. General availability of RediSearch 2.0 is expected this Fall.
(Note: This new feature introduces some changes to the API (listed below). We try to maintain backward compatibility as much as we can, but in this case it was just not possible. We plan to make adjustments and fixes going forward as we gather customer feedback.)
The architecture of the RediSearch 2.0 milestone.
API changes
As noted above, this RediSearch 2.0 milestone includes several changes to the API:
- The index no longer lives in the key space. If you used the index key (idx:<index name>) to list the indexes in the database, for example, this will no longer work. However, we introduced a command FT._LIST to return all the indices in the database.
- Indexes must be created with a prefix/filter. These specify which documents will be indexed automatically by RediSearch. You can specify a simple prefix and/or a complicated filter expression.
- Upgrades are not possible. If you have an RDB created with an older version of RediSearch, RediSearch 2.0 will not be able to read it. Currently, you will have to re-index the entire data set. We are, however, working on an upgrade process for the GA release.
- It works only with Redis 6 and above.
- The FT commands were mapped to their Redis-equivalent commands. This allows existing applications to still work with RediSearch 2.0. The mappings are as follows:
- FT.ADD => HSET
- FT.DEL => DEL (DD by default)
- FT.GET => HGETALL
- FT.MGET => HGETALL
- The inverted index itself is no longer saved to the RDB. This does not mean that persistency is not supported. RediSearch does save the index definition to the RDB and index the data in the background after Redis is started. You can find out when the reindexing is finished by checking the indexing status using the FT.INFO command.
The new API
The biggest update to the API is how indices are created. In RediSearch 2.0 the command FT.CREATE is used to create indices. The additions to the API are highlighted in yellow here:
Let’s dig into some of the details:
- ON {structure} currently supports only HASH
- PREFIX {count} {prefix} tells the index which keys it should index. You can add several prefixes to index. Since the argument is optional, the default is * (all keys)
- FILTER {filter} is a filter expression with the full RediSearch aggregation expression language. It is possible to use @__key to access the key that was just added/changed
- LANGUAGE and SCORE let you override the default language and score for all documents that are indexed
- LANGUAGE_FIELD, SCORE_FIELD, and PAYLOAD_FIELD allow you to have document-specific language and scoring, and to use payload as a field within the document.
Other limitations and changes
The RediSearch 2.0-M01 milestone also brings a few other updates:
- NOSAVE is no longer supported.
- Updating hashes implies that the entire document will be indexed (keyspace notifications don’t address which fields were changed). So partial updates will be slower. Note that we are still investigating options to improve performance in these situations.
- Field names are now case sensitive, so declaring a field “FOO” and indexing it as “foo” will not work.
- The FT.ADD command will be mapped to hset as shown here:
FT.ADD idx doc1 1.0 LANGUAGE eng PAYLOAD payload FIELDS f1 v1 f2 v2
Is mapped to
HSET doc1 __score 1.0 __language eng __payload payload f1 v1 f2 v2
This means that the score, language, and payload fields on your index must be called __score, __language, __payload, accordingly, in order for the mapping to work as expected.
- FT.ADDHASH is no longer supported. Use HSET.
- FT.OPTIMIZE is no longer supported, the RediSearch Garbage Collection function is responsible for optimizing the index.
Conclusion
We are really excited about these changes because you can now load RediSearch into your existing Redis database and index your existing data that resides in hashes, without having to update your application logic when manipulating these documents. You can try out this milestone release by taking the source code from GitHub or by using the 1:99:1 RedisSarch Docker image. This version is not yet production ready, but we wanted to share it with you now to gather your feedback. Please share any comments or issues on our GitHub repository or in the Redis Community forum.
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.