
Why does RAG need real-time data?
We’re seeing Retrieval Augmented Generation (RAG) become the de facto standard architecture for GenAI applications that require access to private data. Nevertheless, some may wonder why it’s important to have real-time access to this data. The answer is quite simple: you don’t want your application to stop running fast when you add AI to your stack.
So, what is a fast application? Paul Buchheit (the creator of Gmail) coined The 100ms Rule. It says every interaction should be faster than 100ms. Why? 100ms is the threshold “where interactions feel instantaneous.”
Let’s examine what a typical RAG-based architecture looks like and what latency boundaries each component currently has as well as the expected end-to-end latency.
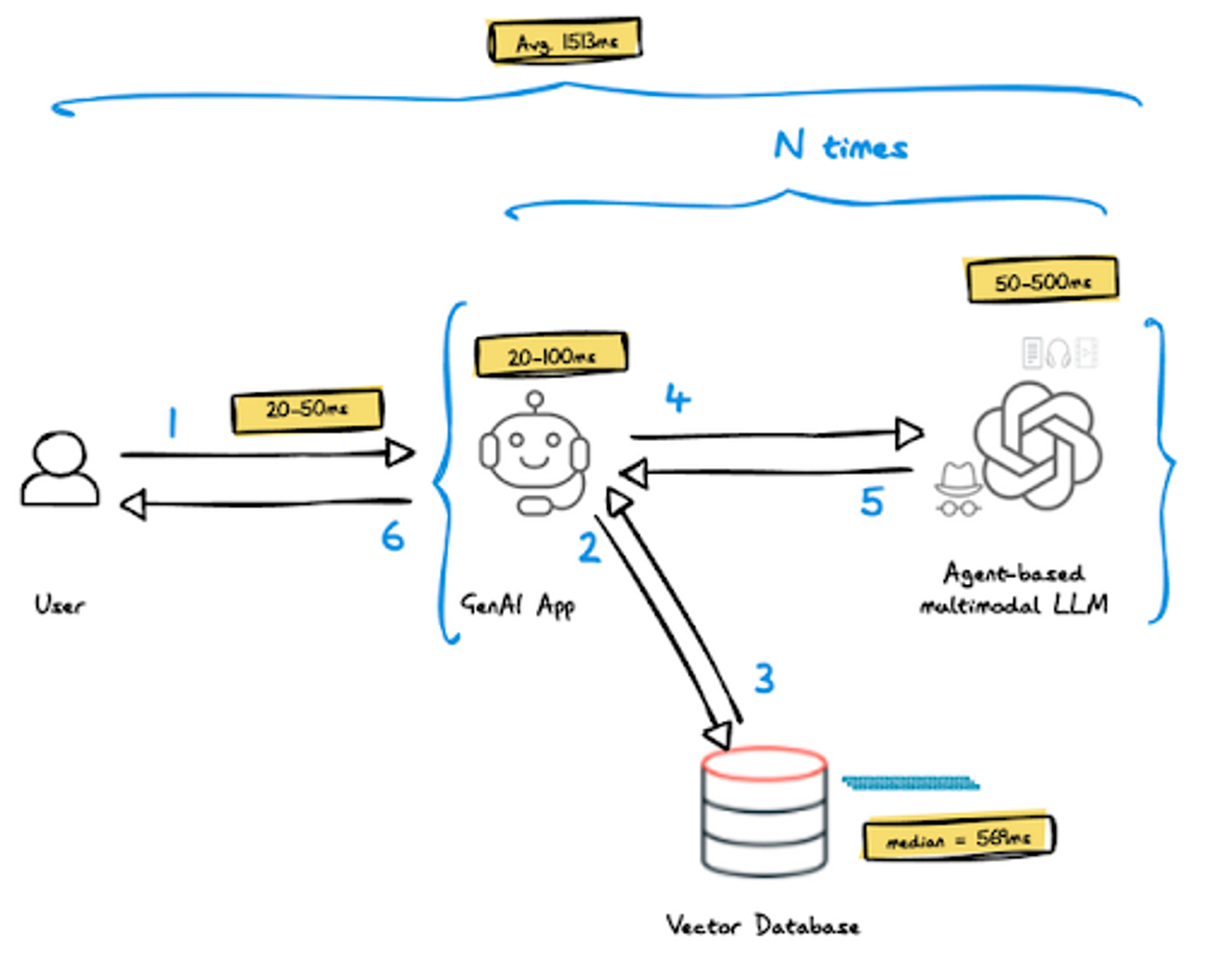
- Network round trip — assuming the end users of your app and data centers are in the US, the round trip is expected to be in the range of 20-50ms.
- LLM — from ChatGPT: “As of my last update, the LLM processing time for generating a response typically ranges from tens to hundreds of milliseconds, depending on the specifics mentioned above. This processing time can be affected by the model’s architecture, the length and complexity of the input text, and any additional tasks performed alongside generating the response (such as context analysis or formatting). “
- GenAI app — we can expect tens of milliseconds for local operations and hundreds of milliseconds when calling third-party services.
- Vector database — stores the dataset or corpus you want to use to add context to the LLMs to generate accurate and relevant responses. The dataset captures semantic information about the documents (i.e. vectors) and enables efficient similarity-based retrieval during the retrieval phase. A vector search query is usually a high computation complexity operation query. In a comprehensive benchmark we conducted and will soon publish, a vector search query plus 10 documents results in a median response time of 569 milliseconds across multiple datasets and loads
- Agent based architecture — may drive multiple execution cycles of components 2-4
Based on this analysis, a GenAI application built using the above architecture should expect an average of 1,513ms (or 1.5 seconds) end-to-end response time. This means you’ll probably lose your end users’ interest after a few interactions.
To build a real-time GenAI application that allows closer to the 100ms Rule experience, you need to rethink your data architecture.

Build fast, accurate AI apps that scale
Get started with Redis for real-time AI context and retrieval.How does Redis make RAG real-time?
To deal with the above challenges, Redis offers three main datastore capabilities for AI that will enable real-time RAG:
Real-time vector database
Redis supports vector data type and vector search capabilities even before the term GenAI was coined. The Redis vector search algorithm uses highly efficient in-memory data structures and a dedicated search engine, resulting in up to 50 times faster search (we will shortly release our comprehensive benchmark results) and two orders of magnitude faster retrieval of documents. It will be shown later in this blog how real-time vector search can significantly improve user experience end-to-end.
Semantic cache
Traditional caching techniques in Redis (and generally) use keyword matching, which struggles to capture the semantic similarity between similar queries to LLM-based services, resulting in very low hits. Using existing caches, we don’t detect the semantic similarity between “give me suggestions for a comedy movie” and “recommend a funny movie”, leading to a cache miss. Semantic caching goes beyond exact matches: It uses clever algorithms to understand the meaning of a query. Even if the wording differs, the cache can recognize if it’s contextually similar to a previous query and return the corresponding response (if it has it). According to a recent study, 31% of queries to LLM can be cached (or, in other words, 31% of the queries are contextually repeatable), which can significantly improve response time in GenAI apps running in RAG-based architectures while dramatically reducing LLM costs.
You can think of semantic cache as the new caching for LLM. Utilizing vector search, semantic cache can have significant performance and deployment cost benefits, as we’ll explain in the following sections.
LLM Memory (or extended Conversation History)
LLM Memory is the record of all previous interactions between the LLM and a specific user; think of it as the session store for LLM, except it can also record information across different user sessions. Implemented using existing Redis data structures and vector search, LLM Memory can be incredibly valuable for several reasons:
- Improved personalization:
- Understanding user preferences: by analyzing past conversations, the LLM can identify a user’s preferred topics, communication style, and terminology. This allows the LLM to tailor its responses to better suit the user’s needs and interests.
- Building rapport: referencing past discussions and acknowledging the user’s history helps create a sense of continuity and rapport, which fosters a more natural and engaging user experience.
- Enhanced Context Awareness:
- Disambiguating queries: LLM Memory allows the LLM to understand the context of a current query. It can connect the user’s current question with previous discussions, leading to more accurate and relevant responses. Semantic Caching can leverage LLM Memory to answer generic questions like “What’s next?”
- Building on previous knowledge: the LLM can leverage past conversations to build upon existing knowledge about the user’s interests or goals. This allows it to provide more comprehensive and informative responses that go beyond basic information retrieval.
Example: Planning a Trip
Without LLM Memory:
User: “I’m planning a trip to Italy. What are some interesting places to visit?”
LLM: “Italy has many beautiful cities! Here are some popular tourist destinations: Rome, Florence, Venice…”
With LLM Memory:
User: “I’m planning a trip to Italy. I’m interested in art and history, not so much crowded places.” (Let’s assume this is the first turn of the conversation)
LLM: “Since you’re interested in art and history, how about visiting Florence? It’s known for its Renaissance art and architecture.” (LLM uses conversation history to identify user preference and suggests a relevant location)
User: “That sounds great! Are there any museums I shouldn’t miss?”
LLM (referencing conversation history): “The Uffizi Gallery and the Accademia Gallery are must-sees for art lovers in Florence.” (LLM leverages conversation history to understand the user’s specific interests within the context of the trip)
In this example, LLM memory (or conversation history) allows the LLM to personalize its response based on the user’s initial statement. It avoids generic recommendations and tailors its suggestions to the user’s expressed interests, leading to a more helpful and engaging user experience.
How does real-time RAG with Redis work?
To explain real-time RAG with Redis’ capabilities for AI, nothing beats a diagram and a short explanation:
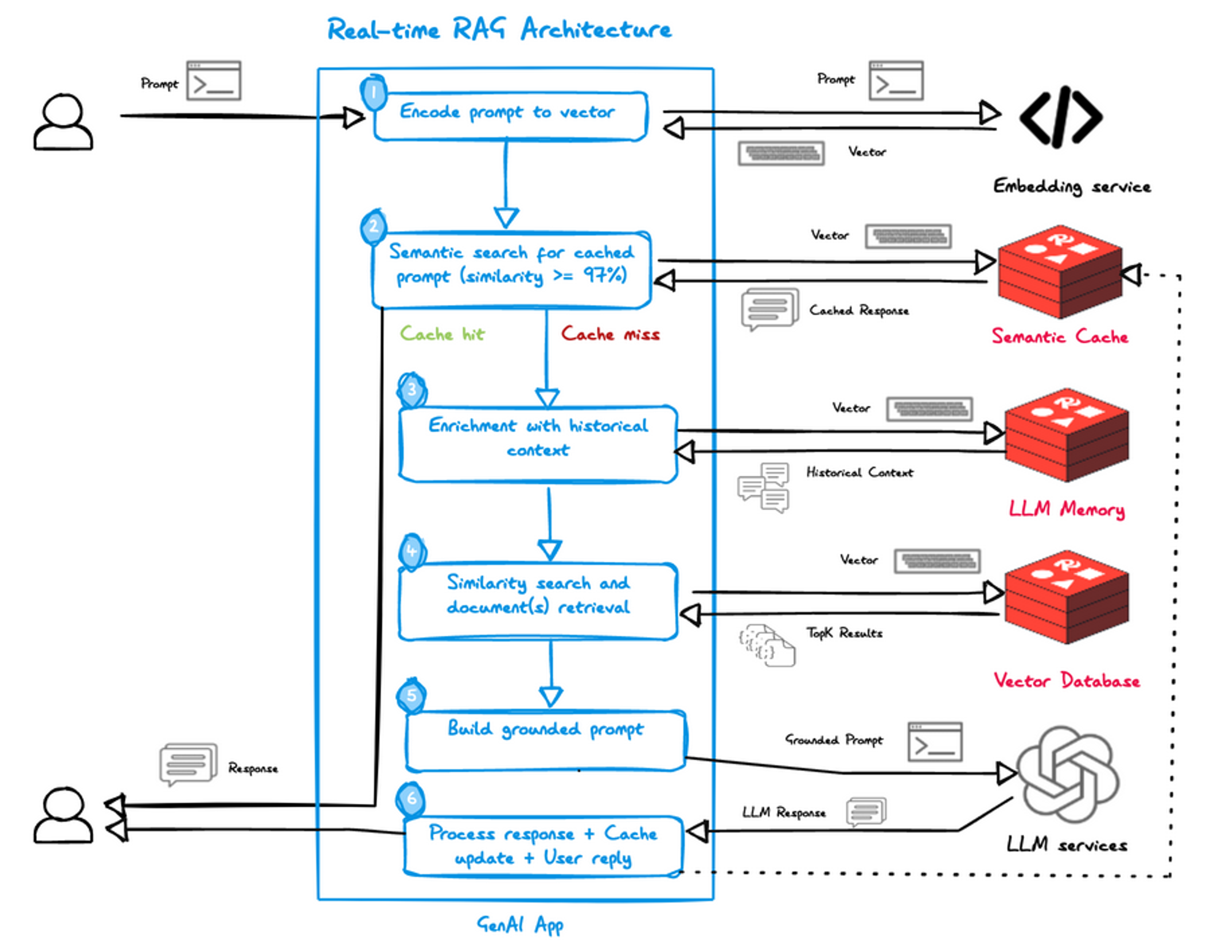
- Upon receiving the user’s prompt, the GenAI App calls an embedding service (e.g., OpenAI Ada2) to vectorize it.
- GenA AppI initiates a semantic caching operation, looking for similar responses (in this case, >= 97% similarity, but other parameters can also be used). If the app hits the cache (over 30% of the time), it just has to send the cache response back to the user.
- Upon cache miss, the GenAI App will retrieve the historical context from Redis’ LLM Memory based on the vectorized prompt.
- To get the top K documents that match the vectorized prompt, a similarity search is running in Redis (in this case, Redis is used as a real-time vector database).
- The GenAI App generates a grounded prompt based on conversation history and documents from the Vector Database and sends it to LLM.
- The response is processed and then sent to the user while the Semantic Cache is updated.
Make your AI apps faster and cheaper
Cut costs by up to 90% and lower latency with semantic caching powered by Redis.How fast is real-time RAG with Redis?
There are two scenarios that we should look at:
- Semantic caching hit — in which all LLM calls are saved, as the relevant response lies in the cache (as mentioned earlier, this makes up approximately 30% of queries to GenAI).
- Semantic caching misses (70% of the cases) — GenAI will trigger a similar process to the non-real-time RAG architecture, using Redis’ LLM Memory, real-time vector search, and real-time document retrieval.
In order to understand how real-time RAG applications perform end-to-end, let’s analyze each option.
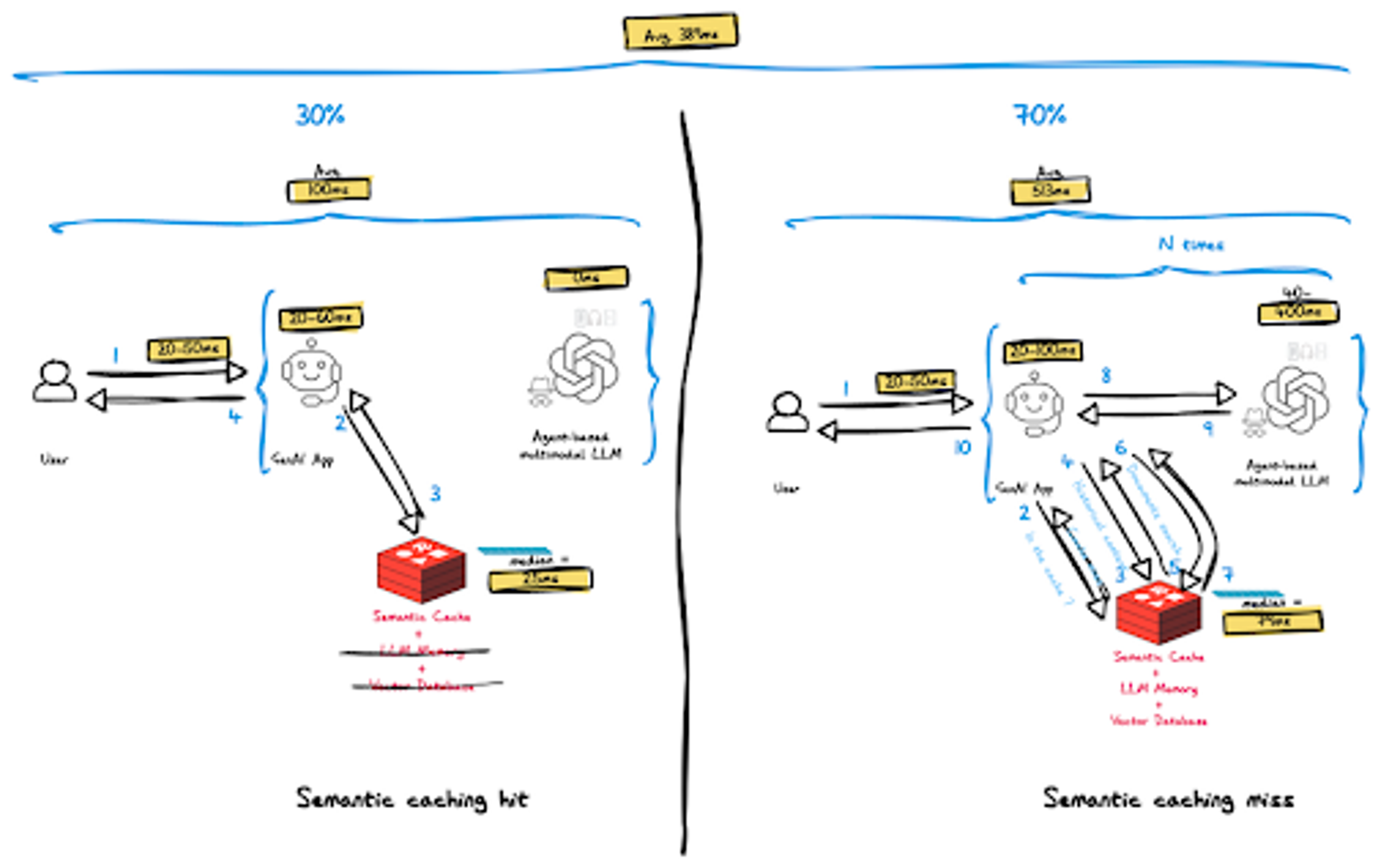
Semantic cache hit analysis
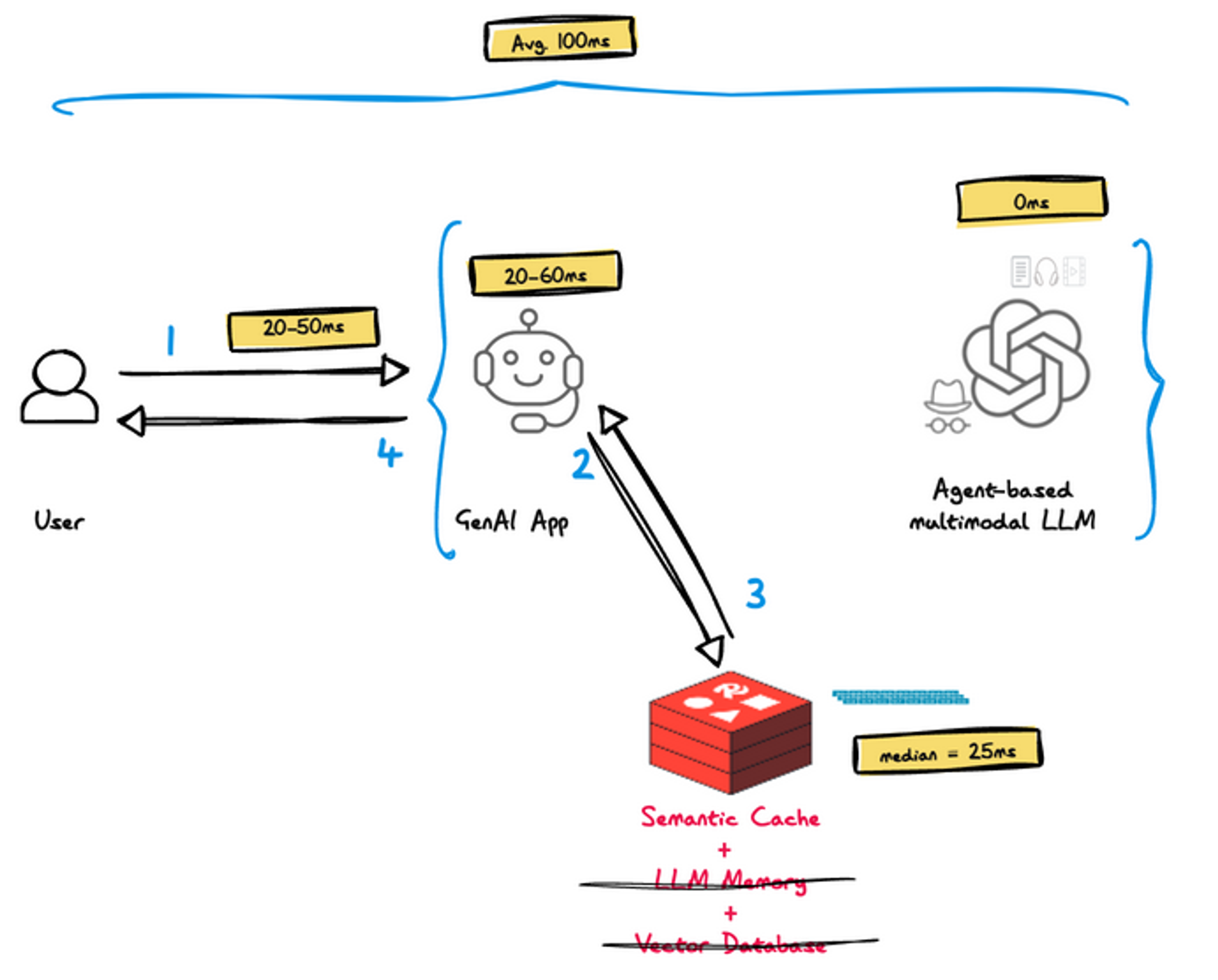
As can be seen in the diagram above, only two components are actually involved in this scenario:
- On receiving the vectorized prompt, GenAI App executes a vector search and a retrieval call to retrieve the cached response and send it back to the user. We assume this process is 33% shorter than the cache miss process, 20-60ms.
- Redis – only semantic caching is performed, corresponding to a single vector search plus a single cached response retrieval. The median latency of this operation is 40ms, and a detailed calculation can be found here.
- The network access remains unchanged and accounts for a latency of 20-50ms
- Average end-to-end latency in case of cache hit – 100ms
Semantic cache miss analysis
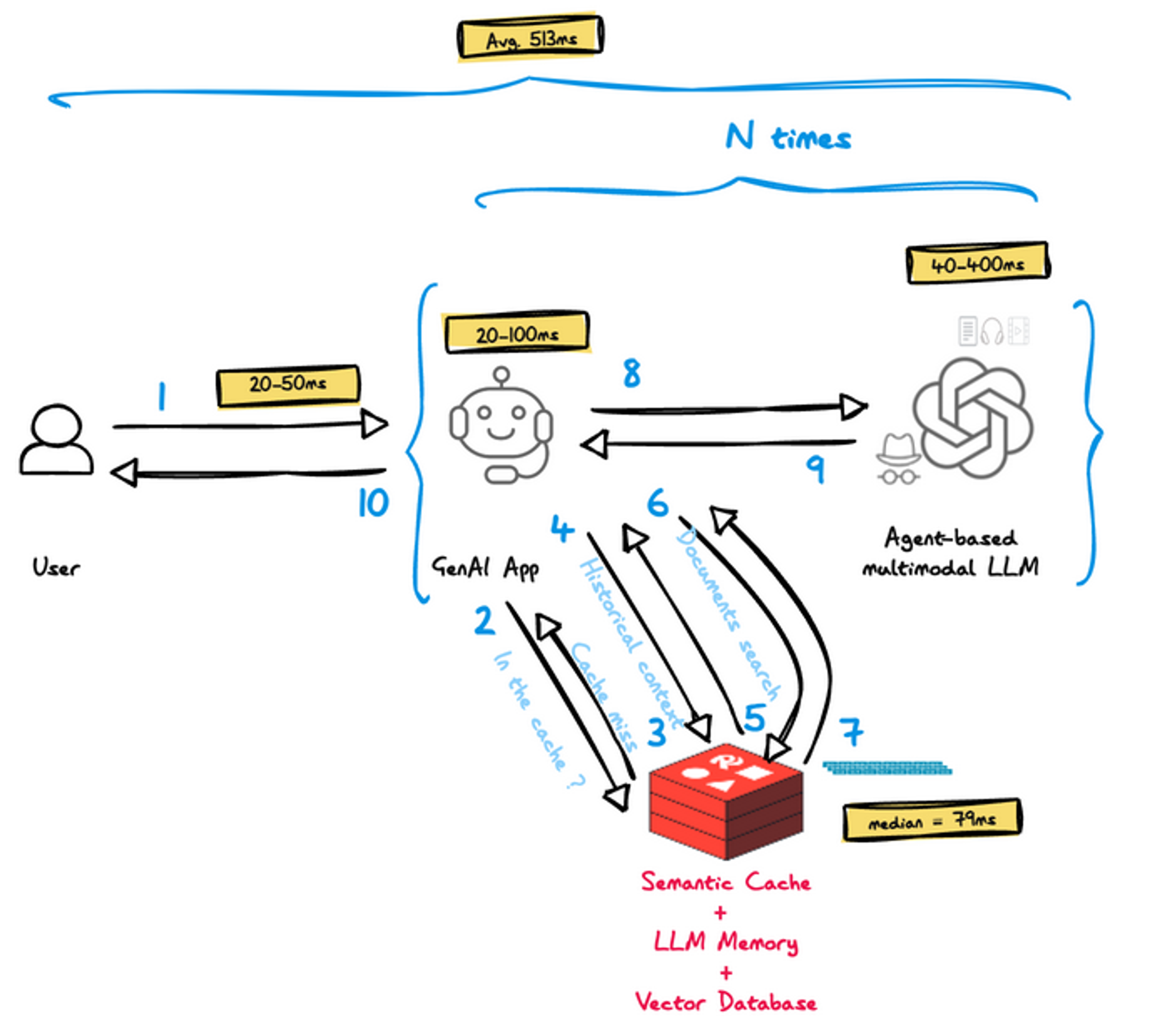
- Network – remains unchanged and accounts for a latency of 20-50ms
- GenAI App – executes all steps detailed here in case of cache miss, still within 20-100ms
- Redis – executes all of the available AI functionality of Redis: (1) Semantic Caching, (2) LLM Memory, and (3) Vector Database. We benchmarked a variety of datasets and loads scenarios and found that the median time for all combined operations (including roundtrip) is 79ms.
- LLM – based on historical context, we expect that LLM processing will improve by up to 25% due to a shorter prompt (fewer tokens) that is more relevant and accurate, i.e. 40-400ms
- Agent-based architecture — remains unchanged and may drive multiple execution cycles of components 2-4
- Average end-to-end latency – 513ms
Total real-time RAG response time analysis
RAG architectures based on Redis have an average end-to-end response time of 389ms, which is around x3.2 faster than non-real-time RAG architectures and much closer to Paul Buchheit’s 100ms Rule. This allows existing and new applications to run LLM components in their stack with minimal performance impact, if any.
Additional benefits
Apart from making sure your fast applications stay fast, Redis-based real-time RAG architecture offers these other benefits:
- Costs — with semantic caching, you can cut up to 30% of your API calls to LLM. This can be a huge savings!
- More accurate responses — LLM Memory provides context about historical conversations and helps LLM understand user preferences, build rapport, and improve responses based on previous knowledge.

Now see how this runs in Redis
Power AI apps with real-time context, vector search, and caching.Summary and next steps
The blog analyzes the response time of RAG-based architectures and explains how Redis can provide real-time end-user experiences in complex, fast-changing LLM environments. If you want to try everything discussed here, we recommend Redis Vector Library (RedisVL), a Python-based client for AI applications that uses Redis capabilities for real-time RAG (Semantic Caching, LLM Memory, and Vector Database). RedisVL works with your Redis Cloud instance or your self-deployed Redis Stack.
Appendix: Detailed E2E latency analysis
In this appendix, you’ll find details on how we calculated end-to-end response times for RAG (real-time and non-real-time). It’s based on a comprehensive benchmark we did and will soon publish, which we ran across four types of vector datasets:
- glove-100-angular (recall>=0.95)
- gist-960-euclidean (recall>=0.98)
- deep-image-96-angular (recall>=0.99)
- dbpedia-openai-1M-angular (recall>=0.99))
More info on these datasets will be available once the benchmark is out.
The non-real-time RAG
For the non-real-time RAG, we averaged the results across all disk-based databases (special purpose and general purpose). We took the normalized median value across four different sets of tests and all the vendors under test because of the big data skew.
| Component | Latency |
|---|---|
| Network round-trip | (20+50)/2 = 35ms |
| LLM | (50+500)/2 = 275ms |
| GenAI App *assuming 20ms when no other services are called and 100ms otherwise | (20+100)/2=60ms |
| Vector database *assuming one vector/hybrid search + 10 docs | One vector search query (we took the median value across low and high loads) – 63ms10x document retrieval – 10x50ms = 500msTotal – 563ms |
| The agent-based architecture assumes 1/3 of the calls to LLM trigger agent processing, which triggers an application call from LLM and another iteration of data retrieval and LLM call. | 33% x (LLM + App + VectorDB) |
| Total | 35 + {275+60+563}⅔ + {275+60+563}2*⅓ = 1232 |
The real-time RAG
For the real-time RAG, we looked at two scenarios: cache hit (using semantic caching) and cache miss. Based on this research, we calculated a weighted average assuming that 30% of queries would hit the cache (and 70% would miss it). We took the Redis median latency value across all the datasets under test in the benchmark.
Semantic caching hit
| Component | Latency |
|---|---|
| Best case | |
| Network round-trip | (20+50)/2 = 35ms |
| GenAI App *Assuming a cache hit would result in a 33% reduction in app processing time | 40ms |
| Redis Semantic Caching | One vector search query (we took the median value across low and high loads) – 24.6ms1x document retrieval – 1×0.5msTotal – 25ms |
| Total | 35+40+25 = 100ms |
Semantic caching miss
| Component | Latency |
|---|---|
| Best case | |
| Network round-trip | 35ms |
| LLM*Based on historical context, we assume that LLM processing will improve by 25% due to a shorter prompt (much fewer tokens) that is more accurate and relevant | (40+400)/2 =220ms |
| GenAI App *assuming 20ms when no other services are called and 100ms otherwise | (20+100)/2=60ms |
| Redis | Semantic cache miss – 24.6msLLM Memory search (24.6ms) + 5 context retrievals (5x 0.5ms ) = 27.1msVector search (24.6ms) + 5 context retrievals (5x 0.5ms ) = 27.1msTotal – 24.6+27.1+27.1 = 79ms |
| The agent-based architecture assumes 1/3 of the calls to LLM trigger agent processing, which triggers an application call from LLM and another iteration of data retrieval and LLM call. | 33% x (LLM + App + Redis) |
| Total | 35 + {220+60+79}⅔ + {220+60+79}2*⅓ = 513ms |
End-to-end application latency
The weighted average of cache hits and misses is calculated as follows: 30% * 100ms + 70% * 513ms = 389ms
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.