Blog
How To Build a Real-Time Product Recommendation System Using Redis and DocArray

This tutorial helps you build a real-time product recommendation system for an e-commerce system using content-based filtering and vector similarity search. Follow along to learn the essential steps and how it works.
Recommendation systems are an important technology for most online businesses and for e-commerce sites in particular. They’re an essential element in generating good conversion and maintaining customer loyalty.
A recommendation system typically shows items to users based on their profiles and preferences and by observing their actions (such as buying, liking, or viewing items).
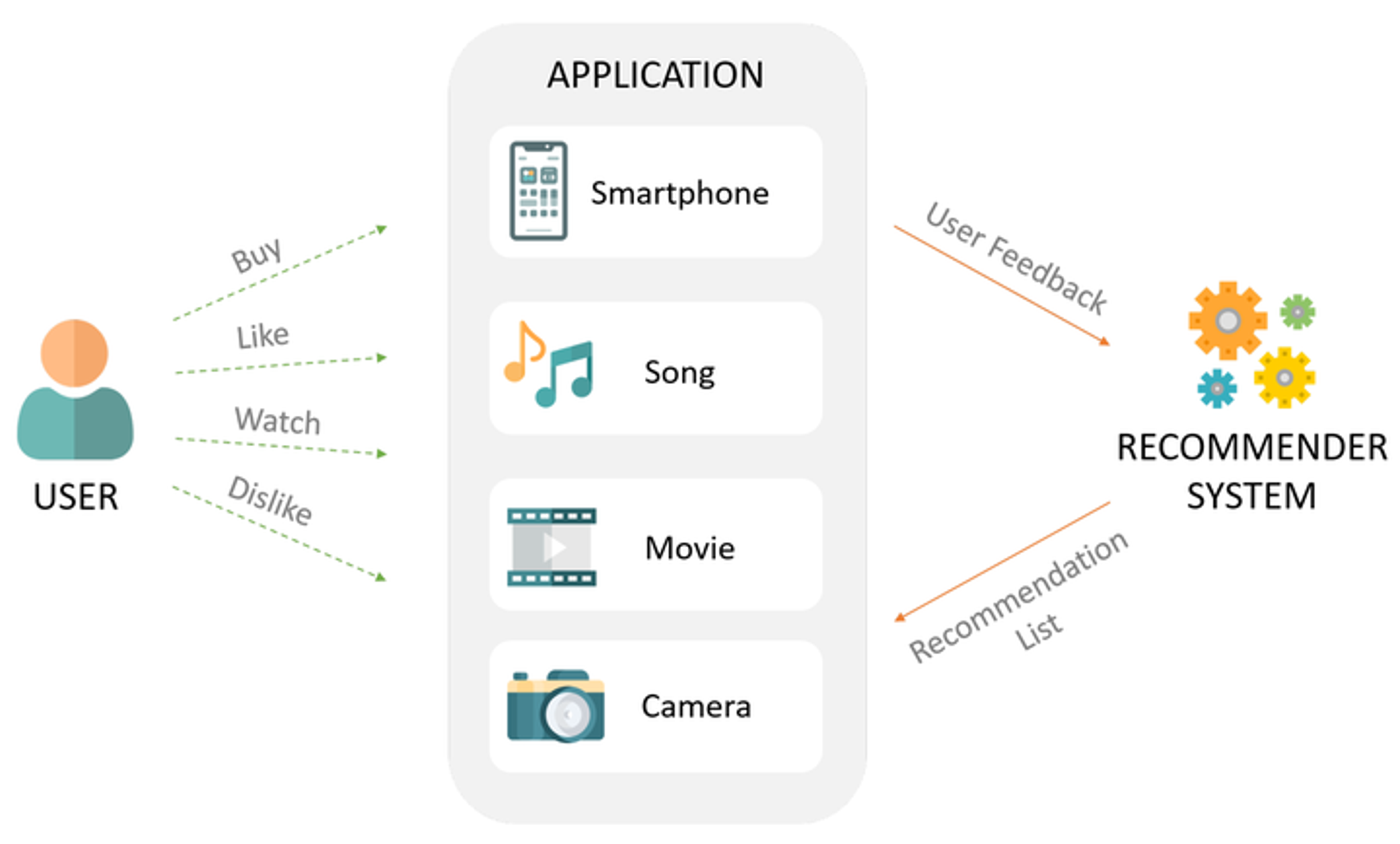
Consider the challenges involved in building a recommendation system for a modern e-commerce site. This is just a subset of the issues to consider:
- Customization: Customers want to filter results, such as by price range, brand, and size. Our system should recommend products only within these parameters.
- Multiple modalities: A product listing is more than a text description. It can also contain images, video, audio, and 3D mesh, for example. All available data modalities should be exploited when making recommendations.
- Latency: Customers expect recommendations to appear quickly. If the system’s recommendations aren’t returned immediately, they’re irrelevant.
- Data volume: The more products and customers the site has, the harder it is to recommend products efficiently. Computing recommendations should stay fast even with big datasets.
As these requirements evolve, approaches to building recommendation systems need to evolve as well. In this blog post, we show you how to build a real-time product recommendation system with respect to user-defined filters using the latest vector search technology. The tool suite includes Redis and DocArray, but the methodology is relevant no matter which tools you employ.
Recommendation systems basics
As with any other computing problem, there are multiple approaches to building recommendation systems and tools to support each effort. They include:
- Collaborative filtering: The system predicts items relevant to the user based on the preferences of similar users.
- Content-based filtering: The system models the user’s interests as feature vectors and predicts relevant items based on the similarity between vectors.
- Hybrid approaches: The system combines collaborative filtering, content-based filtering, and other approaches.
This blog post focuses on improving the content-based filtering approach. If you’re new to this topic, it may help to read Google’s overview of content-based filtering first.
There are two important considerations when implementing content-based filtering:
First, when you model the user and items as a feature vector, it’s important to exploit all modalities of the data. Simply relying on keywords or a set of engineered features might not efficiently represent complex data.
That’s why state-of-the-art AI models are important, as they represent complex, multimodal data as vector embeddings.
One of the best-known models to represent both text and image data is CLIP. Therefore, in this tutorial, we use CLIP-as-service as the inference engine that powers our recommendations.
Also, computing vector similarity can be slow and costly if not performed efficiently. Our application requirements (to respect user filters and deliver low-latency recommendations) make it impractical to pre-compute similarity between items and user profiles in batch jobs. That’s why it’s crucial to compute vector similarity in real-time, using efficient techniques such as Hierarchical Navigable Small World (HNSW).
These techniques are implemented in vector databases. Redis offers vector search capabilities in RediSearch 2.4. And since Redis is an in-memory database, recommending items is both fast and performed in a real-time context.
With feature representation and computing vector similarity covered, we still need a data structure to bridge the gap between our multimodal data and the vector database. For that, we use DocArray. Think of DocArray as a universal vector database client with support for multimodal data. It has a Pythonic interface that makes it easy to build a recommendation system in just a few lines of code.

Build fast, accurate AI apps that scale
Get started with Redis for real-time AI context and retrieval.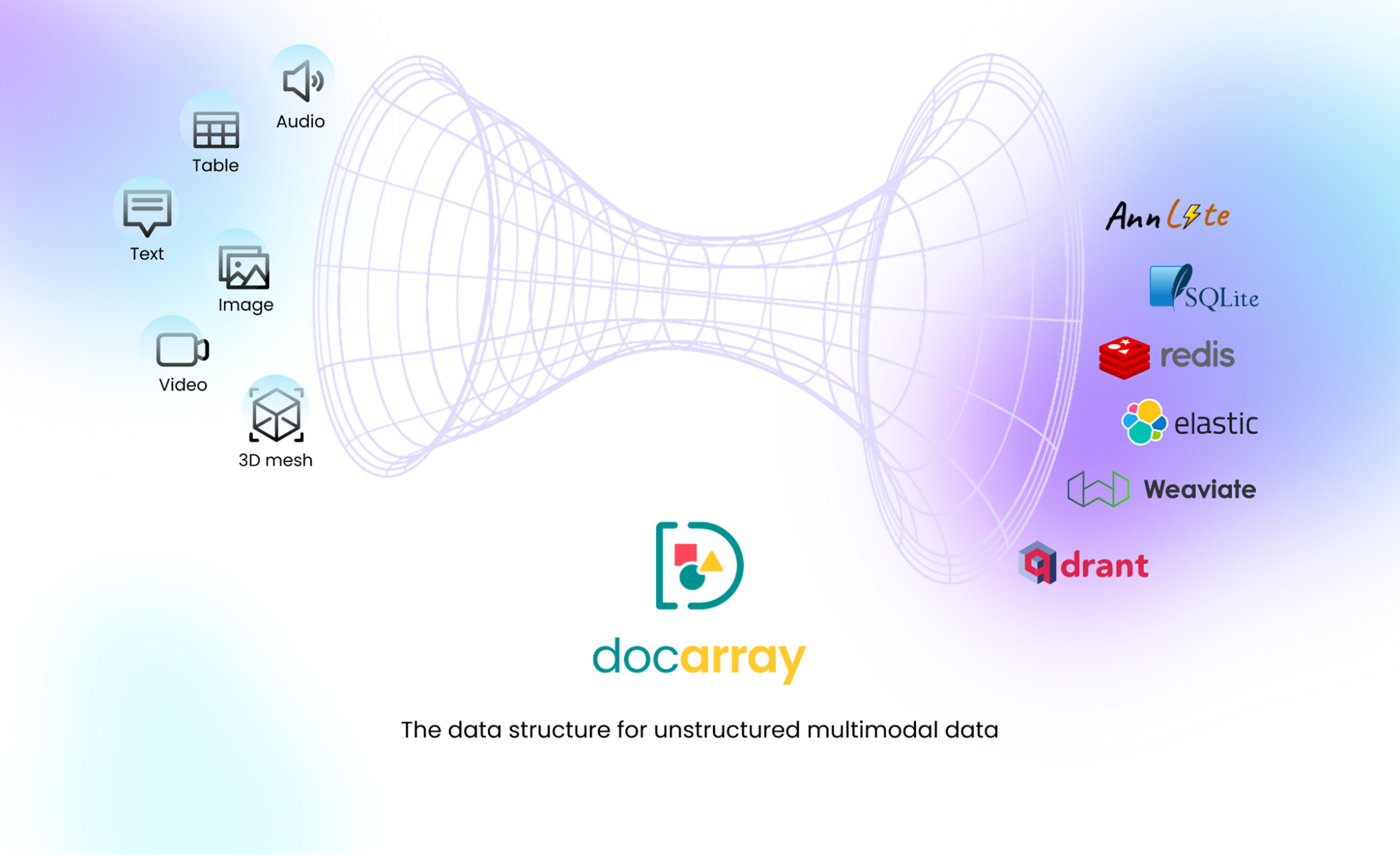
Designing the solution
We have assembled the tools for this application: Redis for Vector Similarity Search, CLIP-as-service to encode visual data, and DocArray to represent multimodal documents and connect to Redis. In this tutorial, we apply these technologies to build a content-based filtering recommendation system.
The procedure is as follows:
- Load the dataset into DocArray format.
- Model products by encoding product images using CLIP-as-service.
- Model the user profile by computing the weighted average of the last k viewed products’ embeddings.
- Use DocArray to load the product data.
- Index the product data in Redis.
- Use Redis Vector Similarity Search to recommend the most similar items to the user’s view history while also filtering those results to respect user preferences.
In the instruction that follows, the data we use for product recommendations comes from the Amazon Berkeley Objects Dataset, a dataset of Amazon products with metadata, catalog images, and 3D models.
Setup
The first step is to provision a Redis instance. You can create a local Redis instance using Docker:
Next, we need to install DocArray, Jina, and clip-client:
That’s all the setup we need. Now we’re ready to start exploring with data.
Dataset exploration
The Amazon Berkeley Objects Dataset consists of product items accompanied by images and metadata such as brand, country, and color. It represents the inventory of an e-commerce website.

For the purposes of this tutorial, we can download a subset of this dataset from Jina Cloud, pre-processed in DocArray format.
First, authenticate to Jina Cloud using the terminal:
Next, download the dataset:
This returns a DocumentArray object containing samples from the Amazon Berkeley Objects dataset. We get an overview using the summary() method:
Or we can display the images of the first items using the [plot_image_sprites()](<https://docarray.jina.ai/api/docarray.array.document/#docarray.array.document.DocumentArray.plot_image_sprites>) method.

Each product contains the metadata information in the tags field.
Let’s take a look at the content of tags:
Later, we use this metadata to filter recommendations according to the user’s preferences.
Adding embeddings
To create the vector embeddings for our dataset, we first need a token for CLIP-as-service inference:
Then we can start to encode the data. Be sure to pass the created token to the Client object:
Encoding the dataset takes a few minutes. When it’s done, we proceed with the next steps.

Search meaning, not just keywords
Use Redis vector search to deliver smarter results instantly.Connecting to Redis
At this point, our data is encoded and ready to index.
To do so, we create a DocumentArray instance connected to our Redis server. It’s important to specify the correct embedding dimensions and filter columns:
For more information, see Redis Document Store in DocArray.
Generating recommendations
In order to understand the recommendation logic, consider the following example: Eleanor decided to add a scarf to her wardrobe and looked into several ones in our shop. Her favorite color is navy, and she has to keep the budget under $25.
Our recommendation function should allow specifying those requirements and recommend items based on the view history, with emphasis on the most recently viewed items.
Thus, we combine embeddings of the latest viewed items by giving more weight to the recent items:
Let’s implement a function that recommends products based on a weighted average of the embeddings of recently-viewed items, taking user filters into account. That is, in recommended items, we want to emphasize the items the shopper viewed most recently.
Thus, we combine embeddings of the latest viewed items by giving more weight to the recent items:
Adding recommendations to product views
To show relevant recommendations when a customer views a product, we need three steps:
- Show the product’s image and description.
- Add the product to the list of last k viewed products.
- Show recommendations related to the last k viewed products.
We can achieve that with the following function:
Viewing the results
Let’s try it out a few times. First, let’s view the first item in the store and the recommendations for it:
That displays an attractive scarf, labeled as ” Thirty-Five Kent Men’s Cashmere Zig Zag Scarf, Blue”:

… and the accompanying recommendations:

How well do they meet the user’s filter?
Let’s check the third item in the recommendation list and apply a filter color=’Navy‘ to ensure a better match:
…which generates a better item display and recommendations:
Thirty-Five Kent Men’s Cashmere Zig Zag Scarf, Blue:


Now the recommendation function returns the most visually similar items to scarves that also satisfy the filter color='Navy'.
Success! And, possibly, a new e-commerce sale.
Putting it all together
The instructions above are a brief overview to demonstrate the building blocks for a process to recommend products in an online store.
You’re welcome to take it further. We created a GitHub repository with source code for a product store interface with the same dataset and technique we just showed.

This demonstration just showed you how Vector Similarity Search can offer low-latency real-time recommendations that respect user preferences and filter selection.
But how fast is it? Let’s look at the latency numbers for recommendation queries. You can find logs in the command line console:
This means computing recommendations takes about 10 milliseconds!
Of course, there’s still room for improvement, especially when it comes to quality. For example, we can come up with more sophisticated ways to model the user’s profile and interests. We could also incorporate more types of data, such as 3D mesh and video. That’s left as an exercise to the reader.

Now see how this runs in Redis
Power AI apps with real-time context, vector search, and caching.Shopping for better answers
Vector Similarity Search is an essential technique for implementing recommendations in a real-time context.
Your next steps:
- Use state-of-the-art AI models to encode multimodal data into vector representations.
- Use a vector database to compute vector similarity in a real-time context. For low latency, an in-memory database like Redis is ideal.
- Consult the Redis documentation for more information.
Use DocArray as a convenient data structure for handling multimodal data as well as for interfacing with the vector database. Consult the DocArray documentation to get started and get connected with the Redis AI/ML team for more information on Redis Vector Search.
Get started with the Redis Cloud free tier.
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.