
Our newly launched Redis Enterprise 5.0 introduced support for the Open Source (OSS) cluster API, which allows a Redis Enterprise cluster to scale infinitely and in a linear manner by just adding shards and nodes. The OSS cluster API relies on the intelligence of the clients to decide to which shard/node to send the request to based on the key part of the key/value item and a hashing function shared across the clients and the cluster. This post explains how Redis Enterprise works with the OSS cluster API and validates the infinite linear performance scalability.
For those of you who are not familiar with the Redis Enterprise architecture, let’s start with some short background:
Redis Enterprise architecture in a nutshell
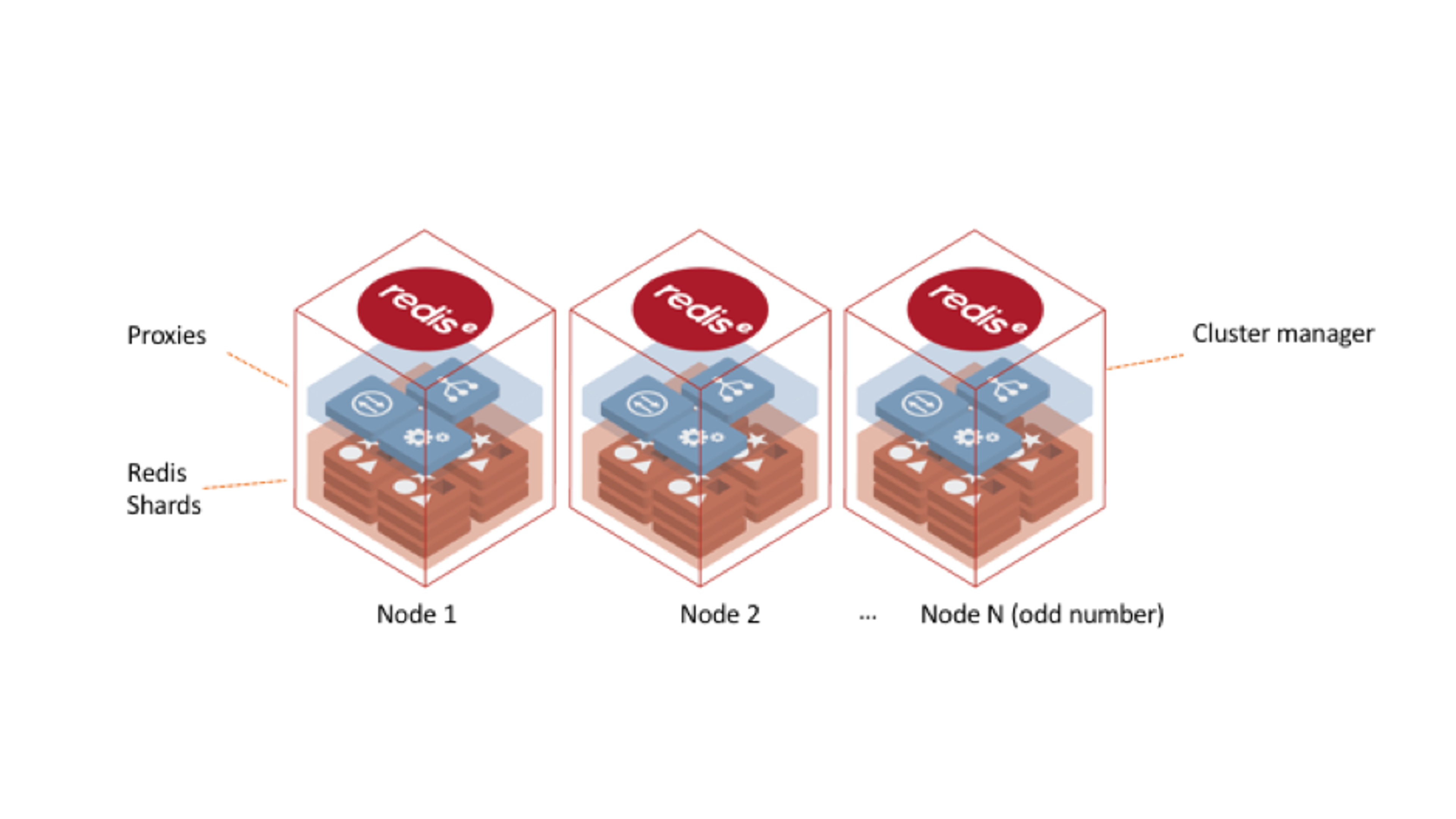
A cluster, in Redis Enterprise terms, is a set of cloud instances, virtual machine/container nodes or bare-metal servers that allows you to create any number of Redis databases (A database in Redis Enterprise terminology is the entity that manages your entire dataset across multiple Redis shards/instances. Don’t confuse this with the databases inside every Redis instance that you can leverage to do some segmentation in your keyspace using the Redis SELECT command.) in the memory pool that is shared across the set. The cluster has a symmetric shared-nothing architecture, complete separation between the data-path and control & management-path, and it includes the following main components:
- Redis Shards (data-path) – a Redis instance with either a master or slave role
- Zero-latency Proxy (data-path) – built on a cut-through, multi-threaded, stateless architecture and is responsible for hiding cluster complexity, enhancing security (SSL, authentication, DDoS protection) and improving performance (TCP-less, connection management and pipelining)
- Cluster Manager (control & management-path) – built from a set of distributed processes that reside on each node of the cluster. The cluster manager takes care of cluster configuration activities, provisioning requests, resource management and monitoring, as well as acting as a resource watchdog and completely offloading the task of having Redis shards manage the health of other shards in the cluster or make failover decisions
A database in the Redis Enterprise cluster can be created in any one of the configurations below:
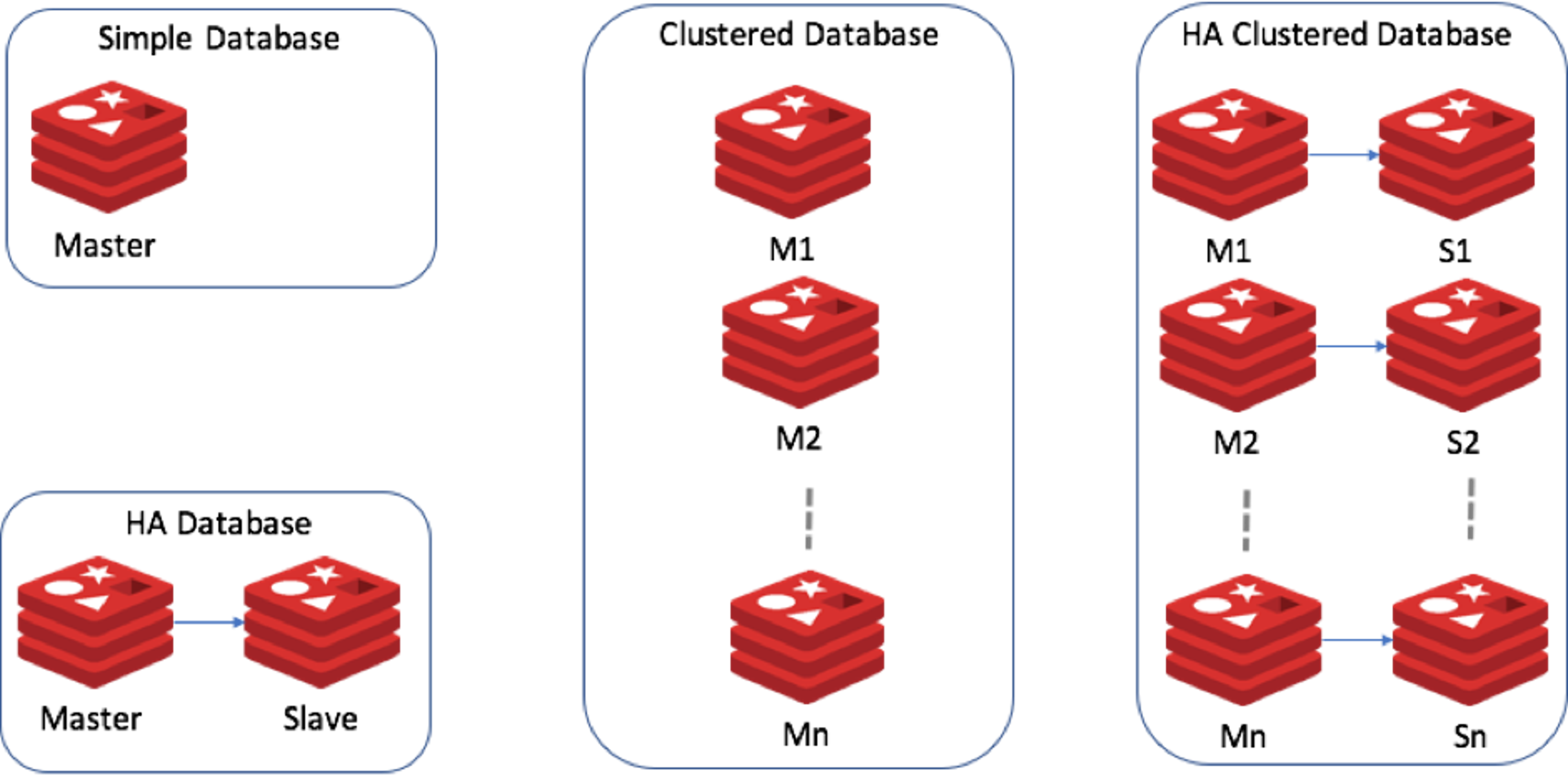
Based on its strong multi-tenant technology, a Redis Enterprise cluster can manage multiple databases of different types on the same cluster resources in a completely isolated manner.
Redis Enterprise with the OSS cluster API
In order to utilize the new OSS cluster API, you should use the following properties when creating a database with the Redis Enterprise API:
- “shards_placement”: “sparse” – distributes shards across Redis Enterprise cluster nodes
- “proxy_policy”: “all-master-shards” – assigns a proxy on every node that has at least one master shard
- “oss_cluster”: “true” – make the database accessible through the OSS cluster API
This will create a clustered database with properties similar to those shown below:
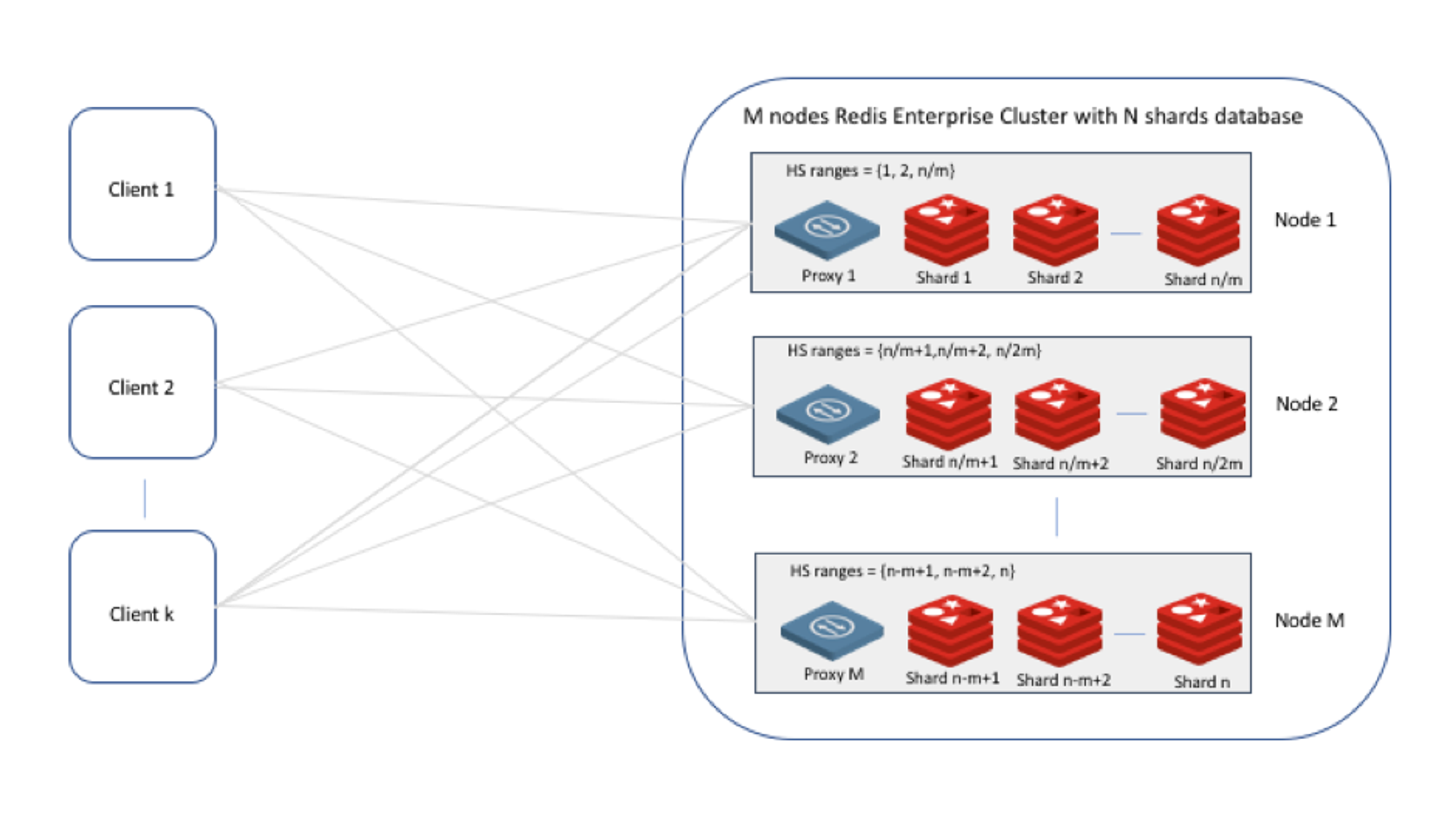
As you can see:
- From the point of view of the Redis client, each proxy represents a range of hash-slots (HSs) equal to the sum of all the HSs served by the master shards hosted on the node of the proxy. In other words, from the point of view of the client, the proxy represents one big Redis instance with a master role
- As in the OSS cluster, the client (a standard OSS client) sends requests to the relevant proxy based on the key of a key/value item and the Redis cluster hashing function.
- Once the request arrives to the proxy, it is forwarded to the relevant shard on the node by applying the same hashing function.
- In the case of a cluster topology change, i.e. shard migration, master/slave failover, etc., the proxy updates the HSs it manages and if necessary redirects requests from the clients to another node in the cluster (using MOVED reply).
Building the test environment
With that in mind, we decided to build a test environment on AWS to validate whether Redis Enterprise can really scale infinitely and in a linear manner. Since we planned to have some serious load, we decided to use EC2 m4.16xlarge instances (64 cores, 256GB RAM) for the cluster nodes and c4.8xlarge instances (36 cores, 60GB RAM) for running memtier_benchmark, an open source multi-threaded load generation tool.
Using multiple instances of memtier_benchmark is a must, since in many cases a single Redis Enterprise node can deal with more traffic than the volume a single memtier_benchmark instance can generate. This approach also allows us to avoid the network bandwidth and packet per second limitations of a single NIC and makes it easy to increase the traffic load in a step by step (instance by instance) manner.
This is what our final setup looks like:
- 6x m4.16xlarge instances for the Redis Enterprise cluster nodes:

- 8x c4.8xlarge instances running memtier_benchmark

- We used the Ubuntu Server 16.04 as our operating system and ensured that the machines were set up to support Enhanced Networking. All instances were placed in the same VPC, availability zone, network subnet and placement group.
Creating and tuning a clustered database
We created a 192-shard clustered Redis database using the Redis Enterprise API with the following parameters:
{
"name": "api-benchmark",
"replication": false,
"port" : 12345,
"sharding": true,
"shards_count" : 192,
"version": "4.0",
"memory_size": 100000000000,
"type": "redis",
"oss_cluster":true,
"proxy_policy": "all-master-shards",>
"shards_placement": "sparse",
"shard_key_regex": [{"regex": ".*{(?.*)}.*"}, {"regex": "(?.*)"}]
}
> curl -k -X POST -u ":" -H "Content-Type: application/json" -d @create_db.json https://localhost:9443/v1/bdbs
We tuned the proxy on each node to cope with the expected load by setting the number of proxy threads to 24:
> rladmin tune proxy all max_threads 24
> rladmin tune proxy all threads 24
Populating the database and running tests
We used the new version of memtier_benchmark that supports the OSS cluster API to first populate the database with around 10 million items, and then run the tests.
Here are the memtier_benchmark parameters we used during our population and benchmarking stages:
- Key pattern: We used a unified random access pattern for reads and writes (−−key-pattern=R:R).
- Number of items: We had to find a combination in which to populate and access all the hash-slots as equally as possible. This was achieved by combining the number of requests with a key range per slot (−−key-minimum=1 −−key-maximum=611 −−num_requests=40042496). Given the random access, it was possible to hit the same key multiple times during the population, which is why we executed more requests than our target of 10 million items.
- Data size: We tested both 100B and 500B item (value) sizes.
- Write/read ratio: We tested a mixed workload (−−ratio=1:1), a read-only workload (−−ratio=0:1) and a write-only workload (−−ratio=1:0).
- Pipelining: We used a realistic pipeline size for all our tests, i.e. −−pipeline=9.
- Number of clients and number of threads: The number of connections created by our memtier_benchmark instance was equal to the multiplication of the number of threads (-t) and the number of clients per thread (-c). In our final setup, each one of the 8 benchmark client machines ran 40 clients over between 12 to 15 threads, creating more than 3000 connections to the cluster in total.
Here is a memtier_benchmark command line example:
> memtier_benchmark -s $DB_SERVER -p $DB_PORT
--pipeline=$PIPELINE_SIZE -c $NUM_CLIENTS -t $NUM_THREADS
-d $DATA_SIZE --key-minimum=$KEY_MIN
--key-maximum=$MAX_KEYS_PER_SLOT --key-pattern=R:R
--ratio=$WR_RATIO --run-count=1 --requests=$NUM_REQ
--out-file=$OUT_FILE --oss-cluster
Test results
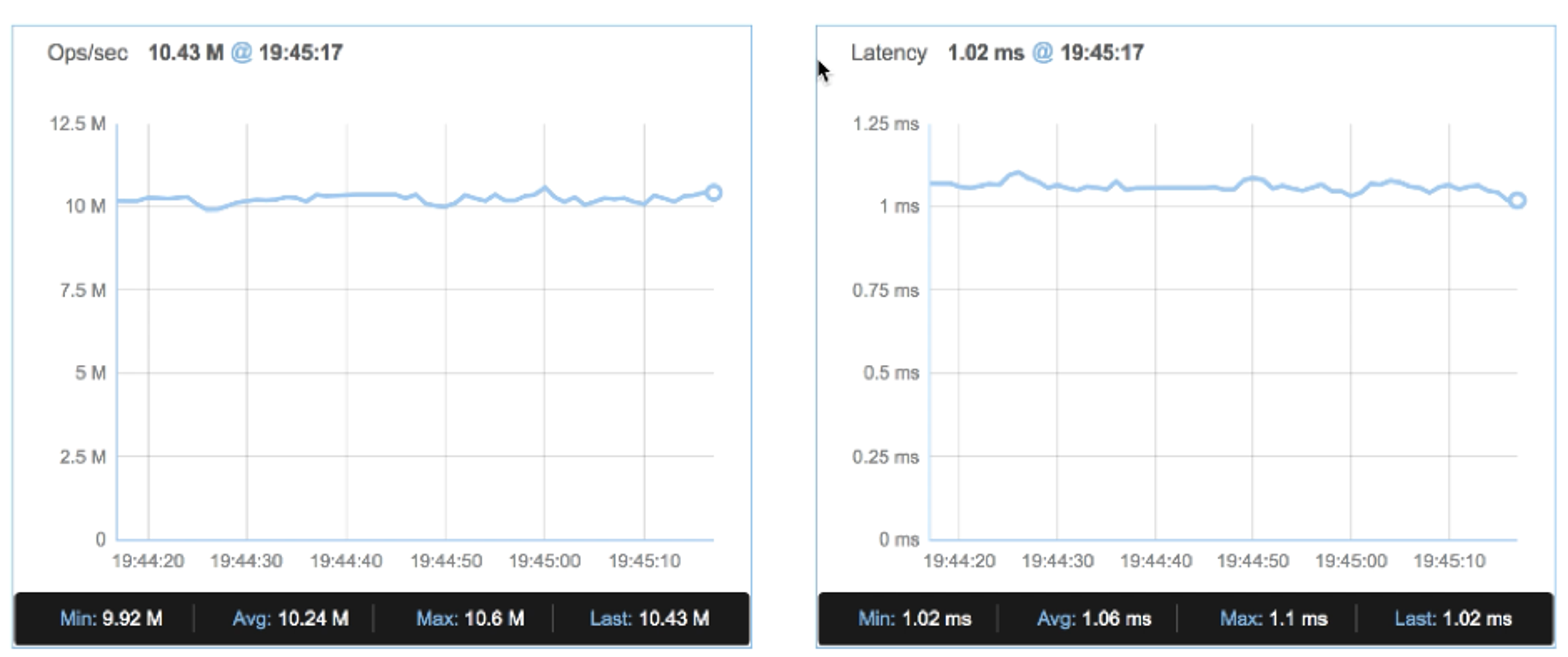
Our final setup ran a 192-shard database over only 6 nodes on the Redis Enterprise cluster and demonstrated outstanding results: over 10 million ops/sec at a slightly higher than 1msec latency! Here is a screenshot taken from the Redis Enterprise UI:
We conducted this experiment in order to validate that the shared-nothing architecture of Redis Enterprise can scale linearly thanks to the new OSS cluster API that was introduced in Redis Enterprise 5.0. Our experiment included:
- Benchmarking a 32-shard database on a single node Redis Enterprise cluster
- Benchmarking a 64-shard database on a two-node Redis Enterprise cluster
- Benchmarking a 192-shard database on a 6-node Redis Enterprise cluster
We found linear performance scalability when scaling from a 1-node cluster to a 6-node cluster, as shown in the following graph:
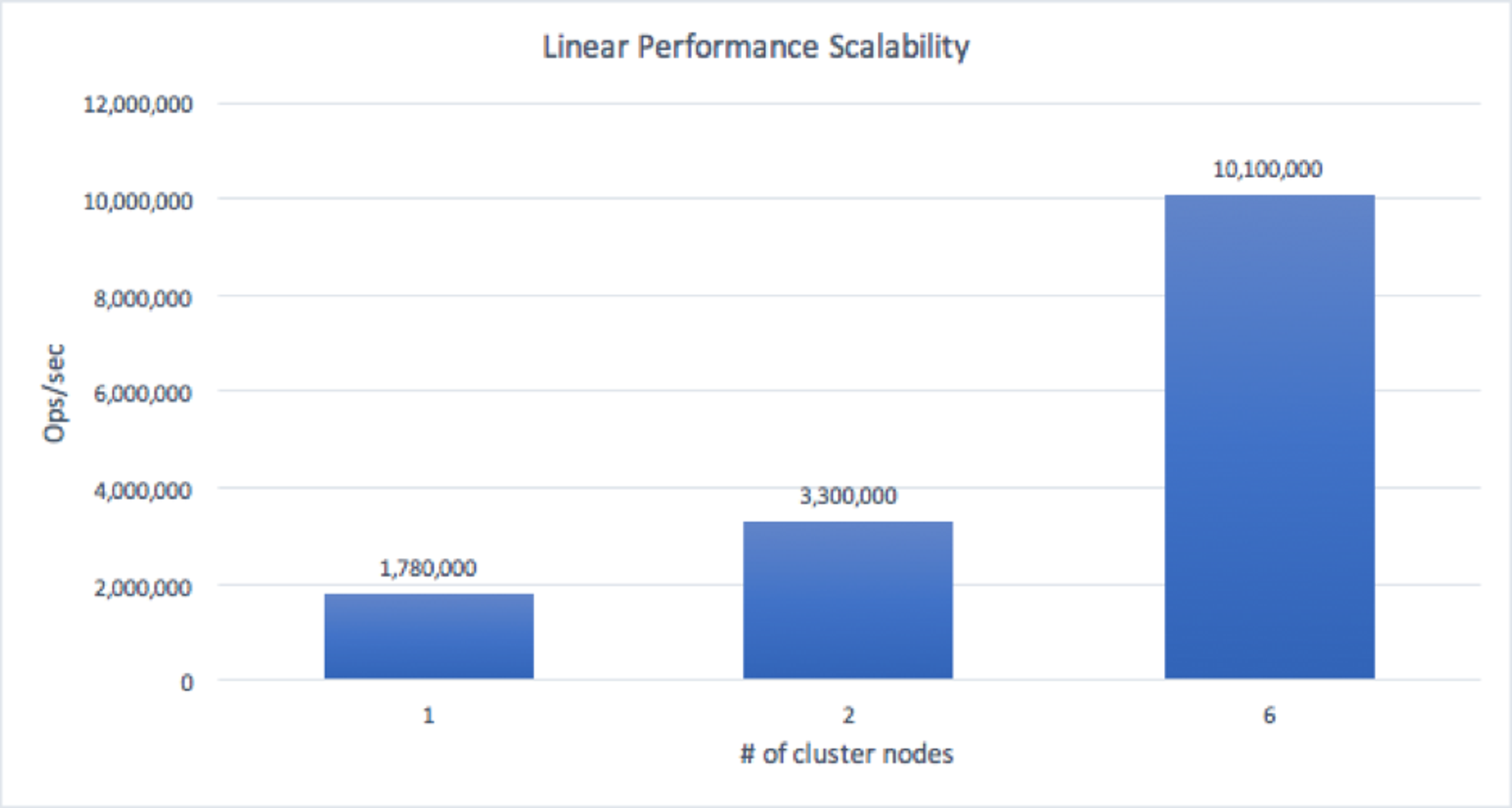
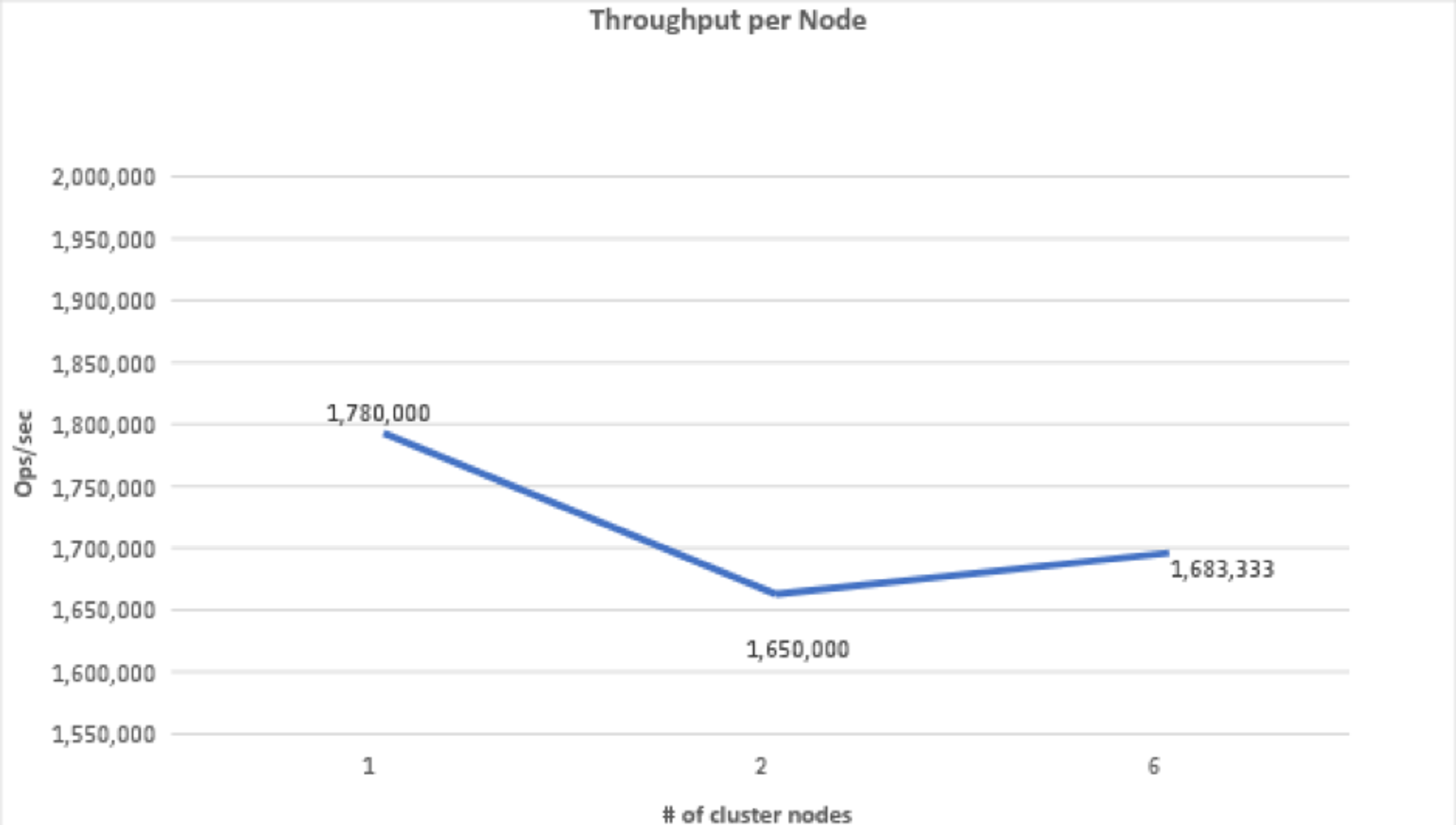
A deeper analysis of these results indicates that the throughput per node did not change by more than 10% when scaling from a single node cluster to a two-node cluster and then to a 6-node cluster. We believe that these changes in performance between the tests might be related to different resource conditions (network, VM, etc.) on each test iteration.
Summary
With the introduction of the OSS cluster API, Redis Enterprise 5.0 can easily scale linearly by just adding shards to the database and nodes to the cluster, as proven by this benchmark. We plan to continue breaking performance records in the database space, but we wanted to share this for re:invent 2017, so we stopped here. Please stay tuned!
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.