
ChatGPT Memory responds to context length limitations in large language models (LLMs) used in AI applications. The ChatGPT package uses Redis as a vector database to cache historical user interactions per session, which provides an adaptive prompt creation mechanism based on the current context.
ChatGPT, the AI chatbot created by OpenAI, has revolutionized the realm of intelligent chat-based applications. Its human-like responses and capabilities, derived from the sophisticated GPT-3.5 and GPT-4 large language models (LLMs) and fine-tuned using reinforcement learning through human feedback (RLHF), took the world by storm since its launch in November 2022. The hype machine is in full force.
Some ChatGPT interactions are entertainingly silly, some uses are worrisome, and they raise ethical concerns that affect many professions.
However, everyone takes for granted that this technology inevitably will have a significant impact. For example, Microsoft is already using these models to provide an AI-based coding assistant (GitHub Copilot) as well as to support its search engine (Bing). Duolingo and Khan Academy are using them to power new learning experiences. And Be My Eyes uses these tools to offer an AI assistant that helps visually impaired people.
Despite the success of these language models, they have technical limitations. In particular, software developers who are exploring what they can accomplish with ChatGPT are discovering issues with the amount of context they can keep track of in an ongoing conversation.
The context length is the amount of information from a previous conversation that a language model can use to understand and respond to. One analogy is the number of books that an advisor has read and from which they can offer practical advice. Even if the library is huge, it is not infinite.
It is important to make good use of the context length to create truly powerful LLM-based applications. You need to make clever use of the available context length of the model. That’s especially so because of cost, latency, and model reliability, all of which are influenced by the amount of text sent and received to an LLM API such as OpenAI’s.
To resolve the issues with limited context length in AI models like ChatGPT and GPT-4, we can attach an external source of memory for the model to use. This can significantly boost the model’s effective context length and is particularly important for advanced applications powered by transformer-based LLM models. Here, we share how we used Redis’ vector database in our chatgpt-memory project to create an intelligent memory management method.
Why context length matters
Let’s start by taking a deeper look into why context length matters.
ChatGPT’s context length increased from 4,096 tokens to 32,768 tokens with the advent of GPT-4. The costs for using OpenAI’s APIs for ChatGPT or GPT-4 are calculated based on the number of conversations; you can find more details on its pricing page. Hence, there is a tradeoff between using more tokens to process longer documents and using relatively smaller prompts to minimize cost.
However, truly powerful applications require a large amount of context length.
Theoretically, integrating memory by caching historical interactions in a vector database (i.e. Redis vector database) with the LLM chatbot can provide an infinite amount of context. Langchain, a popular library for building intelligent LLM-based applications, already provides such memory implementations. However, these are currently heuristic-based, using either all the conversation history or only the last k messages.
While this behavior may change, the approach is non-adaptive. For example, if the user changes a topic mid-conversation but then comes back to the subject, the simplistic ChatGPT memory approaches might fail to provide the true relevant context from past interactions. One possible cause for such a scenario is token overflow. Precisely, the historic interactions relevant to the current message lie so far back in the conversational history that it isn’t possible to fit them into the input text. Furthermore, since the simplistic ChatGPT memory approaches require a value of k to adhere to the input text limit of ChatGPT, such interactions are more likely fall outside the last k messages.
The range of topics in which ChatGPT can provide helpful personalized suggestions is limited. A more expansive and diverse range of topics would be desirable for a more effective and versatile conversational system.
To tackle this problem, we present the ChatGPT Memory project. ChatGPT Memory uses the Redis vector database to store an embedded conversation history of past user-bot interactions. It then uses vector search inside the embedding space to “intelligently” look up historical interactions related to the current user message. That helps the chatbot recall essential prior interactions by incorporating them into the current prompt.
This approach is more adaptive than the current default behavior because it only retrieves the previous k messages relevant to the current message from the entire history. We can add more relevant context to the prompt and never run out of token length. ChatGPT Memory provides adaptive memory, which overcomes the token limit constraints of heuristic buffer memory types. This implementation implicitly optimizes the prompt quality by only incorporating the most relevant history into the prompt; resulting in an implicit cost-efficient approach while also preserving the utility and richness of ChatGPT responses.
The architecture of the ChatGPT memory project
ChatGPT Memory employs Redis as a vector database to cache historical user interactions per session. Redis provides semantic search based on K-nearest neighbors (KNN) search and range filters with distance metrics including L2, Inner Product (IP), and COSINE. These enable adaptive prompt creation by helping to retrieve the semantically-related historical user interactions using one of the distance metrics.
Furthermore, the ChatGPT Memory project takes advantage of the vector indexing algorithms that Redis supports, including the FLAT index (which employs a brute-force approach) and the optimized hierarchical navigable small world (HNSW) index. Redis supports real-time embedding creation/update/delete (CRUD) operations for managing this process in production.
In addition to mitigating the shortcomings of the heuristic memory limitation, ChatGPT Memory allows real-time management of concurrent conversational sessions. It segregates the history of each session, which relates to the user’s past interactions with the chatbot, for each chat session. Once the ChatGPT assistant responds to a user query, both the query and the assistant’s response are embedded using OpenAI’s embedding service. Then the generated embeddings are indexed in a Redis index for later retrieval.
The subsequent interactions are carried out as follows:
- The user sends a new message to the ChatGPT bot.
- ChatGPT Memory embeds the user message using the embedding API to obtain the query vector, and it queries the Redis vector database to obtain the top k semantically related historic interactions.
- ChatGPT Memory incorporates the retrieved interactions into the current prompt alongside the current user message, and it sends the prompt to ChatGPT.
- Once it has ChatGPT’s response, the current interaction is vectorized and cached in the Redis vector database.
This empowers users to get better, personalized answers because the system has more information to draw on.

Build fast, accurate AI apps that scale
Get started with Redis for real-time AI context and retrieval.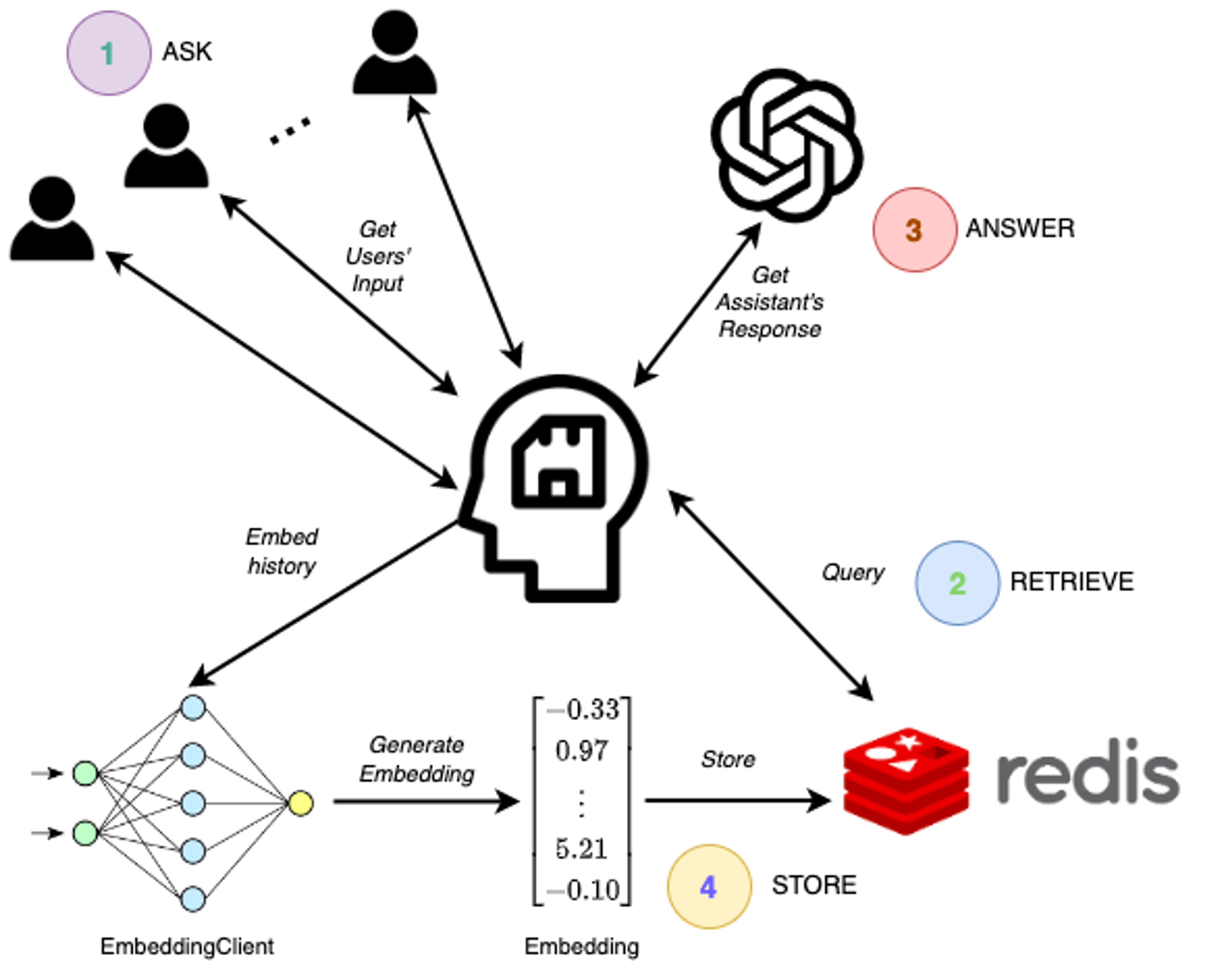
ChatGPT offers a powerful mechanism for automatic retrieval-based prompt augmentation.
Code walkthrough
Before you use ChatGPT Memory, you need to clone the repo and install the dependencies. You also need an OpenAI API key and access to the Redis cloud-based vector database (which you can try for free).
Once you obtain these credentials, set them as environment variables named OPENAI_API_KEY, REDIS_HOST, REDIS_PASSWORD, and REDIS_PORT by plugging in the value in the following bash script.
After that, you can start using ChatGPT Memory by writing just a few lines of code.
Create an instance of the Redis datastore connection.
Instantiate the OpenAI embedding client for vectorizing conversation history.
Create the memory manager for orchestrating semantic prompt creation based on the current context.
Then connect to the ChatGPT API.
Finally, you are all set to interact with the ChatGPT client with an infinite contextual and adaptive memory powered by the GPT and the Redis datastore.

Search meaning, not just keywords
Use Redis vector search to deliver smarter results instantly.Example interactions
So, what’s it look like? Consider these two examples of conversations with ChatGPT. They illustrate the difference in performance between the two modes of operation.
Without ChatGPT memory
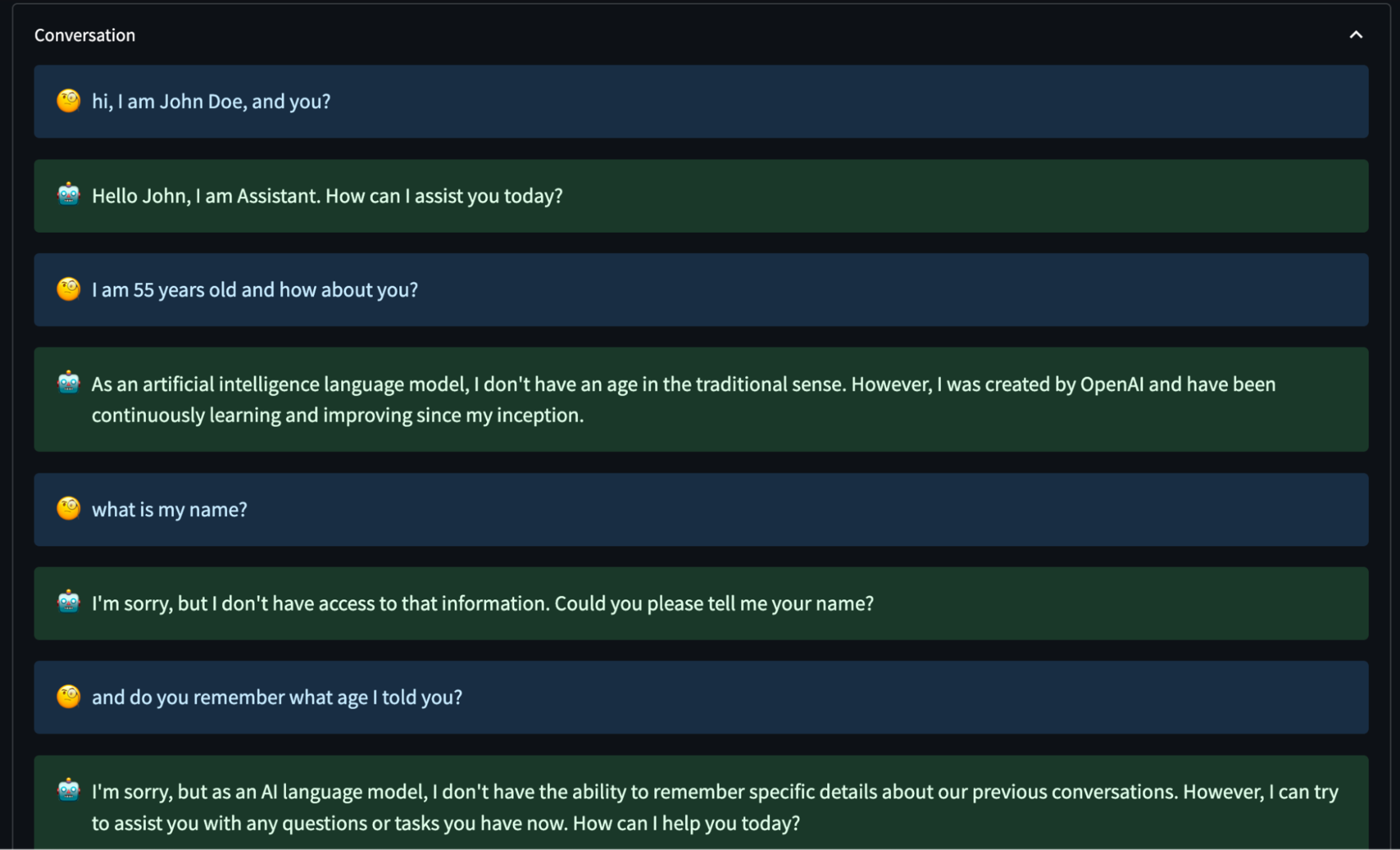
The ChatGPT user told the system his name and age in this low-context example… but it doesn’t remember it even a sentence or two later.
When the memory feature is not activated, the ChatGPT model can’t retrieve any information provided by the user in previous interactions – even from only a few sentences back.
With ChatGPT memory
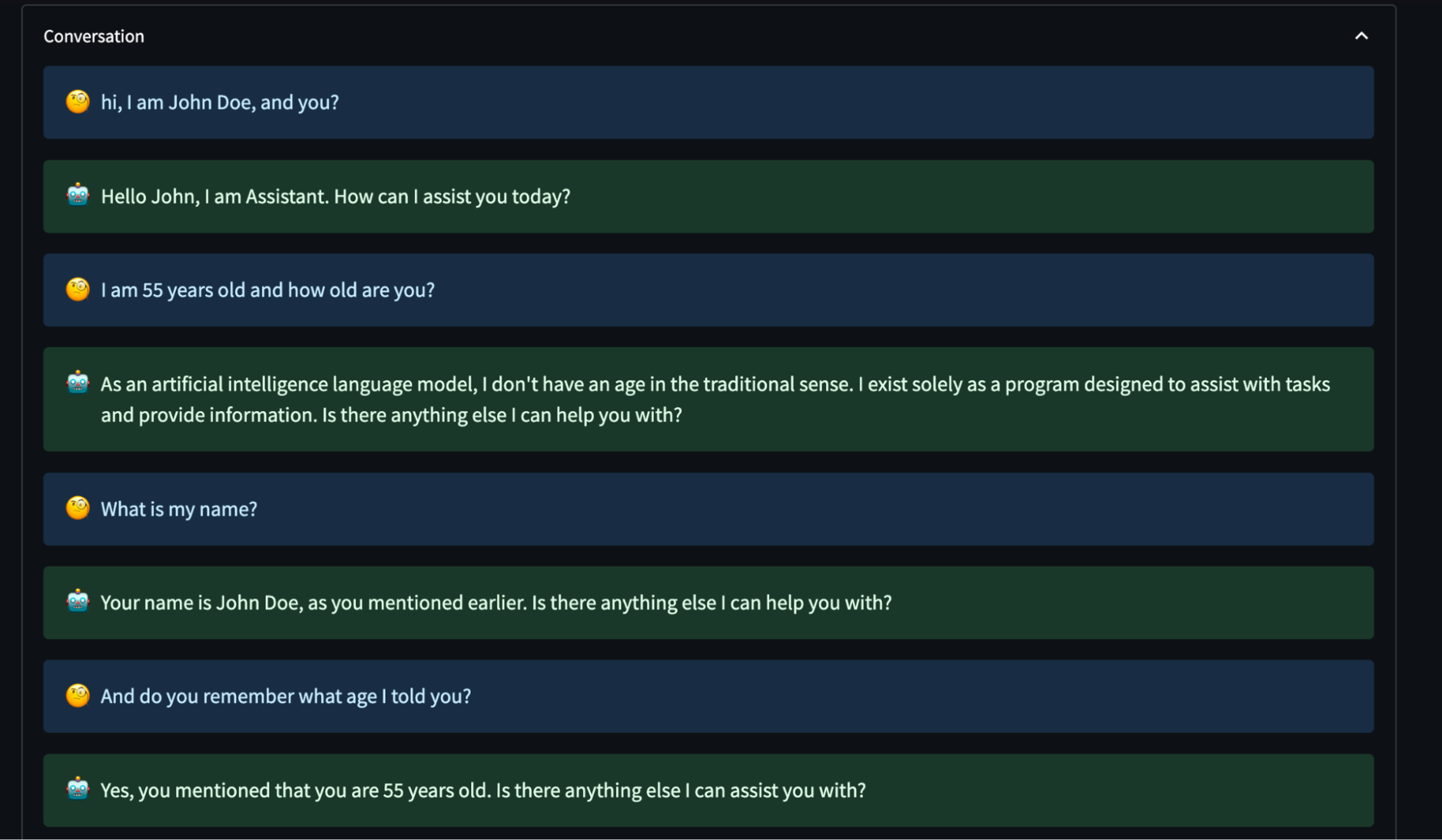
With ChatGPT enabled, the information provided by the user goes into the system to be accessed in later parts of the conversation.
The two conversations presented have a similar message flow. However, the conversation where the memory feature was not enabled showed that the ChatGPT model could not recall any information that the user had provided. In contrast, when the memory feature was enabled, the model remembered specific details about the user and offered a personalized and customizable conversational experience.

Now see how this runs in Redis
Power AI apps with real-time context, vector search, and caching.Next steps
We believe that ChatGPT Memory is a valuable addition to the growing ecosystem of tools designed to improve LLMs’ capabilities. It presents a great opportunity for developers to build powerful and contextually intelligent AI applications.
ChatGPT Memory’s solution also highlights the essential nature of the Redis vector database, which caters to a multitude of AI use cases, including but not limited to LLMs.
To try ChatGPT Memory yourself, head to our GitHub repository and follow the instructions in this post. You should be able to spin up an instance within minutes. Finally, if you’re interested in learning more about building LLM apps with Redis and tools like LangChain, register for this upcoming RedisDays virtual session.
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.