
Hash Field Expiration (HFE) is an exciting new feature introduced in Redis Community Edition and Stack 7.4, and is one of the most requested enhancements since the early days of Redis (see [1], [2], [3]).
We’ll begin by exploring the details of HFE’s implementation and why it’s so important. Then, we’ll compare Redis to Alibaba’s TairHash and Snap’s KeyDB to see how it measures up.
The benchmark reveals that Redis consumes considerably less memory than other solutions, consistently outperforming in all use cases, as well as being the only solution that could run smoothly with up to 10 million HFEs or more. Plus, Redis stands out with an active-expiration mechanism that is both effective and minimally disruptive. Lastly, we’ll explore how this feature lays the groundwork for future exciting innovations and optimizations.
The search for the best solution
Just like the EXPIRE command for keys, the expiration of hash fields needs to support both active and passive expiration mechanisms. Active expiration is managed by a timely cron-job that periodically looks up to find and remove expired hash fields. This keeps stale data from piling up, even if those fields aren’t frequently accessed, preventing the buildup of outdated information. On the other hand, passive expiration occurs upon retrieval, meaning that when an element is accessed, the system checks its expiration status and removes it if it has already expired.
To make this work efficiently, a solid data structure is essential. The challenge isn’t just about managing two levels of expiration—both for hashes and individual fields—it was also about the limitations of relying on the existing keyspace expiration mechanism, which doesn’t quite fit the needs of HFE.
Even so, we first considered simply integrating this feature into the existing EXPIRE implementation in order to get the job done. But this approach risked increasing the challenges and potential limitations of the current system, making it less scalable and harder to maintain. Plus, adding more logic could jeopardize our ability to improve keyspace expiration in the future. Eventually, we realized the need for a more robust solution to address these inefficiencies and manage the added complexity more effectively.
By taking a step back, we evaluated the expiration of the keyspace as a whole, adopting a holistic view to understand the broader challenges. Our goal was to find a pattern that could work for both hash fields and keyspace expiration.
That journey led us to an innovative design: a general-purpose data structure named ebuckets. It’s optimized for active expiration, sorting items by expiration time and cutting memory use to about 20 bytes of metadata per item, down from the 40 bytes we were using before. However, it does require that registered items include an embedded expiry struct.
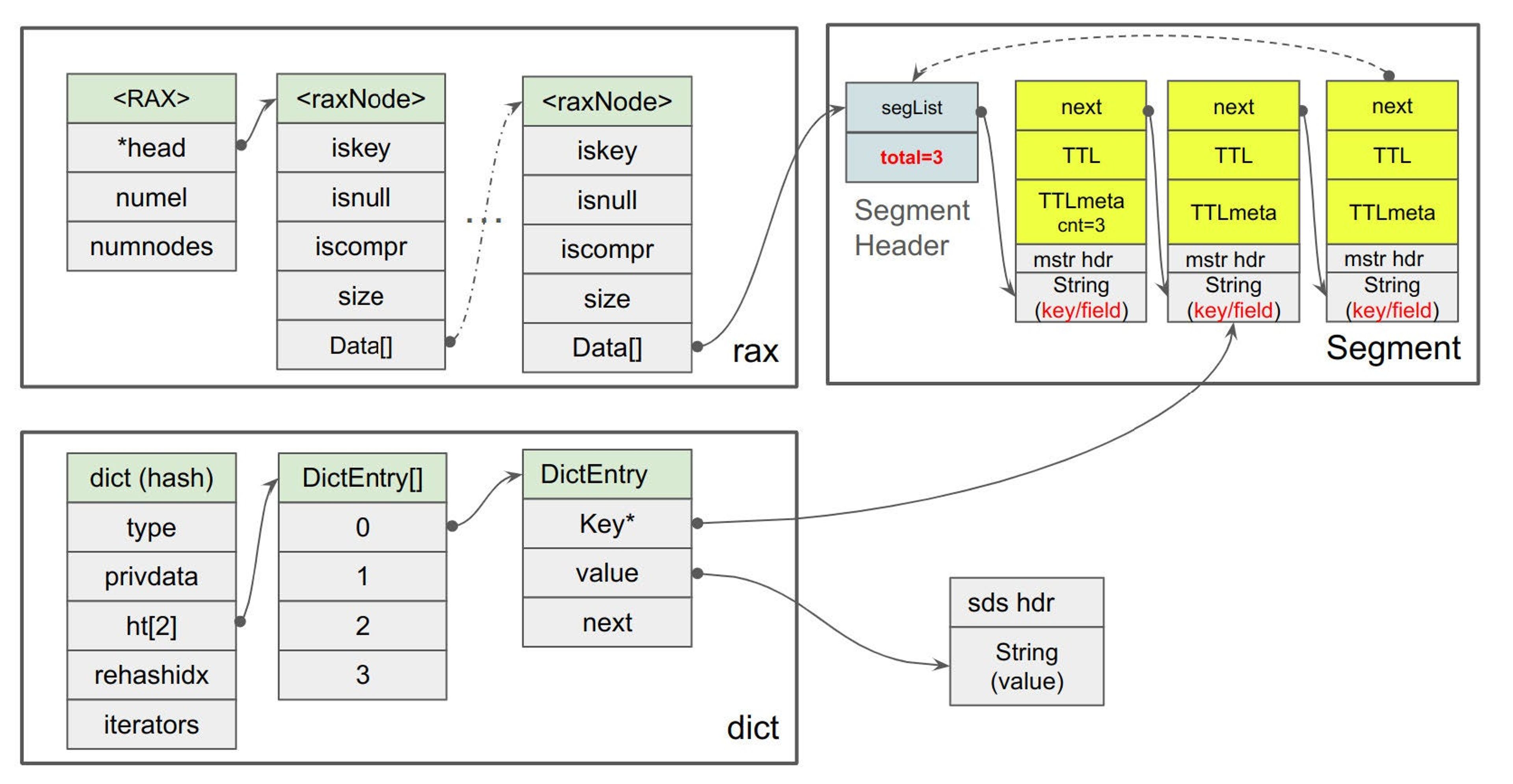
As a result, the expiry struct was embedded into the registered hash fields by switching from using plain Redis SDS strings to a new data structure called MSTR. MSTR is a general purpose immutable string with the option to attach one or more metadata. We integrated it so that each hash instance can manage its own set of HFEs in its private ebuckets. To support active expiration across hash instances, we added global ebuckets to register hashes with associated HFEs.
An ebuckets is made up of a RAX tree or linked list when small. It’s sorted by the TTL of the items. Each leaf in the RAX tree is a bucket that represents an interval in time and contains one or more segments. Each segment within a bucket holds up to 16 items as a linked list. The following diagram summarizes those ideas. It also hints at MSTR layout and how hash table of type dict is going to integrate with it. Expiry struct, painted in yellow, basically includes “next” pointer, expiration time (TTL for short) and few more related metadata:
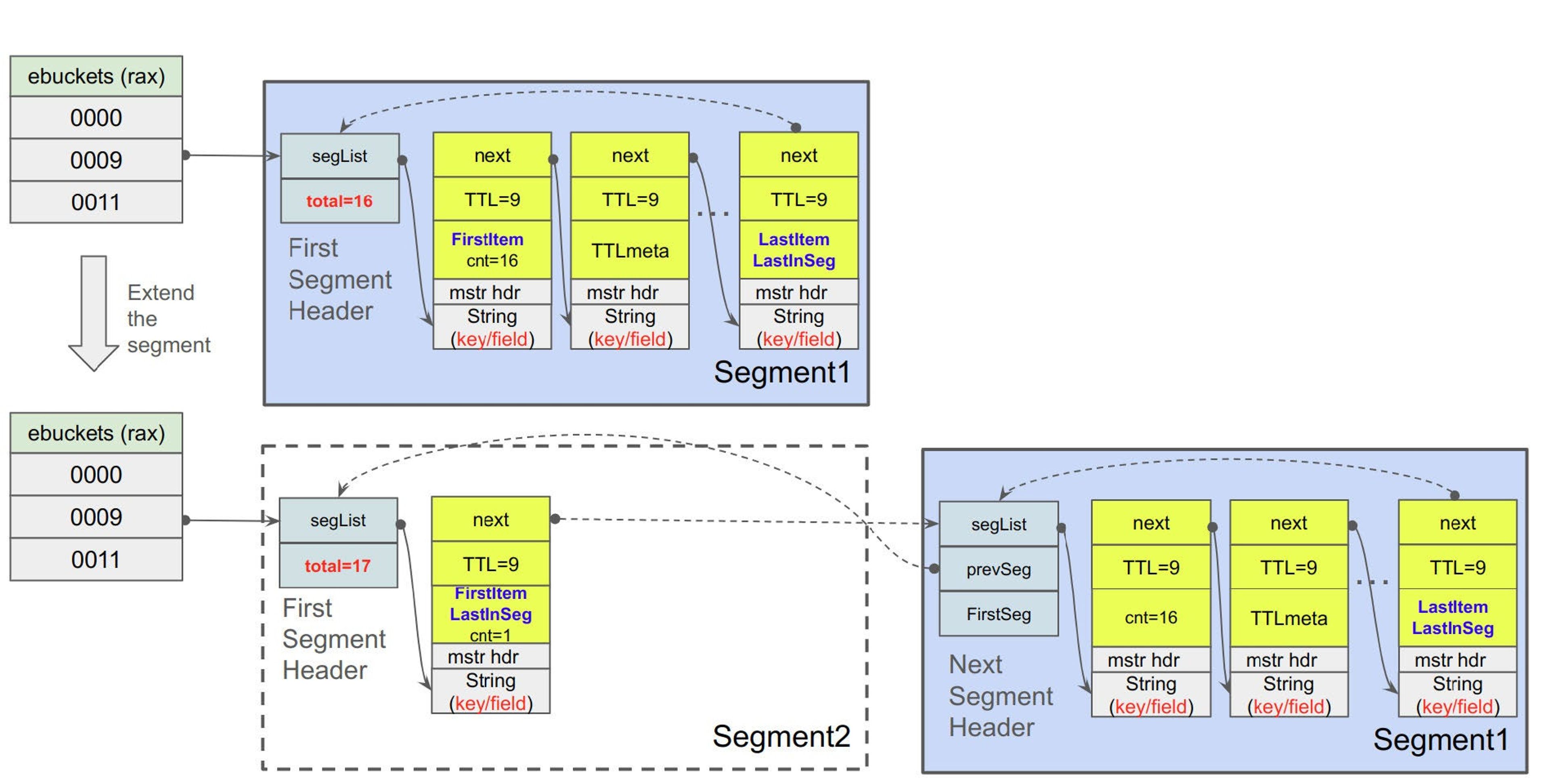
If a segment hits its limit, it splits, and also splits the bucket into two smaller intervals in the data structure. If the segment contains items with the same TTL, the split may not be even since those items, with the same TTL, must stay together in the same bucket. This leads to another key point: if a segment is full and all items share the same TTL, the bucket can’t be split further. Instead, all items with the same TTL are aggregated by creating an extended segment and chaining it to the original segment:
The battle of the benchmarks
Over the years, few projects have come up with solutions for handling HFE, either as modules or forks of Redis. KeyDB by Snap and TairHash by Alibaba stand out among them. Their development efforts were impressive enough that we decided to take them seriously, and benchmark against their capabilities (specifically, testing against commit 603ebb2 and 4dbecf3, respectively). To see how Redis stacks up against them, we ran a series of performance tests, running the benchmark on a m6i.large instance of AWS, with three rounds focusing on:
- Memory usage
- Performance
- Active-expiration
These elements show the nuanced dynamics of this feature, highlighting the intricate balance between resource efficiency, operational speed, and timely removal of outdated items and their influence on the server. Benchmark code is available here for review.
Round 1: Memory usage
The following chart displays the memory usage of two test cases, measured by query used_memory_human:
- Allocating 1 million HFEs on a single hash
- Allocating 1 million hashes with a single HFE per hash.
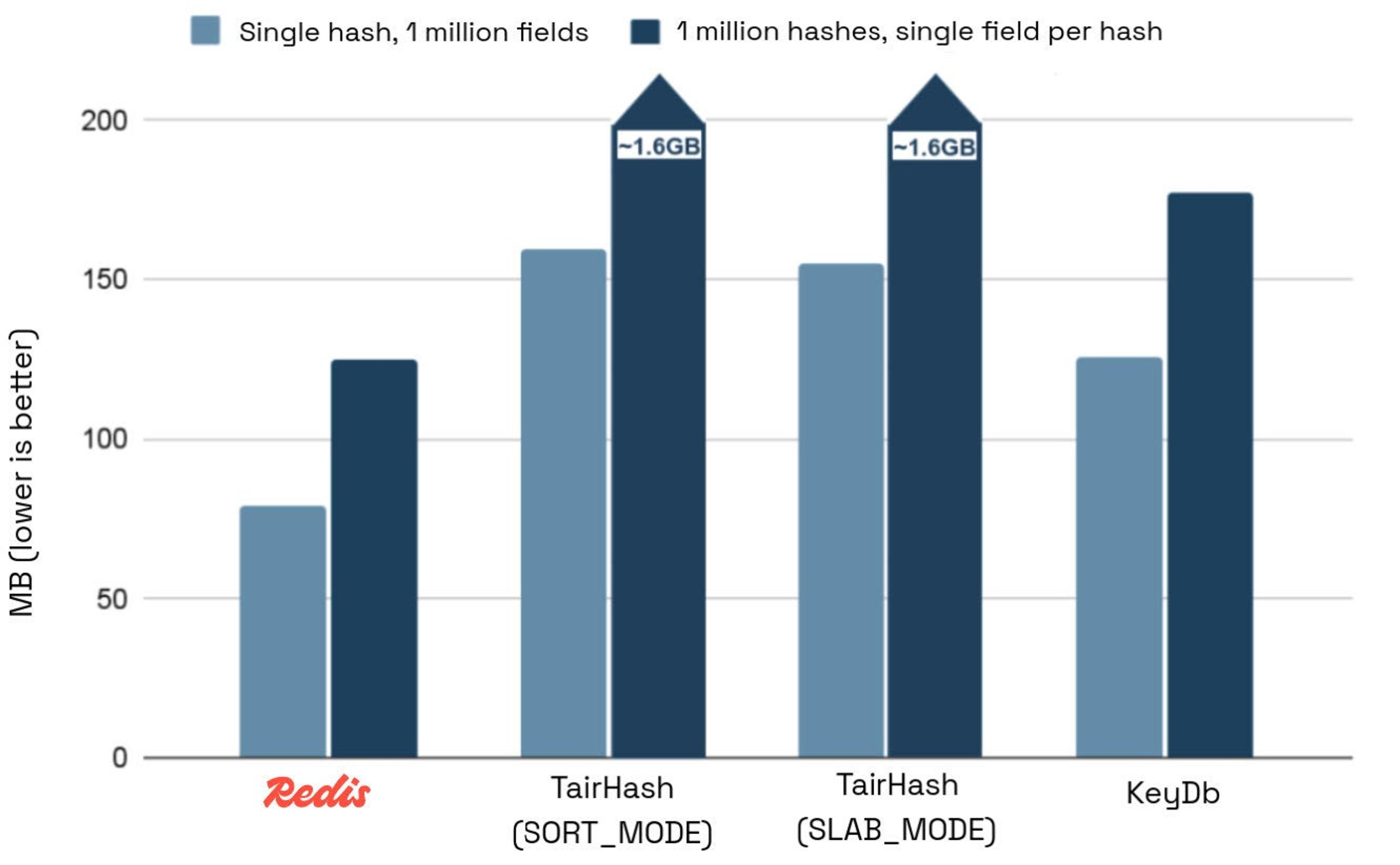
We expected TairHash to perform worse than Redis and KeyDB because it’s a module and comes with extra overhead. But the 12.9x increase in memory usage compared to Redis indicates that there are severe inefficiencies specific to TairHash. While some per key metadata overhead is expected for a module, this big of a gap suggests poor design choices at play.
KeyDB performed better than TairHash but still used 58% more memory than Redis for a single hash and 41% more for multiple hashes.
Round 2: Performance
This round focuses on the performance of setting expiration for 10 million fields, each with various expiration times, within a single hash.
We set up four test cases to evaluate performance, creating 10 million fields on a single hash and setting expiration on the fields as follows:
- All fields with a distant expiry
- All fields with a 3-second expiry
- All fields with a distant expiry. Run the test with multiple clients (memtier: -t 2 -c 5).
- All fields expired at a distant specific time
The benchmark uses the utility memtier_benchmark to fill up the hash and then set the fields’ expiry. If the expiration time is distant, it also queries for TTL for all the fields. For example, test case #1 for Redis will run HSET commands for a single hash, then apply HEXPIRE for all the fields, and lastly, query all the fields for HTTL. It should be noted that test case #3 is designed to see if KeyDB’s multithreading gives it an edge when multiple clients are involved.
The chart below shows requests per second for the command that sets the field’s expiry, as this command was the most error-prone and also in our main focus (higher is better):
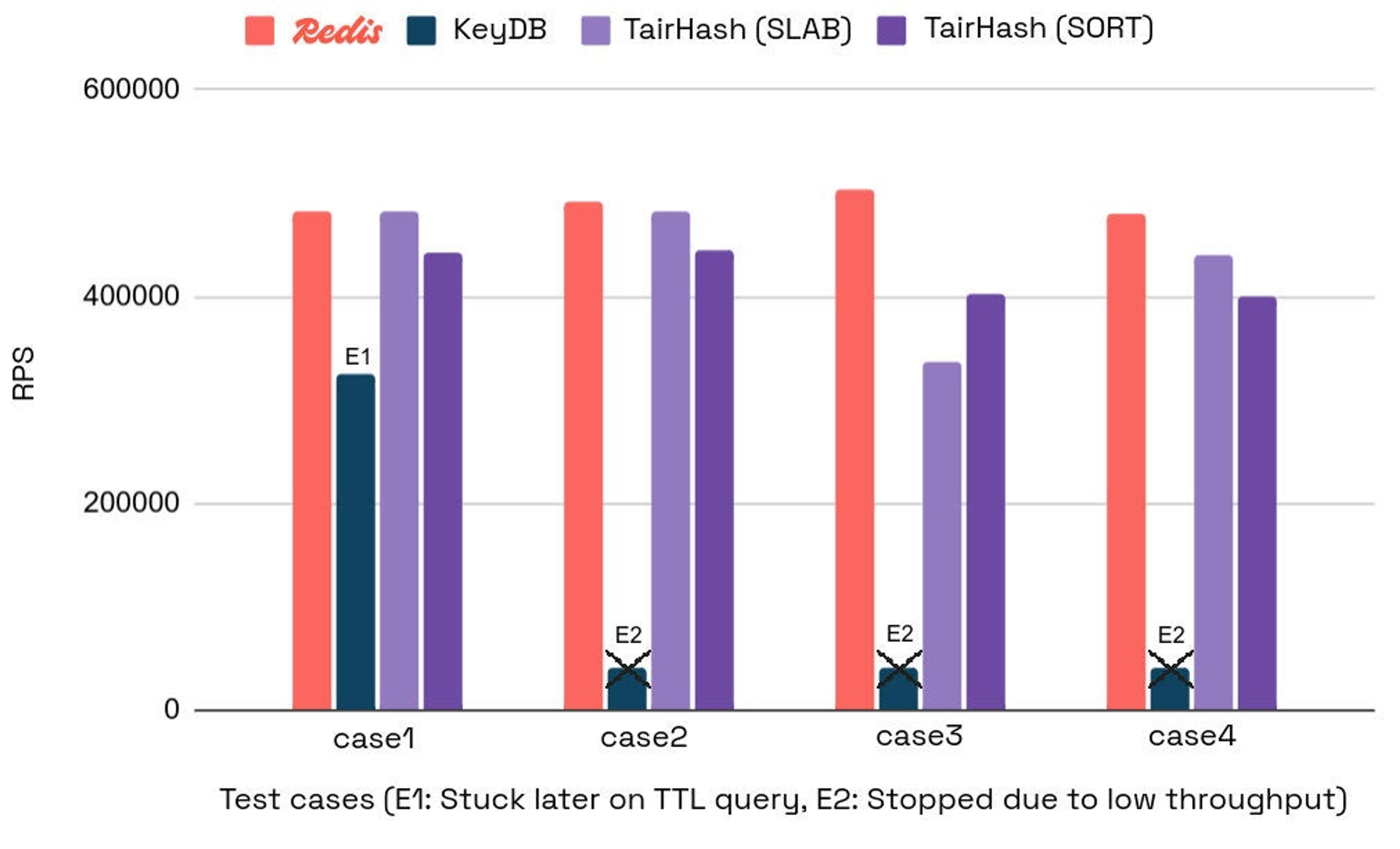
The following table presents also ops/sec measured for each of the executed commands:
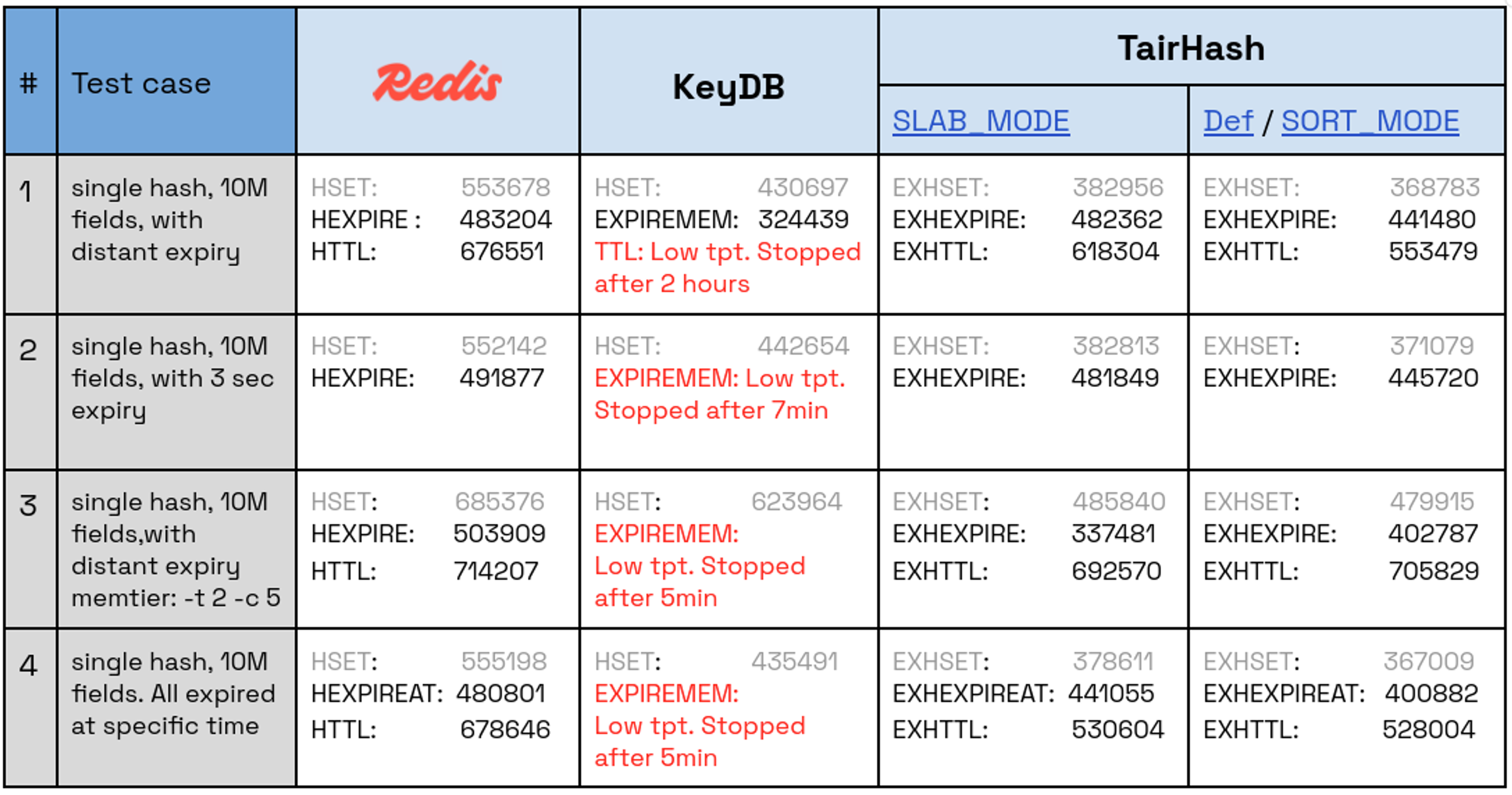
While Redis and TairHash showed competitive performance, Redis stands out, achieving up to 49% higher throughput in its best case compared to SLAB_MODE and up to 25% higher throughput compared to SORT_MODE. KeyDB struggled with EXPIREMEMBER at scale, showing intolerable performance and very low throughput, dropping below 1k ops/sec after handling only 5% of the traffic. Even with a reduced test of 1 million fields, KeyDB showed the same poor results.
We also wanted to benchmark 10M hashes, each with a single field, but testing TairHash for this scenario was challenging. The AWS instance (m6i.large) crashed in SLAB mode after just 1 million hashes due to memory exhaustion (with a single field each), and in SORT mode, it crashed at 4 million hashes. KeyDB, on the other hand, experienced extremely low throughput and was stopped after more than 10 minutes without completion. In contrast, Redis showed remarkable performance in this scenario as well:

Round 3: Active expiration
While setting TTLs for hash-fields and memory usage is important, the real goal here is to efficiently delete expired fields in the background, close to their expiration time, and with minimum impact on the server—especially under varying workload conditions. Note that these are conflicting requirements.
To see how well the active expiration background task handles this, we tested two scenarios that focus on hash-field expiration with short TTLs to trigger quick expiration:
- Setting single hash and multiple fields with 3 seconds TTL
- Setting multiple hashes with a single field with 3 seconds TTL
KeyDB
Once it enters active expiration, it simply blocks on this task until completion in a very inefficient way. With only 100K fields on a single hash, the server couldn’t respond for 5.2 seconds to a simple query. Then we tried the second test case with 100K hashes and a single expired field for each, again, and got a 5.8-second delay for a trivial query. With 1M items, we eventually gave up after waiting for more than 1 minute for a response from the server.
TairHash
TairHash did better. It releases no more than 1000 fields in total every second, either on a single hash or across multiple hashes. And no matter how many pending elements have expired or how busy the system is, it doesn’t exceed that limit. For 10M items, assuming you have enough memory, it will take almost 3 hours to release the entire data, so if the application is using it for short TTL sessions with high traffic, it will eventually lead to memory exhaustion. This limit is configurable at some level but not adaptive to the number of pending expired fields or workload.
Redis
Redis handles active expiration by running a background job at 10 times per second, aiming to release 1,000 items each time it’s triggered. It keeps track of how many calls in a row it was invoked and got stopped due to this limit. If it reaches consecutive releases of some threshold of expired fields in a row, in that case, it factors the limit by x2 with each invocation, up to a factor of x32.
Redis releases 10 million items within about 30 seconds with minimal latency, even while processing new commands. According to internal benchmarks, this HFE feature is more efficient than the legacy EXPIRE for keys, which might interfere more with server availability.
The diagram below shows an extreme case where Redis actively expires 10 million fields from a single hash called hash1, where all fields expired at time 0. At the same time, another hash, named hash2, is being populated with up to 15 million fields using memtier_benchmark (memtier: -t 1 -c 1 –pipeline 200). This test helps evaluate the impact on server availability as well as the efficiency of active-expiration. The dashed line serves as a reference, showing how hash2 would have been populated if hash1 didn’t exist and no fields were released by active-expiration during that time.
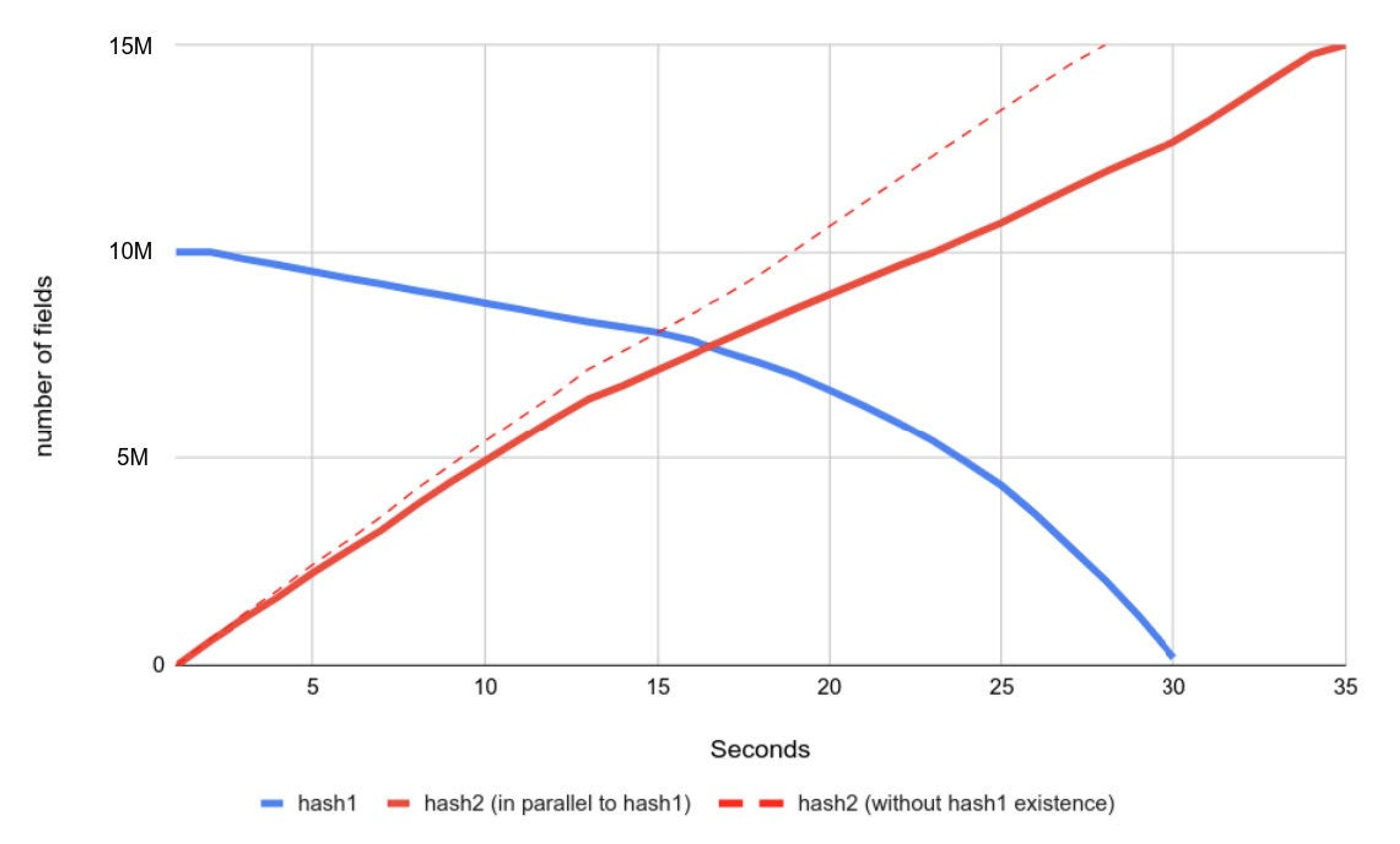
As the diagram shows, it took 34.5 seconds to populate hash2 with 15 million fields, up from 28 seconds, which means throughput dropped by about 18.8%.
In short, this benchmark highlights Redis’ superior memory efficiency, consistent high performance even with 10 million or more hash field expirations, and its adaptive, effective active expiration—putting it well ahead of KeyDB and TairHash.
Looking ahead
Using HFE as lightweight secondary index IDs
eBuckets impose full TTL order over the fields with expiration. Redis can use this feature as lightweight secondary index IDs for sorting hash-fields or categorizing fields. This could work alongside regular usage of hash field expiration, even on the same hash. The only restriction is that the same field cannot be set with expiration time and index. Each field can hold up to 48 bits of expiration time, but users can only set 46 bits. So, we can raise the 48th bit in case of lightweight indexing and retain 46 bits (1 bit is reserved) for USER_INDEX. This is just a preliminary idea and could be developed in different forms and APIs. Currently, it is not yet part of the Redis roadmap.
Replacing EXPIRE data structure and more
The ebuckets data structure looks like a strong contender to replace the current EXPIRE implementation. It’s shown some clear benefits over the existing method, and Redis plans to explore this further.
The final bit
The community has long sought the ability to manage expiration for individual elements within complex data types like hashes. Despite concerns about complexity and resource demands, Redis found an efficient approach that not only meets user demands for performance and simplicity but also lays the groundwork for future innovations. Benchmarking against Redis-forked products like TairHash of Alibaba and KeyDb of Snap underscored Redis’ superior memory efficiency and operational stability.
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.