
We recently released Redis Copilot to help devs build faster with Redis. It’s our mission to make apps fast and make building simple. To this end, Redis Copilot is your AI assistant that helps you complete tasks with Redis even faster. You can get started with it in Redis Insight today.
Redis Copilot helps you build with Redis so you can:
- Get qualified answers with Copilot’s up-to-date knowledge about Redis docs
- Generate code snippets to help you develop apps with Redis faster
- Answer questions about your data by generating and executing queries in Redis

Copilot was built with the capabilities of Redis for AI
Redis makes apps fast. We knew when building Copilot that it needed to provide fast, accurate answers and scale for worldwide use. So we built it using Redis to provide a great user experience that devs expect from Redis-powered apps. We offer many components specific to building AI apps but with much more functionality. Many of our customers ask us the best way to use Redis for their AI apps, so here, we’ll break down the ways you can use Redis to make your apps fast and efficient.
The fastest vector database powers RAG for better answers
The RAG approach, presented by Meta in 2020, allows LLMs to incorporate external knowledge sources through retrieval mechanisms, extending capabilities with the latest information. This method allows language models to provide better answers in real time.
RAG has proven to be very effective, but it requires careful prompt engineering, fresh knowledge management, and orchestrating different components. As a real-time vector database, Redis can search through millions of embedding vectors in real time to guarantee that relevant contextual information is provided and embedded based on a user prompt.
Redis Copilot uses RAG and our vector database to retrieve relevant information from our docs to help answer your questions. It’s the fastest vector database available per our benchmark tests, and with RAG, we’re able to use the latest version of our docs—so you always get up-to-date answers to your questions about Redis.
LLM memory makes responses more relevant
Redis facilitates the retention of entire conversation histories (memories) by using preferred data types. Whether employing plain lists to preserve the sequential order of interactions or storing interactions as vector embeddings, we enhance interaction quality and customization for you when using Redis Copilot. When Redis Copilot calls an LLM, it adds pertinent memories from your conversation to provide better responses. This functionality results in smooth transitions between topics during conversations and reduces misunderstandings.
Semantic caching saves costs & makes responses faster
Generating responses from LLMs can come with a lot of computational expenses. Redis reduces the overall expenses associated with ML-driven apps by storing input prompts and responses in a cache and retrieving them with vector search.
This diagram summarizes the flow of user interaction with Redis Copilot:
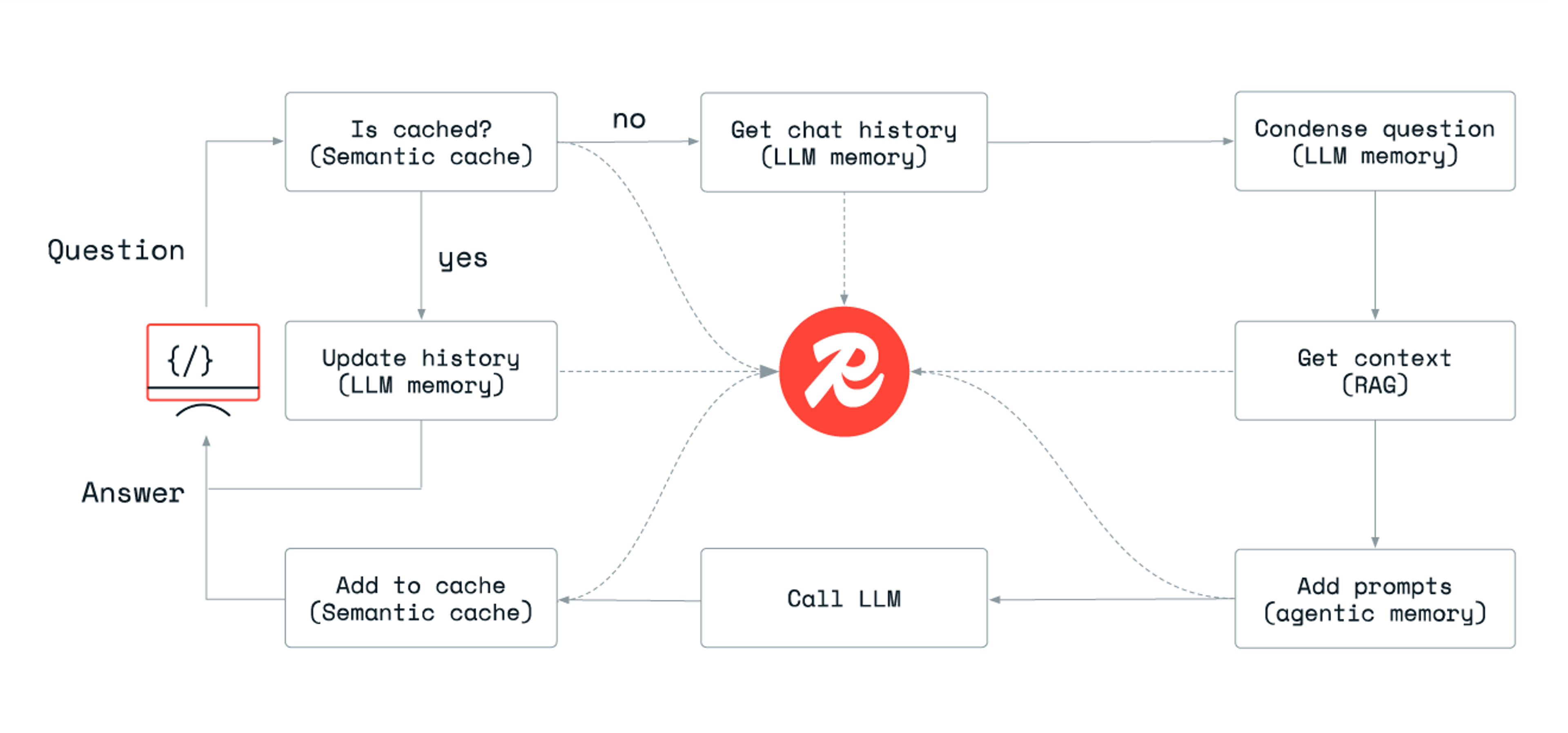
Redis does so much more
While GenAI models are exciting innovations, building and deploying GenAI apps to production requires fast and reliable data. Redis is the proven platform that serves many critical functions for today’s apps across many diverse use cases.
Store responses in an index for fast retrieval & additional processes
From request to the completed answer, it can take up to a few seconds for the LLM to stream results back to users. We opted to stream replies to users to improve responsiveness and cut down on wait times, rather than return the whole response once it’s complete. We also embed additional context from a semantic search in a Redis database in the conversational bubble.

For the LLM, we chose OpenAI’s GPT-4o because of its reliability and speed. However, while OpenAI provides excellent AIaaS capabilities for conversational agents and embedding models, we use local embedding models to compute vector embeddings. Specifically, we use the HuggingFace embedding model for the semantic retrieval of existing answers in the semantic cache.
Full-text & faceted search help browse docs for specific results
While the latest trend is semantic search, and traditional searches can be reinterpreted by these new AI/ML capabilities, full-text search is an irreplaceable asset for retrieving information by matching words or phrases. Redis real-time full-text search is available in Redis Copilot to complement the conversational experience. Redis highlighting and summarization also addresses user demands for fast and readable results.

Last but not least, aggregation capabilities are also critical to help users see how many results have been retrieved by Redis and determine how popular a particular search is.
Redis is used as a message broker between microservices
By assigning the task of reading documents to a separate service, it’s possible to direct Redis Copilot to use Redis to obtain contextual information with RAG.
This microservice architecture effectively splits the responsibility of a more extensive monolithic system into smaller and loosely coupled microservices. The Redis stream—the permanent time-ordered log data structure that powers asynchronous, subscribable messages to consumers—synchronizes database maintenance with the latest information. Actions are triggered and invoked by the corresponding service via messages stored in a stream, which is used as a message broker.
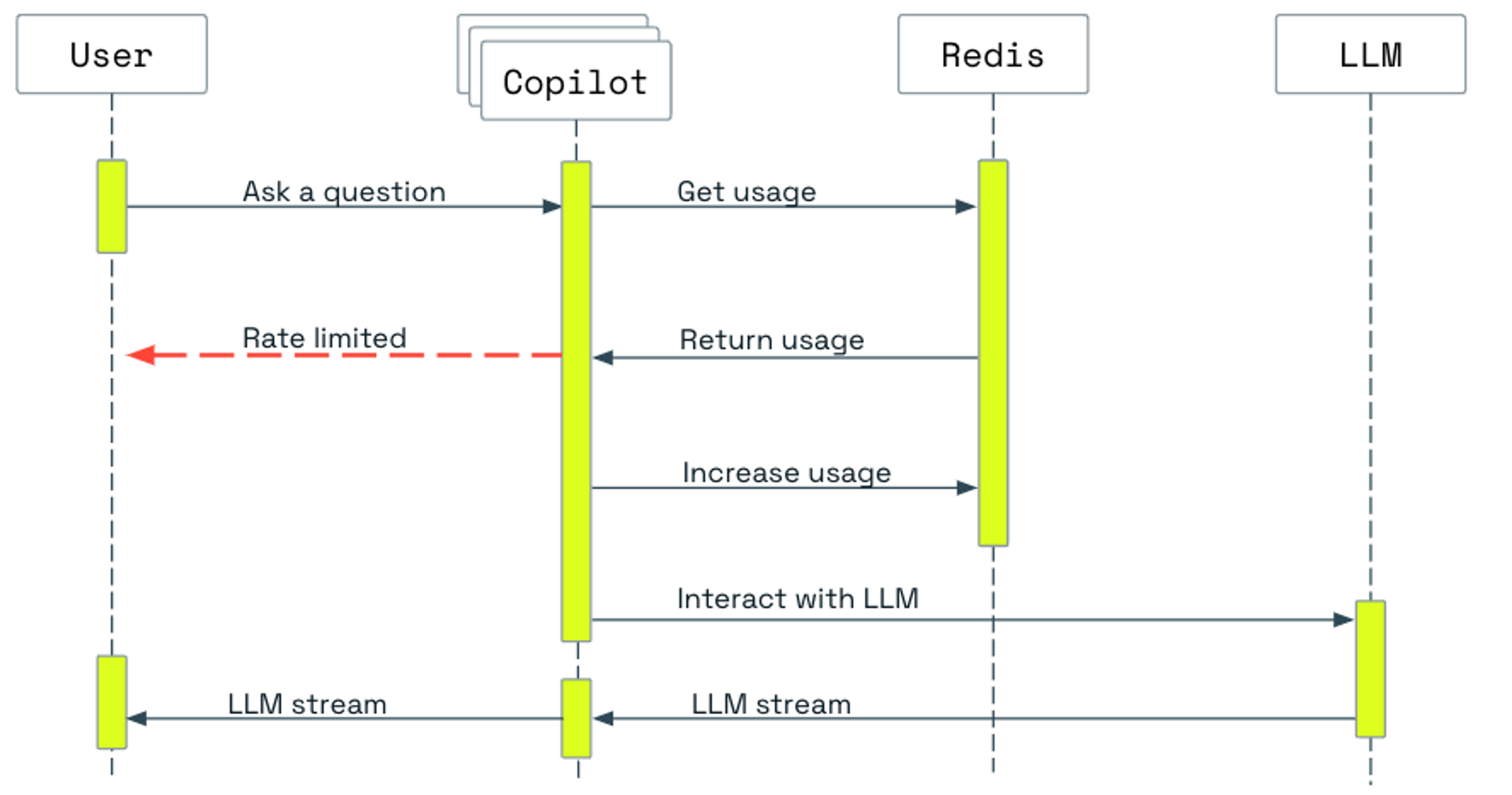
Rate-limiting makes apps stable & reliable
Redis Copilot is the main entry point for searching docs, our knowledge base, and all the training opportunities available in the Redis portal. But protecting critical endpoints from overloading is a must for all public services, as all internet services are exposed to misuse and attacks like distributed denial-of-service (DDoS) attacks. Redis has long been adopted as a rate limiter for app servers, API gateways, and more. And we use Redis as our rate limiter to ensure Redis Copilot is stable and usage is balanced across different sessions and IPs. Redis measures and checks usage. When the usage exceeds a predetermined threshold, Redis steps in to prevent abuse.
Get started today with Copilot
You can use Redis Copilot in Redis Insight today. Just download Redis Insight, sign in with your cloud account, and start building.
If you want to build your own AI apps, we offer a variety of AI resources to help you build your AI apps fast, including our RedisVL library. You can begin with our example repo Minipilot, which is a slimmed down version of Redis Copilot.
To talk to a rep about how Redis can help you build AI apps, book a meeting with us.
Related resources
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.