
In this short tutorial, we create a chain with Relevance AI, Redis VSS, OpenAI GPT, and Cohere Wikipedia embeddings.
Working with large language models (LLM) often requires retrieving the correct data to inject as context into a prompt. This is to give the LLM understanding of your own custom data without having to finetune the model. A popular strategy for retrieving the data is using vector search, as it’s exceptionally good at matching similar data without having an exact match. Redis natively supports vector similarity search and is built for speed.
In this example, we show how to build and deploy a chain, or a sequence of operations, in Relevance AI that allows us to ask questions of Wikipedia using Redis vector search to extract the best article based on our question. For embeddings, which are lists of numbers that can represent many types of data, we use Cohere’s multilingual model.
To follow along, you need a Redis database that supports JSON document data structures and built-in real-time Search and Query features. You can create one on Redis Enterprise Cloud or with Docker using Redis Stack.
Set up Redis as a vector database
Once you have Redis running, we import data from Cohere’s multilingual Wikipedia embeddings dataset on HuggingFace. This requires a few simple steps. You can see the full code in this jupyter notebook.
Step 1. Install the Python libraries for redis and datasets.
Step 2. Create a client.
Step 3. Download the sample dataset.
Step 4. Ingest each document into Redis using JSON.
Step 5. Create a vector search index.
This command specifies the index, Wikipedia, which stores data in JSON, where all keys are indexed with the prefix wiki:. In the schema, we reference each field in JSON as $.field_name and give it a friendly label using as name and its data type. The vector field, emb, is of type vector. and uses HNSW as the index type with L2 as the distance metric.
Once the command runs, you’ll have a Redis index supporting vector similarity search.
Consult the documentation for more details on how to set up an index in Redis.
Build an LLM chain
Now it’s time to jump into a Relevance AI notebook to start building our chain.
Step 1. If necessary, sign up for a free account with Relevance AI. Once you’re logged in, choose “Build AI chains” and click “Create new chain.” This takes you to a notebook.
The Relevance AI chain notebook.
Step 2. You need to configure an OpenAI API key and the Redis connection string before we can execute the chain. To do this, select “API keys” from the sidebar, then provide your Redis connection string and OpenAI API key.
Step 3. Choose “Start with prompt.” Add a new transformation for “Vector search (Redis).” Fill out the form with the following details:
- Index name: the index you created in Redis, which was wikipedia.
- Vector field: the field that stores the embeddings; for the Wikipedia dataset this is emb.
- Model: cohere-multilingual-22-12 to generate the vector embeddings for the search query
- Search query: We define an input for the chain in a few minutes. Press {} and enter {{params.question}} to change this to variable mode.
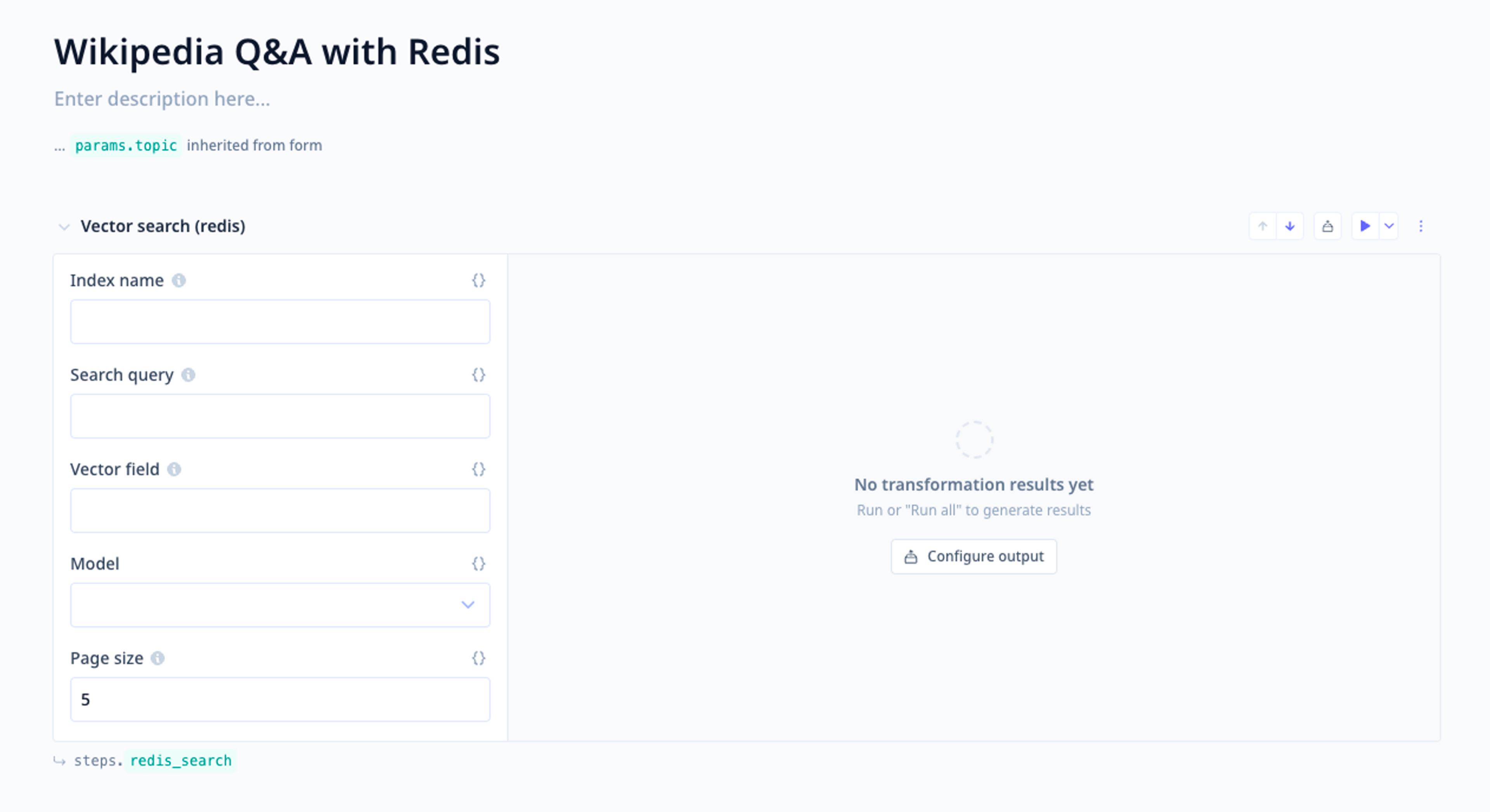
Example of a Redis Vector Search step and its inputs.
Step 4. Configure the LLM prompt to inject the context from the vector search and to ask our question. You can customize the prompt to fit your needs.
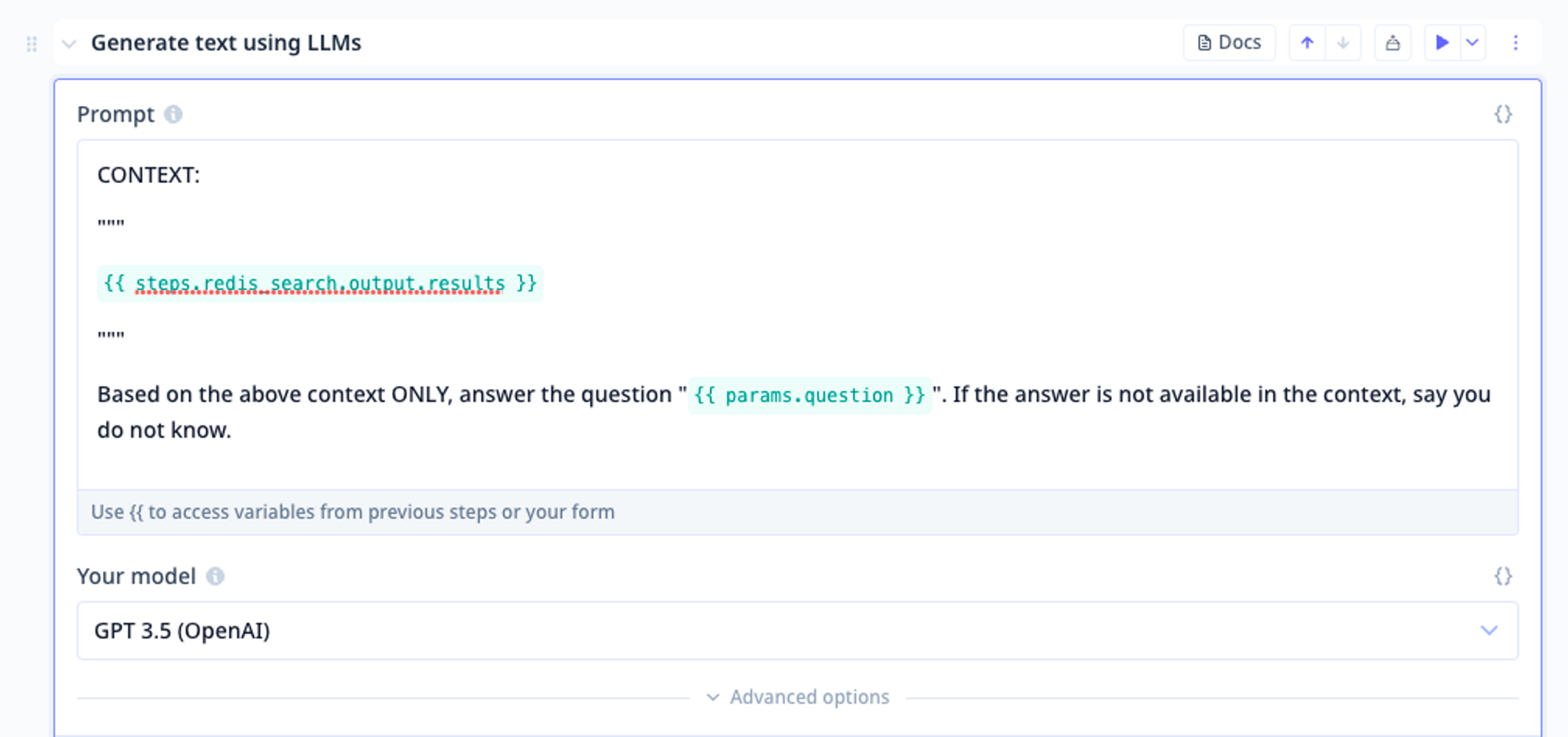
Example of an LLM step that takes the context from Redis Search and Query and asks a question.
The intent here is to help people query vast swathes of information. Say you’re mulling over your favorite Bob Dylan song, “Stuck Inside of Mobile,” and you wonder, “Who strummed those infectious guitar riffs?” With our LLM chain, you could effortlessly pose that question to an AI-infused Wikipedia search, which would swiftly return with your answer. (We leave the non-AI-infused search to the casual observer, which may demonstrate the usefulness of such a tool.)
This is more than just an exercise in technological wizardry; it’s about enriching your understanding and satiating your curiosity at lightning speed. Like a knowledgeable friend eager to share trivia over a cup of coffee, our LLM chain stands ready to engage in a dialogue with you, adding that personal touch to your search for knowledge.
Deploy a chain
A chain can be deployed in two ways with Relevance AI: as an embeddable application or as an API endpoint. An application can also be shared directly with a link where a user can see the form, fill it out, and run the chain. These are now ready to be used in production.
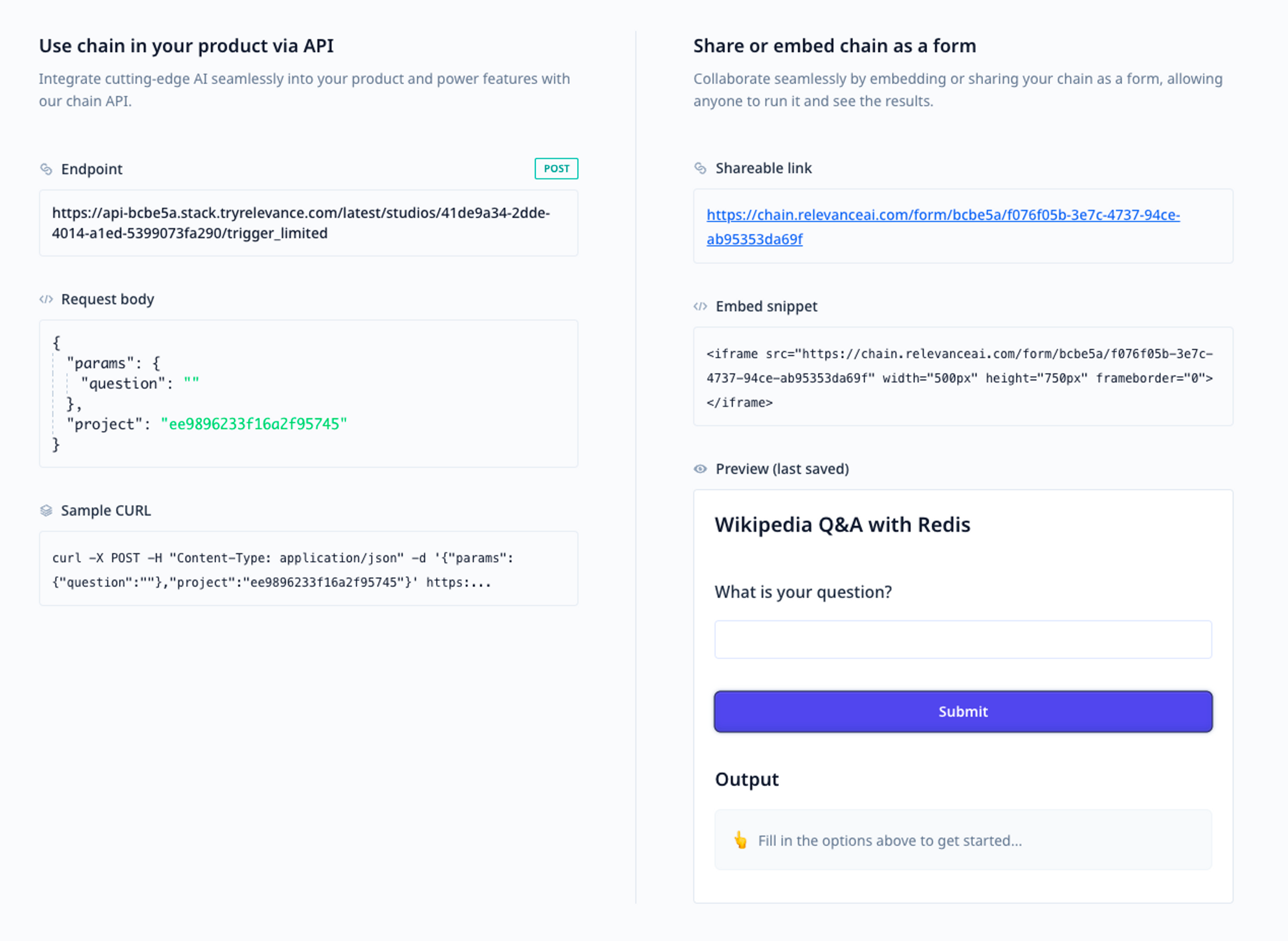
The deploy page for a chain with a production-ready API endpoint or shareable URL form.
Want to experiment more or try out the SDK? You can view a technical tutorial on building a business analyst agent that can query SQL, create charts, and answer questions.
Get started today with your own vector-search powered retrieval system by signing up for Redis Enterprise Cloud and Relevance AI.

Join us on June 3, 2023, in person in San Francisco for a 12-hour LLM hackathon with the MLOps community featuring Redis and Relevance AI. Collaborate with other machine learning practitioners for a chance to win prizes.
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.