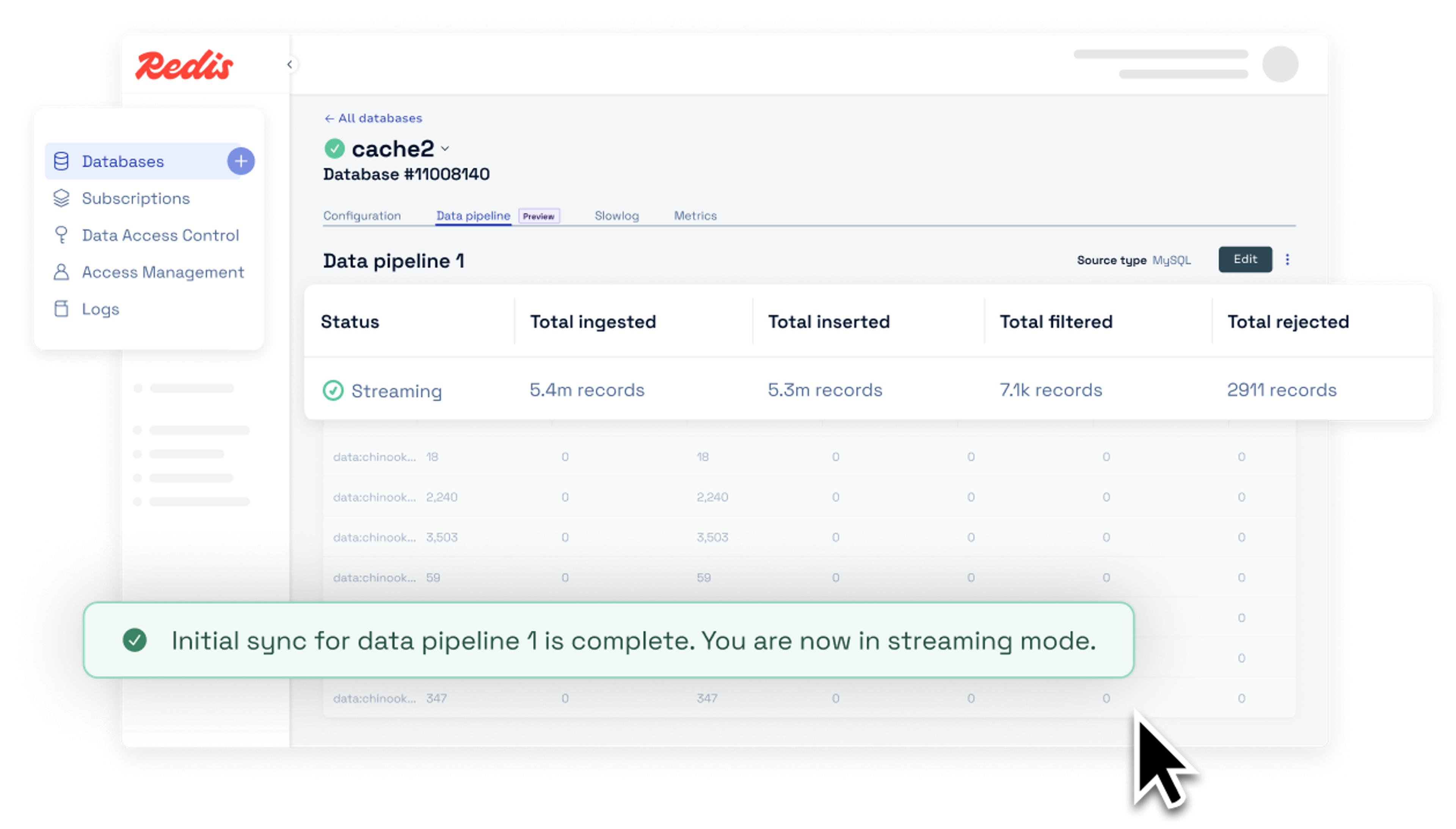
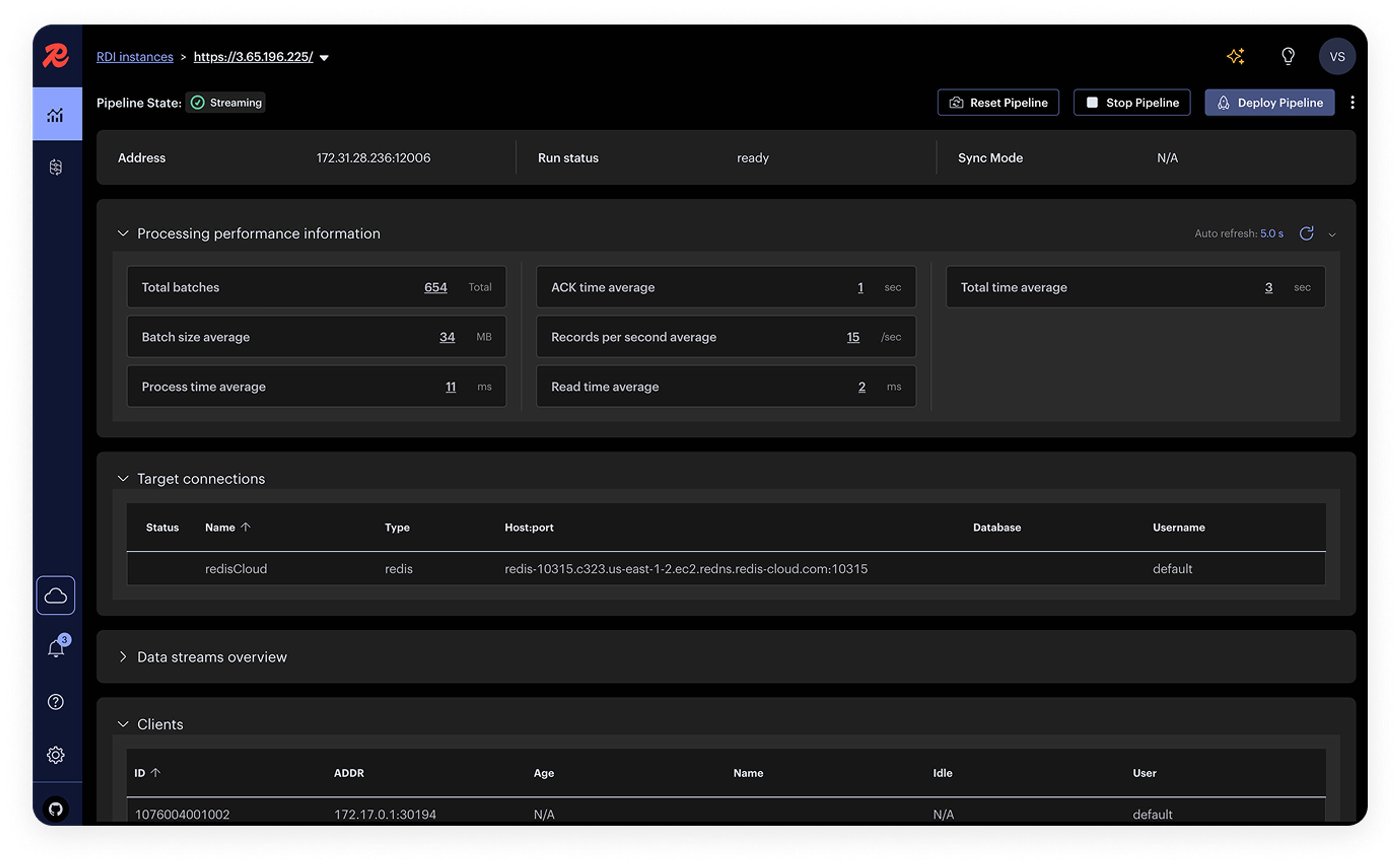
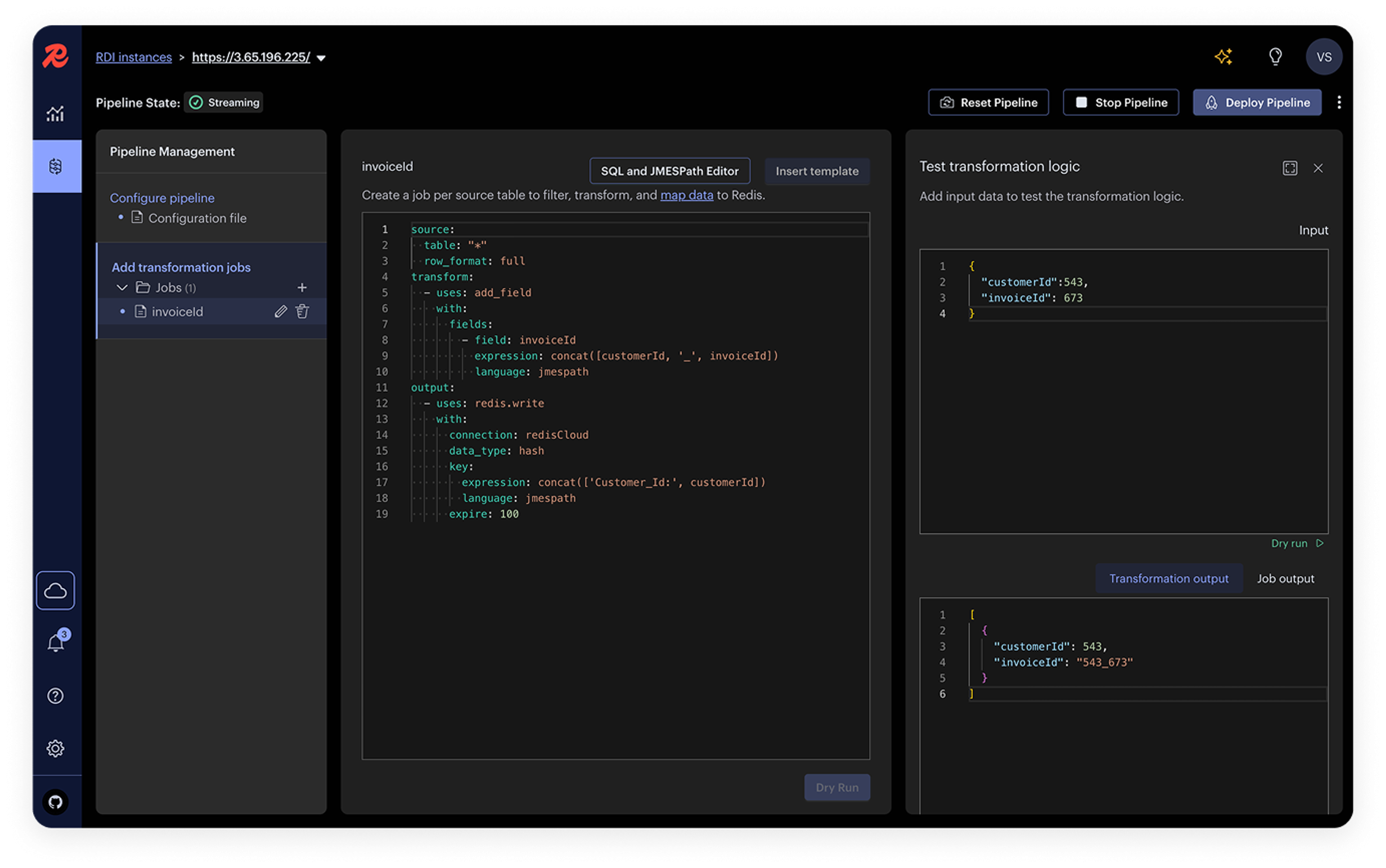



“No queremos complicaciones operativas entre sistemas. Todo debe ser fiable y funcionar sin fallos; eso es lo que esperamos. Hasta ahora, Redis nos está dando las herramientas y la tranquilidad que necesitábamos para dedicar más tiempo a lo que de verdad importa: nuestros clientes”.
Retailer especializado en estilo de vida ruralArquitecto senior







