Blog
Faster Redis: Client library support for client-side caching

Getting faster than Redis isn’t easy, but starting today, you can read your most frequently accessed data, cut down on latency, and use resources more efficiently. Today, we’re proud to announce that client-side caching support for the official Redis client libraries is now available.
- Jedis for the Java programming language
- Redis-py, for the Python programming language
Redis Community Edition has supported client-side caching since version 6. But, until now, you needed commercial third-party client libraries to use it because Redis didn’t offer support in the official client libraries. Now, you can benefit from near caching directly with the Redis official open-source client libraries, and with a few lines of code, you can enable caching at connection establishment time.
Let’s see how client-side caching can speed up data access by first taking a step back to review what near caching is and what motivates its use.
Redis’s client-server model means performance is network-bound. Every operation requires round-trip communication, which can affect performance, especially in high-throughput systems or when network latency is an issue.
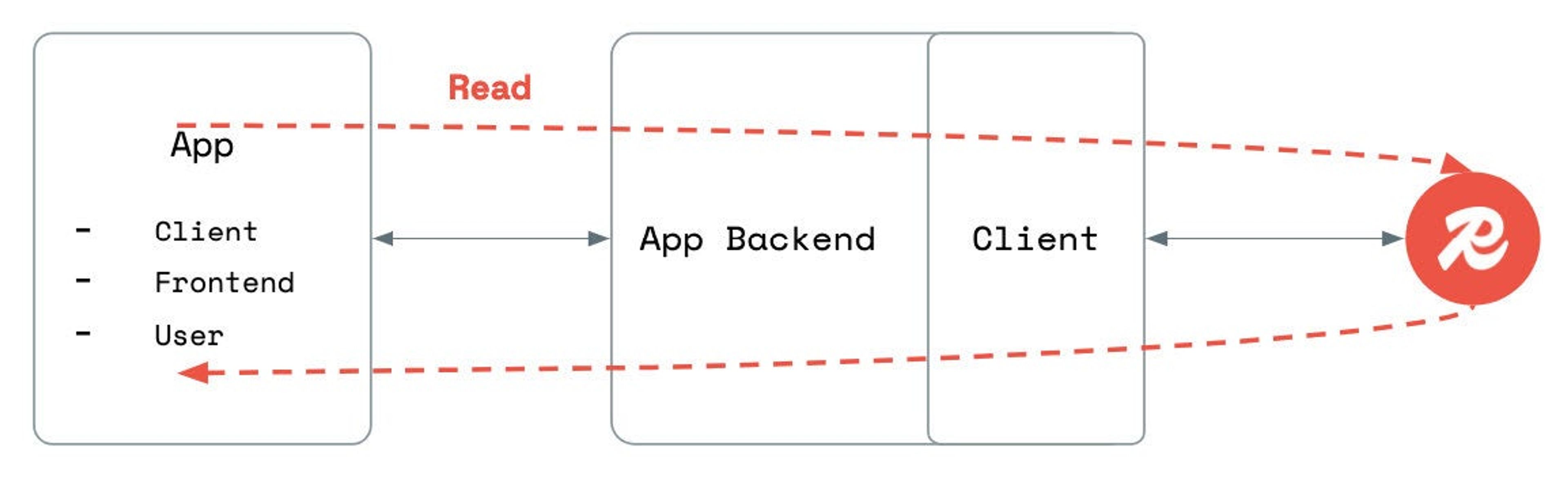
One effective way to cut down on network overhead—and boost app performance—is through client-side caching, also called near cache. This technique allows frequent read operations to be served directly from a cache on the same application server where the client is running. With client-side caching enabled, client applications are served with data cached by the backend application, reducing network traffic and latency.
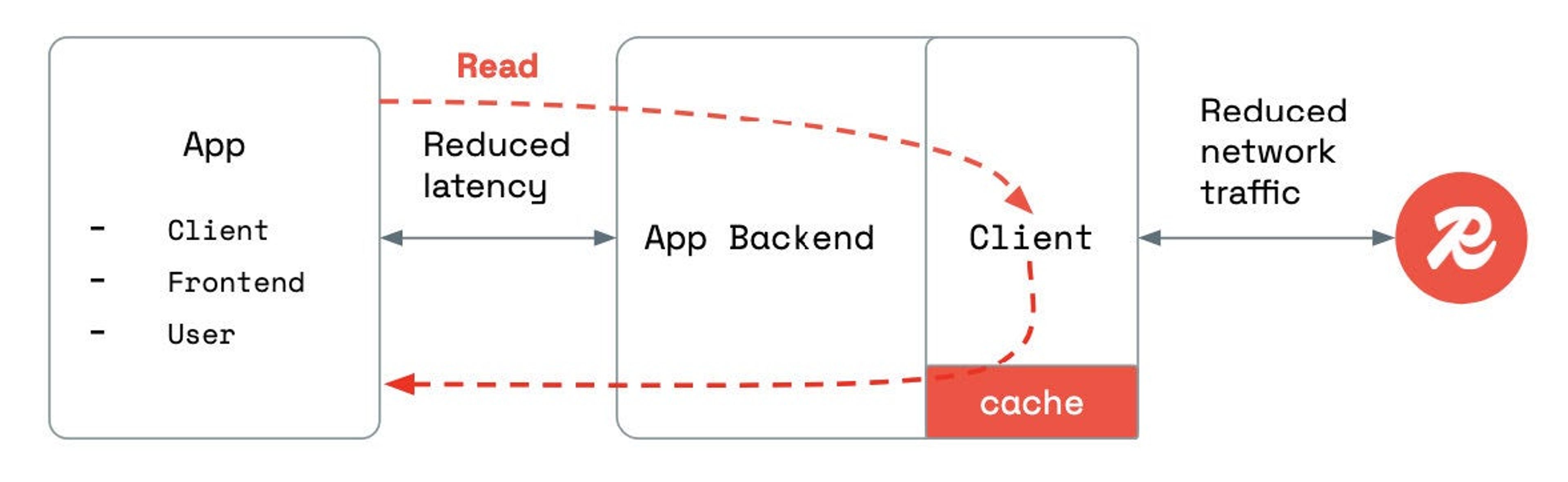
Here’s how it helps:
- Local caching is ideal for read-heavy scenarios, deployments in low bandwidth environments, and managing hot shards/keys (for reads).
- It reduces network round trips to the server, which helps lower both bandwidth consumption and costs—especially in the cloud.
- Server load is minimized, cutting down on computational overhead and saving on infrastructure costs.
How it works
Let’s walk through an example to see how client-side caching works.

- SET foo bar
- Data is stored in the server
- GET foo
- The command is sent to the server
- The client caches the reply in the local memory
- GET foo
- The client gets bar from the local memory
Whenever tracked data is changed by an arbitrary client, the server publishes an invalidation message to all the clients that currently track the data.

- SET foo qux
- Client A changes the data
- Invalidation message and cache removal
- Client B receives an invalidation message on the same connection established by the client and used to request the data initially
- Client B removes the data from the cache
- GET foo
- Client B requests the data again
- Client B caches the reply in the local memory
- GET foo
- Client B gets qux from the local memory
Testing client-side caching
To start experimenting with the feature, remember that client-side caching needs the RESP3 protocol since push notifications are required. Make sure you select the correct protocol version when you’re setting up the connection.
To streamline your development experience across all Redis products, you’ll need Redis CE 7.4, Redis Stack 7.4, or newer. You can also test the latest Redis 8 M01 milestone release. Client-side caching is fully compatible with Redis Software, Redis Cloud, and Azure Cache for Redis Enterprise, where the feature is currently in preview and generally available soon.
We said client-side caching would be easy to set up with just a few lines of code, and here’s the proof. The example below won’t complicate your client setup. Just enable caching when you establish the connection, as shown in this Python example, and you’re ready to go.
The first time the key “city” is retrieved, it is read from the database and cached in the memory of the invoking process. Subsequent reads will be transparently served by the local cache, with minimal latency and no additional load on the database.
If you’re working with Java, all the heavy-lifting is done by Jedis. You can create a connection and enable client-side caching as follows.
Frequently Asked Questions
Do client libraries support connection pooling?
You can enable client-side caching for both standalone connections and connection pools. It also works with Cluster and Sentinel APIs.
When should I enable caching?
Each time the value of a cached key is modified in the database, Redis pushes an invalidation message to all the clients that are caching the key. This tells the clients to flush the key’s locally cached value, which is invalid. This behavior implies a trade-off between local cache hits and invalidation messages: keys that show a local cache hit rate greater than the invalidation message rate are the best candidates for local tracking and caching.
For example, counters represented as strings or embedded in hashes, leaderboards, and so on—keys like these could be read on a standard connection to prevent an excess of invalidation messages.
What should I do if I do not want to cache some keys?
To control what keys are cached, instantiate a standard connection without client-side caching enabled.
What data is cached?
Clients cache a normalized version of the commands sent to the database together with the returned result. All the read-only commands are cached, except:
- Commands for probabilistic and time series data structures
- Search and query commands
- Non-deterministic commands (e.g., HSCAN, ZRANDMEMBER, etc.).
How do I estimate the memory consumption of the local cache?
Cached items have variable sizes, so the memory consumption of a local cache is related to the workload and size of stored data. Clients support inspection of the cache, so relevant statistics about the locally stored data can support benchmarks.
How do I verify that caching is working for my command?
If you’d like to see what’s happening under the hood, start the profiler in Redis Insight to see what commands are sent or use the MONITOR command in a redis-cli session from the terminal.
Using the client libraries
Read more about client-side caching here and try your favorite client library using the following GA versions below. We’ll add client-side caching to more client libraries for other languages soon.
- Jedis v5.2.0. Consult the Jedis-specific documentation.
- redis-py v5.1.1. Consult the redis-py-specific documentation.
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.