
As a provider of the Redis Cloud, we’re always testing out different configurations and options for Redis and AWS to help the Redis community achieve the best possible performance. This week, we decided to find out how fork times influence various AWS platforms and Redis dataset sizes. Redis uses Linux fork and COW (Copy On Write) to generate point-in-time snapshots or rewrite Append Only Files (AOFs) using a background save process. Fork is an expensive operation in most Unix-like systems, since it involves allocating and copying a large amount of memory objects (see more details here). Furthermore, the latency of fork operations on the Xen platform seems to be much more time consuming than on other virtualization platforms (as discussed here). Since a fork operation runs on the main Redis thread (and the Redis architecture is single-threaded), the longer the fork operation takes, the longer other Redis operations are delayed. If we take into account that Redis can process anywhere between 50K to 100K ops/sec even on a modest machine, a few seconds delay could mean slowing down hundreds of thousands operations, which might cause severe stability issues for your application. This problem is a real life limitation for Redis users over AWS because most AWS instances are based on Xen. Our test scenarios in a nutshell were as follows — We ran Redis (version 2.4.17) on top of the following platforms:
- Regular Xen hypervisor instances – m1.small, m1.large, m1.xlarge, m2.2xlarge
- Xen HVM (Hardware Virtual Machine or Hardware-assisted virtualization) instance – i.e. the Cluster Compute cc1.4xlarge
- Redis was configured with the AOF “fsync every second” policy, and auto AOF rewrite was turned off
- We populated 70%-80% of available memory with Redis objects, and then randomly rewrote to those objects at a very high throughput in order to “touch” as many memory pages as possible during the fork process
- We issued the BGREWRITEAOF command using redis-cli, and then looked at the latest_fork_usec field of Redis INFO. We repeated this process 3-5 times and recorded the average value of each test
A more detailed description of the test setup can be found at the end of this post. Here’s what we found out about the Fork times:
| Instance type | Memory limit | Memory used | Memory usage (%) | Fork time |
|---|---|---|---|---|
| m1.small | 1.7 GB | 1.22 GB | 71.76% | 0.76 sec |
| m1.large | 7.5 GB | 5.75 GB | 76.67% | 1.98 sec |
| m1.xlarge | 15 GB | 11.46 GB | 76.40% | 3.46 sec |
| m2.xlarge | 34 GB | 24.8 GB | 72.94% | 5.67 sec |
| cc1.4xlarge | 23. GB | 18.4 GB | 80.00% | 0.22 sec |
Fork time per GB of memory:
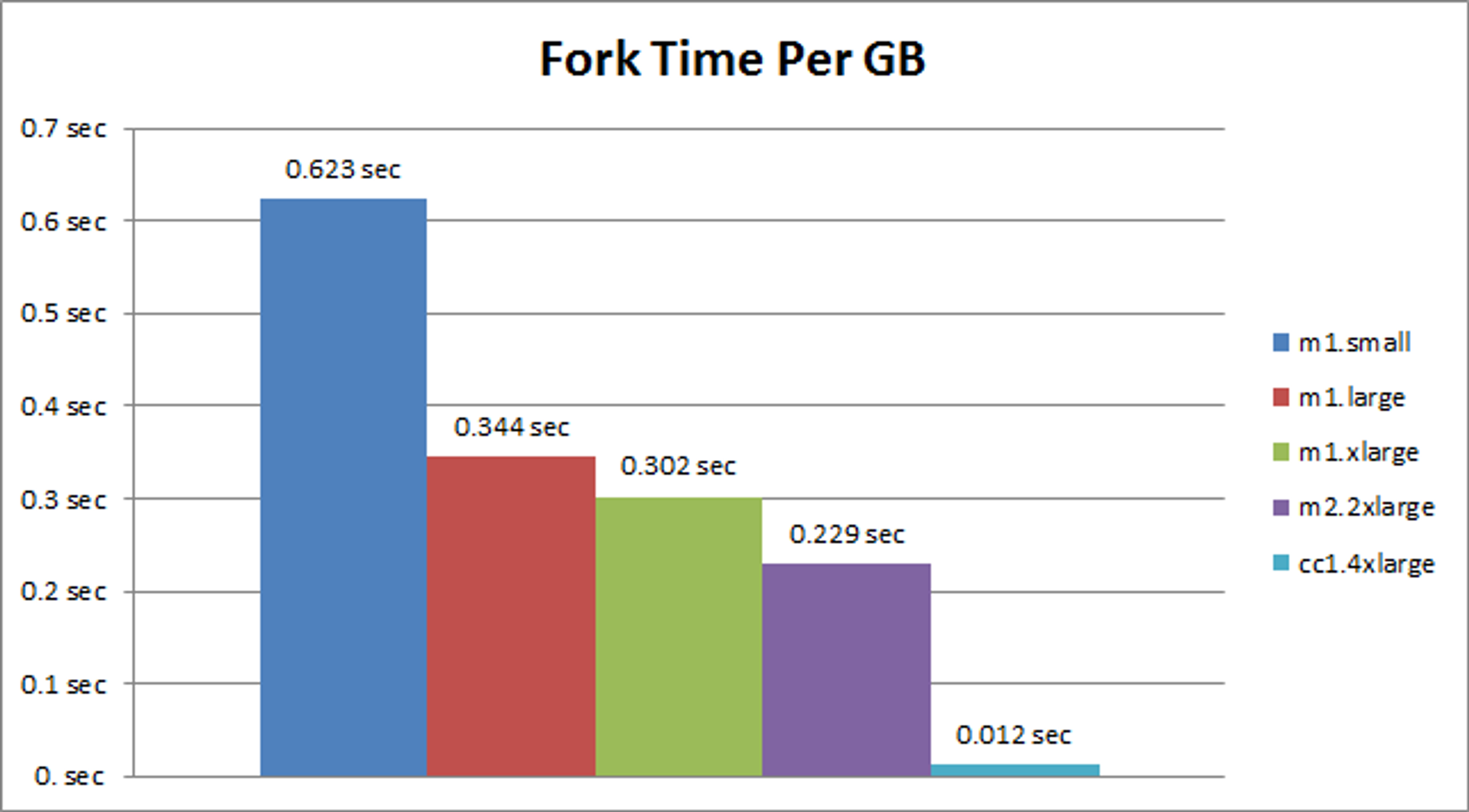
As you can see, there is a strong correlation between instance processing power and the execution time of fork operation. Moreover, the Xen HVM instance achieved significantly lower latency than the regular Xen hypervisor instances. So, should Redis users over AWS migrate their datasets to Cluster Compute instances? Not necessarily. Here’s why:
- The smallest Cluster Compute instance comes with 23GB and 33.5 EC2 Compute Units (2 x Intel Xeon X5570, quad-core “Nehalem” architecture). This is very expensive for most users, costing $936/month (over us-east-1 region using the on-demand plan) not including EBS storage space, storage I/O and network traffic.
- Although a Cluster Compute instance has many compute units (33.5), each of those units is relatively weak. When we tested Redis over a cc1.4xlarge instance, we saw similar results to what we achieved with m1.large at 25% of the cost. Clearly, the cc1.4xlarge is not optimized for high speed Redis.
Fork time and the Redis Cloud We tested fork times in similar scenarios on the Redis Cloud and compared the results to those of corresponding instances in a do-it-yourself (DIY) approach. This is what we found out:
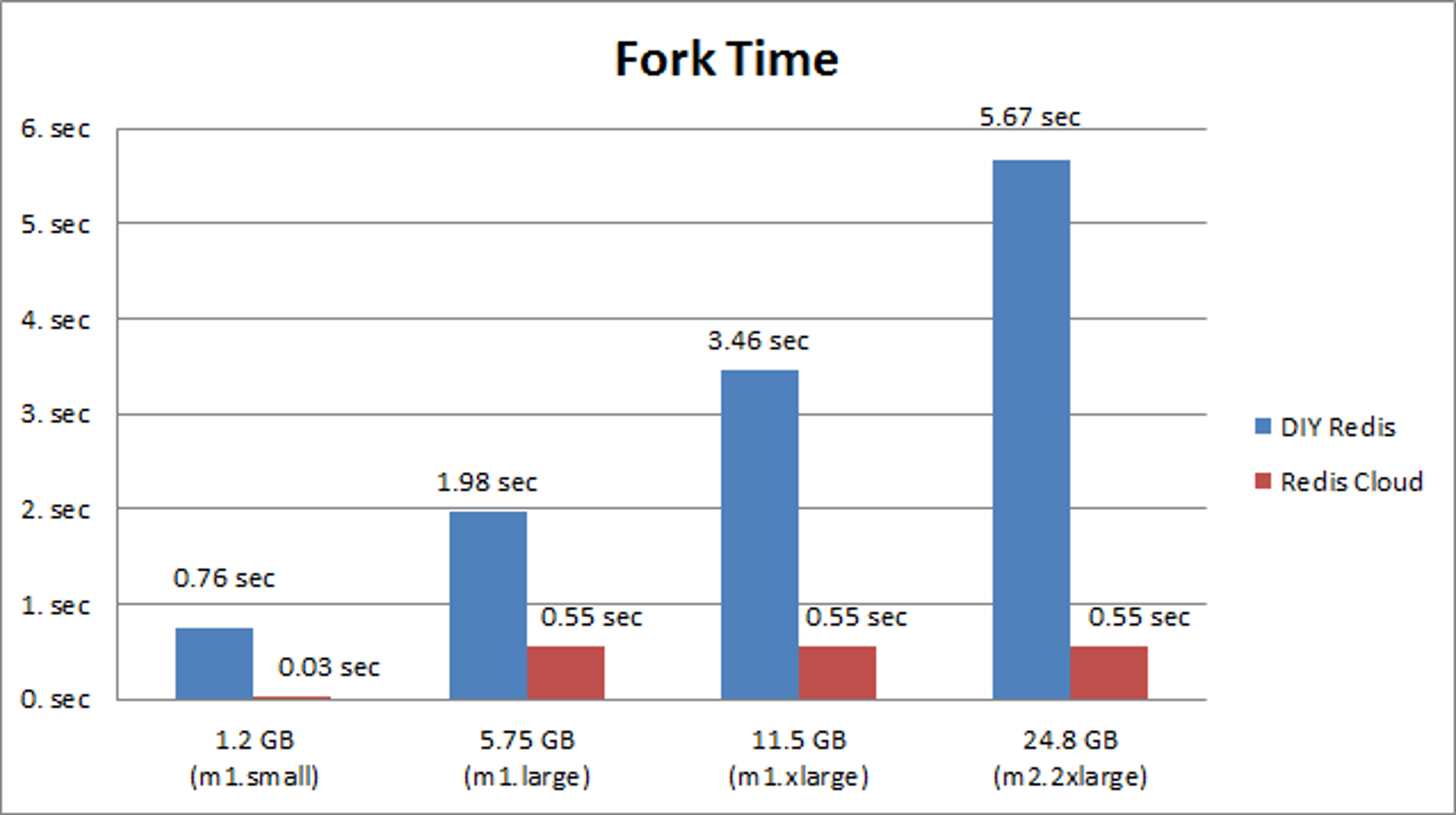
Fork time per GB of memory:
As you can see here, fork times are significantly lower with the Redis Cloud than with regular Xen hypervisor platforms. Furthermore, fork time per GB drops when dataset size grows. Fork times on the Redis Cloud are somewhat higher than those of Xen HVM (cc1.4xlarge instance) – for small datasets of about 1GB it is 0.03 seconds versus 0.008 seconds. However, since there is probably a correlation between the size of your dataset and the rate your app is accessing Redis, the amount of delayed requests when using the Redis Cloud should be small. For larger datasets, the Redis Cloud fork time is 0.03 seconds per GB compared to 0.01 seconds for Xen HVM. Nevertheless, we still prefer to use m2.2xlarge and m2.4xlarge instances over cc1.4xlarge and and cc2.8xlarge instances in the Redis Cloud, for the following reasons:
- m2.2xlarge and m2.4xlarge instances have more memory than cc1.4xlarge and cc2.8xlarge (respectively)
- Each Redis process runs x2-x3 times faster with m2.2xlarge and m2.4xlarge instances
- One can easily set in-memory replication in the Redis Cloud, which totally eliminates fork time issues. In this configuration, slave shards handle persistent storage access, while master shards are fully dedicated to processing client requests.
How does the Redis Cloud minimize fork time? The Redis Cloud applies several mechanisms and technologies to maintain high performance:
- We run all users’ datasets on the most powerful AWS instances – m2.2xlarge and m2.4xlarge
- We use several memory optimization techniques and consequently occupy less memory pages
- We auto-shard large datasets – this ensures low, predictable fork time for any dataset size
Conclusions We validated in this test that the fork process on AWS standard Xen hypervisor instances causes significant latency on Redis operations (and therefore on your application performance). Fork time per GB somewhat improves with stronger instances, but it is still unacceptable in our opinion. While fork time is practically eliminated when using AWS Cluster Compute instances, these instances are very expensive and are not optimized for Redis operations. The Redis Cloud provides minimal fork times at affordable infrastructure prices, and our fork times drop even further when dataset sizes grow. Benchmark test setup For those who want to know more about our benchmark, here are some details on the resources we used:
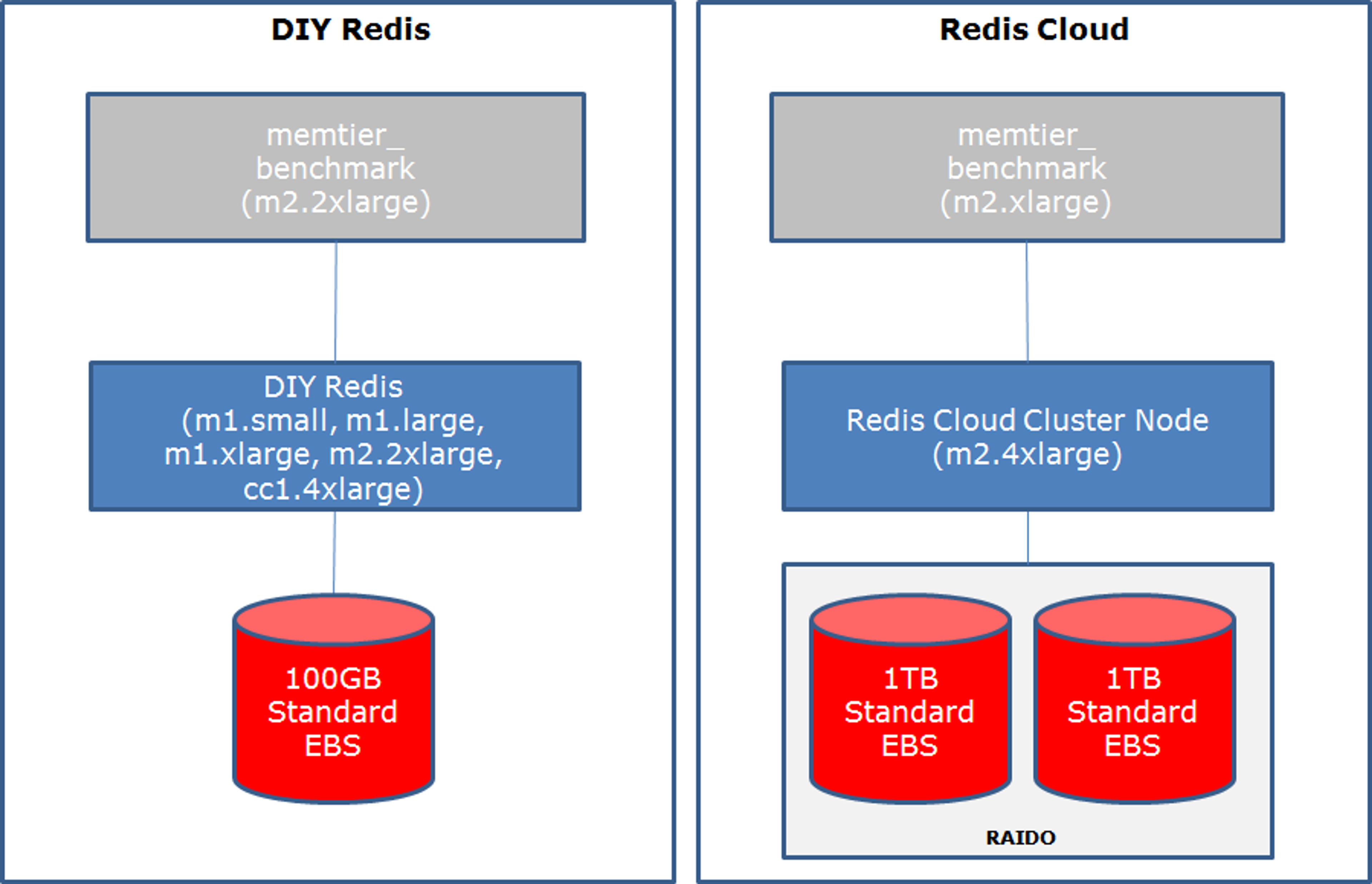
- Do-It-Yourself (DIY) Redis:
- Instances: m1.small, m1.large, m1.xlarge, m2.2xlarge and cc1.4xlarge
- Standard EBS volumes: 100GB for all instances (non-raided)
- A Redis Cloud cluster on m2.4xlarge instances using standard EBS volume of 2x1TB (raided) on each cluster node
This was our setup for generating load:
- m2.2xlarge instance that ran our memtier_benchmark load generation tool (an advanced load generator tool we developed, which we will soon share in our github account).
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.