
Following the recent launch of Redis 7.2, which underscores our dedication to advanced developer tools and AI innovation, Redis is thrilled to announce the integration of Redis Cloud with Amazon Bedrock as a knowledge base for building RAG applications.
AWS designed Amazon Bedrock with customer needs in mind: seamless access to powerful foundation models (FMs) without complex infrastructure management, accompanied by the ability to customize these FMs securely. Today’s announcement ensures that developers can use a unified API to access FMs from Cohere, AI21 Labs, Anthropic, Stability AI, and Amazon, backed by a high-performance data layer (Read the AWS announcement on their blog here).
What this means for the Redis community
The traction Redis Cloud has garnered as a highly-performant, stable vector database doesn’t surprise many people, given the company’s investments in enterprise-grade capabilities such as high availability, persistence, scalability, and geo-replication for business continuity.
In the past, merging private, domain-specific data with the capabilities of a large language model (LLM) was labor-intensive for Redis developers. The routine was multifaceted: extract source documents, morph them into embeddings, feed them into Redis, and then, on demand, execute complex vector search queries.
The newly established integration between Redis and Amazon Bedrock marks a pivotal step in streamlining the generative AI development process. By seamlessly connecting Redis to Agents for Amazon Bedrock as an external knowledge base, it bridges the gap between your domain-specific data and the vast capabilities of LLMs. This synergy automates the import of business documents from Amazon S3 (PDF, doc, txt, etc.) into Redis Cloud, freeing developers from the complex chore of data preparation and integration. With this foundation, the intelligent agents crafted using Amazon Bedrock can enrich model prompts, extracting relevant context from Redis via Retrieval Augmented Generation (RAG).
Why RAG is all the rage
On their own, LLMs can be clever and even astonishing, but they certainly are not infallible. Without domain-specific data, an LLM’s relevance and utility diminishes. Simply put, while LLMs have a wealth of general knowledge, the magic happens when they adapt to your specific data.
Training and fine-tuning LLMs on custom data to fit your needs may require significant computational firepower, however, and that introduces new costs. RAG aims to solve this problem: to bridge the gap between the LLM’s general knowledge and your own valuable data.
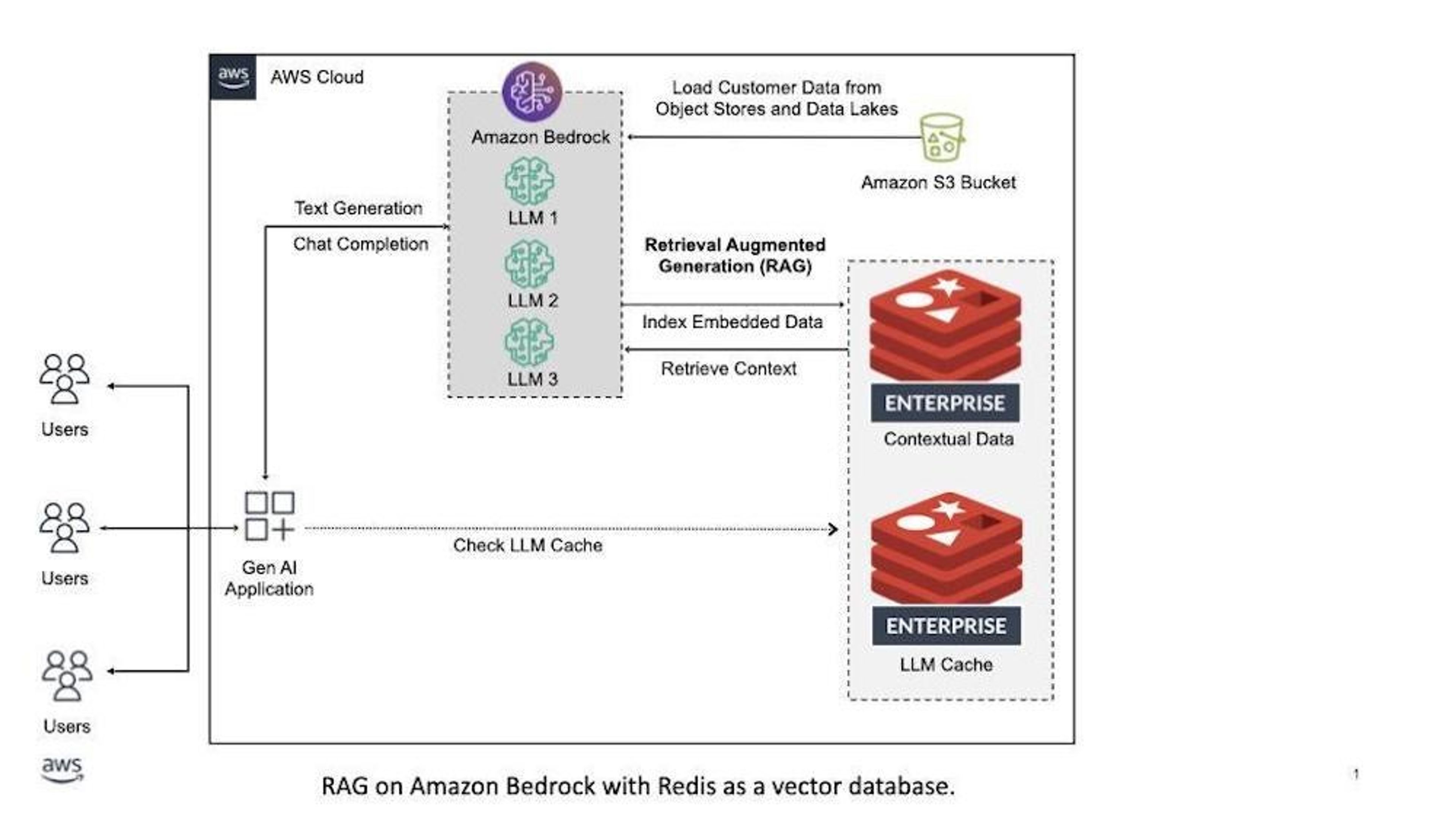
This reference architecture highlights:
- Data integration directly from Amazon S3
- Embedding generation using your selected LLM on Bedrock
- Embedding storage in Redis
- RAG for context retrieval from Redis to enrich LLM prompts
- LLM caching: semantic cache Redis to improve query response throughput and optimize costs
Contextual relevance: Redis Enterprise stores and indexes domain-specific data as vector embeddings. At runtime it fetches the most contextually relevant data chunks using vector similarity search based on a user’s query. By incorporating this retrieved context into the LLM prompt (input), it ensures that outputs are tailored to your domain.
Scalability: As your knowledge base expands, Redis Enterprise scales horizontally by sharding data and search indices across a distributed cluster.
Security: You don’t want sensitive data or knowledge leaked by mistake. Safeguard critical data from being incorporated into the central LLM by housing it externally in a vector database–like Redis. This ensures adherence to the highest security standards, including encryption at rest and in transit, along with robust role-based access controls.
Cost effectiveness: The integration reduces the need for continuous LLM training or fine-tuning. The result? You save both in computational requirements (faster chatbot performance) and costs.
The union of Redis Cloud and Agents for Amazon Bedrock redefines generative application potential on the technology side of things, and reduces time to market, which makes the business happy.
Two ways you might use this
Let’s consider practical examples.
Customer support
As businesses scale, addressing customer inquiries promptly and efficiently becomes increasingly challenging. Traditional chatbots may fall short in providing accurate or contextually-aware responses.
By connecting a company’s extensive knowledge base or FAQ database with a vector database, a RAG system can empower chatbots to pull real-time, context-specific information. For instance, a user might ask about a specific product feature or troubleshooting step; the RAG-backed bot would then retrieve the most relevant details from the database and generate a coherent, helpful response, improving customer satisfaction and reducing manual intervention.
Marketing and content creation
Content marketers often need to write articles, blog posts, or promotional materials that resonate with specific audience segments, but it can be time-consuming to find relevant past content for reference or inspiration.
By converting previous marketing materials, product documentation, customer feedback, and market research into vector embeddings, a RAG system can assist content creators in generating new content. For instance, when crafting a new article about a product feature, the system can pull relevant customer testimonials, past marketing angles, and current market trends, enabling the writer to create a more compelling and informed piece.
Getting started
To begin using both Amazon Bedrock for generative AI and Redis Cloud as your vector database, you create a database through the AWS Marketplace, set up an AWS secret using Amazon Secrets Manager, and then create an index for vector similarity search within Redis Cloud.
Create your Redis Enterprise deployment on AWS Marketplace
Whether you link from the Amazon Bedrock knowledge base configuration screen or use this customized link to the AWS Marketplace offering, you will create a flexible, pay-as-you-go subscription for Redis Cloud with TLS enabled. If you are new to Redis,we give you a 14-day free trial of $500 to get started.
Follow this detailed guide to create your Redis Cloud database.
Right-size your database for Amazon Bedrock
When you create the database, you eventually land on a step that requires inputting a “Memory limit (GB).”
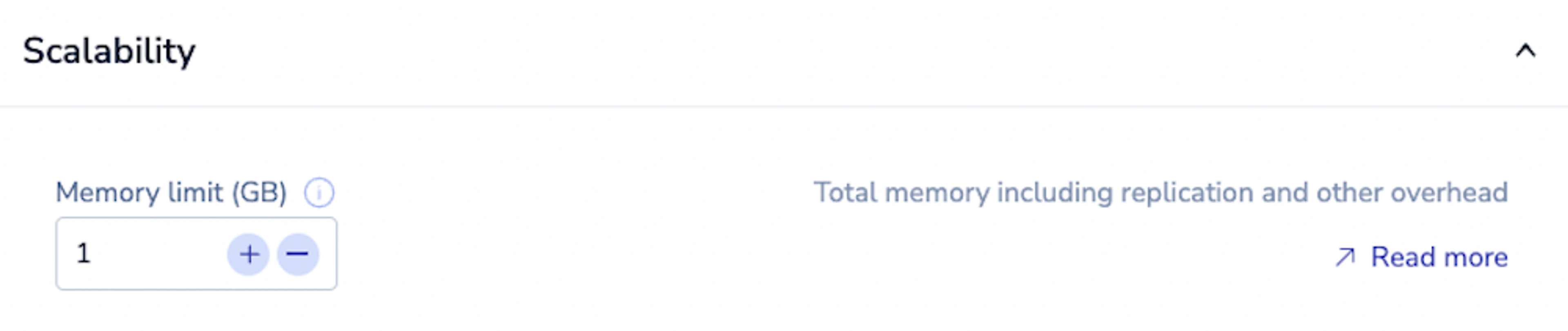
Sizing your database in the Redis Cloud console
Amazon Bedrock takes raw documents from Amazon S3, creates smaller chunks of text, generates embeddings and metadata, and upserts them in Redis as hashes. For RAG to work well, text chunks should capture just enough isolated semantic context from the source documents to be useful. Thus, Bedrock creates text chunks that are about 200 words long on average.
Let’s work through an example where you have a dataset in Amazon S3 that is 10,000KB in size. (Read more about figuring out the size of your bucket.)
- The average English word is 5 bytes. Bedrock creates chunks of about 200 words, so each chunk is typically 200 x 5 bytes = 1KB.
- Given the total size of the data in S3, we would expect 10,000KB / 1KB = 10,000 chunks.
- The Amazon Titan embedding model generates vectors with 1536 dimensions. Since each dimension is a Float32, this gives us 1536 x 4 bytes = 6.2KB per chunk. In order to have this embedding represented in the Redis search index, it yields a final size of about 12.5KB.
Pulling all of this together, we can estimate a final Redis database size as the sum of the raw text content, vector embedding, and vector index, multiplied by the total number of expected chunks:
(1KB + 12.5KB) * 10,000 expected chunks = 135,000KB
We created the table below to help you pick a reasonable starting point. While it is optional, we strongly recommend enabling high-availability (HA) with replication for any production deployment to ensure peak performance. You can always monitor and adjust this sizing in the Redis Cloud console as needed.
| Total size of documents in S3 | Database size without replication (no HA) | Database size with replication (HA) |
|---|---|---|
| 10,000KB | 135MB | 270MB |
| 100,000KB | 1.35GB | 2.7GB |
| 1,000,000KB | 13.5GB | 27GB |
| 10,000,000KB | 135GB | 270GB |
Store database credentials with Amazon Secrets Manager
After you create the database, use Amazon Secrets Manager to create a secret with the following fields:
- username: Database username
- password: Database password
- serverCertificate: Contents of the server certificate (redis_ca.pem)
- clientCertificate: Contents of the client certificate (redis_user.crt)
- clientPrivateKey: Contents of the client private key (redis_user_private.key)
Once you store this secret, you can view and copy the Amazon Resource Name (ARN) of your secret on the secret details page. If you need more help, follow this step-by-step guide to create the required connection secret.
Create a Redis vector index
After you set up your database within Redis Cloud, you need tocreate an index with a vector field as your knowledgebase for Amazon Bedrock.
With Redis you can build secondary indices on hash or JSON fields including text, tags, geo, numeric, and vectors. For vector similarity search, you must choose between a FLAT (brute-force) or HNSW (approximate, faster) vector index type, and one of three supported distance metrics (Inner Product, Cosine Distance, L2 Euclidean). Picking the right index type should be based on the size of your document dataset and the required levels of search accuracy and throughput.
For starting with Amazon Bedrock, we recommend a simple index configuration with the following settings:
- User defined index name: bedrock-idx
- User defined vector field name: text_vector
- Vector index type: FLAT
- AWS Titan model embedding dimensions: 1536
Assuming your documents dataset is not massive and you require the utmost retrieval accuracy for RAG, this index configuration is a solid starting point.
Out of the box, Redis provides a few options to create an index using RedisInsight, RedisVL, or the Redis command-line interface (CLI).
Use RedisInsight
RedisInsight is the desktop graphic user interface (GUI) to visually browse and interact with data in Redis. Follow the steps in our dedicated guide to create your vector index with RedisInsight.
Use RedisVL
RedisVL is a new, dedicated Python client library that helps AI and ML practitioners leverage Redis as a vector database.
First, install RedisVL in your Python (>=3.8) environment using pip:
pip install redisvl==0.0.4
Copy this YAML file that contains a basic Redis vector index spec for Amazon Bedrock and paste it into a local file named bedrock-idx.yaml:
You can now use the rvl command in a terminal to connect to the database and create a new index from the YAML schema definition.
Set the REDIS_URL environment variable that incorporates the username, password, host, port, and full paths to all three required TLS cert files:
Now, run the command to create the index. Watch for a success message:
rvl index create -s bedrock-idx.yaml
Validate that the index was created successfully using the listall or info commands:
rvl index info -s bedrock-idx.yaml
Use Redis CLI
To use the Redis CLI, download Redis on your local machine. Connect to your database with the CLI including TLS certs:
Execute the snippet below to create an index named bedrock-idx:
Configure Amazon Bedrock
At this point, everything should be ready. It’s time to integrate your Redis deployment with Amazon Bedrock as a knowledgebase for RAG.
✅ Redis database deployed
✅ AWS secret created
✅ Vector index created
On the Amazon Bedrock knowledgebase configuration screen select your source Amazon S3 bucket. Make sure Redis Cloud is selected as your vector database. Plug in your database Endpoint URL, Credentials secret ARN, and Vector index name.
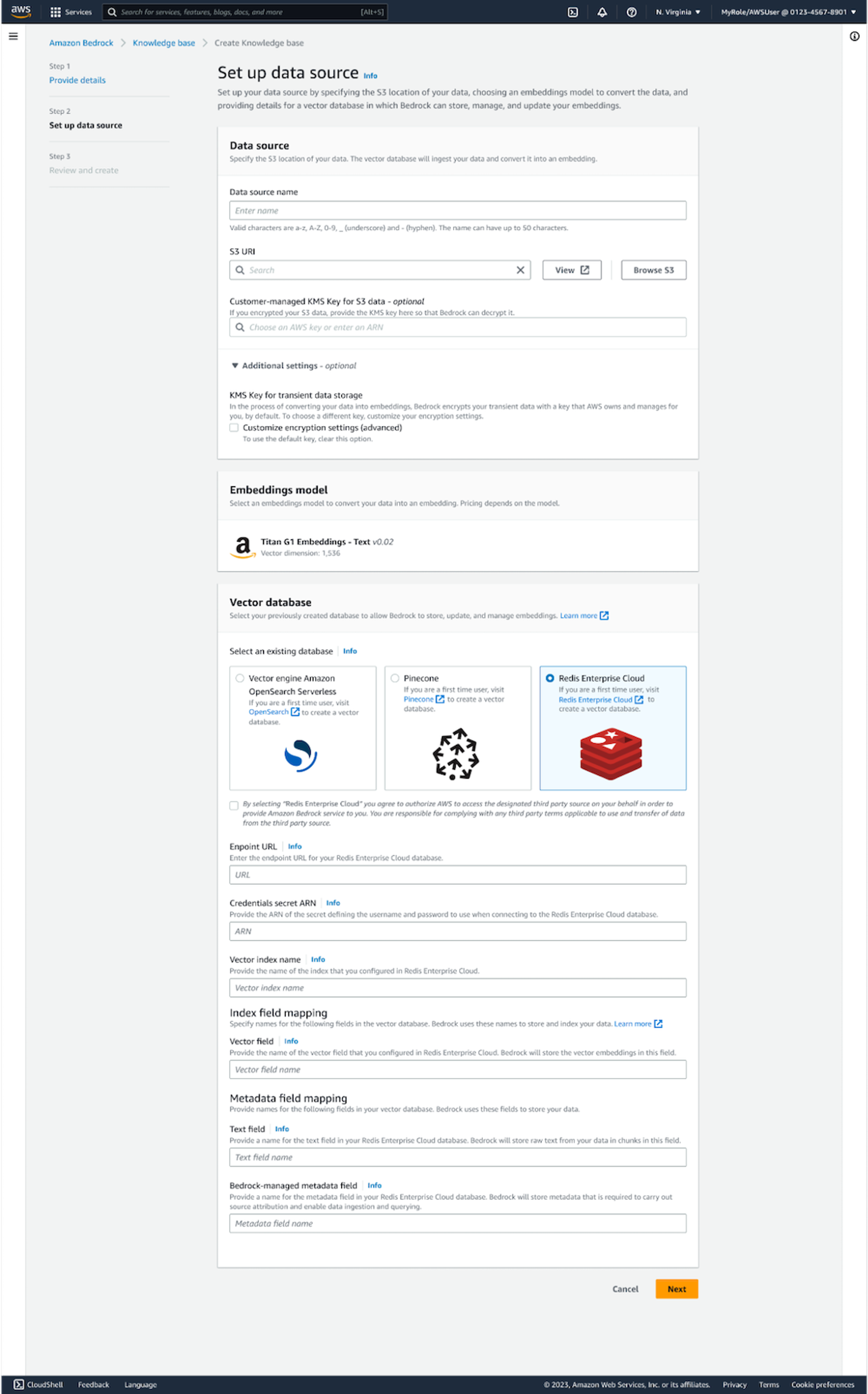
Amazon Bedrock configuration screen for selecting your vector database
Finally, plug in user-defined name for your Index field mapping and Amazon Bedrock-created Metadata field mapping. These are created automatically by Amazon Bedrock when processing your source data from Amazon S3.
Your next steps
Ready to begin your generative AI journey with Redis Cloud and Amazon Bedrock? Start by visiting the Amazon Bedrock page, in the AWS console, and read the AWS announcement here.
Have a use case or example you want to highlight? Kick the tires and open a PR with a community example in our github repo.
Want to go deeper after trying out this integration or need additional assistance? We’re here to help. Contact a Redis expert today.
Test the full power of Redis Enterprise with no upfront costs or commitments. Our new 14-day free trial comes with everything Redis Enterprise has to offer and is available in AWS Marketplace. Get started for free today!
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.