Blog
Collaborative filtering: How to build a recommender system

Collaborative filtering predicts what a user will like by learning from patterns in other users' behavior. It's how Netflix can suggest a movie you've never searched for, based on what you (and people like you) watched before. If your app has users and a catalog of anything (products, content, jobs, music), collaborative filtering is often one of the most impactful ranking signals you can add.
The idea predates modern AI and machine learning. Early recommender systems appeared soon after the web, and the core idea of learning from patterns in user-item interactions still underpins many large-scale recommendation systems today, even as models have evolved. This article covers what collaborative filtering is, how it works, the main types, where it's used, and how to build a movie recommendation system with Redis and RedisVL.
How does collaborative filtering work?
Collaborative filtering finds patterns in user-item interactions (ratings, purchases, views, likes) and uses them to predict what a user will engage with next. When two users behave similarly across a set of items, the system infers they'll agree on items neither has tried yet. Those inferred preferences become recommendations.
Under the hood, interactions go into a user-item matrix: rows are users, columns are items, and each cell holds a signal like a star rating or purchase indicator. Most cells are empty because no user interacts with every item, so collaborative filtering's job is to fill in those gaps. In production, that means you need fast access to user vectors, item vectors, and interaction data at query time, which is why many teams store the decomposed user and item vectors (along with related interaction features) in an in-memory datastore like Redis rather than recomputing from the full matrix.
What are the types of collaborative filtering?
Collaborative filtering comes in two main types: memory-based and model-based. The difference is whether you compute similarity directly from the interaction data or learn a predictive model from it.
Memory-based collaborative filtering
Memory-based collaborative filtering generates recommendations directly from the user-item matrix. It compares users or items with similarity metrics (often cosine similarity or Pearson correlation) and recommends items based on the nearest neighbors. There are two types:
- User-based collaborative filtering finds users with similar histories and recommends items those similar users liked.
- Item-based collaborative filtering finds items that tend to be engaged with together. This approach is often more stable over time because item-to-item relationships typically change less frequently than individual preferences.
In a naive implementation, both approaches compute similarities at query time, which gets expensive as your user and item counts grow. Production systems typically precompute and cache similarity neighborhoods offline to avoid this.
Model-based collaborative filtering
Model-based collaborative filtering learns latent "factors" that represent users and items in a shared vector space. Instead of comparing users or items directly, it uses machine learning techniques, from classical matrix factorization like Singular Value Decomposition (SVD) to more recent neural recommender models, to predict missing preference scores in the user-item matrix.
Because the model learns compact user and item vectors, it can make predictions even when the interaction matrix is sparse. These vectors are also what make model-based approaches easier to scale in large systems: instead of recomputing neighbor similarity on demand, you store precomputed vectors and run fast lookups at query time.
Collaborative filtering vs. content-based filtering
The other major approach to recommendations is content-based filtering, which works from the opposite direction. Instead of learning from user behavior, it builds a profile of each user's preferences from item features (genre, keywords, description) and recommends items with similar attributes.
Collaborative filtering can surface recommendations that a content-based system would miss because it's driven by co-occurrence and shared taste, not metadata similarity. The trade-off is that content-based filtering depends on item features rather than interaction history, so it's generally less affected by cold start when good metadata is available.
| Aspect | Collaborative filtering | Content-based filtering |
|---|---|---|
| Data source | User-item interactions & ratings | Item features & metadata |
| Cold start | Struggles with new users & items | Generally less affected when rich item metadata exists |
| Recommendation diversity | Can surface unexpected items | Limited to similar item types |
| Item metadata required | No | Yes |
| Personalization basis | Community behavior patterns | Individual preference history |
| Scalability | Can be intensive without approximate neighbors or precomputation | Often simpler to scale when item feature extraction is cheap |
Where is collaborative filtering used?
Collaborative filtering shows up anywhere a platform needs to rank a large catalog for individual users. Online, there are always too many options, and too many options lead to analysis paralysis. That dynamic makes collaborative filtering one of the most common ranking techniques across industries:
- E-commerce platforms aren't bound by physical shelves, so catalogs can be massive. Collaborative filtering helps surface relevant products by learning from what similar shoppers browse, purchase, and rate. A 2025 systematic review of e-commerce recommendation systems found it was the most frequently used method across the studies analyzed.
- Streaming services like Netflix and Spotify use collaborative filtering to suggest content based on the behavior patterns of similar users. Netflix famously sponsored a $1 million prize in 2009 to beat its recommendation algorithm. Spotify's approach has evolved to focus on playlist co-occurrence, learning track embeddings from how users organize songs together rather than just listening history alone.
- Social media platforms rely on massive user bases and network effects, making them a natural fit for collaborative filtering. Research on TikTok's For You Page found it uses a blend of collaborative filtering and content-based filtering to personalize content delivery, grouping users with similar behaviors to surface relevant videos.
- Job matching platforms use collaborative filtering to connect candidates with roles based on how similar users have engaged with job listings. A 2025 literature review found collaborative filtering is one of the most common approaches in job recommender systems, though most production systems now combine it with content-based methods.
The same approach extends to news personalization, ad targeting, and anywhere users face information overload.
What are the advantages & disadvantages of collaborative filtering?
With that range of applications in mind, it's worth understanding where collaborative filtering works well and where it breaks down. It's strongest when you have lots of interaction data and want recommendations that reflect real user behavior. It struggles when there isn't enough history (cold start) and when popularity and scale skew results.
Advantages
Because it learns from observed behavior, collaborative filtering often captures "taste" signals that aren't easy to represent with item features alone. That makes it useful in domains where metadata is incomplete, inconsistent, or expensive to maintain.
It can also surface unexpected items. Behavioral overlap can connect items that look unrelated on paper but still resonate with the same users.
Disadvantages
The biggest drawback is cold start: when the system has little or no interaction data, it can't make good predictions.
It can also get expensive at scale, especially for similarity-heavy approaches, and it can reinforce popularity. Items with many interactions get recommended more, while niche items with sparse data get overlooked, reducing diversity in long-tail catalogs.
How to build a collaborative filtering system with Redis
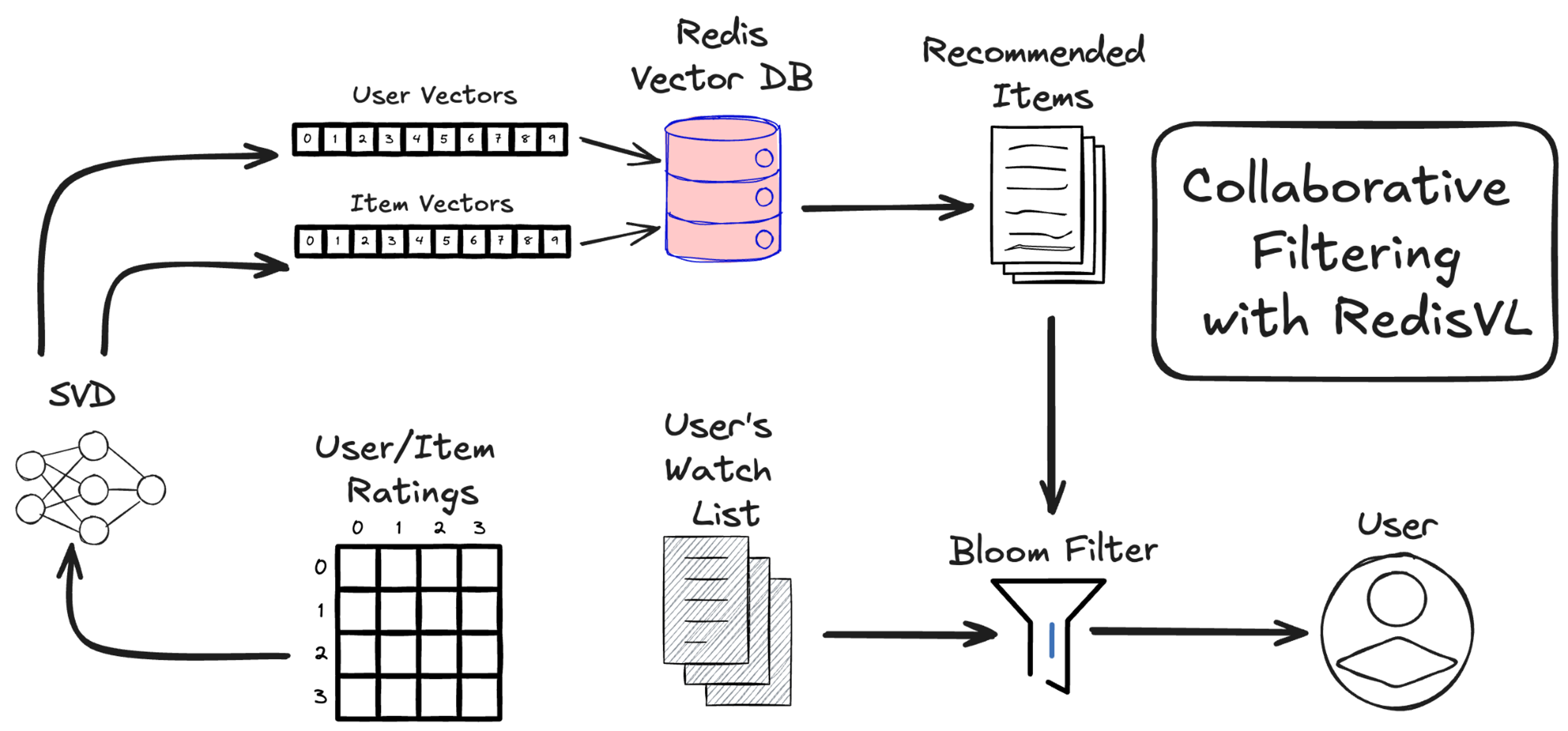
With Redis, you use real-time, low-latency capabilities to build scalable, AI-powered recommendation systems. In environments where real-time data processing is necessary to make the best recommendations, Redis’ sub-millisecond response times and vector database capabilities can help you deliver seamless user experiences.
Here, we’ll walk through how to build a movie recommendation system supported by collaborative filtering using RedisVL and the IMDB movie dataset.
You can run it yourself or clone the repo here.
The algorithm we’ll be using is the Singular Value Decomposition, or SVD, algorithm. It works by looking at the average ratings users have given to movies they have already watched. Below is a sample of what that data might look like.
| User ID | Movie ID | Rating (0 to 5) |
|---|---|---|
| 1 | 31 | 2.5 |
| 1 | 1029 | 3.0 |
| 1 | 1061 | 3.0 |
| 1 | 1129 | 2.0 |
| 1 | 1172 | 4.0 |
| 2 | 10 | 4.0 |
| 2 | 17 | 5.0 |
| 3 | 60 | 3.0 |
| 3 | 110 | 4.0 |
| 3 | 247 | 3.5 |
| 3 | 267 | 3.0 |
| 3 | 296 | 4.5 |
| 3 | 318 | 5.0 |
| … | … | … |
Unlike content filtering, which is based on the features of the recommended items, collaborative filtering looks at the user’s ratings and only the user’s ratings.
Singular value decomposition
It’s worth going into more detail about why we chose this algorithm and what it is computing in the methods we’re calling.
First, let’s think about what data it’s receiving—our ratings data. This only contains the user IDs, movie IDs, and the user’s ratings of the movies they watched on a scale of 0 to 5. We can put this data into a matrix with rows being users and columns being movies.
| RATINGS | Movie 1 | Movie 2 | Movie 3 | Movie 4 | Movie 5 | Movie 6 | … |
|---|---|---|---|---|---|---|---|
| User 1 | 4 | 1 | 4 | 5 | |||
| User 2 | 5 | 5 | 2 | 1 | |||
| User 3 | 1 | ||||||
| User 4 | 4 | 1 | 4 | ? | |||
| User 5 | 4 | 5 | 2 | ||||
| … |
Our empty cells are missing ratings—not zeros—so user 1 has never rated movie 3. They may like it or hate it.
Unlike content-based filtering, here, we only consider the ratings that users assign. We don’t know the plot, genre, or release year of any of these films. However, we can still build a recommender by assuming that users have tastes similar to each other.
As an intuitive example, we can see that user 1 and user 4 have very similar ratings on several movies, so we can assume that user 4 will rate movie 6 highly, just as user 1 did.
Since we only have this matrix to work with, what we want to do is decompose it into two constituent matrices.
Let’s call our ratings matrix [R]. We want to find two other matrices, a user matrix [U] and a movies matrix [M], that fit the equation:
[U] * [M] = [R]
[U] will look like:
| User 1 feat 1 | User 1 feat 2 | User 1 feat 3 | User 1 feat 4 | … | User 1 feat k |
|---|---|---|---|---|---|
| User 2 feat 1 | User 2 feat 2 | User 2 feat 3 | User 2 feat 4 | … | User 2 feat k |
| User 3 feat 1 | User 3 feat 2 | User 3 feat 3 | User 3 feat 4 | … | User 3 feat k |
| … | … | … | … | … | … |
| User N feat 1 | User N feat 2 | User N feat 3 | User N feat 4 | … | User N feat k |
[M] will look like:
| Movie 1 feat 1 | Movie 2 feat 1 | Movie 3 feat 1 | Movie 4 feat 1 | … | Movie M feat 1 |
|---|---|---|---|---|---|
| Movie 1 feat 2 | Movie 2 feat 2 | Movie 3 feat 2 | Movie 4 feat 2 | Movie M feat 2 | |
| Movie 1 feat 3 | Movie 2 feat 3 | Movie 3 feat 3 | Movie 4 feat 3 | Movie M feat 3 | |
| Movie 1 feat 4 | Movie 2 feat 4 | Movie 3 feat 4 | Movie 4 feat 4 | Movie M feat 4 | |
| … | … | … | … | ||
| movie 1 feat k | Movie 2 feat k | Movie 3 feat k | Movie 4 feat 4 | Movie M feat k |
These features are the latent features (or latent factors) and are the values we’re trying to find when we call the svd.fit(train_set) method. The algorithm that computes these features from our ratings matrix is the SVD algorithm.
Our data sets the number of users and movies. The size of the latent feature vectors k is a parameter we choose. We’ll keep it at the default 100 for this notebook.
A look at the code
Grab the ratings file and load it up with Pandas.
A lot is going to happen in the code cell below. We split our full data into train and test sets. We define the collaborative filtering algorithm to use, which in this case is the Singular Value Decomposition (SVD) algorithm. Lastly, we fit our model to our data.
Extract the user and movie vectors
Now that the SVD algorithm has computed our [U] and [M] matrices, which are both just lists of vectors, we can load them into our Redis instance. The Surprise SVD model stores user and movie vectors in two attributes:
svd.pu: user features matrix—a matrix where each row corresponds to the latent features of a user).
svd.qi: item features matrix—a matrix where each row corresponds to the latent features of an item/movie).
It’s worth noting that the matrix svd.qi is the transposition of the matrix [M] we defined above. This way, each row corresponds to one movie.
Predict user ratings in one step
The great thing about collaborative filtering is that using our user and movie vectors, we can predict the rating any user will give to any movie in our dataset. And unlike content filtering, there is no assumption that all the movies a user will be recommended are similar to each other. A user can get recommendations for dark horror films and light-hearted animations.
Looking back at our SVD algorithm, the equation is:
[User_features] * [Movie_features].transpose = [Ratings]
To predict how a user will rate a movie they haven’t seen yet, we just need to take the dot product of that user’s feature vector and a movie’s feature vector.
Add movie metadata to our recommendations
While our collaborative filtering algorithm was trained solely on users’ ratings of movies and doesn’t require any data about the movies themselves, such as the title, genre, or release year, we’ll want that information stored as metadata.
We can grab this data from our `movies_metadata.csv` file, clean it, and join it to our user ratings via the `movieId` column.
We’ll have to map these movies to their ratings, which we’ll do so with the `links_small.csv` file that matches `movieId`, `imdbId`, and `tmdbId`.
We’ll want to move our SVD user vectors and movie vectors and their corresponding userId and movieId into two dataframes for later processing.
RedisVL handles the scale
Especially for large datasets like the 45,000 movie catalog, like the one we’re dealing with here, you’ll want Redis to do the heavy lifting of vector search. All that you need is to define the search index and load the data we’ve cleaned and merged with our vectors.
For a complete solution, we’ll store the user vectors and their watched list in Redis, too. We won’t be searching over these user vectors, so there is no need to define an index for them. A direct JSON look up will do.
Unlike in content-based filtering, where we want to compute vector similarity between items and use cosine similarity between items vectors to do so, in collaborative filtering, we instead try to compute the predicted rating a user will give to a movie by taking the inner product of the user and movie vector.
This is why, in our schema definition, we use ‘ip’ (inner product) as our distance metric. It’s also why we’ll use our user vector as the query vector when we do a query. The distance metric ‘ip’ inner product is computing:
vector_distance = 1 – u * v
And it’s returning the minimum, which corresponds to the max of u * v. This is what we want. The predicted rating on a scale of 0 to 5 is then:
predicted_rating= -(vector_distance-1) = –vector_distance +1
Let’s pick a random user and their corresponding user vector to see what this looks like.
Add all the bells and whistles
Vector search handles the bulk of our collaborative filtering recommendation system and is a great approach to generating personalized recommendations that are unique to each user.
To up our RecSys game even further, we can use RedisVL Filter logic to get more control over what users are shown. Why have only one feed of recommended movies when you can have several, each with its own theme and personalized to each user?
| Top picks | Blockbusters | Classics | What’s popular | Indie hits | Fruity films |
|---|---|---|---|---|---|
| The Shawshank Redemption | Forrest Gump | Cinema Paradiso | The Shawshank Redemption | Castle in the Sky | What’s Eating Gilbert Grape |
| Forrest Gump | The Silence of the Lambs | The African Queen | Pulp Fiction | My Neighbor Totoro | A Clockwork Orange |
| Cinema Paradiso | Pulp Fiction | Raiders of the Lost Ark | The Dark Knight | All Quiet on the Western Front | The Grapes of Wrath |
| Lock, Stock and Two Smoking Barrels | Raiders of the Lost Ark | The Empire Strikes Back | Fight Club | Army of Darkness | Pineapple Express |
| The African Queen | The Empire Strikes Back | Indiana Jones and the Last Crusade | Whiplash | All About Eve | James and the Giant Peach |
| The Silence of the Lambs | Indiana Jones and the Last Crusade | Star Wars | Blade Runner | The Professional | Bananas |
| Pulp Fiction | Schindler’s List | The Manchurian Candidate | The Avengers | Shine | Orange County |
| Raiders of the Lost Ark | The Lord of the Rings: The Return of the King | The Godfather: Part II | Guardians of the Galaxy | Yojimbo | Herbie Goes Bananas |
| The Empire Strikes Back | The Lord of the Rings: The Two Towers | Castle in the Sky | Gone Girl | Belle de Jour | The Apple Dumpling Gang |
Keep things fresh with Bloom filters
You’ve probably noticed that a few movies get repeated in these lists. That’s not surprising as all our results are personalized, and things like popularity, rating, and revenue are likely highly correlated. And it’s more than likely that at least some of the recommendations we’re expecting to be highly rated by a given user are ones they’ve already watched and rated highly.
We need a way to filter out movies that a user has already seen and movies that we’ve already recommended to them before. We could use a Tag filter on our queries to filter out movies by their ID, but this gets cumbersome quickly.
Luckily, Redis offers an easy answer to keeping recommendations new and interesting: Bloom Filters.
| Top picks | Blockbusters | Classics | What’s popular | Indie hits |
|---|---|---|---|---|
| Cinema Paradiso | The Manchurian Candidate | Castle in the Sky | Fight Club | All Quiet on the Western Front |
| Lock, Stock and Two Smoking Barrels | Toy Story | 12 Angry Men | Whiplash | Army of Darkness |
| The African Queen | The Godfather: Part II | My Neighbor Totoro | Blade Runner | All About Eve |
| The Silence of the Lambs | Back to the Future | It Happened One Night | Gone Girl | The Professional |
| Eat Drink Man Woman | The Godfather | Stand by Me | Big Hero 6 | Shine |
What's new in Redis for recommendation workloads
Recent Redis releases have made vector-based recommendation patterns even more practical. Redis 8.4 introduced hybrid search through the FT.HYBRID command, combining full-text and vector search into a single ranked result list. Redis 8.6 improved vector set insertion performance by up to 43% and querying performance by up to 58% compared to 8.4, with significantly higher overall throughput compared to Redis 7.2 for typical caching workloads.
For recommendation systems specifically, these improvements mean faster index updates when user behavior changes and lower-latency lookups at query time—both of which matter when you're serving personalized results in real time.
Collaborative filtering is a signal in hybrid recommenders
In production, collaborative filtering is usually one input to a hybrid recommendation stack, not the whole system. Teams often blend collaborative signals with content-based features and real-time context to improve ranking quality and handle common gaps like cold start.
In these setups, collaborative filtering still does important work: it captures behavioral similarity (who behaves like whom, and which items co-occur) and turns that into features for downstream ranking models. Depending on the product, those features may be combined with other context, like session activity or LLM-generated summaries.
This kind of ranking pipeline puts pressure on infrastructure. You need to fetch user vectors, item vectors, and recent interaction features with low latency, which is why many teams keep this data in an in-memory layer. Redis fits naturally here: it stores vectors alongside operational data like session state and feature values in a single system, so you don't need to manage a separate vector database for your recommendation vectors.
Recent Redis releases have continued to improve vector and search performance, with Redis 8.4 introducing hybrid search and Redis 8.6 delivering further gains in vector set operations and overall throughput.
If you're exploring that pattern, the RedisVL vector library supports apps that combine vector search with operational data access. Related walkthroughs include the two-tower recommendation system tutorial with RedisVL and the product recommendation engine guide.
If you want to evaluate Redis for recommendation workloads, you can try Redis free or talk to our team about your personalization infrastructure.
FAQs about collaborative filtering
How does collaborative filtering handle the cold start problem for new users or items with no interaction history?
Collaborative filtering struggles with the cold start problem because it relies on interaction data to make predictions, and new users or items have none. To work around this, systems typically fall back to popularity-based rankings, content-based filtering, or onboarding surveys until enough behavioral data accumulates.
Hybrid architectures help by weighting collaborative signals lower when data is sparse and leaning on content features, contextual data, or demographic information instead. As interaction history builds, collaborative filtering gradually takes on a larger role in generating recommendations.
What is the difference between user-based & item-based collaborative filtering, & when should you use each approach?
User-based collaborative filtering recommends items enjoyed by people with similar taste profiles, while item-based collaborative filtering identifies items that are frequently engaged with together and suggests them based on those patterns.
Item-based approaches tend to work better in production because item relationships are more stable over time and scale more efficiently when users far outnumber items. User-based filtering is better suited to smaller systems with stable user populations or when community-driven discovery is a priority.
How does matrix factorization (SVD) work in model-based collaborative filtering to predict missing ratings?
Matrix factorization decomposes the sparse user-item interaction matrix into two smaller, dense matrices—one representing users and one representing items—across a set of hidden dimensions that emerge from behavioral patterns. To predict a missing rating, the system computes the dot product of the user's vector and the item's vector, producing an estimated engagement score.
The key advantage is compression: instead of storing millions of user-item pairs, the system uses compact factor vectors (typically 20–200 dimensions) that make real-time inference faster, more memory-efficient, and better at handling data sparsity.
How do hybrid recommender systems combine collaborative filtering with content-based filtering in production?
Hybrid recommender systems run collaborative filtering and content-based filtering as parallel pipelines that feed into a unified ranking layer. Collaborative filtering generates embeddings from behavioral data, while content-based filtering extracts features from item metadata like descriptions, categories, or tags. These signals are merged using ensemble methods such as weighted averaging or gradient-boosted trees.
More advanced setups use deep learning to combine collaborative embeddings with content features in a shared neural network, and the final ranking often incorporates contextual signals like time of day or session behavior for more reliable recommendations.
What are the best practices for scaling collaborative filtering to handle millions of users & items efficiently?
At scale, collaborative filtering shifts from real-time similarity computation to precomputed embeddings served from low-latency stores. Approximate nearest neighbor algorithms like Hierarchical Navigable Small World (HNSW) trade small accuracy losses for massive speed gains, while dimensionality reduction keeps vectors compact without sacrificing much predictive power.
Production systems also rely on batch pipelines to update embeddings periodically, sharding to distribute data across nodes, and caching for frequently accessed profiles. Monitoring data skew is critical, since power-law distributions can create hotspots that require careful load balancing.
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.