Blog
Running a Machine Learning Data Store on Redis Labs

Utilizing a machine learning API to create a scalable model artifact pipeline
Managing large, pre-trained predictive models across an organization and ensuring the same version is in production can be a challenge with the rapid pace of changes in the AI/machine learning space. Here, we have an approach that demonstrates how to automate building, storing, and deploying predictive models from a Remote Machine Learning Data Store hosted on Redis. This approach is focused on showing how DevOps CI/CD artifact pipelines can be used to build and manage machine learning model artifacts with Jupyter IPython notebooks, accompanying command line automation versions, and administration tools to help manage artifacts across a team. By utilizing DevOps for your machine learning build workflows you can easily manage model deployments across intelligent environments.
The Basics—What Are We Automating?
In general, machine learning workflows share these common steps to create a predictive model:
1. Define a dataset
2. Slice the dataset up into train and test sets
3. Build your machine learning algorithm model
4. Train the model
5. Test the model
We wanted to share how to automate these common steps within a machine learning pipeline under a server API that creates model artifacts on completion. Artifacts are dictionaries containing the models’ analysis, accuracy, predictions, and binary model objects. Once the artifact is created, it can be compressed as a pickle serialized object and uploaded to a configurable S3 location or in another persistent storage location. This post is also a demonstration for designing a machine learning API with a pseudo-factory to abstract how each step works and the underlying machine learning model implementation. This approach lets a team focus on improving model predictive accuracy, improving a dataset’s features, sharing models across an organization, helps with model evaluation, and deploying pre-trained models to new environments for automation and live intelligent service layers that need to make predictions or forecasts in real-time.
What Does the Workflow Look Like?
Here is the workflow for using a machine learning data store powered by Redis and an S3 artifact backbone:
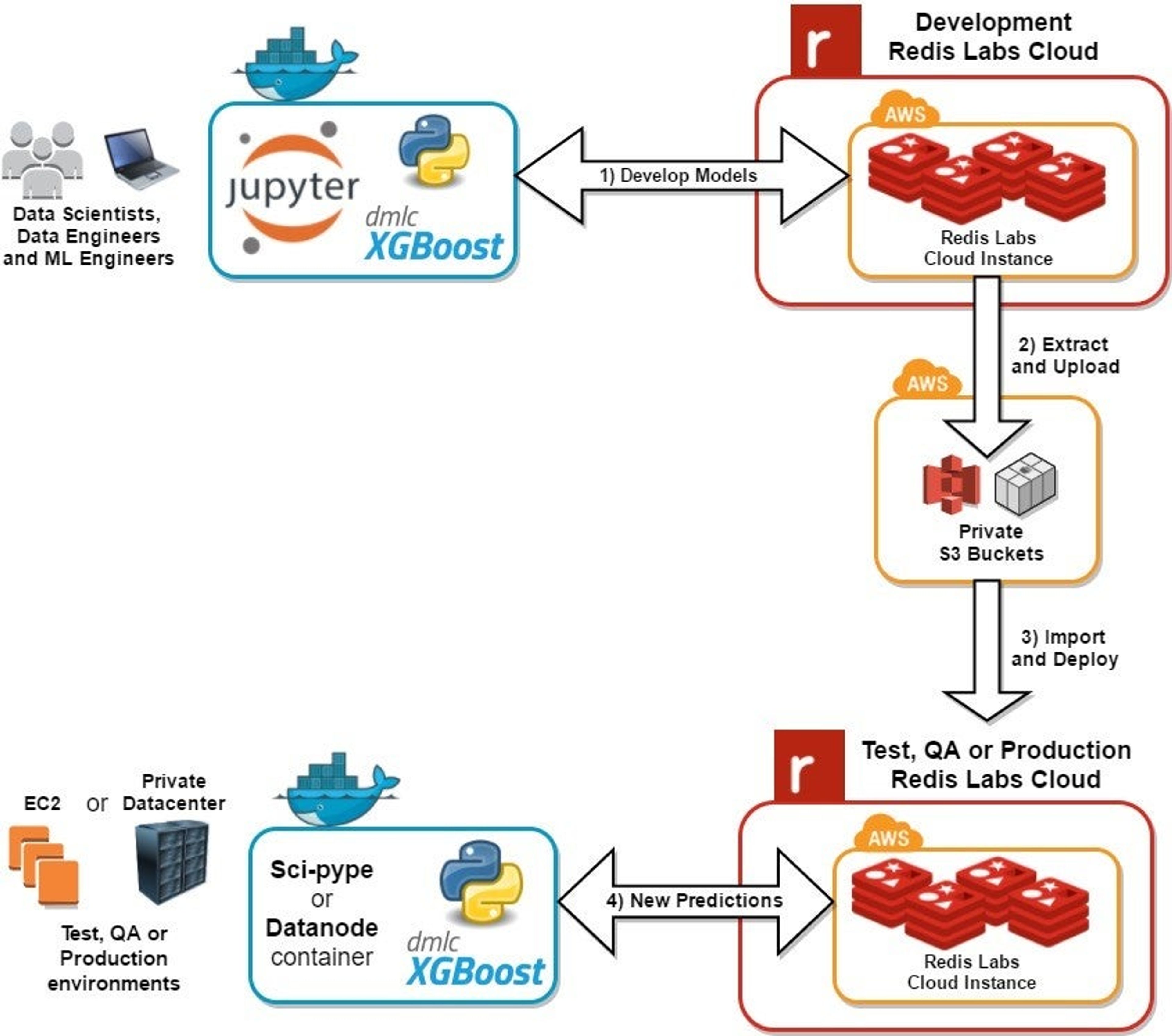
This workflow is built to help find highly predictive models because it uses an API that can scale out expensive tasks (like building, learning, training and testing models) and natively manages machine learning models with Redis caching with an S3 backbone for archiving. Just like DevOps in the enterprise software world, automating build workflows enables your organization to focus on stuff that matters like: finding the most predictive models, defining quality datasets, and testing newly engineered features.
To continue reading the Jay Johnson’s complete blog, please visit the Levvel site.
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.