Blog
Scaling Entity Matching at The Room with Scribble Enrich and Redis

The Room’s mission is to connect top talent from around the world to meaningful opportunities. Envisioned as a technology-driven, community-centric platform to help organizations quickly find high-quality, vetted talent at scale, The Room will host tens of millions of members in its system and have a worldwide presence.
At the core of the technology challenge is a mathematically difficult entity-matching problem. Each entity in the system—individuals, organizations, opportunities, and content—must be matched to other entities with high accuracy and relevance, context-sensitivity, and timeliness. The application has multiple instances of this problem.
After experimentation, The Room’s ML team settled on an approach using vector space embedding of raw text data describing entities, and a combination of vector similarity matching and evolving business logic to surface similar entities. When testing the implementation, it was discovered that the core vector similarity computation was driving the compute and memory needs of the algorithm. Using Redis’ high-performance key retrieval based on nearest neighbour vector lookup, the team was able to achieve more than 15 times improvement in the core similarity computation loop without any memory overhead. In turn, this created headroom to increase the complexity of the algorithm and also deliver it on the real-time path.
Overall system
The overall flow of data is shown in the architecture diagram in Figure 1. While fairly standard, the key challenge was to put the entire production system in place with a small team, tight timelines, and the need for flexibility.
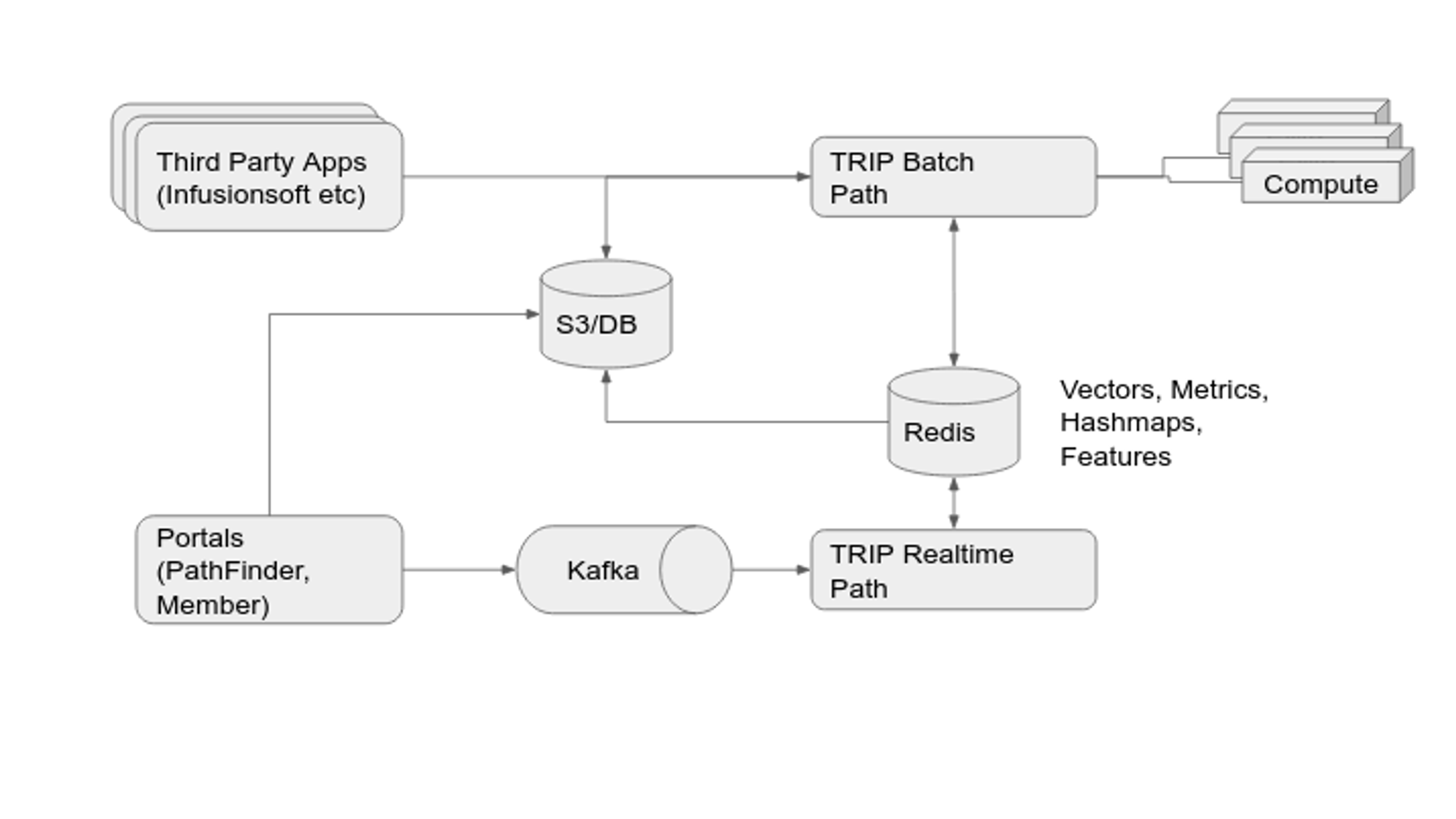
Figure 1: Data flow around The Room Intelligence Platform (TRIP)
Scribble Data’s Enrich feature store and its apps provided the overall framework for implementation of The Room Intelligence Platform which is responsible for entity matching. Enrich handled integration with approximately 15 data sources, data quality, batch, and streaming-feature engineering including vectorization, as well as integration with in-memory database backends such as Redis, cataloging, and compliance. Enrich’s pipelining and orchestration was also used for modeling, and future versions of implementations will use a standalone model database such as MLFlow.
Challenges
Profiling of the early versions of the matching code for The Room’s entity matching engine indicated that more than 95% of the time consumed and 90% of memory was spent in the vector similarity computation. This resource intensiveness hinted at the need for compute distribution and cumbersome optimizations. The three main challenges were:
- Cost: The N2 growth in computation as entities grew linearly (hundreds of millions of potential matches to score) implied switching to a distributed implementation—which is people and resource heavy.
- Messiness: The growing sophistication in the matching algorithm and optimizations would interact in complex ways.
- Realtime support: Matching an entity against all other potential candidate entities was taking too long to be acceptable for real-time generation of matches.
Furthermore, it was necessary to optimize for the following key constraints:
- Team Size: The ML team’s small size makes it limited in addressing other problems than the challenges above.
- Time Constraints: The business is evolving fast, and it is important to rapidly iterate by surfacing results and testing outputs.
Redis for vector similarity
Redis made available a private-preview version of their vector similarity functionality and, to demonstrate the capability, leveraged RedisGears to support key retrieval using high-performance vector similarity lookup. The interface was quite simple, involving storing and lookup using similarity matching, with straightforward integration. Cosine similarity and Euclidean distance metrics were supported to find k-nearest neighbors (k-NN) vectors stored in Redis given a query vector. Standalone tests showed that the top-k closest match retrieval time was sub-millisecond, and the duration is almost constant over a large range of vector counts. The current test implementation has some limitations such as only supporting fixed length of vectors and ability to match all vectors stored in Redis. The production version is expected to address these issues.
Entity matching and performance comparison
The entity matching problem at The Room was modeled as a k-nearest neighbour (k-NN) retrieval on vectors representing entities. The number of candidate vectors (N) is large and expected to grow rapidly. The number of dimensions of each vector is on the order of a few thousand. The testing only focused on the core similarity score computation portions in the application and the speedup reported is based on this.
Three approaches were tested:
- First, as a naive baseline, a Pandas dataframe apply (…) loop that effectively does a row-wise vector-vector similarity computation (Pandas Apply).
- Second, an optimized version of the similarity computation using the Python scikit-learn package’s spatial.distance.cdist(…) function (Python Vectorized).
- Third, the Redis Gears k-NN lookup (Redis).
For approaches (1) and (2) above, a key sort was performed on the scores to get the indices of the top-k similar candidate vectors. Various values of N and k were tested. All three approaches used the same dataset of vectors. The results are shown in Table 1.
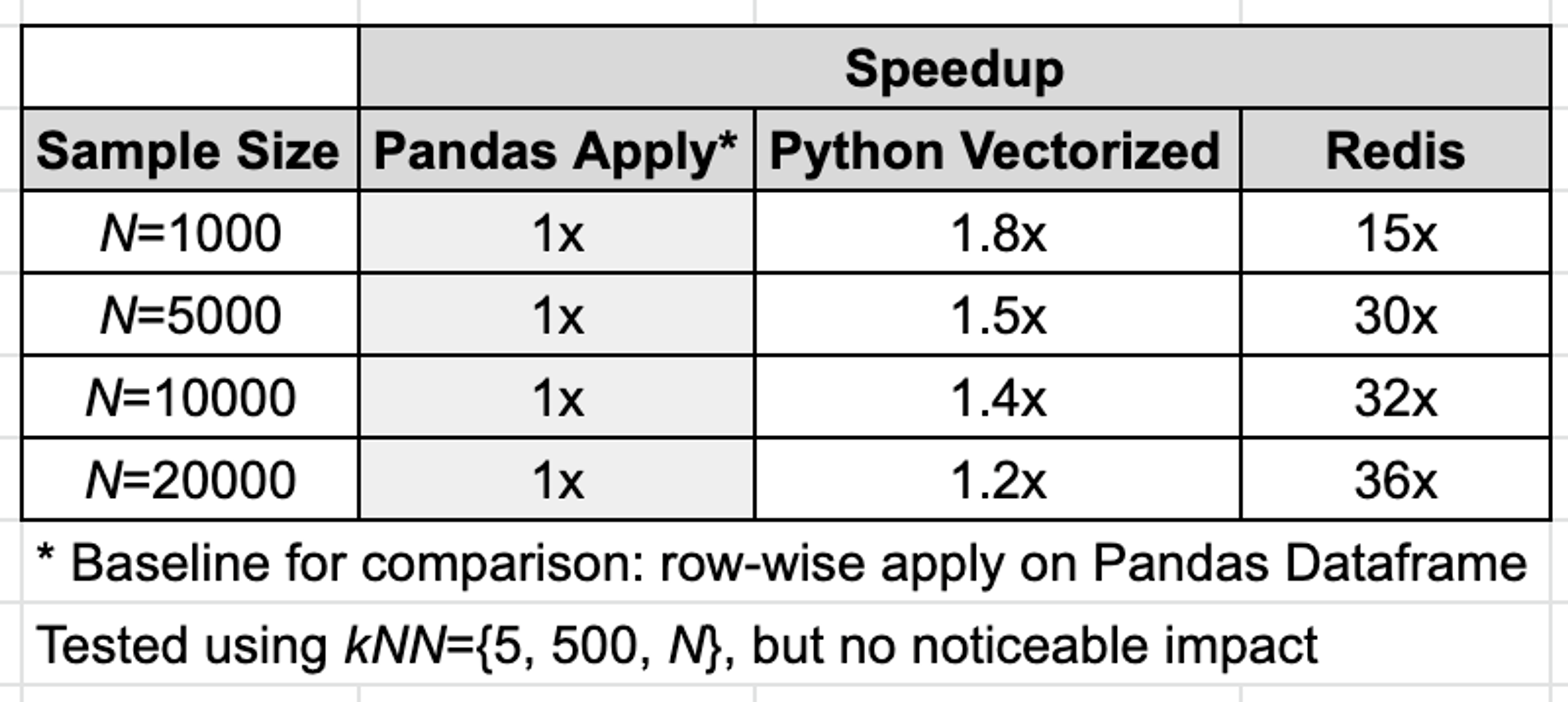
Table 1: Speedup comparison using various methods for retrieving top-k closest vectors given a query vector
We see a consistent 15 times speedup in top-k vector retrieval performance. The larger the data size, the greater the speedup. Our hypothesis is that this speedup is due to elimination of Python and Pandas overhead in compute and memory, and that this speedup can be expected in production consistently.
Redis at The Room
There are a number of value propositions in using Redis’ functionality at The Room:
- Online feature store: Storage of features computed on the streaming path and also the batch path for fast lookup by clients.
- k-Nearest vector lookup: Redis’ high-performance key lookup based on vector similarity computation addressed a core scaling challenge at The Room.
- Building with Redis: The Room roadmap involves building social graphs and processing streams. Redis offers additional data models and other capabilities to core Redis, including search, graph, and programmable data processing, which reduces the need for managing the data flow across separate systems.
Next steps
Redis’ low latency and high-performance vector similarity computation, integrated with Scribble Data’s Enrich feature store, is being extended to address other problems. Beyond a datastore for serving online features, there are two near-term problems that Redis Enterprise is being evaluated for, including use of graphs to identify opportunities and streams to process real-time events. The Room’s own data intelligence platform benefits from this integration as it develops state-of-the-art low-latency data applications for its members and internal staff alike.
Fellow authors
The Room
Peter Swaniker, CTO of The Room
Scribble Data
Achint Thomas, Data Architect, Scribble Data
The Room is hiring data scientists and data engineers! See more at https://www.theroom.com/careers/
Learn more about the Enrich Feature Store at www.scribbledata.io/product, and to get started developing with Redis visit /learn/, including with RedisAI for real-time serving at /modules/redis-ai/.
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.