Blog
Data Replication Explained: Examples, Types, and Use Cases

What is data replication?
Data replication also known as database replication, is a method of copying data to ensure that all information stays identical in real-time between all data resources. Think of database replication as the net that catches your information and keeps it falling through the cracks and getting lost. Data hardly stays stagnant. It’s ever-changing. It’s an ongoing process that ensures data from a primary database is mirrored in a replica, even one located on the other side of the planet.
These days, “instantaneous” isn’t quick enough. Cutting latency down to sub-millisecond intervals is the universal objective. We’ve all seen this situation before – pressing the refresh button on a website, waiting for what feels like an eternity (seconds) to see your information updated. Latency decreases productivity for a user. Achieving near-real-time is the goal. Zero time lag is the new ideal for any use case.
How does data replication work?
Data replication is copying data from one host to another, like, say, between two on-prem, or one on-prem to a cloud, and so forth. The point is to achieve real-time consistency with data for all users, wherever they’re accessing the data from. Data-Driven Business Models (DDBMs), like the gaming industry, rely heavily on the analytics acquired through real-time data. For a clearer understanding of just how necessary real-time accessibility is for a DDBM, watch this video below:
What are the benefits of data replication?
Improved reliability and disaster recovery
In case of an emergency, should your primary instance be compromised, it’s vital to have mission-critical applications safeguarded with a replica that can be swapped in its place. Disaster recovery replication methods work similarly to a backup generator; imagine blowing a critical fuse or your power grid goes dark – you won’t have to worry because you have a backup generator to swoop in as a substitute and keep your lights running.
Because replica instances are exact copies of primary instances, you can guarantee performance will not falter, regardless of what happens to your primary. Even if the link between a primary and a replica breaks, performance is still assured as the primary will enact a partial resynchronization, gathering the commands that were not delivered to the replica during the disconnection. If not possible, a full resynchronization will be initiated using a snapshot.
Increased app performance
By spreading the data across multiple instances, you’re helping to optimize read performance. Performance is also optimized by having your data accessible in multiple locations, thus minimizing any latency issues. Also, when replicas are directed to process most of your reads, that opens up space for your primary to tackle most of the heavy lifting of writes.
More efficient IT teams
Reduction in IT labor to manually replicate data.
Understanding full data replication vs. partial replication
Full Database Replication occurs when an entire primary database is replicated within every replica instance available. This is a holistic approach that mirrors pre-existing, new, and updated data to all destinations. Though this approach is very comprehensive, it also calls for a considerable amount of processing power and encumbers the network load because of the large size of the data being copied.
Unlike full replication, partial replication only mirrors some parts of the data, typically recently updated data. Partial replication isolates particular bits of data following the importance of the data at a specific location. For example, a large financial firm with headquarters in London could have many satellite offices operating around the world, with an office in Boston, another in Kuala Lumpur, and so on.
Partial replication allows the analysts in London to have only UK-pertinent data at their site and have only that data be consistently replicated for their needs. The other satellite offices in the United States and Malaysia, respectively, can do the same and not bog down any one system, which improves performance and minimizes network traffic.
Examples of data replication
Transactional replication
This form of database replication sees data from a primary database replicating data in real-time to a replica instance by mirroring these changes in the order that they were made in the primary database. This optimizes consistency. The replication takes what is called a “snapshot” of the data in the primary and uses that snapshot as a blueprint of what needs to be replicated elsewhere. With transactional replication, you can track and distribute changes as needed.
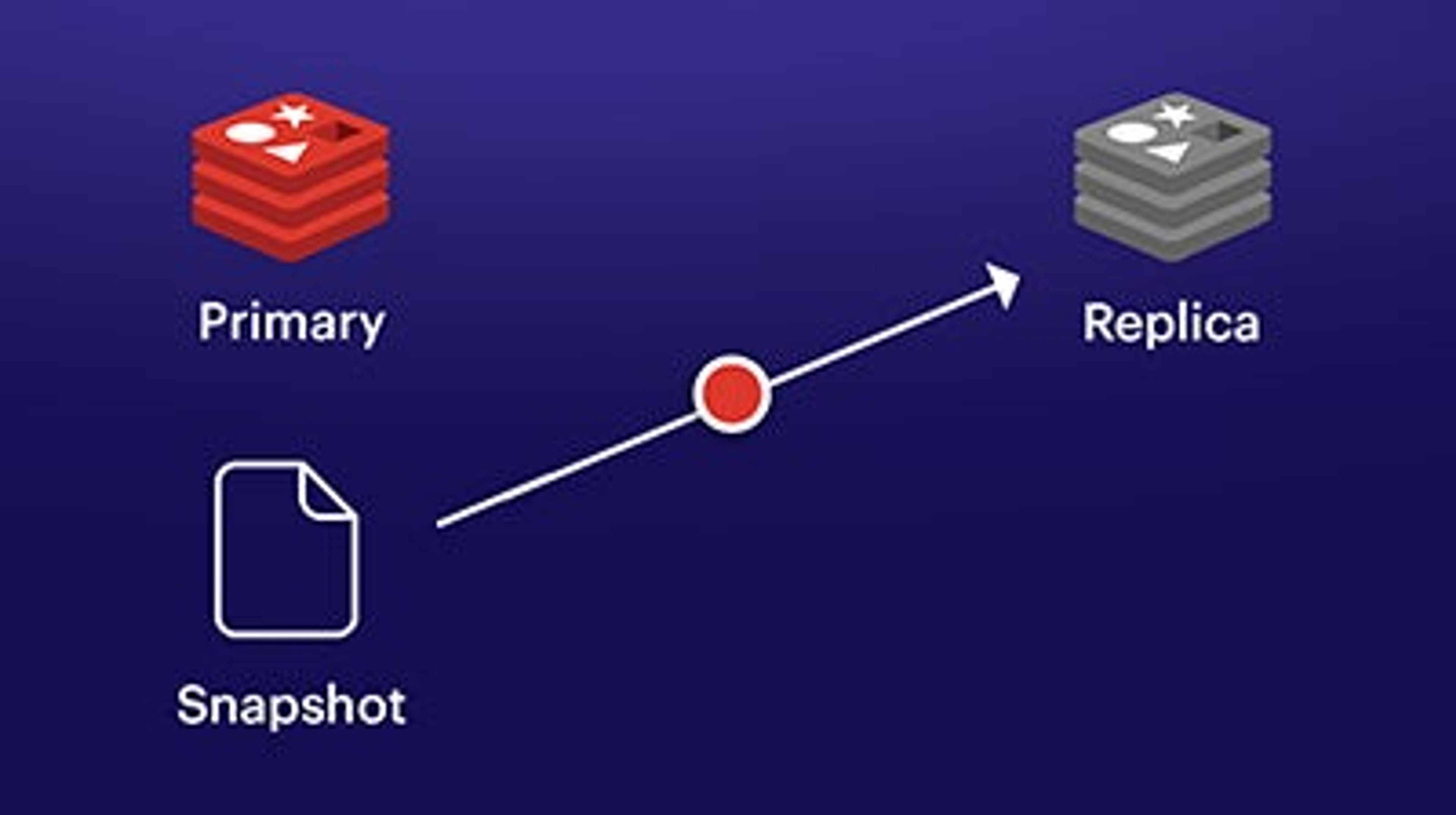
A snapshot of the primary is shared to the replica
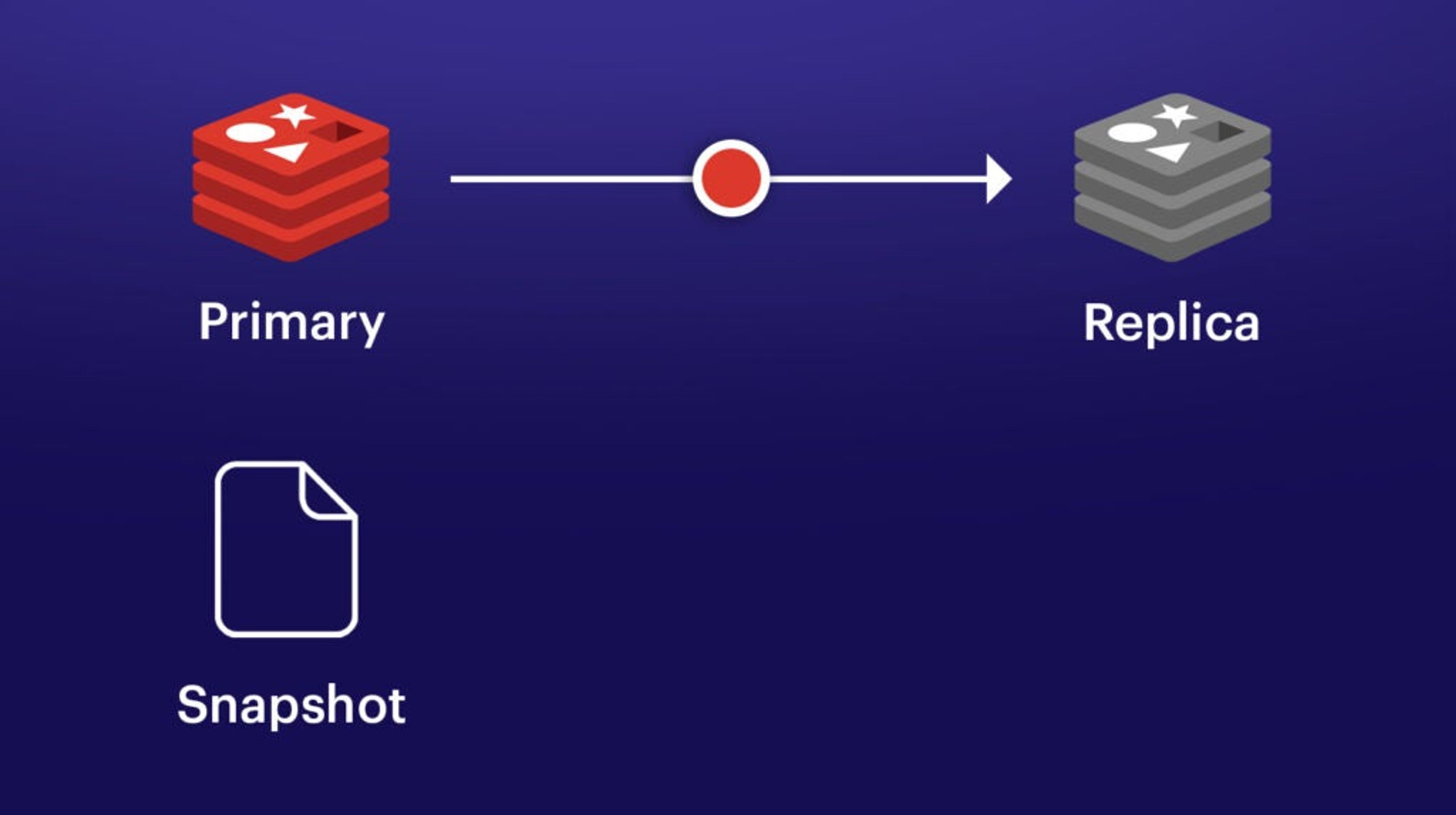
Primary sends data gathered after the snapshot to the replica
Given the incremental nature of this process, transactional replication isn’t the optimal choice when looking for a backup database option. Transactional replication is a useful choice in situations where you need real-time consistency across all data locations, where each minuscule change needs to be accounted for, not just the overall impact of the changes, and if data is changing regularly from one specific location.
Snapshot replication
As its name suggests, snapshot replication takes a “snapshot” of the data from the primary as it appears at a specific moment and moves it along to the replica. Like a photograph, snapshot replication captures what data looks like at a point in time, as it looks when it moves from the primary to the replica, but doesn’t account for how it is later updated. Thus, don’t use snapshot replication to make a backup.
In the event of a storage failure, snapshot replication will have no path to updated information. To keep your information consistent, you can start with a snapshot, but then ensure that all changes made to the primary are then passed on to every replica.
On the other hand, this method is rather helpful for recoveries in the event of accidental deletion. Think of it like your Version History on Google Docs. Wish you could work on your presentation the way it looked four hours ago? If Google Docs takes a snapshot of your work at hourly intervals, you could click back on that version, or “snapshot,” from four hours ago and see what your information looked like then.
Merge replication
This method typically begins with a snapshot of the data and distributes that data to its replicas, and maintains synchronization of data between the entire system. What makes merge replication different is that it allows each node to make changes to the data independently but merges all those updates into a unified whole.
Merge replication also accounts for each change made at each node. To go back to our previous Google Docs example, if you’ve ever shared a document with coworkers who then leave comments and edits on your document, you’ll see who made what changes and at what time. Merge replication functions in a very similar way.
Key-Based replication
Also known as key-based incremental data replication, this method leverages a replication key to identify, locate and alter only the specific data that has been changed since the last update. By isolating that information, it facilitates the backup process, working with only as much load as it has to. Though key-based replication makes for a speedy method of refreshing new data, it comes with the disadvantage of failing to replicate deleted data.
Active-Active Geo-Distribution
Active-Active Geo-Distribution, also known as peer-to-peer replication, works somewhat like transactional replication, as it relies on constant transactional data via nodes. With active-active, all the nodes in the same network are constantly sending data to one another by synching the database with all the corresponding nodes. All the nodes are also writable, meaning anyone can change the data anywhere around the world, and it will reflect in all the other nodes. This guarantees real-time consistency, no matter where in the globe the change may occur.
Conflict-free Replicated Data Types (CRDTs) define how this data is replicated. In the event of a network failure with one of the replicas or nodes, the other replicas will have all the necessary data ready to replicate once that node comes back online. This is a solid solution for enterprises that need several data centers located across the globe. Take a look at the video below for examples of Active-Active Geo-Distribution use cases.
Download the Under the Hood: Redis CRDTs white paper now
Synchronous and asynchronous replication
With synchronous replication, the data is written in both the primary and the replica at the same time, hence the name. Asynchronous replication, on the other hand, only copies data to the replica once the writes have already occurred in the primary. Asynchronous replication doesn’t tend to happen in real-time, though it’s possible. Because of the scheduled write operations that tend to happen in batches with asynchronous, sometimes data gets lost, in most cases when a fail-over event transpires. Still, asynchronous is an apt solution when having to replicate data over long distances, as the real-time component isn’t a mission-critical factor.
What are common data replication implementation challenges?
Maintaining data across multiple instances requires a consistent set of resources. The cost of having a primary with multiple replica instances can be quite high in many instances. Maintaining these operations and ensuring that no system failures occur requires a dedicated team of experts. And depending on the architecture, the network bandwidth could get overloaded when new processes are put in place, which could affect latencies, reads, and writes.
FAQ
- What is data replication?
- Data replication is a method of copying data to ensure that all information stays identical in real-time between all data resources. Think of database replication as the net that catches your information and keeps it falling through the cracks and getting lost. Data hardly stays stagnant. It’s ever-changing. It’s an ongoing process that ensures data from a primary database is mirrored in a replica, even one located on the other side of the planet.
- What is a replicated database?
- A replicated database is a type of database system that maintains multiple copies of the same data across different nodes or servers. The purpose of replicating the data is to improve data availability, fault tolerance, and performance.
Redis makes data replication expedient, cost-effective, and simple to implement. Are you ready for the Redis Enterprise treatment?
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.