Blog
Explore the new Multimodal RAG template from LangChain and Redis


Large language models (LLMs) are trained on massive sets of public data and excel at generating human-like text based on that information. However, they don’t have access to private or corporate data, which limits how effective they are for enterprise use cases. Retrieval-augmented generation (RAG) is a popular approach to connect LLMs to this specialized data, broadening their knowledge bases beyond their initial training data. With RAG, companies are using LLMs to answer questions about their unique documents and data.
RAG works by integrating a retrieval component into the generative process. An application first retrieves relevant documents based on an input query and then synthesizes this information to generate a response. This approach not only provides a deeper context but also enhances the model’s responses with the most current information, delivering more accurate and relevant responses compared to traditional LLMs.
However, most RAG approaches focus exclusively on text, leaving out information-rich images or charts contained in slide decks or reports. With the rise of multi-modal models, such as GPT4-V, it’s possible to pass images directly into LLMs for reasoning. Still, there’s been a gap in the development of RAG frameworks that seamlessly work with text and images.
Redis and LangChain go beyond text by introducing a template for multimodal RAG. By incorporating visual data, this template allows models to process and reason across both text and images, paving the way for more comprehensive and nuanced AI apps. We’re thrilled to present a system that not only reads text but also interprets images, effectively combining these sources to enhance understanding and response accuracy.
In this post, we’ll:
- Introduce multimodal RAG
- Walk through template setup
- Show a few sample queries and the benefits of using multimodal RAG
Go beyond simple RAG
The typical RAG pipeline involves indexing text documents with vector embeddings and metadata, retrieving relevant context from the database, forming a grounded prompt, and synthesizing an answer with an LLM. For more on this, see LangChain’s video series RAG From Scratch.
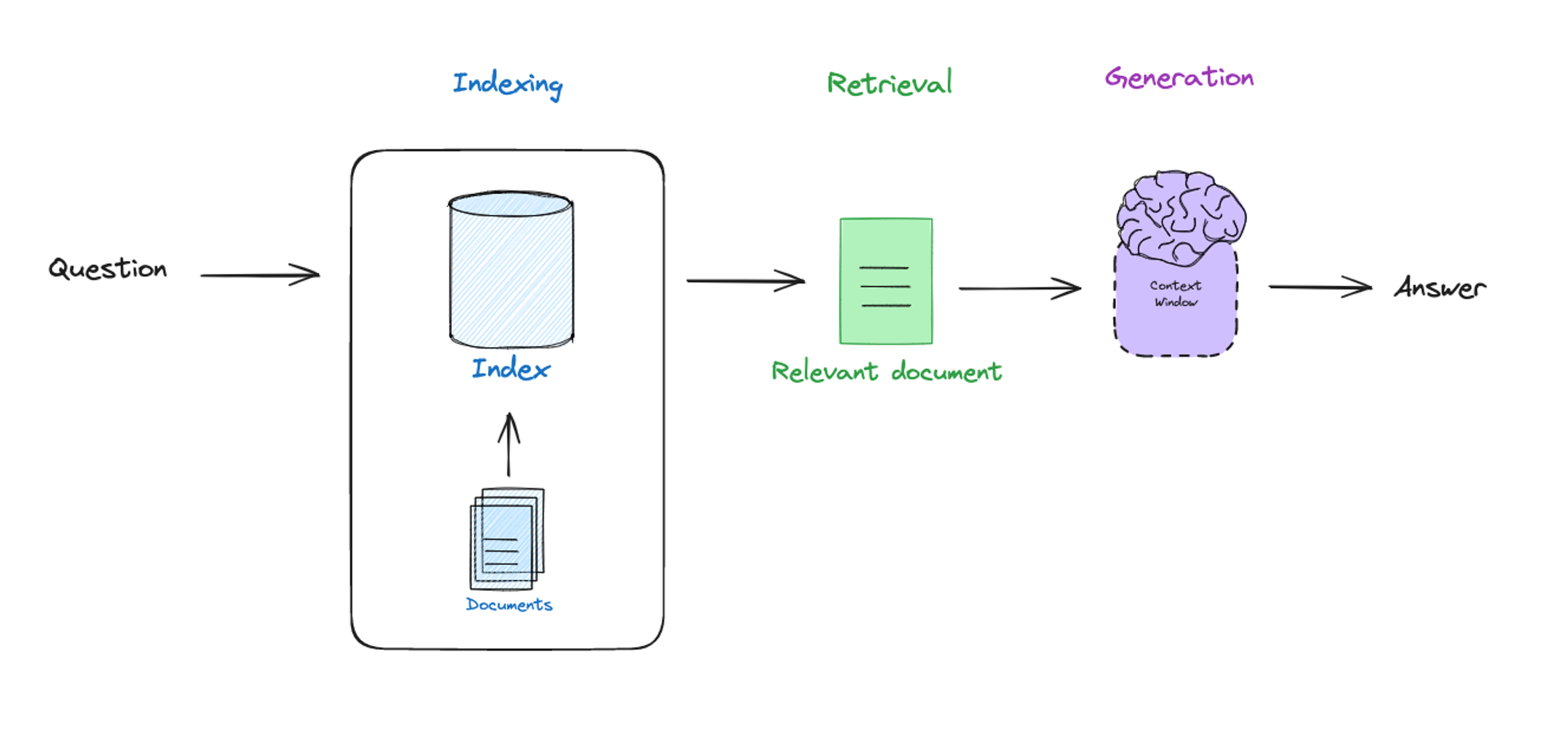
But what about non-textual data like images or graphics? For these other data types, we have to extract semantics with a unique process. For example, consider analyzing a slide deck of the Nvidia Q3 FY24 investor presentation. The slides are a combination of text, images, tables, and charts. Standard PDF extraction techniques will only extract text, leaving information-rich images outside retrieval scope.
Fortunately, we can solve this using the flexible data structures in Redis and the innovative capabilities of OpenAI’s combined text and vision model, GPT4-V. To setup the multi-modal RAG pipeline, we start with a few preprocessing steps:
- Extract slide summaries as text using GPT4-V
- Embed text summaries using OpenAI’s embedding models
- Index text summary embeddings in Redis hashes, referenced by a primary key
- Encode raw images as base64 strings and store them in Redis hashes with a primary key
For this use case, LangChain provides the MultiVector Retriever to index documents and summaries efficiently. The benefit of this approach is that we can employ commonly used text embeddings to index image summaries just like any other text, avoiding the need for more specialized and less mature multimodal embeddings.
Now at runtime, when a user asks a question:
- Embed the user question using OpenAI
- Retrieve relevant images from Redis based on the embedded image summaries
- Look up the raw images from Redis using the primary key
- Generate an informed answer using GPT4-V with the raw images and original question
As RAG functionality continues to advance, many expect that processes like this will have more retrieval calls to databases and to LLMs, creating compound AI systems. Each of these additional steps increases lag and cost. Redis semantic caching reduces the number of calls to databases and LLMs for repeat questions, removing redundant work. Semantic caching works by storing responses from previously answered questions. Then, when a similar question is asked, the application retrieves that stored answer from the cache instead of initiating a duplicate call to the database and another costly call to the LLM. By removing additional steps for frequently-asked questions, apps can speed up responses and significantly reduce the cost of calling LLMs.
Spin up with the RAG template
Before starting the app, you need a (free) Redis Cloud instance and an OpenAI API key.
1. Set your OpenAI API key and Redis URL environment variables:
2. Install the LangChain CLI in your Python environment:
3. Create a new LangChain app:
This will create a new directory called my-app with two folders:
- app: Where LangServe code lives
- packages: Where your chains or agents live
4. Add the multimodal rag package:
When prompted to install the template, select the yes option, y.
5. Add the following snippet to your app/server.py file:
6. Ingest source data for demo app:
This may take a few minutes. The ingest.py script executes a pipeline to load slide images, extract summaries with GPT4-V, and create text embeddings.
7. Serve the FastAPI app with LangServe:
8. Access the API at http://127.0.0.1:8000 and test your app via the playground at http://127.0.0.1:8000/playground:
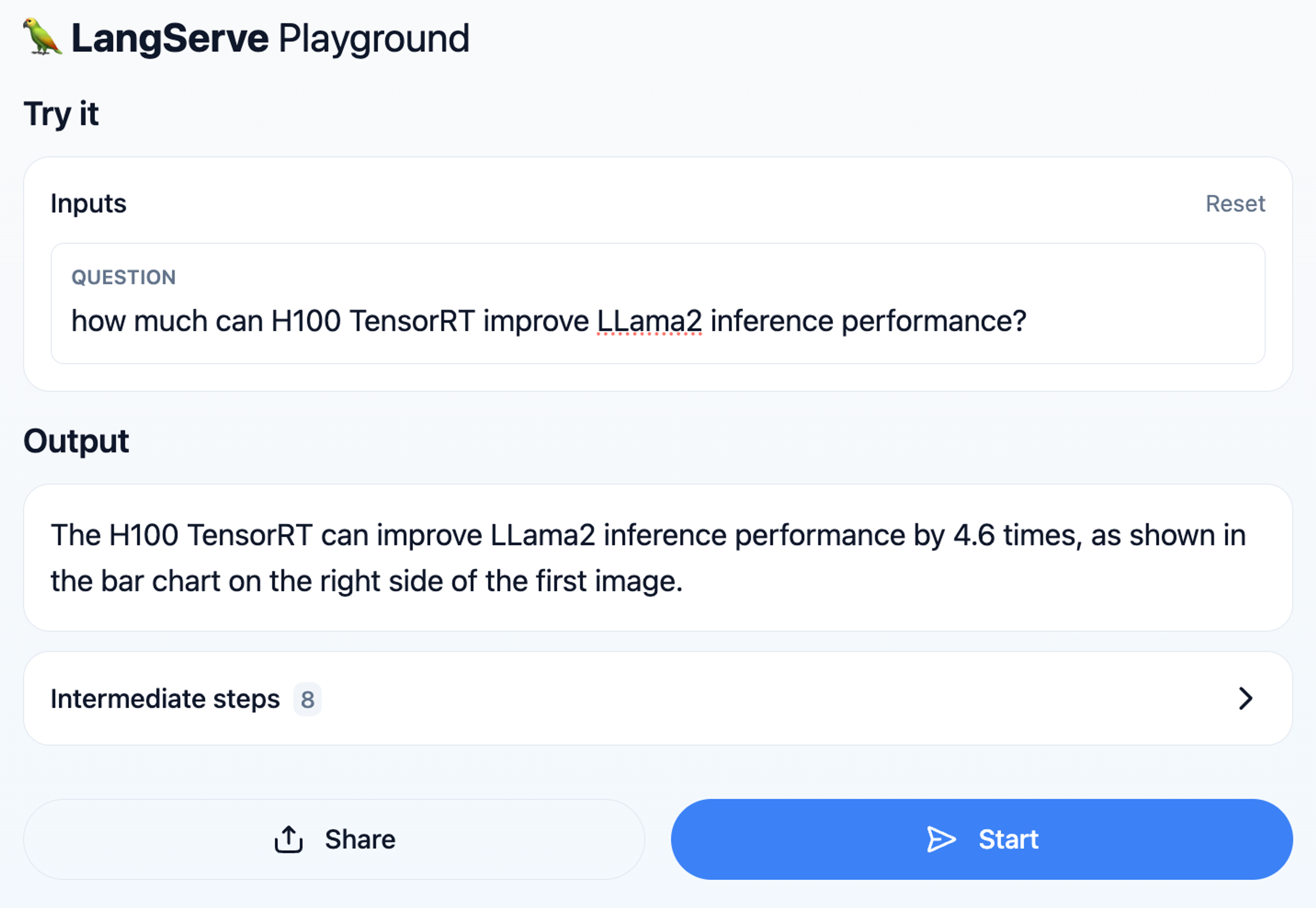
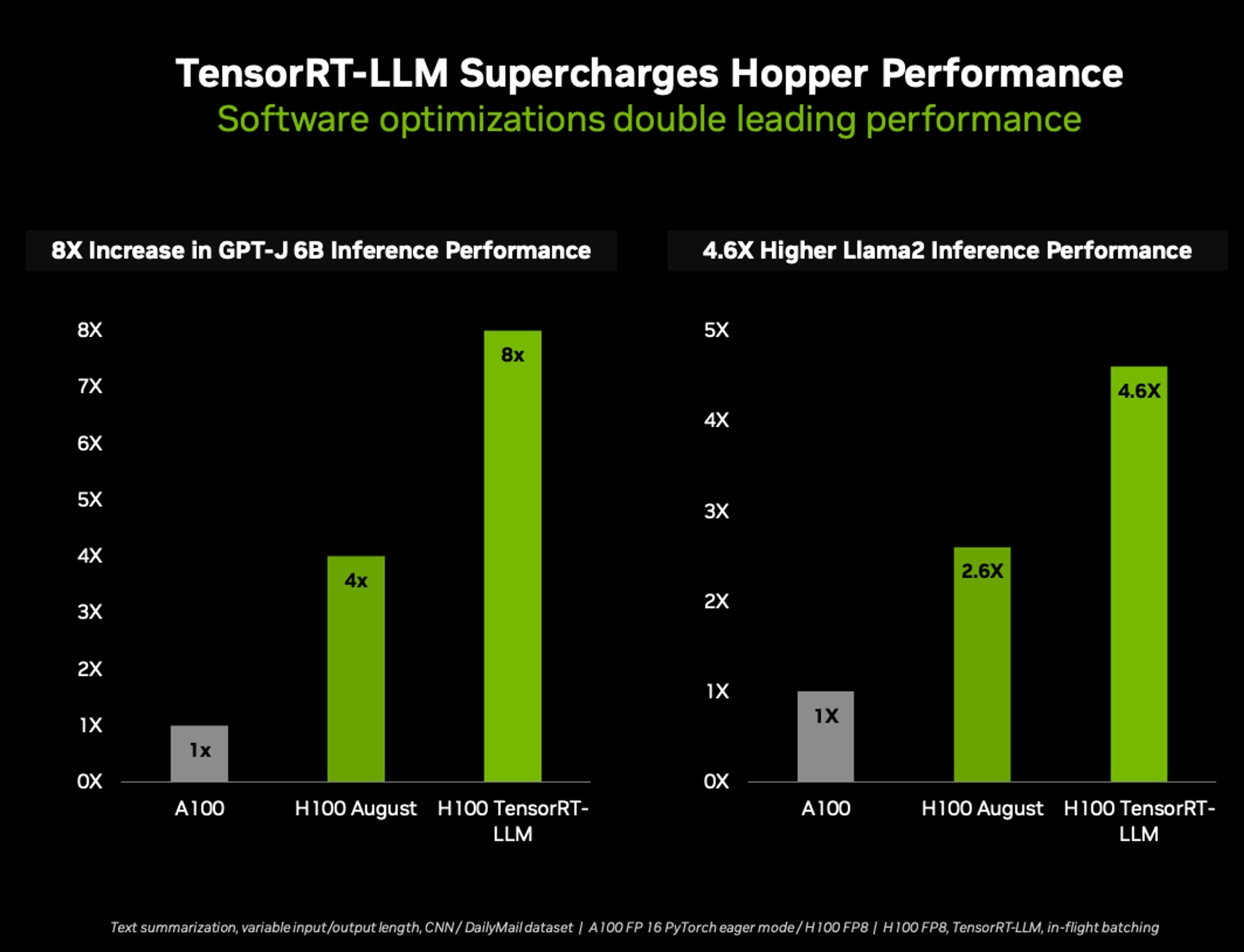
Validate the answer from the RAG system by quickly checking the referenced PDF image from the slide deck.
In addition to LangServe, LangChain also has an observability platform called LangSmith. This will log all generations performed by the template, allowing for inspection of the prompt and validation of the images passed to GPT-4V. For example, you can see a trace on langchain.com on multi-modal data that shows extraction of information from financial charts.
Wrapping up
With the new multimodal RAG template, devs can now build sophisticated AI apps that understand and leverage diverse data types powered by a single backend technology—Redis.
Get started by setting up a free Redis Cloud instance and using the newRedis <> LangChain. For insights on other emerging RAG concepts, explore the recent session with Lance Martin, Nuno Campos, and Tyler Hutcherson.
Related Resources
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.