
Retrieval-augmented generation (RAG) is often overhyped, leading to unmet expectations after implementation. While it may seem straightforward—combining a vector database with a large language model (LLM)—achieving optimal performance is complex. RAG is easy to use but difficult to master, requiring deeper understanding and fine-tuning beyond basic setups.
More on RAG Agentic RAG with Redis, AWS Bedrock, and LlamaIndex
In my previous two blogs, I have covered how to fine-tune the initial retrieval piece with BGE embedding model and Redis Vector Database.
Advance RAG with fine-tuning
- Fine-tuning Embedding Model With Synthetic Data for Improving RAG
- Evaluating information retrieval with Normalized Discounted Cumulative Gain (NDCG@K) and Redis Vector Database
- Improving Information Retrieval with fine-tuned Reranker (this blog)
Rerankers are specialized components in information retrieval systems that refine search results in a second evaluation stage. After an initial retrieval of relevant items, rerankers reorder results to prioritize the most relevant ones, improving the quality and ranking of the final outputs.
In this blog post, we’ll focus on fine-tuning the reranker.
How do rerankers improve RAG?
In a RAG system, a query is encoded into a vector and searched in a vector database containing document embeddings. The top-k matching documents are retrieved and used as context by an LLM to generate a detailed, relevant response. This works well with small documents that fit within the LLM’s context window. However, for large datasets, retrieved results may exceed the context window, causing information loss and reduced response quality.
To address this issue, you should employ a reranker to refine and prioritize the top-k matching documents before they are fed into the LLM.
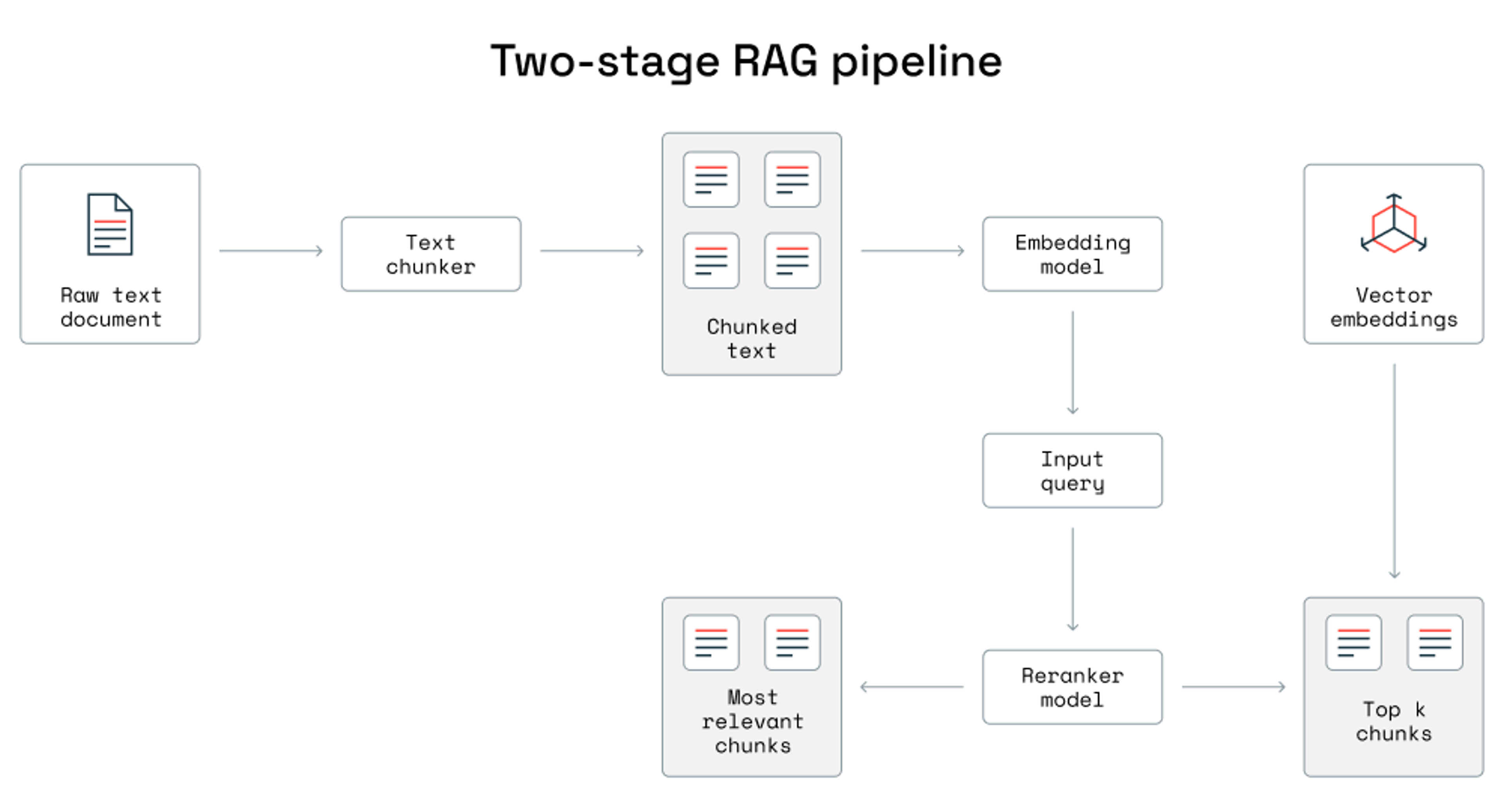
The reranker reorders the retrieved documents based on relevance, ensuring the most pertinent information fits within the LLM’s limited context window. This optimizes context usage, improving the accuracy and coherence of the response.
A Cross-Encoder fine-tuning
A Cross-Encoder is a type of neural network used for sentence pair classification tasks, including reranking search results.
Unlike Bi-Encoders, which encode each input separately, Cross-Encoders process both input texts together, allowing deeper interaction between them.
What is “BAAI/bge-reranker-base”?
This is a pretrained Cross-Encoder model from BAAI (Beijing Academy of Artificial Intelligence), specifically designed for reranking tasks.

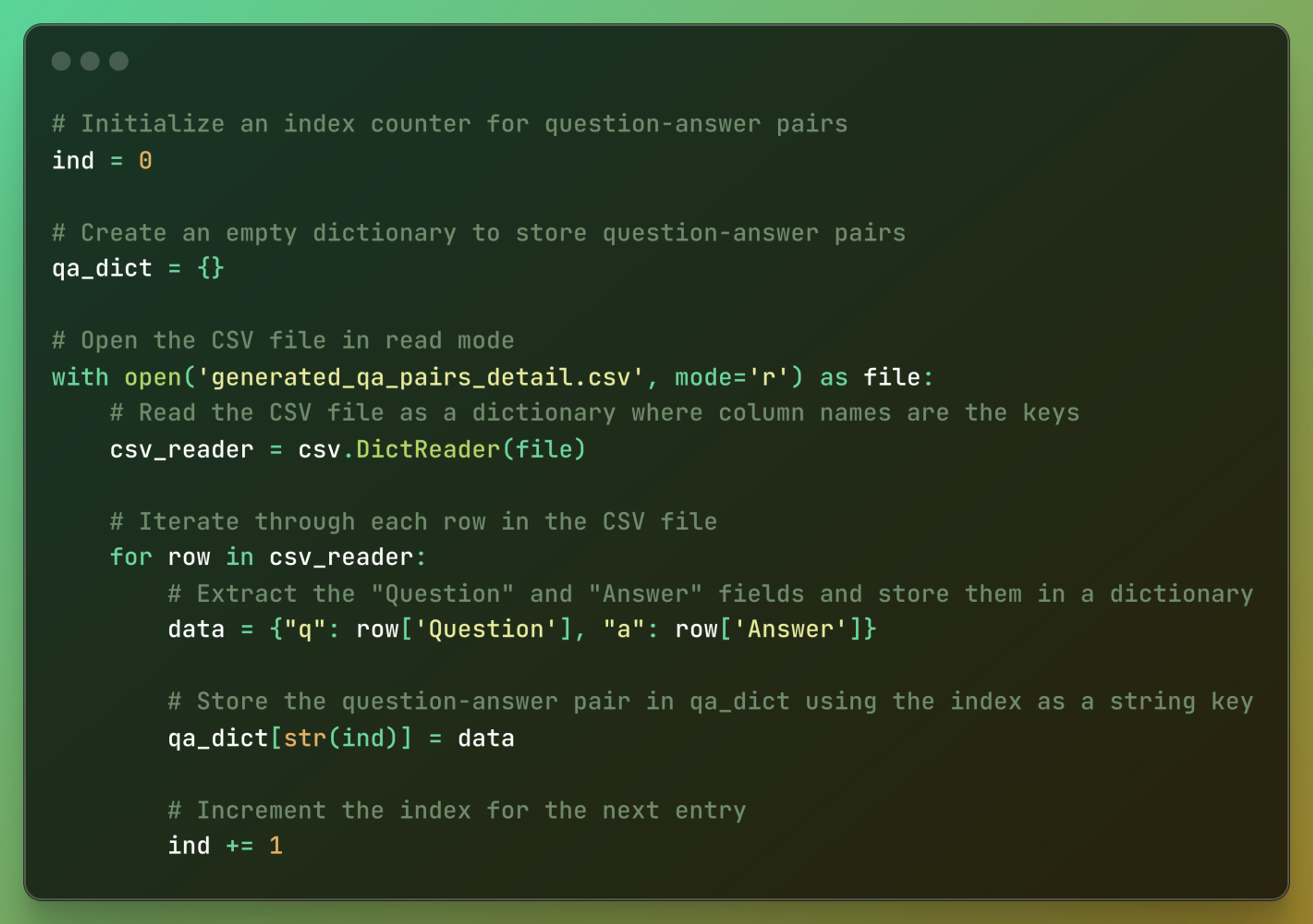
Reads a CSV file containing questions and answers. Extracts “Question” and “Answer” from each row. Stores them in a dictionary with numeric string keys. The dictionary qa_dict can later be used for quick lookups of Q&A pairs.
Creates a mix of entailment and contradiction pairs to train an NLI model. Helps the model distinguish real question-answer pairs from unrelated ones. Balances the dataset by ensuring both entailment and contradiction labels exist.
Entailment example:

Contradiction example:

Define a custom evaluator class for Mean Squared Error (MSE) accuracy evaluation
Create Training DataLoader:

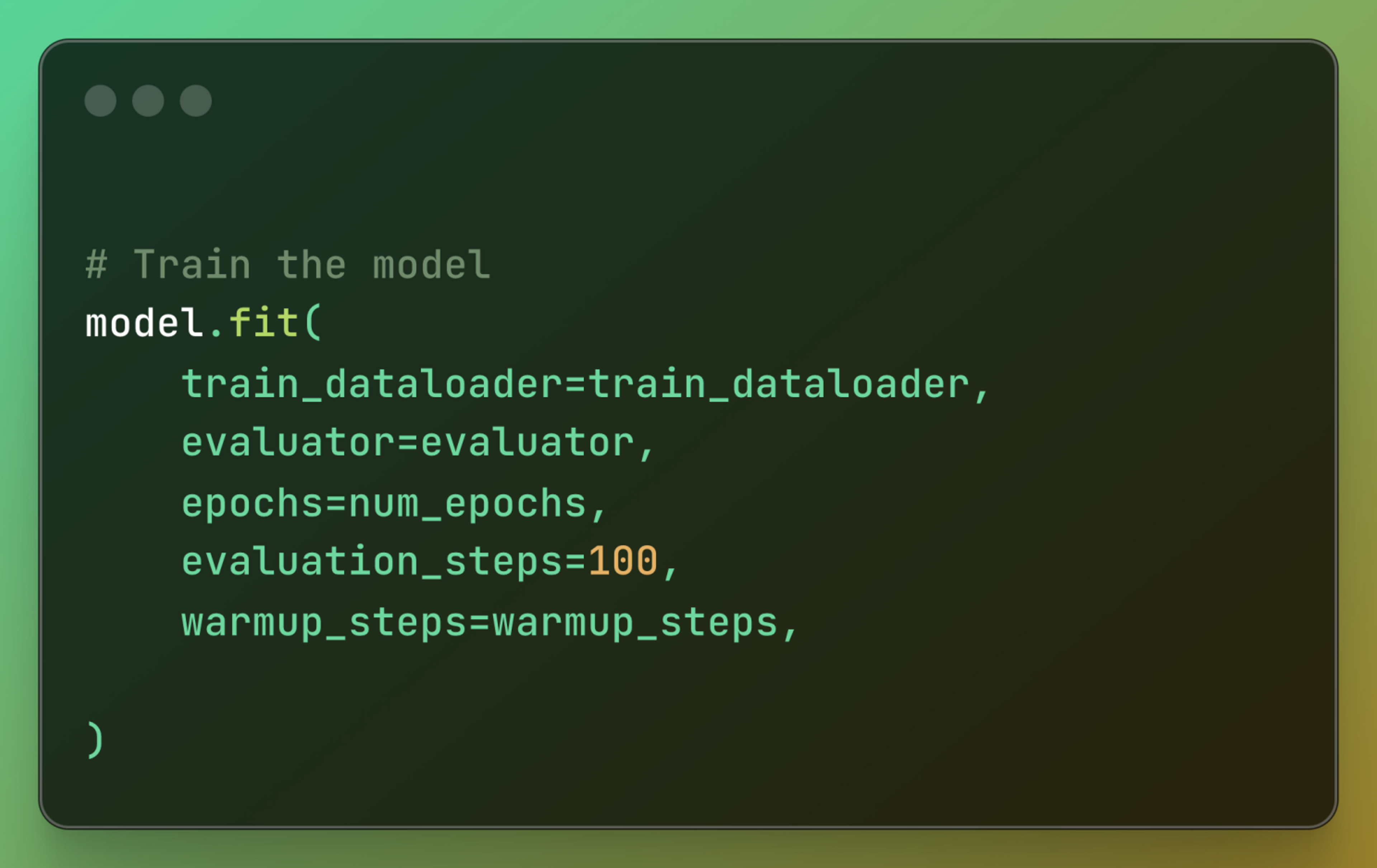
Train the model:
Predict the entailment pair with fine-tune model:

Predict the contradiction with fine-tune model:
Fine-tuning reranking models is a logical progression after working with embeddings and offers a powerful approach to enhancing how systems interpret and prioritize information. From generating synthetic data to training and evaluating the model, each step presents unique challenges and opportunities. Whether you’re leveraging real-world data or building custom datasets, success lies in continuous experimentation, iteration, and refinement. I hope this guide encourages you to explore the potential of fine-tuning in your own projects.
Démarrez avec Redis dès aujourd’hui
Parlez à un expert Redis et découvrez Redis Enterprise.