Blog
Indexing, Querying, and Full-Text Search of JSON Documents with Redis

Related Resource: Click to download RedisJSON module.
RedisJSON and RediSearch are by far the most popular Redis modules in our cloud. (See Fig. 1) The docker images of RedisJSON and RediSearch (bundled with Redis) are pulled more than 2000 times every single day. This is why we think of Itamar Haber, technology evangelist at Redis, as a visionary when he wrote the first version 4 years ago. In April, we made several announcements at RedisConf related to JSON, indexing and full-text search capabilities. Today, we’re happy to announce the private preview of these capabilities.
In this blog, we’ll give you an overview of the current RedisJSON capabilities. After that we’ll dive into the new capabilities section of this private preview. The ability to index, query, and use full-text search on JSON documents using RediSearch is the coolest new feature of this release. Finally, we’ll show you how to quickly get started.
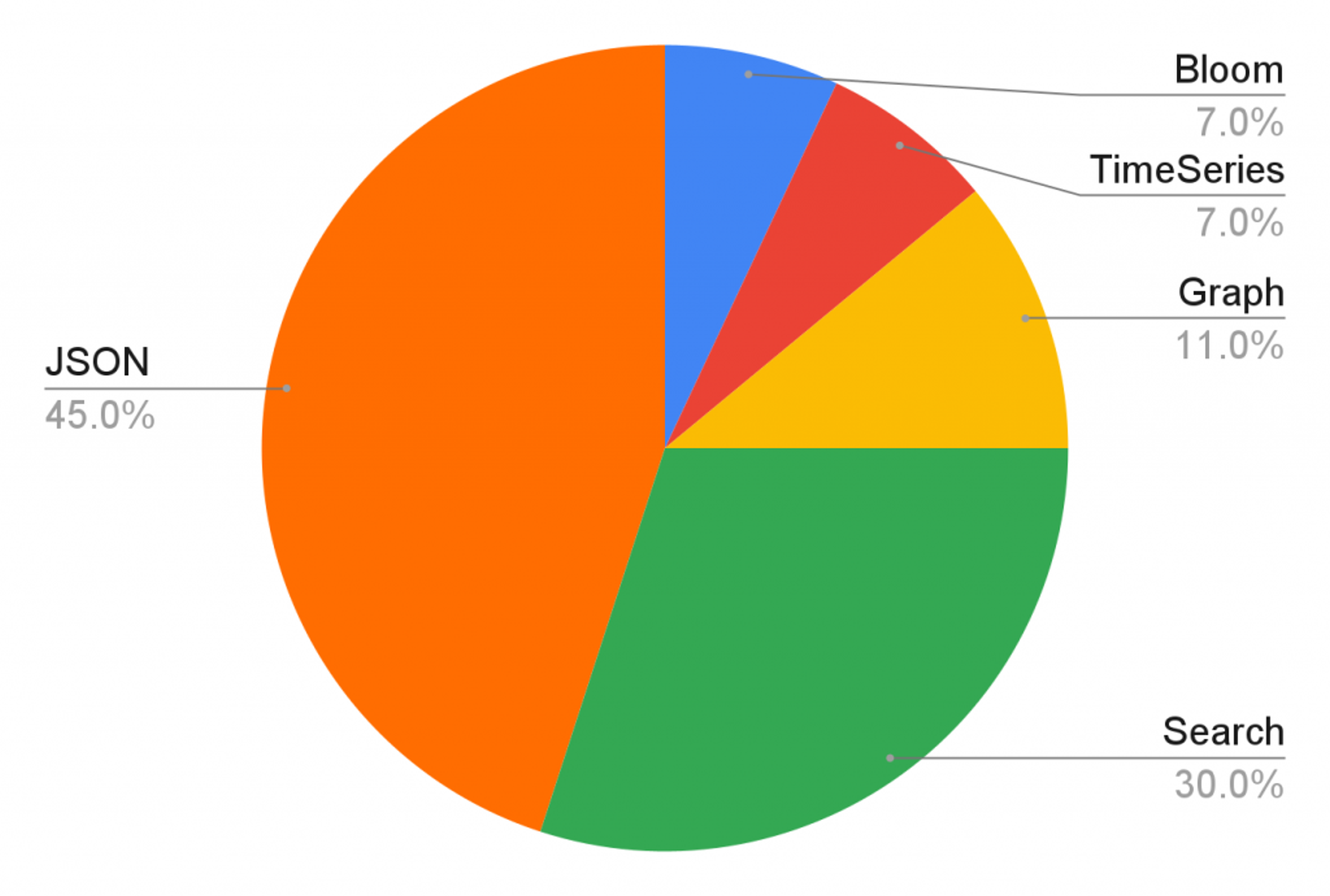
Fig1. Redis Cloud databases using at least one module (May 2021)
JSON capabilities
When you don’t have RedisJSON, you model nested documents in Redis by using the String data structure.
But, what if we need to update a subpart of the document?
To preserve the atomicity of the operation, we will need to:
- WATCH for the document
- Read the previous version and deserialize it
- Embed the update in a Redis transaction
- Serialize to JSON and update the document
- Execute the transaction
We may need to retry all these steps if another client updated the document during this process.
However, with RedisJSON, we can do this update with a single atomic transaction:
Let’s look at another example, one where you have a large JSON, but only require a subpart of that document in your application.
Without RedisJSON:
You have to:
- Retrieve the whole json string, serialized as a string
- Deserialize the JSON
- Extract the subpart you need
With RedisJSON, you can retrieve only the data you require with a single command, minimising CPU cycles, network overhead, and, most importantly, latency.
As you can see, RedisJSON simplifies JSON document manipulations. The current GA version of RedisJSON (v1.0) is the version the community is already widely using and solves exactly the shortcomings of modeling nested structures with a String data structure. Here’s an overview of some of its key capabilities.
Store (or update) a JSON document associated with a key in Redis
Replace a subpart (eg. the string value of a key)
Add an item to a collection or a map
Extract the whole document
Extract part of it using a subset of JSONPath
RedisJSON 2.0: Private Preview release
We announced this version at RedisConf 2021, and today we’re happy to announce that it’s available as a private preview for a select group of our Redis Enterprise customers—and as a release candidate to our community. This version has three major features, namely, full support of JSONPath expression, support for Active-Active (with Redis Enterprise), and the ability to index, query, and use full-text search on JSON documents with RediSearch. But there’s more! Let’s dive into the new goodies.
Rewritten in RUST
System programming languages is a family of languages oriented to efficiency. Programs written in these languages are usually lightweight and provide the best performances. This is the reason why Redis has been historically written in C. It also explains why Redis is able to achieve extremely low latencies and high throughputs. Most of the Redis modules are written in C, C++, or Rust, which are languages of the same family.
JSON is especially well served by the Rust community including very fast and efficient JSON serialisation and JSONPath implementation. Giving the benefit of those implementations to Redis users was obvious and just required a mapping between the Redis module API and Rust.
Full support for JSONPath
And here is the benefit of this RUST rewriting. This new version includes a comprehensive support of JSONPath. It is now possible to use all the expressiveness of JSONPath expressions.
Given a JSON document
Wildcards (was previously limited to the first item)
Extract slices
A more advanced example with filter expressions
Support for Active-Active
Active-Active is a feature provided by Redis Enterprise. Active-Active allows you to replicate your database into several geographically-distributed Redis Enterprise clusters. The users can connect to the closest cluster with local read and write latencies.
The implementation is based on Conflict-free Replicated Data-Type (CRDT) technology. While implementing it for most of the core data structures supported by Redis, Redis developed a strong knowledge and experience confirmed by this new implementation made for JSON.
Application developers can now rely on this to build geo-distributed applications using JSON documents. Here is an example of a succession of operations in an active-active environment with two clusters:
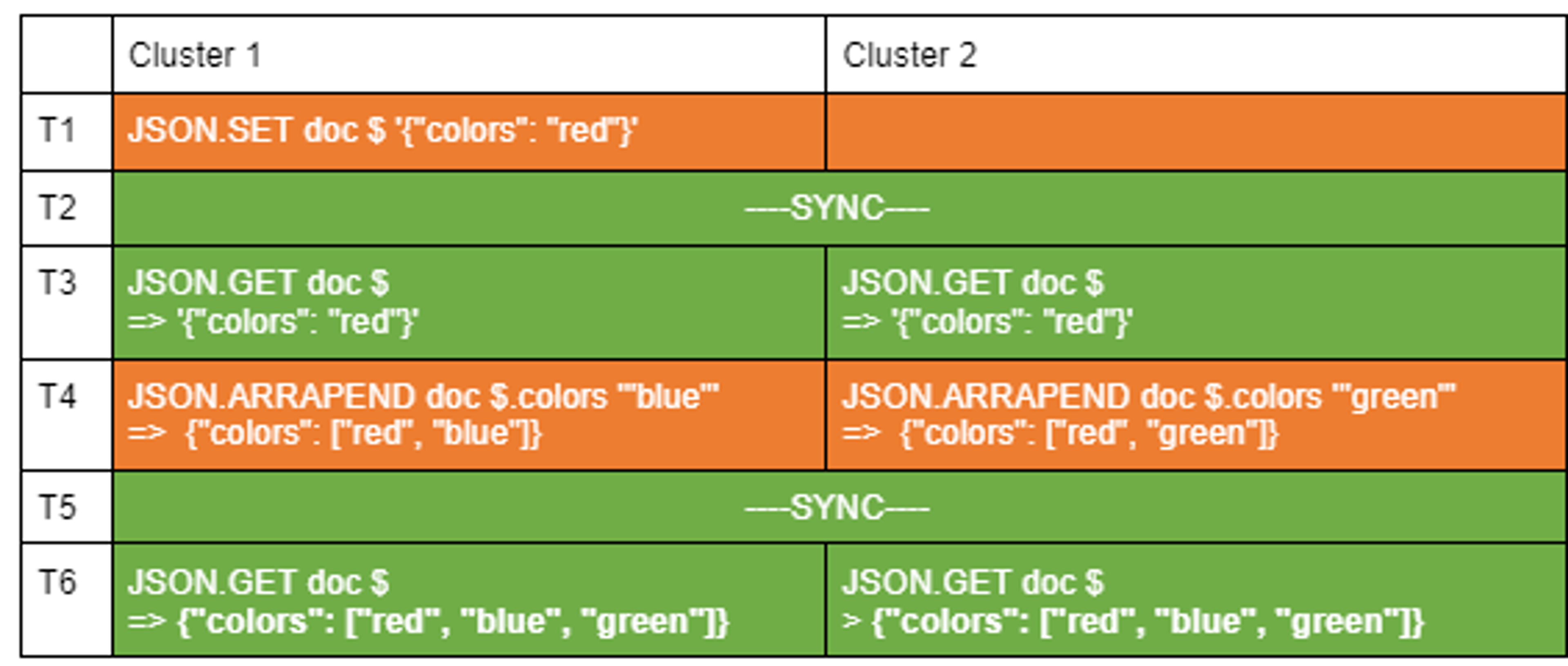
Let see the detail of each operations:
- T1: A client sets a JSON document on Cluster 1.
- T2: The synchronisation process replicates the document on Cluster 2.
- T3: Both clusters contain the same document.
- T4: A client adds the blue color to the colors array in Cluster 1, and, concurrently, another client is adding the green color to the same array in Cluster 2.
- T5: The synchronization process merges the operation and updates the document on both clusters.
- T6: Both clusters contain the same document.
RediSearch 2.2: Private Preview release
This blog also announces the availability of a private preview for RediSearch 2.2 (as a private preview for a select group of our Redis Enterprise customers and as a release candidate to our community).
In this section we’re going to describe the new features provided by this new release of RediSearch. But first, here is a reason why we are releasing those two popular modules together:
Indexing, querying, and full-text search of JSON documents
This particular new feature will bring Redis’ JSON capabilities to a whole new level. Going beyond being a Key-Value store, until now, RediSearch has been providing indexing and search capabilities on hashes. Under the hood, RedisJSON 2.0 exposes an internal public API. Internal, because this API is exposed to other modules running inside a Redis node. Public, because any module can consume this API. So does RediSearch 2.2 !
By exposing its capabilities to other modules, RedisJSON gives RediSearch the ability to index JSON documents so users can now find documents by indexing and querying the content. These combined modules give you a powerful, low latency, JSON-oriented document database!
Let’s have a look at what this would look like.
We should first populate the database with a JSON document using the JSON.SET command.
To create a new index, we use the FT.CREATE command. The schema of the index now accepts JSONPath expressions. The result of the expression is indexed and associated with an attribute (here: title).
We can now do a search query and find our JSON document using FT.SEARCH:
Aggregation on JSON documents
Aggregation is a powerful feature of RediSearch that can be used to create analytic reports or perform faceted search style queries. Now that RediSearch can access JSON documents, it’s possible to load any value from a JSON document using JSONPath expression and use it in a pipeline whether the value is indexed or not.
Let’s create an index:
Add a JSON document to the database:
And do a simple computation using two numeric value extracted from the JSON document:
More flexibility on the indexing strategy
With the new version of RediSearch, it’s now possible to index the same value (field on hashes, or JSON Values from a JSON document) with different parameters. Here is a typical use case, solved by this new feature:
Let’s have a database containing documents that belong to categories.
Using the TAG type you can then easily filter your search results on any category:
But what if you also want to be able to do a full-text search on categories?
Until now, with hashes, you had to duplicate the value into two fields, which would consume twice the memory.
This is where FT.CREATE…AS has become more than handy. Let’s get back to our nice and simple document:
…and use the new AS feature:
…and…
Bingo! We can now filter by a tag, and do a full text search in the same field, without having to duplicate the data.
Query profiling
Time complexity of most of the Redis commands is well documented. As an example, HMGET comes with a complexity of O(N), “where N is the number of fields being requested.” With RediSearch, it’s possible to write advanced queries. The complexity of the FT.SEARCH and the FT.AGGREGATE commands, however, depend on the complexity of the query.
We wanted to give you the tools to understand what’s happening under the hood when a query is executed, to figure out where time is consumed, and how the query can be optimized. The new FT.PROFILE command returns a tree showing the main steps used by RediSearch to execute the query. For each step, a time information is given.
So what happens inside RediSearch when we are doing a query with a fuzzy search ?
Let see an example:
We are ready to profile our query. Let’s run the profiling and decompose the profiling result.
redis.cloud:6379> FT.PROFILE idx SEARCH LIMITED QUERY "%hello%"
First we get the result. Useful to check that the profiling query returns what is expected.
Here is the total time, called “profile time”, because it includes the time spent in collecting the profile information.
The time spent in parsing the query and building the execution plan:
Here is the time spent in finding the fuzzy matches in the dictionary:
And finally, have you ever wondered what it means to build a search result? We need to compute the full-text score for each document, sort them by score, and finally load the fields. With this information you can identify bottlenecks, make queries faster, and improve performance of the server.
How to get started
We believe that these new capabilities are game changers for application developers and the Redis community. Here’s how you get started.
Use the docker image of the preview
To get started you can pull the following docker image with the :preview tag:
Alternatively, you can compile from the RC1 release tags (v2.2.0 for RediSearch, v2.0.0 for RedisJSON) on both repositories and load them to Redis.
Once you’re up and running, you can try out all the above commands or with this quickstart guide. We will also be launching a series of blogs about RedisMart, an online retail application that we showcased during the keynote of RedisConf 2021. RedisMart leverages RediSearch and RedisJSON deployed in a geo-distributed manner to deliver the best online retail experience. In this series, we’ll walk you step by step through how we build this application.
Develop using the latest versions of the compatible clients
The following list of clients are currently being upgraded so you’re able to use the new features with a good developer experience. Check the latest releases and/or the pull requests (at this moment most of them are supporting the preview version on the master branches).
| RedisJSON | RediSearch | |
|---|---|---|
| Node.js | redis-modules-sdk | redis-modules-sdk |
| Java | JredisJSON | JRediSearch |
| .NET | NRedisJSON | NRediSearch |
| Python | redisjson-py | redisearch-py |
Join the community
We welcome any feedback, bug reports, feature requests while we work towards General Availability. Leave feedback on the documentation websites or in the github repositories of RediSearch (on Github) or RedisJSON (on Github), or get in touch with us on Discord.
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.