Blog
Try Redis 8.0-M02 today. The fastest Redis ever.


We’re happy to announce the second milestone of Redis 8, our most advanced and performant offering yet, available for you to try in Community Edition (CE) today.
In CE 8.0 M01 (Milestone 1 pre-release), we introduced new data structures: JSON, time series, and 5 probabilistic data structures (previously available as separate Redis modules).
Today, in CE 8.0 M02, we’re introducing major performance improvements. The latency of many commonly used Redis commands has been significantly reduced. For example, up to 36% reduction in latency for ZADD, up to 28% for SMEMBERS, and up to 10% for HGETALL—compared to Redis 7.2.5.
In this version, we also made two significant improvements available to our community that previously were only available in Redis Cloud and Redis Software. We added the ability to scale the Redis Query Engine vertically as well as horizontally. To showcase what can be achieved with this, we created a vector search benchmark with 1 billion 768-dimensions vectors—running on a Redis Community cluster.
You can now also download Community Edition 8.0-M02 now as either an Alpine or a Debian Docker image. More distributions will become available as we progress to the 8.0 CE GA release.
At least 70% of Redis users will see a substantial latency reduction
We continuously monitor how tens of thousands of customers and community members are using our Redis managed service. Anonymised statistics collected provide us with a very accurate understanding of how Redis is being used. Based on this, we optimize our ongoing investment in performance improvements.
Since Redis 7.2.5, we introduced significant latency reduction and throughput increment for many common commands and usage patterns.
For the complete list of performance optimizations, please take a look at the “Performance and resource utilization improvements” sections in the 7.4 RC1, 8.0 M01, and 8.0 M02 release notes. There are 18 performance optimizations on M01 and M02 that strictly focus on reducing CPU cycles, reducing memory allocations, and optimizing data access patterns of commonly used code—including replies handling, data structures improvements and deduplication. In short, Redis is now more CPU efficient and cache friendly.
The following chart depicts, per data structure, the p50 (median) latency reduction in Redis 8.0-M02 compared to Redis 7.2.5. We can see p50 latency improvements across data types ranging from 9% to 53% latency reduction.
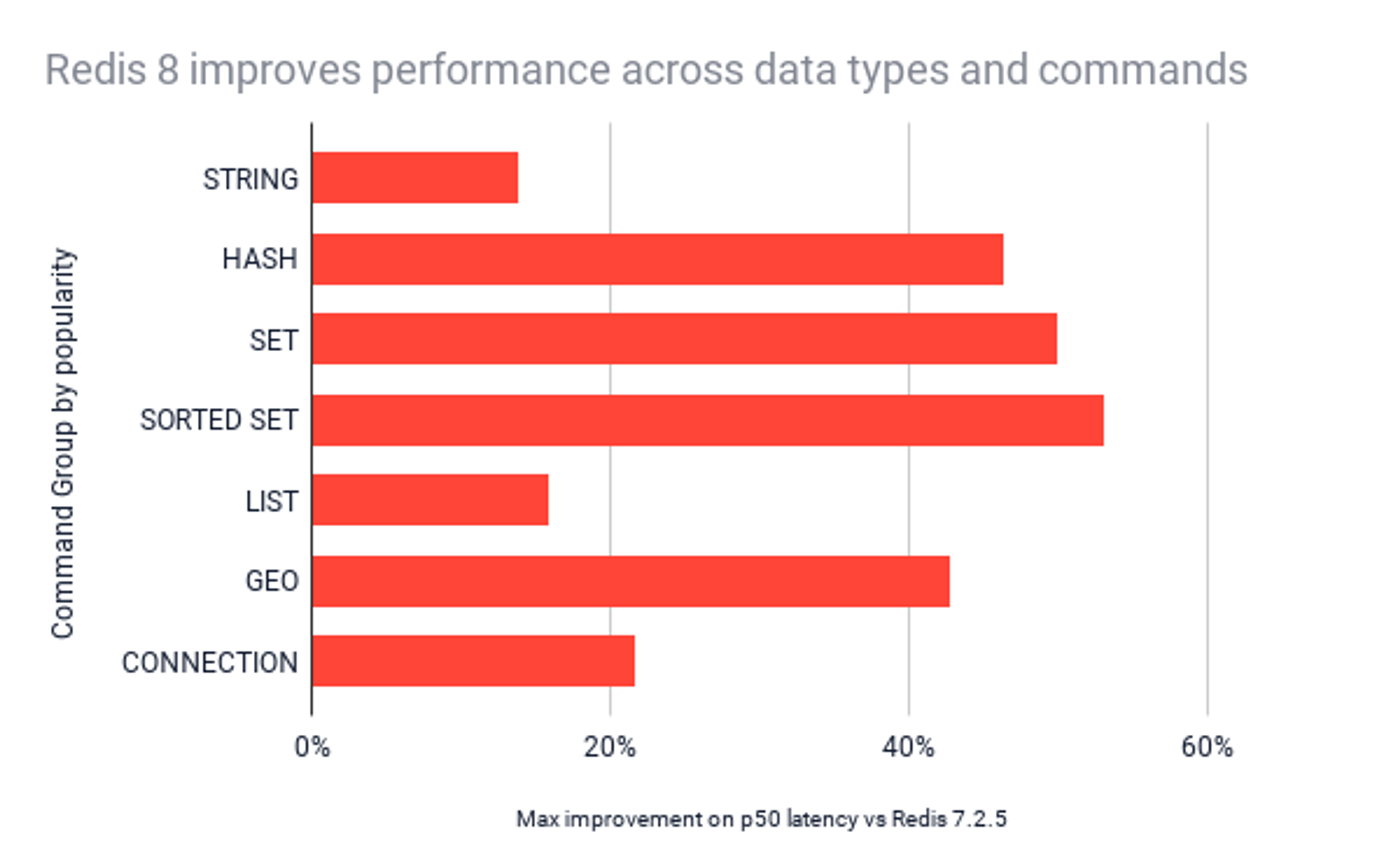
When looking at the p50 latency per command, we can see for example, up to 36% reduction in the median latency for ZADD and up to 28% reduction in the median latency for SMEMBERS.
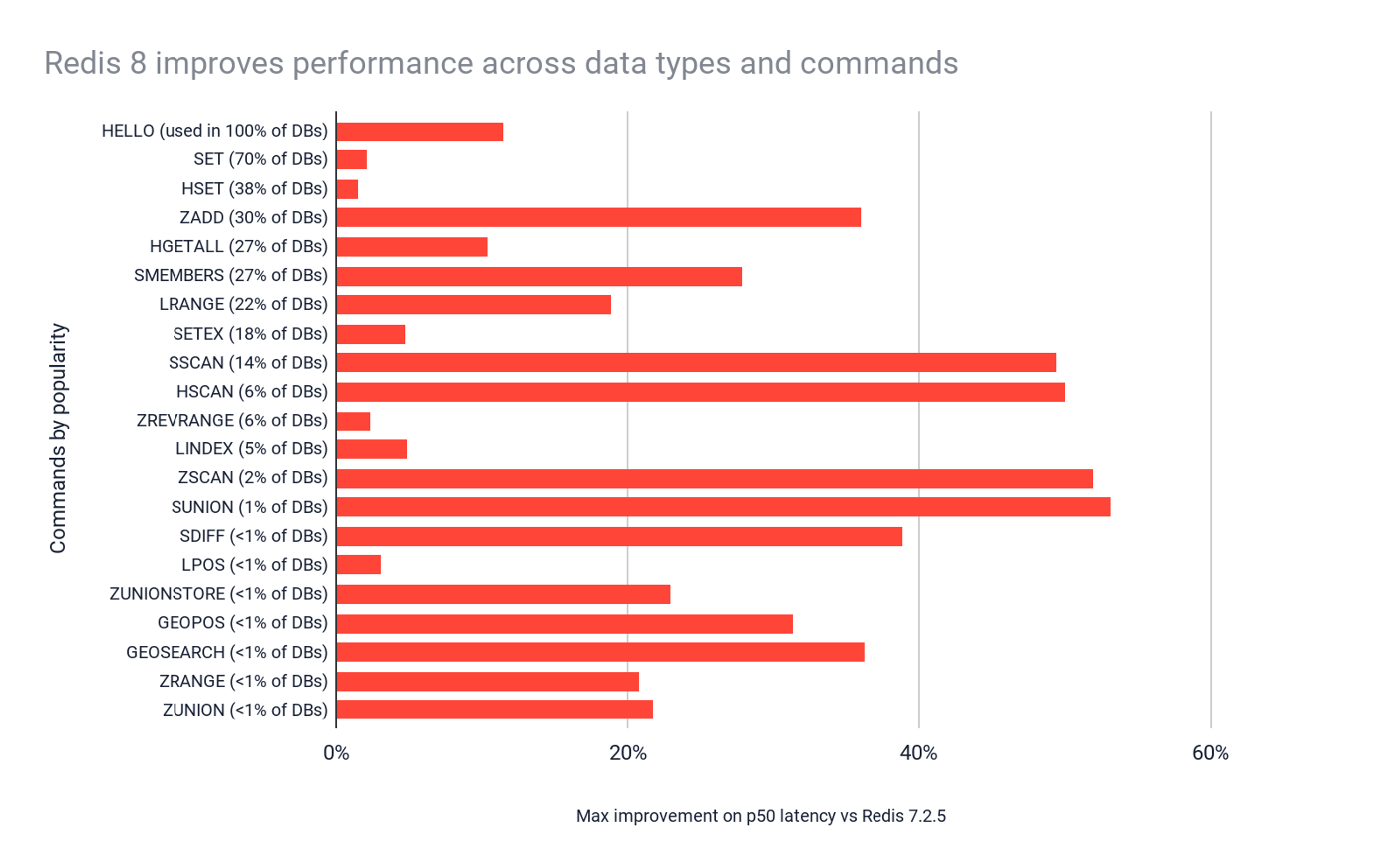
The (% of DBs) for each command is the percentage of databases on our managed service that use this command.
Not only the median latency is significantly lower; also the tail latencies were reduced, as can be seen on the p99 chart below. This means Redis 8.0 commands are faster with more predictable and constant performance per command.
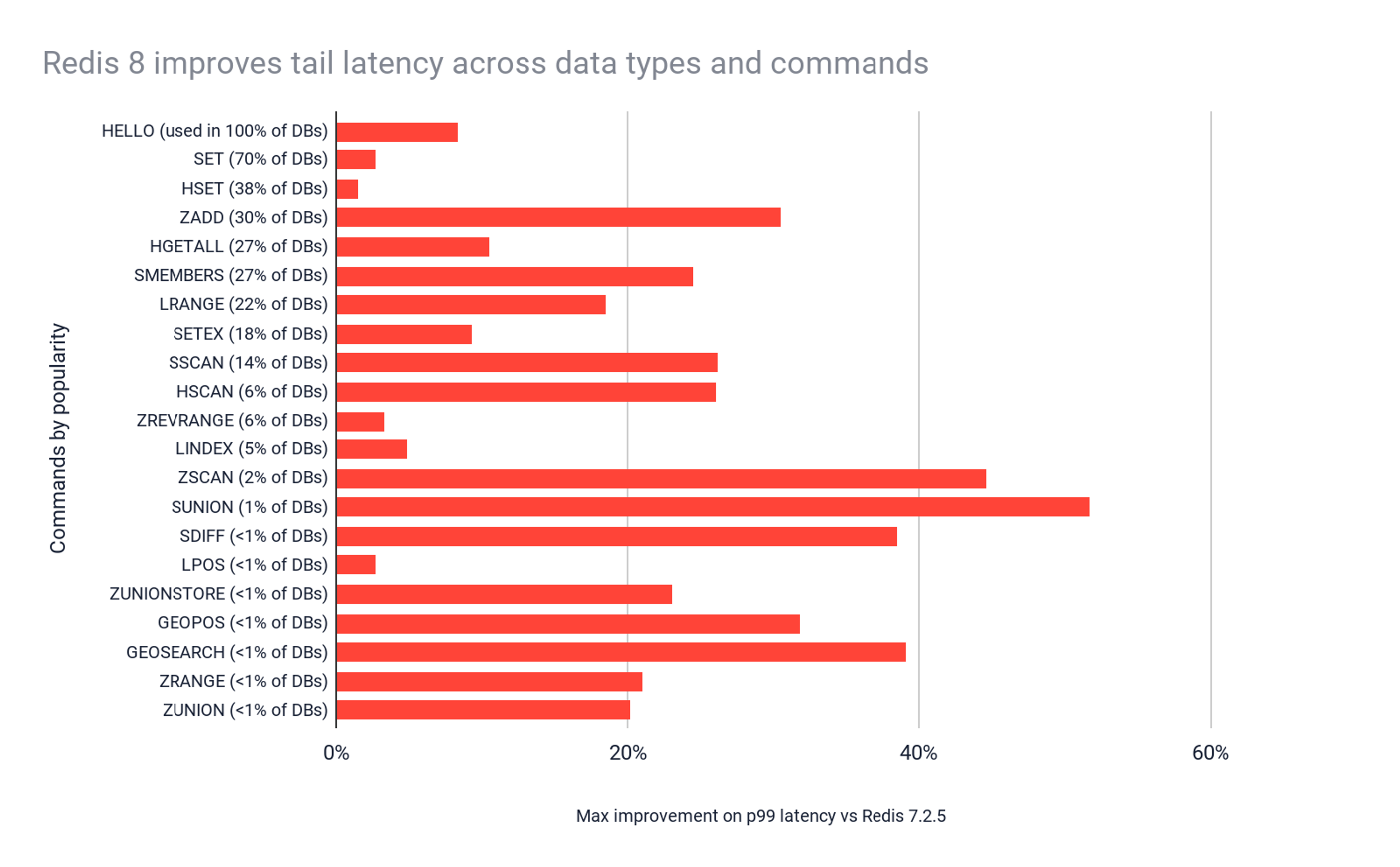
We see significant performance improvements over 20 commands of Redis, some of which with a broad usage and impact. 70% of the Redis databases use the SET/SETEX command and 30% use ZADD. Overall, the vast majority of Redis users will see significant performance improvements.
Redis Query Engine— horizontal and vertical scaling on Redis CE
Community Edition 8.0 also includes two scaling features of the Redis Query Engine that were previously only available on Redis Cloud and Redis Software. The first feature enables querying in clustered databases, allowing you to manage very large data sets with indices and support for higher throughput of reads and writes by scaling out to more Redis processes. The second feature allows you to add more processing power scaling your query throughput vertically, enabling up to 16 times more throughput than before. With these additions, Redis Community Edition is now the fastest vector database available, for free.
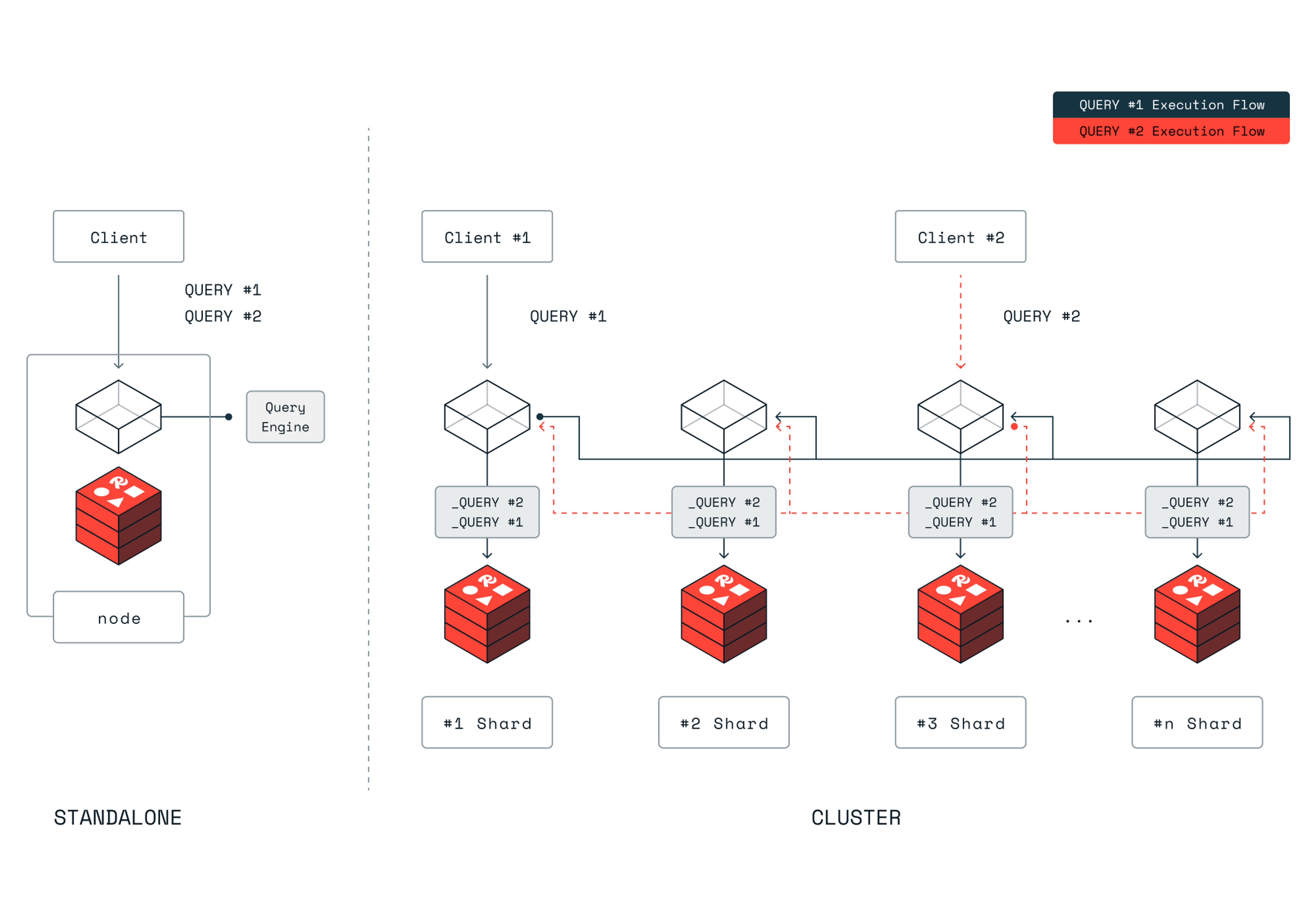
Searching 1 billion 768-dimensions vectors
Utilizing Redis CE 8.0 scaling capabilities, we demonstrate how you can perform vector search queries at real time on a one billion 768-dimensional vector embeddings at high precision.
We use a vector dataset prepared in collaboration with our Intel® Partners, consisting of one billion 768-dimensional vectors, using FLOAT16 precision and 10K queries with 100 ground truth (exact neighbors) per query, derived from the LAION-5B dataset, an open large-scale dataset for training next generation image-text models like Stable Diffusion and OpenClip.
The vector index used the Euclidean distance metric and FLOAT16 precision, and the following parameters were varied to achieve different precision during query time:
- EF_CONSTRUCTION (set at index creation): Number of maximum allowed potential outgoing edges candidates for each node in the graph during the graph building.
- M (set at index creation): Number of maximum allowed outgoing edges for each node in the graph in each layer. On layer zero the maximal number of outgoing edges will be 2M.
- EF_RUNTIME (variable at query time): The number of maximum top candidates to hold during the KNN search. Higher values of EF_RUNTIME will lead to more accurate results at the expense of a longer runtime.
The dataset’s ground truth of 100 nearest neighbors was used to evaluate the accuracy (recall) of each reply, and we varied M between 4, 8, 16, and 32 outgoing edges, EF_CONSTRUCTION between 4, 8, 16, and 32, and EF_RUNTIME between 4, 8, 16, 32, 64, 128, 256, 512, 1024, 2048, 4096, and 8192. To ensure reproducible results, each configuration was run 3 times, and the best results were chosen. Read more about the HNSW configuration parameters and query.
Redis CE 8.0-MO2 Billion scale benchmark
In a previous blog post, we focused on proving that Redis is the fastest vector database. Now we prove that we can extend from millions-vectors to billion-vectors use cases while preserving real-time latency.
At a billion-vectors scale, with real time indexing, Redis CE 8.0 can sustain 66K vector insertions per second for an indexing configuration that allows precision of at least 95% (M 16 and EF_CONSTRUCTION 32). For indexing configurations that result in lower precisions (M 4 and EF_CONSTRUCTION 4), Redis CE 8.0 can sustain higher ingestion rates of 160K vector insertions per second. Throughput can be increased further by using more servers.
For high precision queries, we can see that larger HNSW indices (higher M and EF_CONSTRUCT) improves the search quality at the expense of latency. We reach 90% precision with a median latency including RTT of 200ms, and 95% precision with a median latency includ/ing RTT of 1.3 seconds for the top 100 nearest neighbors, while executing 50 search queries concurrently.
Since the required precision and latency trade off are use case dependent, it is important to tune your HNSW parameters as depicted in the chart above.
Redis 8.0-M02 is available now
We are committed to continuous improvement and innovation. In Redis CE 8.0-M01, we introduced new integral data types. In 8.0-M02, we’ve reduced the latency of more than 20 commands, for common usage patterns, by up to 54%. In addition, our enhanced query engine now supports fast querying, search and vector search, and scales both horizontally and vertically.
We still have exciting plans for the upcoming pre-releases of 8.0 that are worth waiting for. In the meantime, you can experiment with 8.0-M02 by downloading an Alpine or a Debian Docker image from Docker Hub.
Appendix
Benchmark setup
Our benchmarks were done with an on-prem setup, using a total of 6 servers, powered by 3rd generation Xeon Scalable server processors (Intel IceLake CPUs): 1 client server, and 5 DB Servers connected to a high-speed 40Gb switch, The hardware was set up by Intel. Read more about how Redis collaborates with Intel to optimize performance.
The results were obtained using the Redis CE (Community Edition) 8.0-M02, with the cluster having 200 primaries in total.
Reproducing the benchmark results
Our results are obtained in a deterministic and easy-to-replicate manner. To reproduce the above results, you should use the redis-benchmark-specification, specifically the client runner utility, an easy-to-install tool that contains all the requirements to run the benchmarks and analyze the results.
You can get to the same improvements by using the following command (and adjusting the connection details).
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.