Blog
Announcing RedisAI 1.0: AI Serving Engine for Real-Time Applications


As modern mission-critical applications incorporate more and more machine learning techniques, they face some surprisingly complex challenges. Those challenges center around coping with real-time model serving requirements and monitoring the impact of these new features on end users.
We’re happy to announce that RedisAI, an AI serving engine for Redis, is now generally available. RedisAI was built with two core goals:
- Minimizing end-to-end inferencing time by reducing the time spent on processes other than inferencing.
- Simplifying a scalable deployment of AI models.
RedisAI is designed to run where the data lives, decreasing latency and increasing simplicity, in use cases ranging from transaction scoring and fraud detection to recommendation engines personalization, among many others. For more information on common use cases and when to apply it, see the RedisAI product page.
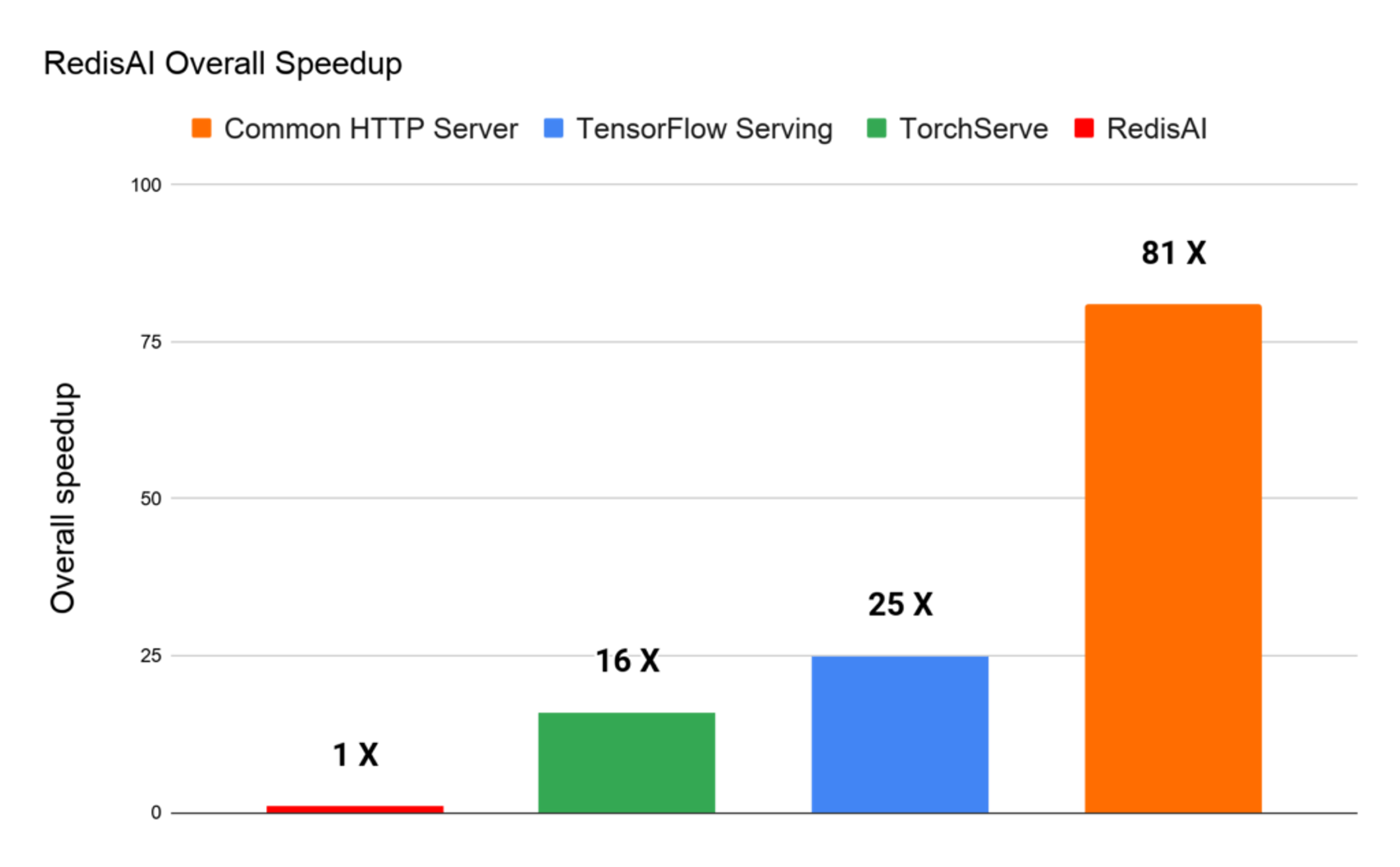
This blog is intended to help developers and architects see under the hood of RedisAI, and learn how it addresses the goals listed above. We will dive into architecture and share the benchmarks we’ve established for a prominent real-world AI problem—real-time fraud detection on financial transactions. These benchmarks reveal that RedisAI increases speed by up to 81x compared to other model serving platforms, when the overall end-to-end time is not dominated by the inference itself.
RedisAI architecture
Most artificial intelligence (AI) frameworks ship with a runtime for executing the models developed with it, and the common practice for serving these is building a simple server around them. Because RedisAI is implemented as a Redis module, it automatically benefits from the server’s capabilities, including Redis’ native data types and robust ecosystem of clients, as well as its persistence and clustering, not to mention the flexibility provided by Redis modules and the peace of mind of proven Redis Enterprise support. Of course, there’s also Redis’ high availability (99.999%) and infinite linear scalability.
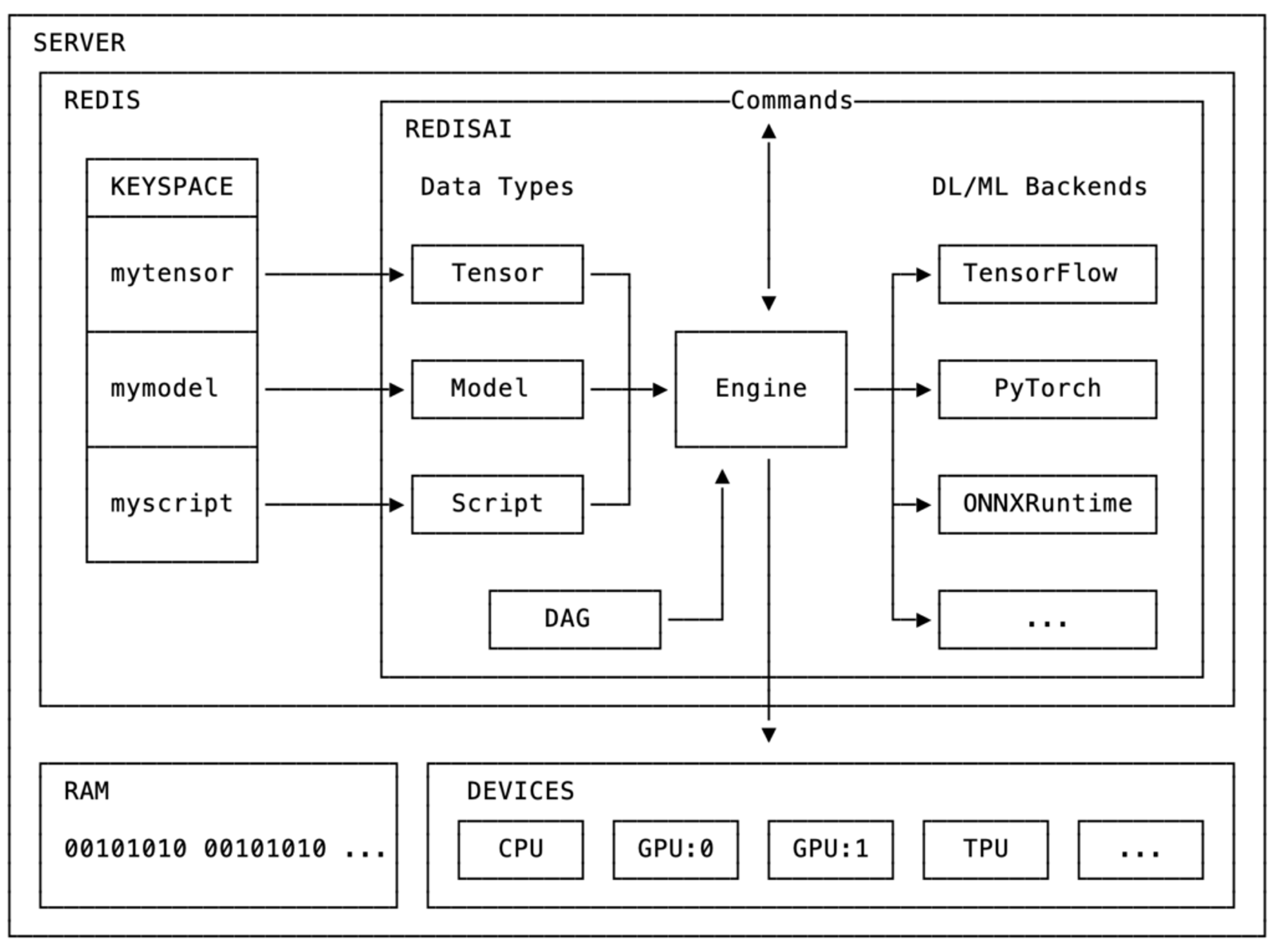
RedisAI architecture.
Because Redis is an extendable in-memory data structures server, RedisAI uses it for storing its machine learning (ML) native data types. The main data type supported by RedisAI is the tensor, which is the common representation of ML data.
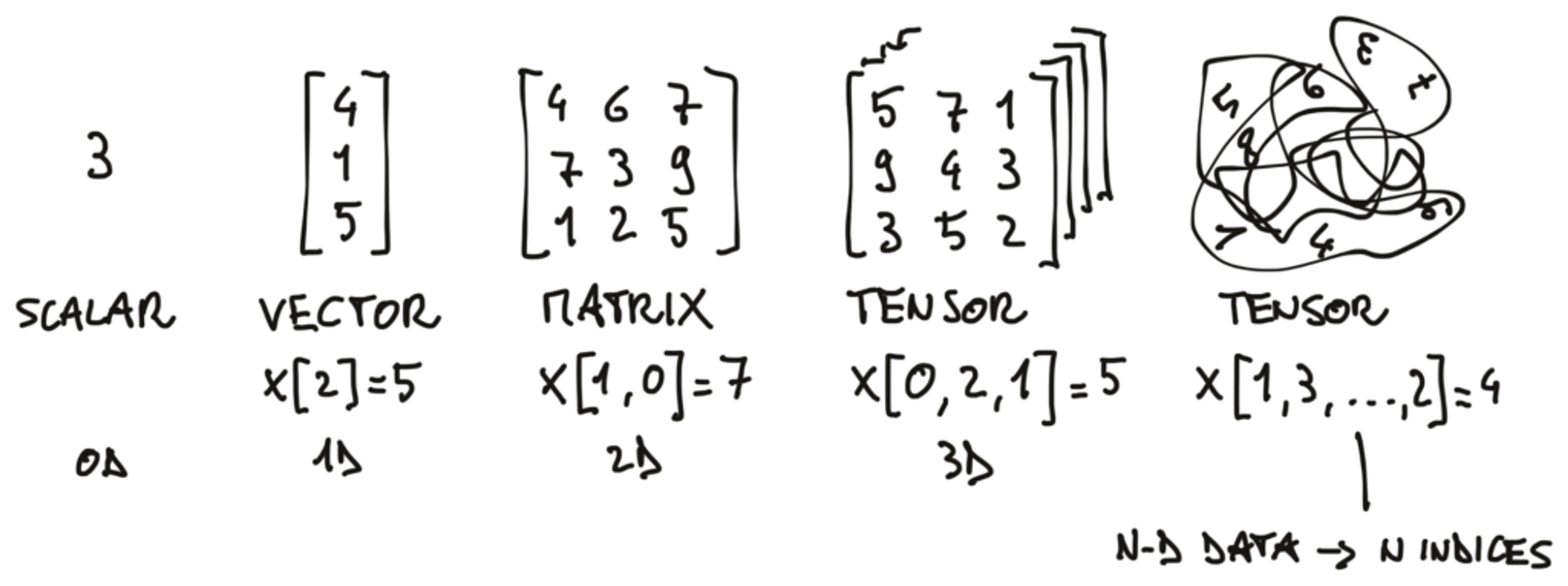
What are tensors?
Additionally, RedisAI adds two data structures—models and scripts—for model runtime features. Models represent a computation graph by one of the supported deep learning (DL) or machine learning framework backends and are set with information about which device they should run on (CPU or GPU) and backend-specific parameters. RedisAI has several integrated backends, including TensorFlow, Pytorch, and ONNXRuntime.
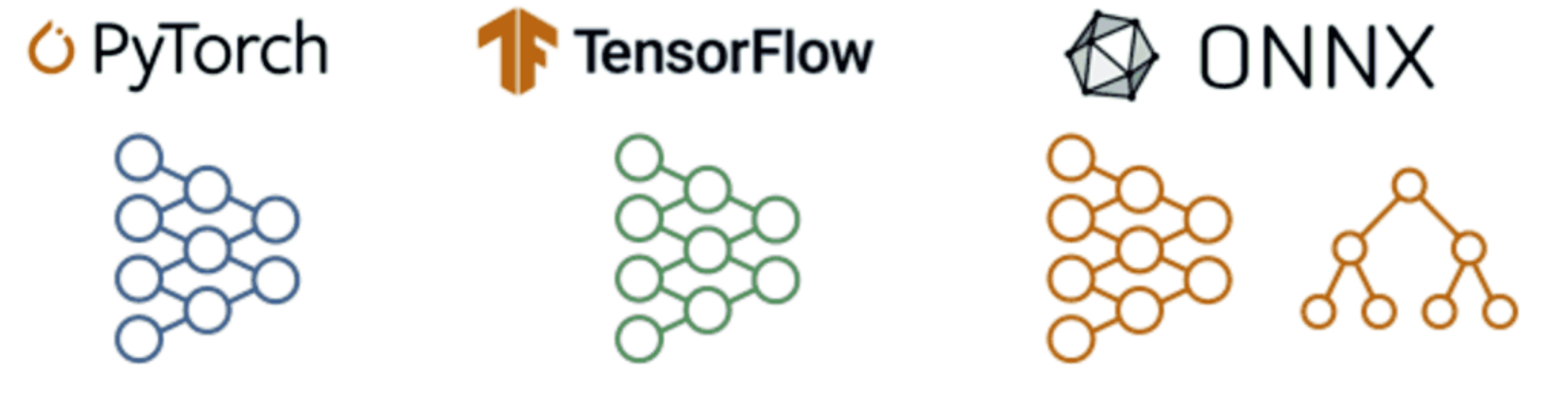
Supported backends in RedisAI.
Scripts can run both on CPUs and GPUs, and let you manipulate tensors via TorchScript, a Python-like domain specific language (DSL) for tensor operations. This lets you pre-process your input data before you execute your model, and post-process the results, such as for ensembling different models to improve performance.
Because tensors are stored in the memory space of the Redis server, they are readily accessible to DL/ML backend libraries and scripts, with minimal latency. This locality of data allows RedisAI to provide optimal performance when serving models. It also makes it a perfect choice for deploying DL/ML models in production and allowing them to be used by any application.
Importantly, this architecture is not tied to a single backend, letting you decouple your backend choice (a decision typically made by data scientists) from the application services using these models to provide functionality. Switching models (even when the model is created in a different backend) is as easy as setting a new key into Redis.
Other important RedisAI features include its auto-batching support and the DAG (as in direct acyclic graph) command. With auto-batching, requests from multiple clients can be automatically and transparently batched into a single request to increase CPU/GPU efficiency during serving. The new AI.DAGRUN command supports the prescription of combinations of other RedisAI commands in a single execution pass, where intermediate keys are never materialized to Redis.
Benchmarking RedisAI
To benchmark RedisAI, we created a benchmark suite consisting of a fraud-detection use case based on a Kaggle dataset with the extension of reference data. This use case aims to detect a fraudulent transaction based on anonymized credit card transactions and reference data.
We used this benchmark to compare four different AI serving solutions:
- TorchServe: built and maintained by Amazon Web Services (AWS) in collaboration with Facebook, TorchServe is available as part of the PyTorch open-source project.
- Tensorflow Serving: a high-performance serving system, wrapping TensorFlow and maintained by Google.
- Common REST API serving: a common DL production grade setup with Gunicorn (a Python WSGI HTTP server) communicating with Flask through a WSGI protocol, and using TensorFlow as the backend.
- RedisAI: an AI serving engine for real-time applications built by Redis and Tensorwerk, seamlessly plugged into Redis.
We wanted to cover all solutions in an unbiased manner, helping prospective users make an informed decision on the solution that best suits their case, both with and without data locality.
Read more about the optimization in the addendum.
See Addendum
Addendum: Benchmark Infrastructure and Details
We wanted the infrastructure to reflect a production-grade model serving instance, so we used an AWS Deep Learning AMI v27 optimized for deep learning on EC2 with NVIDIA CUDA, cuDNN, and Intel MKL-DNN.
For both Model Serving and benchmark clients, we used the latest-generation instance classes optimized for compute-intensive applications. We used c5.12xlarge instance sizes, with Intel Hyper-Threading Technology enabled, thus offering 48 VCPUs for each EC2 instance, improved networking performance, and large memory capacity.
Regarding the Model Serving software stack, the base OS was Ubuntu 18.04, Linux kernel version 4.4.0-1095-aws, TensorFlow Serving version was 1.15.2, the TorchServe version was v0.0.1 with PyTorch 1.5, the Gunicorn solution with TensorFlow version was 1.15, and the Redis Enterprise version was 5.6.0.
We followed best practices for high-performance serving for each benchmarked solution. For more details on the in-placed optimization, visit the performance section of the RedisAI documentation.
Finally, some model servers have components that are lazily initialized, which can cause high latency for the first requests sent to a model after it is loaded. To reduce the cold start influence on the overall performance of that solution, we added 10,000 full-inference burn-in cycles, which are not taken into account across all model servers.
On top of that, we wanted to reduce the impact of reference data in this benchmark so that it sets the lower bound of what is possible with RedisAI, by:
- Using a high-performance data store common to all solutions (Redis). We wanted to make sure that the bottleneck is not the reference data store and that we stress the model server as much as possible. When the reference data is held in one or more disk-based databases (relational or NoSQL) then RedisAI’s performance benefits will be even greater.
- Preparing your data in the right format. The reference data for the non-RedisAI solutions is stored in Redis as a blob. This is the best-case scenario. In many applications, data needs to be fetched from different tables and different databases and be prepared into a tensor. RedisAI has a tensor data structure that lets you maintain this reference data in the right format.
- Keeping the reference data to a minimum. The reference data in this benchmark was kept to 1 kilobyte of data but can easily become several megabytes. The larger the reference data, the bigger the impact of data locality on performance.
Baseline latency comparing different solutions
The first test compares the solutions without any reference data for single client performance. All serving solutions in this benchmark are essentially a serving wrapper around their core libraries. The setup and data flow is shown here:

The baseline setup for all AI serving solutions under test.
The table below shows the end-to-end inference time measured on the benchmark client. This test sets the baseline. It shows that RedisAI does not introduce any overhead on running a model compared to other serving solutions. In certain cases it is even more optimized, largely due to the programming languages that were chosen (RedisAI is written in C/C++, TensorFlow Serving in C++, TorchServe is written in Java, and the common REST API servers are written in Python).
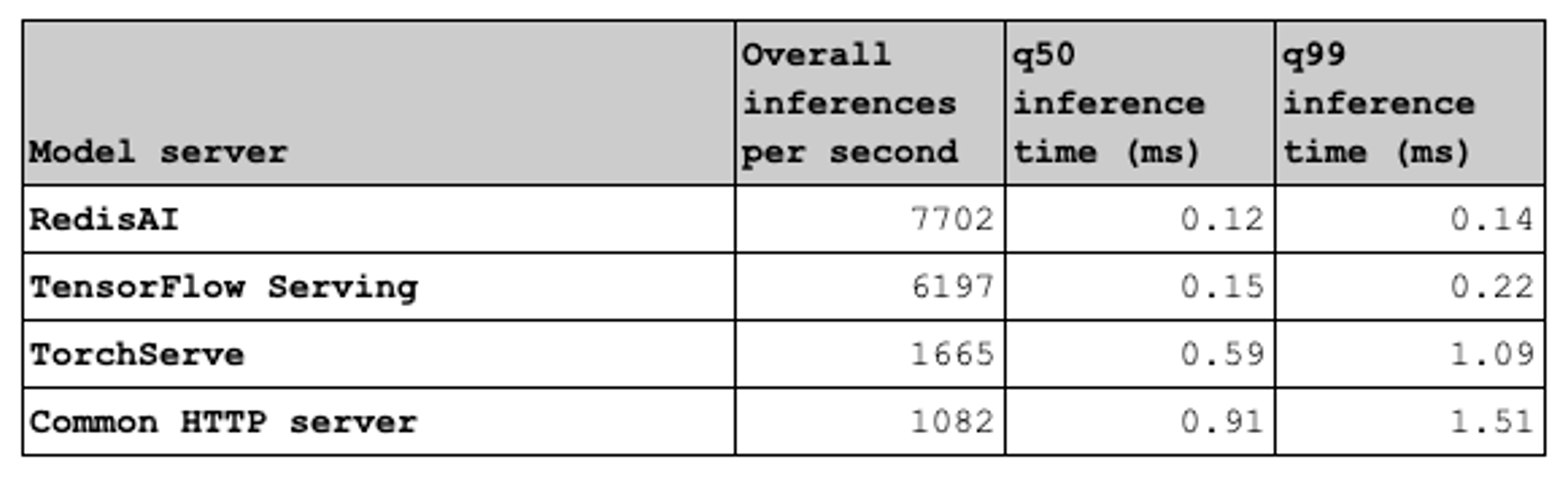
Impact of latency with reference data
Now that we have set the baseline, let’s look at how the latency is impacted when the model requires 1KB of reference data. For TensorFlow Serving, TorchServe, and Gunicorn, the reference data will reside in a different host.
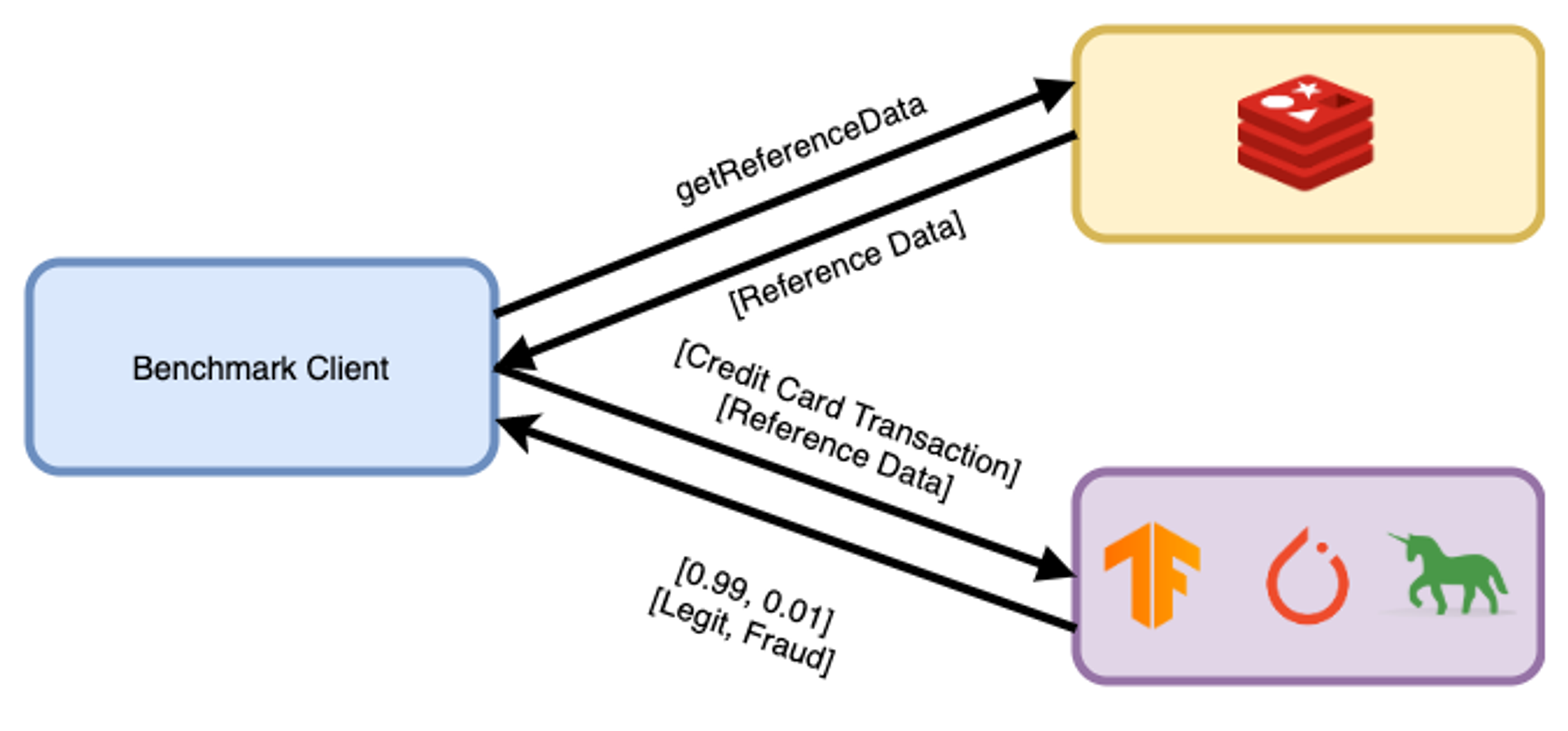
Benchmark setup with reference data for Tensorflow Serving, TorchServe, and Gunicorn.
As explained above, for RedisAI, the reference data resides within Redis, already as a tensor. That’s why the setup is simpler:
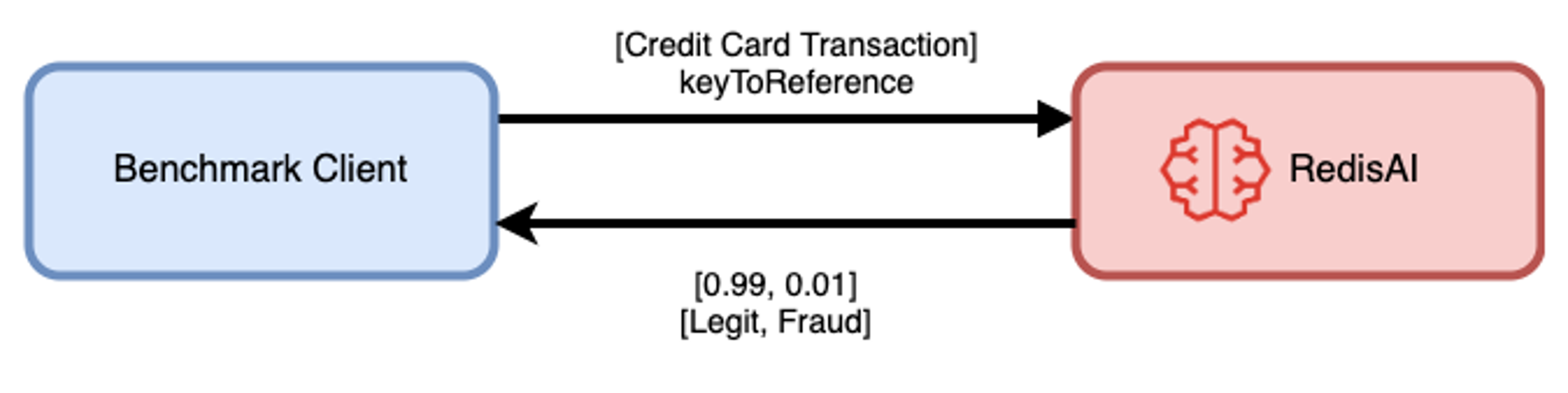
Benchmark setup with reference data for RedisAI.
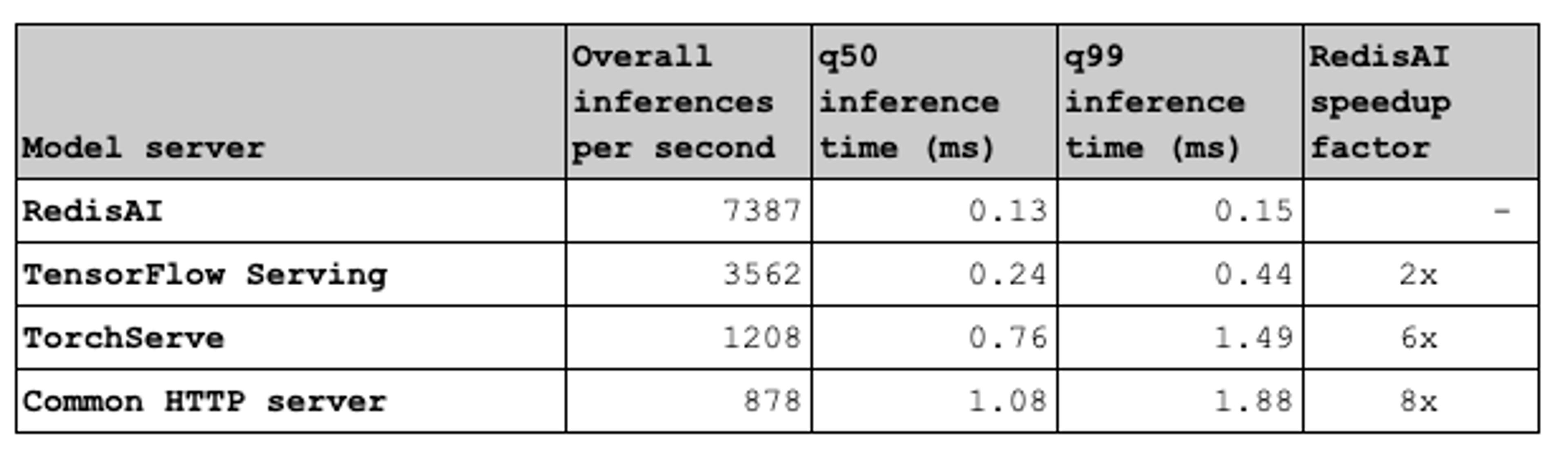
The table below captures the results of this second test, and shows that RedisAI reduces end-to-end inference latency up to 8x compared to other model serving solutions when there is reference data at play for single-client performance. The q99 numbers, meanwhile, show that RedisAI delivers a much more stable solution than any others:
How do these solutions handle scale?
After analyzing the single-client performance, the next question is how do these solutions scale on highly concurrent scenarios? We designed a third test in which we varied the number of clients from 16 to 160, increasing 16 clients at a time.
For a dataset consisting of 1 million distinct credit-card transactions, the common HTTP server solution was limited at around 21K full inference cycles per second, TensorFlow Serving at around 40K full inferences cycles per second, TorchServe at around 50K full inference cycles per second, and RedisAI at around 192K full inference cycles per second.
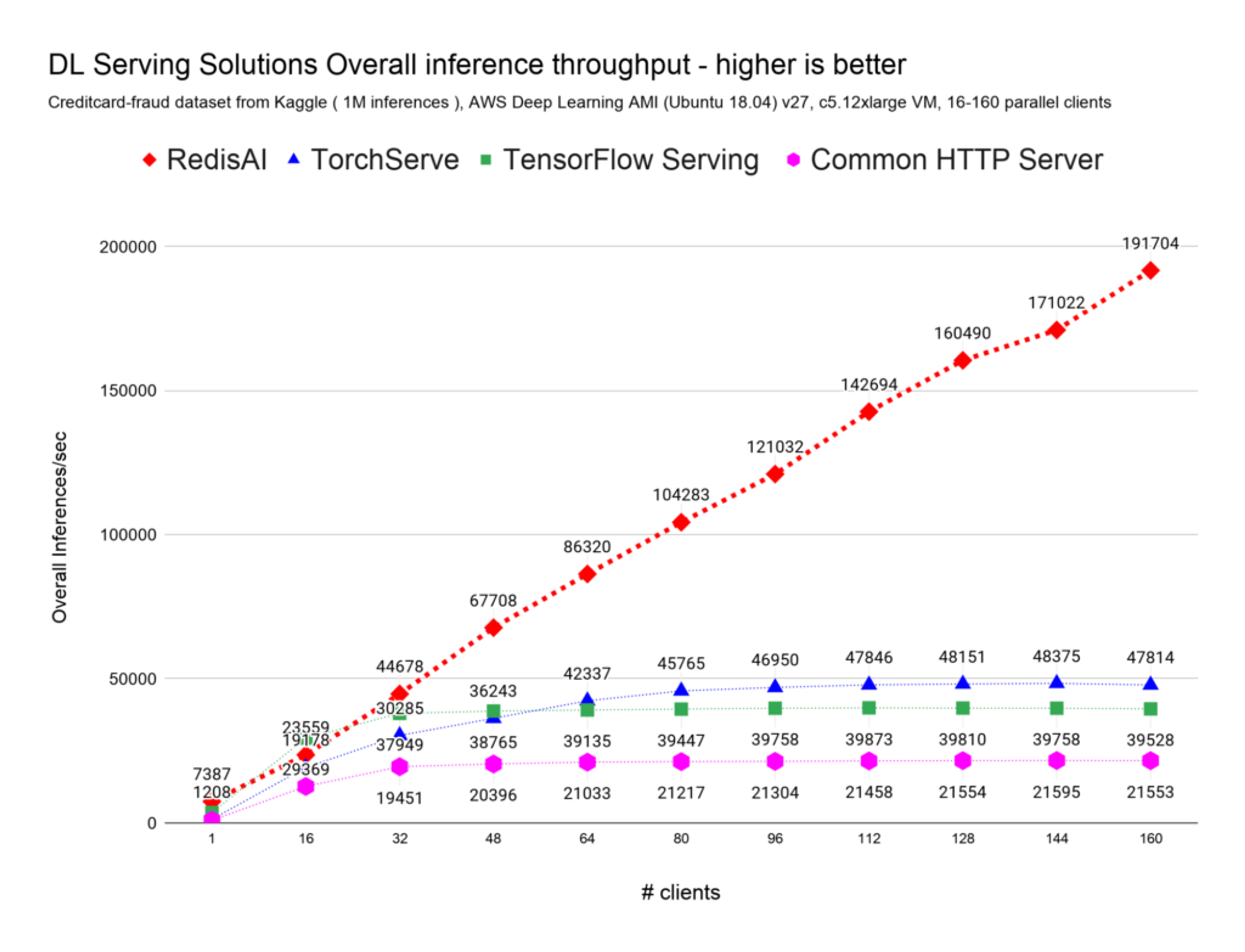
On the same hardware and serving based on the same model, RedisAI handles 4.8 times more inferences than TensorFlow serving, 4 times more inferences than TorchServe, and 9 times more inferences than common web APIs, as shown here:
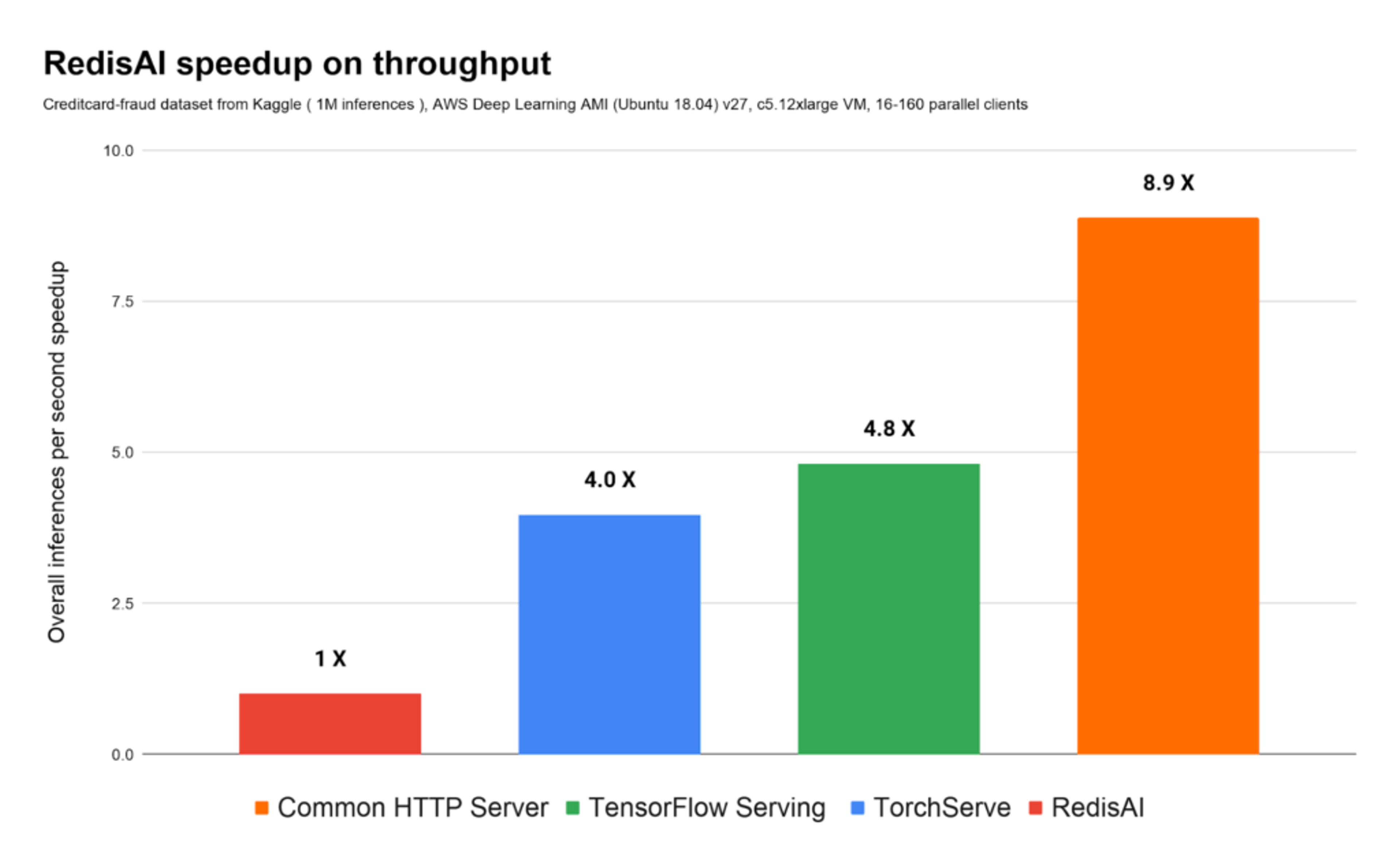
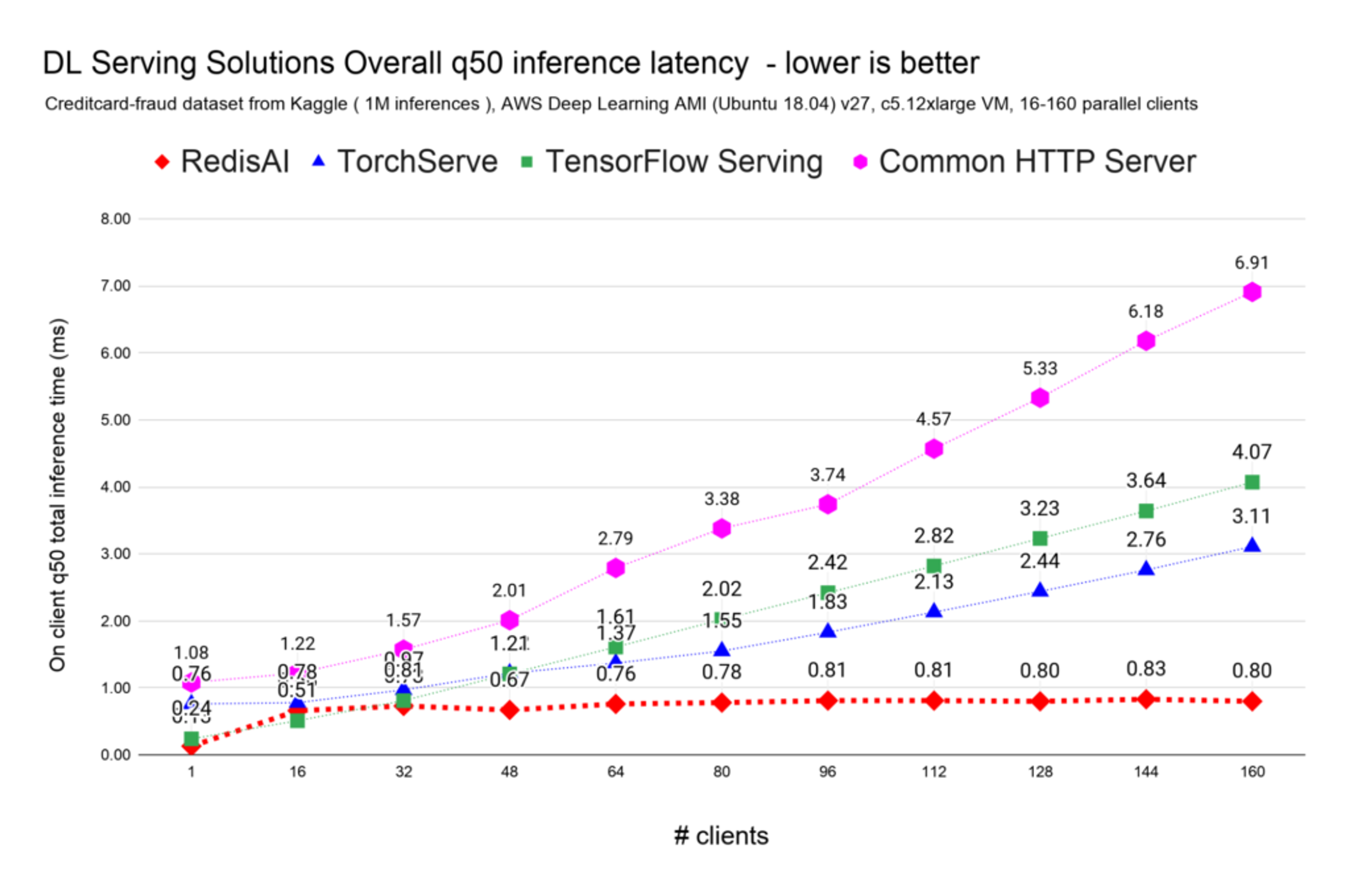
Considering the best results for each distinct model serving solution, note that while other model servers are overloaded at around 50K inferences per second, RedisAI is performing at steady and stable sub-millisecond latencies, without requiring additional virtual machines to be added to the cluster, at up to 190K inferences per second, as seen in these charts:
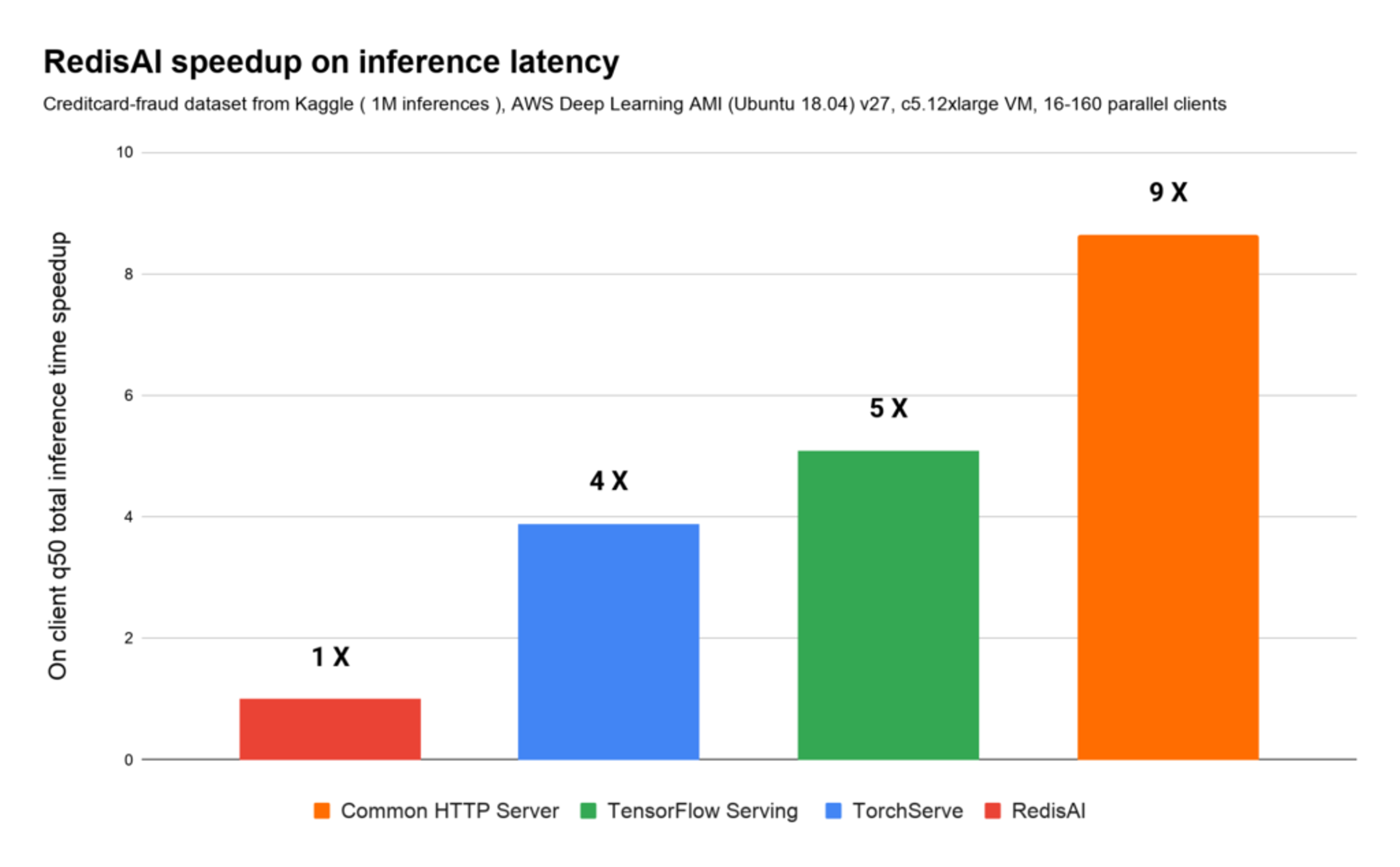
If you relate the speedup factors on throughput and inference latency, RedisAI presents an overall speedup of 16x vs. TorchServe, 25x vs. TensorFlow Serving, and 81x vs. the common HTTP server. This means that on the same underlying hardware RedisAI can be 81x more efficient on serving the total 1 million inferences, as illustrated here:
Benchmark analysis
This initial benchmark shows that data locality makes a tremendous difference in the benchmark and in any real-life AI solution.
Note that the impact of reference data in this benchmark has been greatly reduced, and, as mentioned earlier, only sets the lower bound of what is possible.
We plan to enhance our benchmark and create more setups in line with many modern and legacy deployments so that you can easily understand the potential speedup of your application architecture.
Lastly, as seen on the previous charts, for high-load/high-concurrency use cases, there is no match for RedisAI, given that Redis is the only model server retaining sub-millisecond latencies and steady and state results as we increase concurrency.
RedisAI: Built for high performance
RedisAI achieves these impressive results mainly because it was built from the ground up for high performance. Seamlessly plugged into Redis, it uses Redis’ core characteristics to scale while avoiding the usual high-load/high-concurrency workload bottlenecks that Redis has already solved.
RedisAI is fast, stable, and supports multiple backends—and we’re constantly working to enhance its capabilities. (In upcoming blogs we plan to focus on how you can deploy models with the support for ML-flow and how you can monitor your models in production.) RedisAI shows that we can create a feature-rich, high-performance model server on top of Redis. We’re looking forward to hearing your feedback, so please get in touch or comment on GitHub, or at the new RedisAI community forum.
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.