
Download Caching at Scale e-book. A primer you need to understand what application caching is, why and when it’s needed, and how to get the best performance from your applications.
If you believe Ralph Waldo Emerson, a foolish consistency may be the hobgoblin of little minds, but when it comes to implementing a scalable, successful enterprise-level caching strategy, there’s nothing foolish about consistency. In fact, one of the greatest challenges in managing the operation of an enterprise database is maintaining cache consistency.
Why do we bother with caches in the first place? The principal advantage of an enterprise cache is the speed and efficiency at which data can be accessed. While each call to the primary database can be expensive in terms of both time and processing power, a call to a cache can be lightning-quick and have no impact on the primary database.
Three obstacles to cache consistency
Of course, these advantages rest on the fundamental assumption that the data in the cache—or caches—always maintain the same values as the source data. Although this may seem like a straightforward goal, it’s easier in theory than in practice. In fact, there are three pitfalls that can derail it:
1. When changes to the primary database aren’t reflected in the cache
Because accessing data via a cache is, by definition, faster than accessing the data via the primary database, if a specific item is requested, the cache will be consulted first. Assuming the item exists in the cache, it will be returned far more quickly than it would from the primary database. This strategy is known as the cache-aside pattern. The cache is checked first by default. If the data isn’t in the cache, the application queries the primary database and deposits the result in the cache on the way back to the user.
The problem arises during the gap between when the data in the primary database is changed and when the cache is adjusted to reflect said change. This is influenced by how frequently the application checks the cache. However, each check comes at the cost of processor resources. The same processor may simultaneously be handling numerous other functions or transactions, some of them as important, if not more so, than updating the cache.
The challenge comes in finding the sweet spot, a kind of Goldilocks area that lies between checking for updates too frequently or not enough. Of course, if a user attempts to access obsolete data during this gap, that gamble is lost.
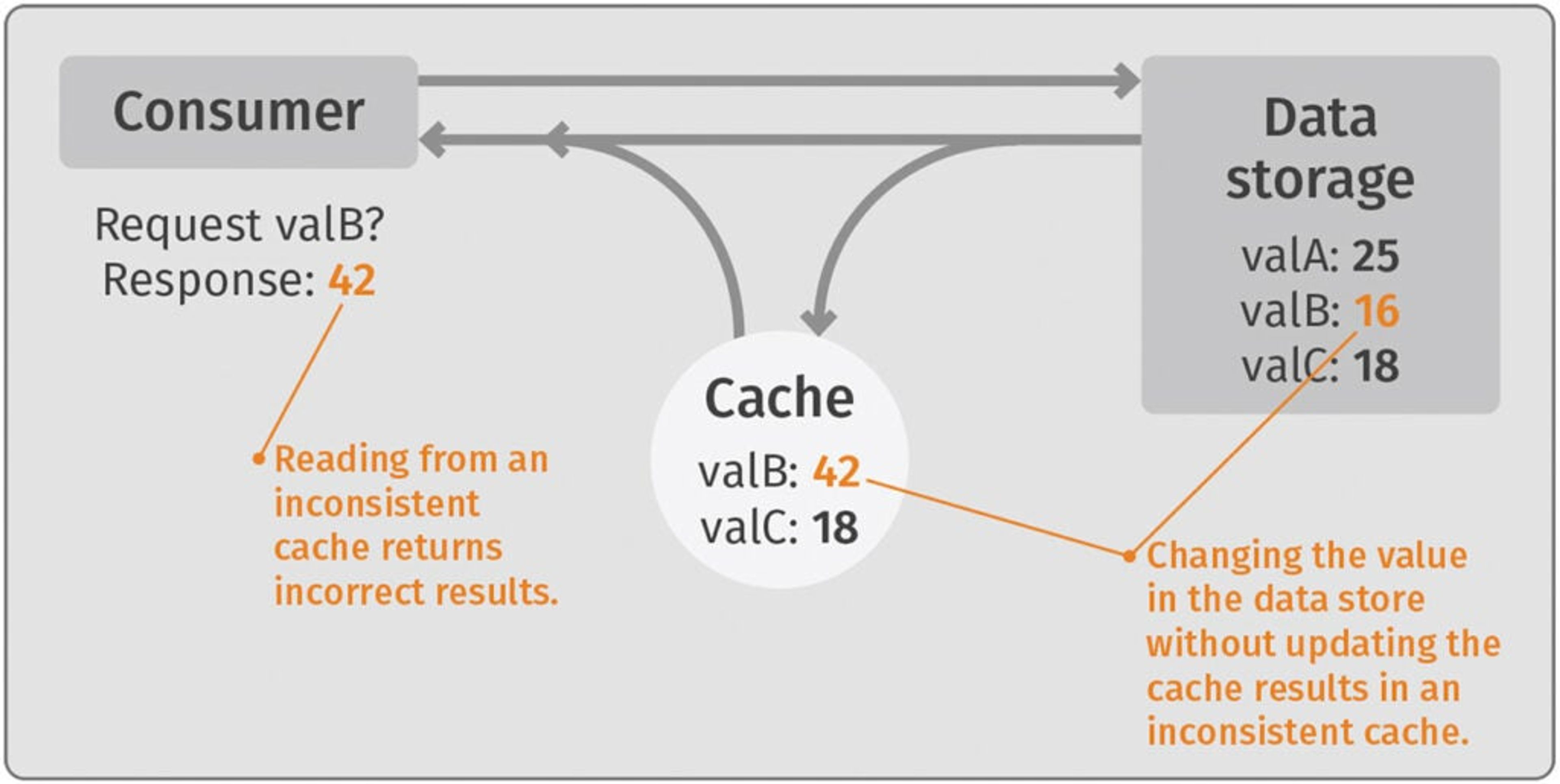
2. When there’s a delay in updating cached results
This problem overlaps a little with the previous problem. Each time a value is updated in the primary database, a message is sent to the cache, instructing it either to update the changed value or to remove it entirely. (In the latter case, the next time the value is requested, it will be accessed from the primary database and then from the cache thereafter.) Under normal circumstances, this communication happens relatively quickly and the cached item is either updated or removed in order to maintain cache consistency.
Once again, however, this change requires processing power, and it takes time. Delays can be affected both by available processing speed as well as by network throughput. Should a user have the misfortune of choosing to access obsolete data between the time the message has been sent by the server to update the cache and the time when that message is received by the cache and acted upon, the result can be data that is obsolete, incorrect or both.
3. When there’s inconsistency across cached nodes
Of course, the larger the website or the application, the more likely the cache is stored on multiple nodes instead of just one. In addition to a primary node, there may be any number of replica nodes that are, ideally, storing identical data. From the standpoint of load balancing and performance, this often makes sense.
But from the perspective of data integrity, it introduces yet another potential source of cache inconsistency. Each time the data is updated in the primary database, this change needs to be reflected in all of the replicas as well. Depending on where these nodes are located geographically, and how many there are, the updating process can take a significant amount of time. Although the updating process may be underway, it’s still quite possible that a user will access a node where the changes have yet to be made. Once again, the result, you guessed it, can be cache inconsistency.
The cost of cache inconsistency
For all the benefits of a cached database, the potential for cache inconsistency is perhaps its most conspicuous drawback. But how big is the problem? Ultimately, the cost of cache inconsistency depends on the context.
Some cache inconsistency can occur without much consequence. For example, if the total “likes” in your cache are temporarily out of sync with the actual total in your primary database, the brief discrepancy is unlikely to cause problems or even be noticed.
On the other hand, if the cache lists that one remaining item of a particular product is still in stock, while the actual inventory at the primary database says there are none left, the resulting conflict can confuse and alienate your customers, damage your brand’s reputation for reliability, wreak havoc on the company’s transactions and accounting, and, in extreme cases, even put you in legal jeopardy.
Three ways to counteract inconsistency
Luckily, for each of the potential sources of cache inconsistency above, there are a corresponding number of solutions.
1. Cache invalidation
With cache invalidation, whenever a value is updated in the primary database, each cached item with a corresponding key is automatically deleted from the cache or caches. Although cache invalidation could perhaps be seen as a “brute force approach,” the advantage is that it requires only one costly and often time-consuming write—to the primary database itself—instead of two or more.
2. Write-through caching
In this case, rather than updating the primary database and removing the cache, with the write-through strategy, the application updates the cache, and then the cache updates the primary database synchronously. In other words, instead of relying on the primary database to initiate any updating, the cache is in charge of maintaining its own consistency and delivering word of any changes it makes back to the primary database.
3. Write-behind caching
Unfortunately, there are times when two writes can actually make a wrong. One of the drawbacks of the write-through cache strategy is that updating both the cache and the primary database requires two time-consuming, processor-taxing changes, first to the cache and then to the primary database.
Another strategy, known as write-behind, avoids this problem by initially updating only the cache and then updating the primary database later. Of course, the primary database will also need to be updated, and the sooner the better, but in this case the user doesn’t have to pay the “cost” of the two writes. The second write to the primary database occurs asynchronously and behind the scenes (hence the name, write-behind) at a time when it is less likely to impair performance.
Redis Enterprise to the rescue
In addition to cache invalidation, write-through and write-behind caching can address many of the scenarios that help you achieve cache consistency. But finding the answer to a problem is not the same as implementing it.
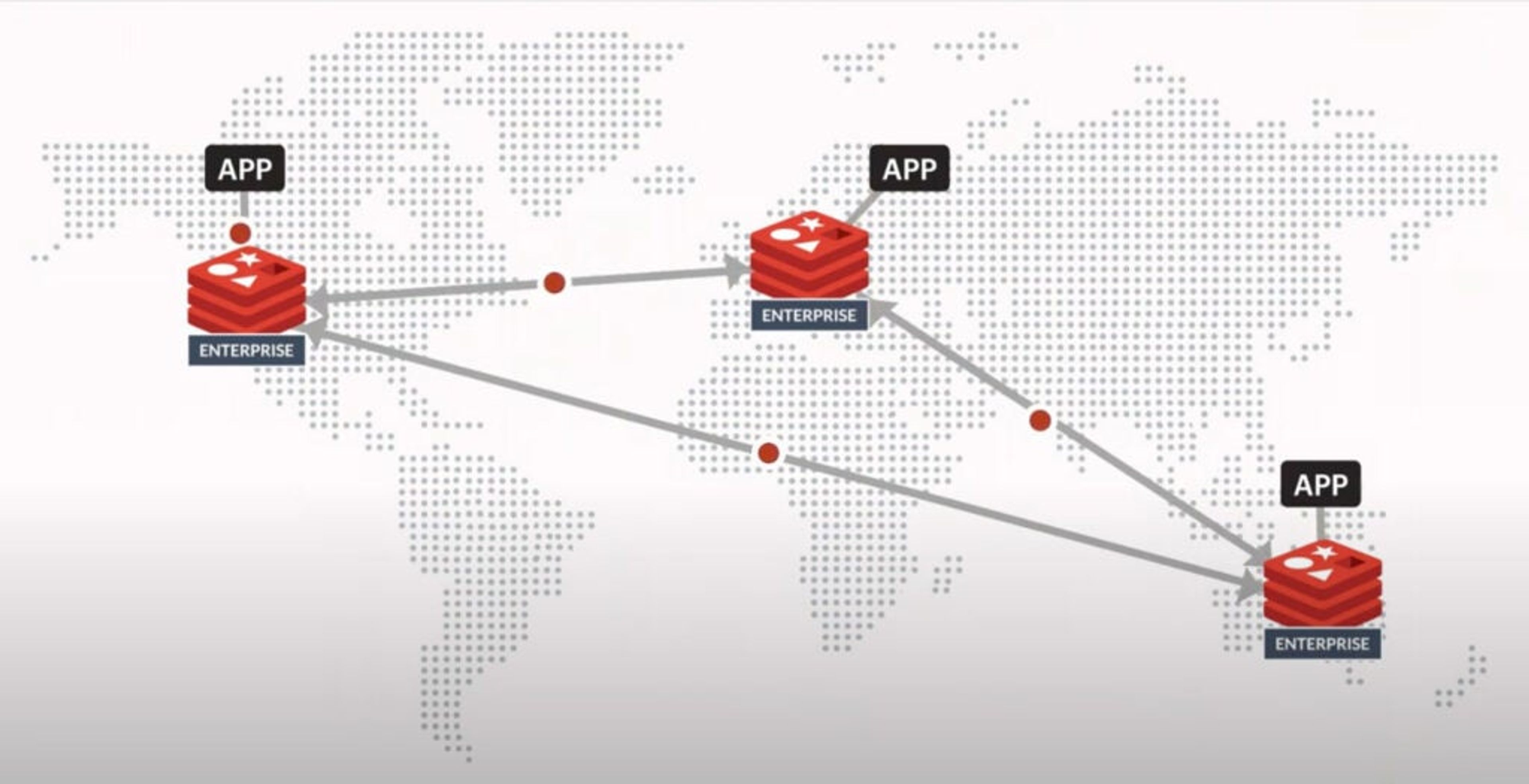
Redis Enterprise’s active-active geo-duplication allows for multiple primaries and enables you to deftly handle increasingly heavier loads. The name active-active refers to the fact that each instance of your database can accept both read and write operations on any key. Each database instance, no matter how far-flung, is a peer on your network. That means when a write occurs to any instance, that node automatically sends a message to all the other instances on your network, indicating what in the cache has been changed and ensuring all of the instances retain a consistent set of cached data.
Redis Enterprise’s unique active-active geo-duplication employs sophisticated algorithms designed to deal with potential write conflicts that can lead to cache inconsistency. These algorithms are based on conflict-free replicated data types (CRDTs), ensuring that writes from multiple replicas can be merged in a way that effectively maintains consistency.
Hooray for hobgoblins!
Because the challenge of maintaining cache consistency becomes more complex and increasingly more consequential as your architecture grows, you need an enterprise-level caching solution to reliably deliver the consistency that your business requires and that your customers expect.
Consistency may have been a hobgoblin as far as Emerson was concerned, but it’s absolutely essential when it comes to enterprise-level database caching. That’s why it’s wise to choose Redis Enterprise. You’d be foolish not to.
Get the whole story of caching. Read Caching at Scale with Redis, by Lee Atchison.
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.