Configure the query performance factor for Redis Search in Redis Software
Configure the query performance factor for Redis Search in Redis Software to increase the performance of queries.
Query performance factors are intended to increase the performance of queries, including vector search. When enabled, it allows you to increase a database's compute capacity and query throughput by allocating more virtual CPUs per shard. This is in addition to horizontal scaling with more shards which enables a higher throughput of key value operations. This document describes how to configure the query performance factor.
Prerequisites
Redis Search requires a cluster running Redis Software version 7.4.2-54 or later. For the simplified configuration experience (no shard restart required, new UI, and new REST API), Redis Software version 8.x or later is required.
If you do not have a cluster that supports Redis Search, install Redis Software version 7.4.2-54 or later on a new cluster, or upgrade an existing cluster.
Sizing
-
Calculate the hardware requirements for your Redis database:
-
Use the hardware requirements documentation to derive the overall cluster architecture.
-
Calculate the RAM requirements using the Index Size Calculator. The total RAM required is the sum of the dataset and index sizes.
-
-
Determine the query performance factor you want and the required number of CPUs. Unused CPUs, above the 20% necessary for Redis, can be used for the scalable Redis Search.
-
Create a new Redis database with the number of CPUs configured for the query performance factor.
Calculate query performance factor
CPUs for query performance factor
Vertical scaling of Redis Search is achieved by provisioning additional CPUs for the RediSearch module. At least 20% of the available CPUs must be reserved for Redis internal processing. Use the following formula to define the maximum number of CPUs that can be allocated to search.
| Variable | Value |
|---|---|
| CPUs per node | x |
| Redis internals | 20% |
| Available CPUs for Redis Search | floor(0.8 * x) |
Query performance factor versus CPUs
The following table shows the number of CPUs required for each performance factor. This calculation is sensitive to how the search index and queries are defined. Certain scenarios might yield less throughput than the ratios in the following table.
| Scale factor | Minimum CPUs required for Redis Search |
|---|---|
| None (default) | 1 |
| 2 | 3 |
| 4 | 6 |
| 6 | 9 |
| 8 | 12 |
| 10 | 15 |
| 12 | 18 |
| 14 | 21 |
| 16 | 24 |
Example performance factor calculation
| Variable | Value |
|---|---|
| CPUs per node | 8 |
| Available CPUs | floor(0.8 * 8)=6 |
| Scale factor | 4x |
| Minimum CPUs required for scale factor - WORKERS | 6 |
Configure query performance factor in the Cluster Manager UI
Redis Software 8.x and later
Starting with Redis Software 8.x, configuring the query performance factor is simplified. You can select the query performance factor directly from the Cluster Manager UI without manually setting connection routing, connection limits, or module parameters. Changes to the query performance factor for existing databases take effect immediately without restarting shards.
To configure the query performance factor:
-
In the Cluster Manager UI, create a new database or edit an existing database.
-
In the Capabilities section, click Add parameters.
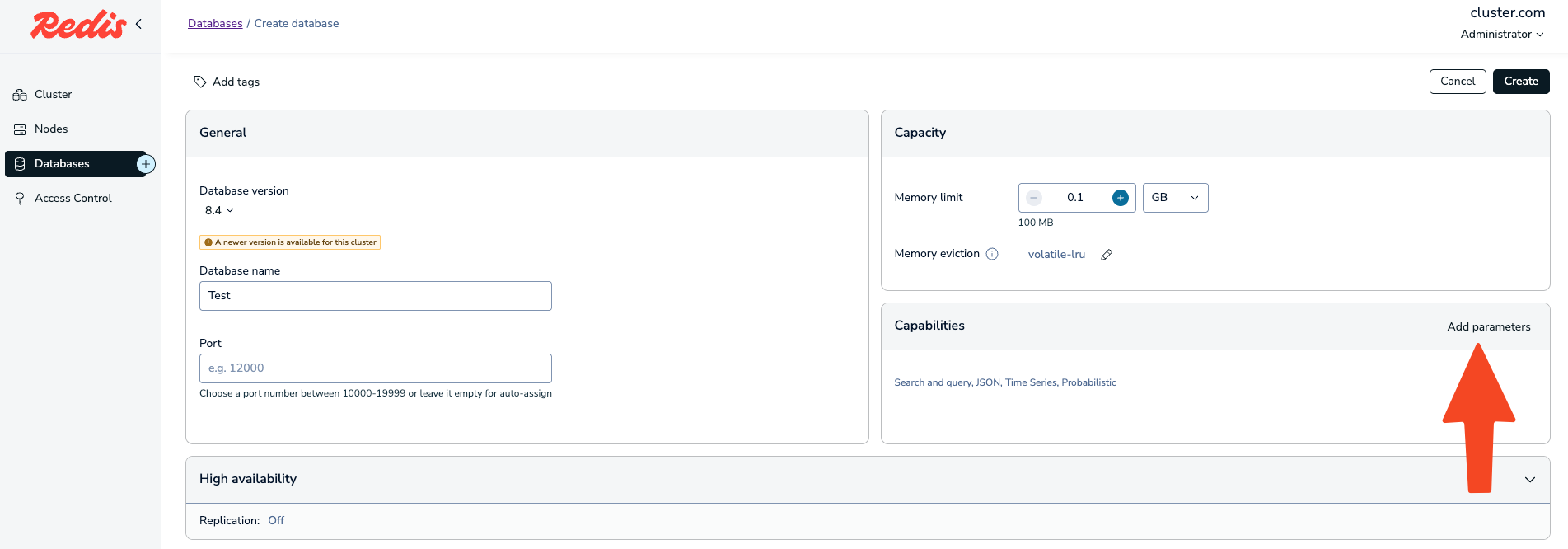
-
In the Parameters dialog, use the Query performance factor dropdown to select the performance factor value (Standard, 2x, 4x, 6x, 8x, 10x, 12x, 14x, or 16x).
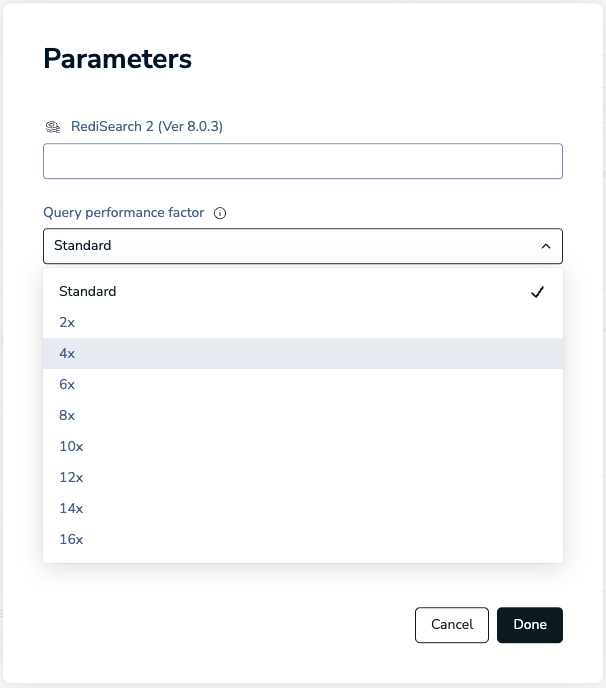
-
Click Done to close the parameter editor.
-
Click Create or Save.
The new configuration applies automatically. No shard restart is required, even for existing databases.
Prior to Redis Software 8
To manually configure the query performance factor in Redis Software versions prior to 8.x:
-
Configure query performance factor parameters when you create a new database or edit an existing database's configuration in the Cluster Manager UI.
-
If you configure the query performance factor for an existing database, you also need to restart shards. Newly created databases can skip this step.
Configure query performance factor parameters
You can use the Cluster Manager UI to configure the query performance factor when you create a new database or edit an existing database with search enabled.
-
In the Capabilities section of the database configuration screen, click Parameters.
-
If you are creating a new database, select Search and query.
-
Adjust the RediSearch parameters to include:
WORKERS <NUMBER_OF_THREADS>See Calculate query performance factor to determine the minimum CPUs required to use for
<NUMBER_OF_THREADS>. -
Expand the Query Performance Factor section and enter the following values:
-
mnpfor Connections routing -
32for Connections limit
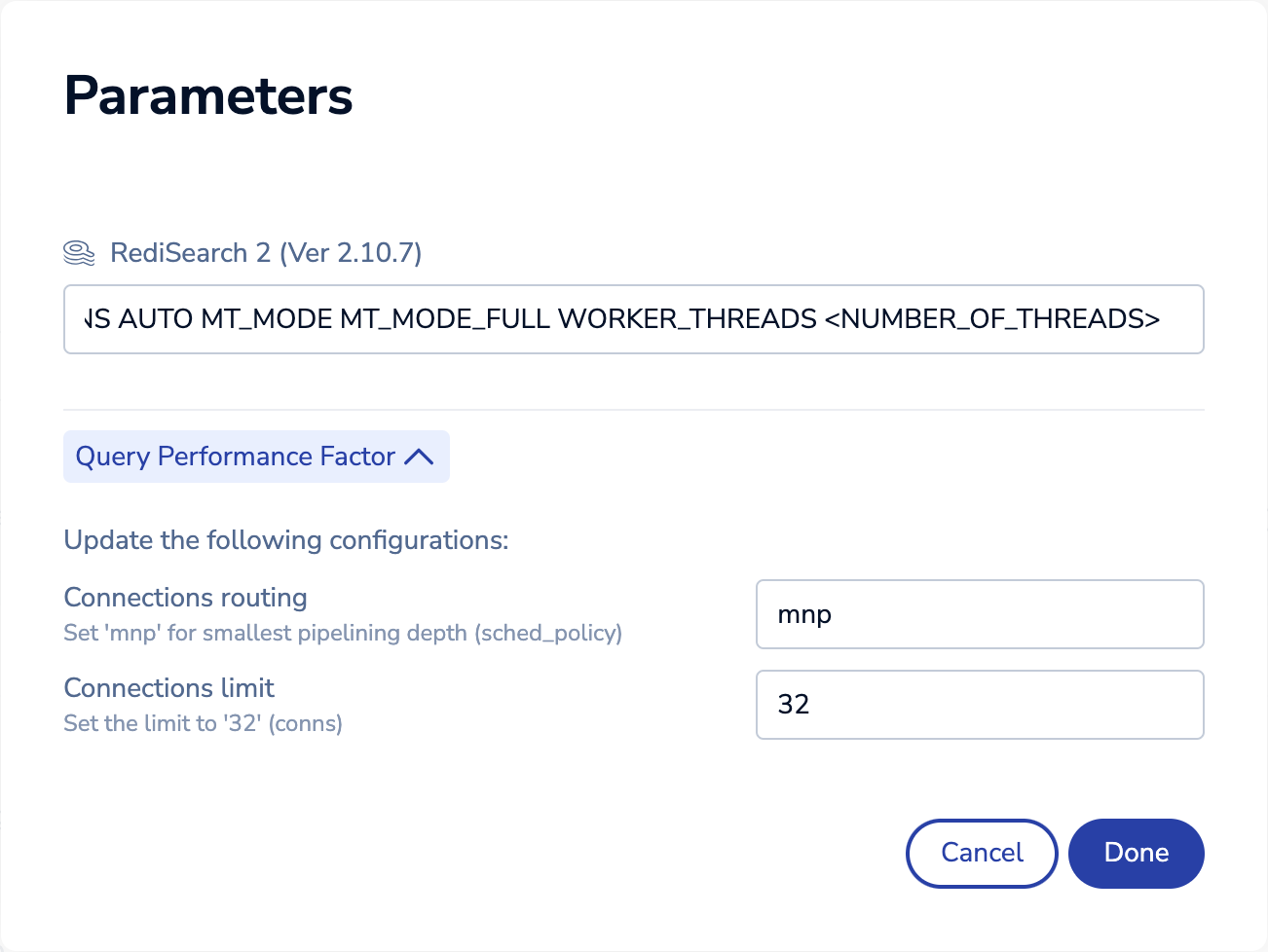
-
-
Click Done to close the parameter editor.
-
Click Create or Save.
Restart shards
After you update the query performance factor for an existing database, restart all shards to apply the new settings. You can migrate shards to restart them. Newly created databases can skip this step.
-
Use
rladmin status shards db <db-name>to list all shards for your database:rladmin status shards db db-nameExample output:
SHARDS: DB:ID NAME ID NODE ROLE SLOTS USED_MEMORY STATUS db:2 db-name redis:1 node:1 master 0-16383 1.95MB OK db:2 db-name redis:2 node:2 slave 0-16383 1.95MB OKNote the following fields for the next steps:
ID: the Redis shard's ID.NODE: the node on which the shard currently resides.ROLE:masteris a primary shard;slaveis a replica shard.
-
For each replica shard, use
rladmin migrate shardto move it to a different node and restart it:rladmin migrate shard <shard_id> target_node <node_id> -
After you migrate the replica shards, migrate the original primary shards.
-
Rerun
rladmin status shards db <db-name>to verify the shards migrated to different nodes:rladmin status shards db db-nameExample output:
SHARDS: DB:ID NAME ID NODE ROLE SLOTS USED_MEMORY STATUS db:2 db-name redis:1 node:2 master 0-16383 1.95MB OK db:2 db-name redis:2 node:1 slave 0-16383 1.95MB OK
Configure query performance factor with the REST API
Redis Software 8.x and later
Starting with Redis Software 8.x, you can configure the query performance factor using the query_performance_factor object in the BDB object. You no longer need to manually set sched_policy, conns, or module WORKERS parameters. Changes take effect immediately without restarting shards.
Create a new database
To create a database with the query performance factor enabled, use the create database REST API endpoint with the query_performance_factor field:
{
"name": "scalable-search-db",
"type": "redis",
"memory_size": 10000000,
"port": 13000,
"authentication_redis_pass": "<your default db pwd>",
"proxy_policy": "all-master-shards",
"sharding": true,
"shards_count": 3,
"shards_placement": "sparse",
"shard_key_regex": [{"regex": ".*\\{(?<tag>.*)\\}.*"}, {"regex": "(?<tag>.*)"}],
"replication": false,
"module_list": [{
"module_name": "search",
"module_args": ""
}],
"query_performance_factor": {
"active": true,
"scaling_factor": 4
}
}
The following cURL request creates a new database from the JSON example:
curl -k -u "<user>:<password>" https://<host>:9443/v1/bdbs -H "Content-Type:application/json" -d @scalable-search-db.json
Update an existing database
To configure the query performance factor for an existing database, use the update database configuration endpoint with the query_performance_factor field:
curl -k -u "<user>:<password>" -X PUT https://<host>:9443/v1/bdbs/<DB_ID> -H "Content-Type:application/json" -d '{
"query_performance_factor": {
"active": true,
"scaling_factor": 4
}
}'
No shard restart is required. The new configuration applies automatically.
Query performance factor object fields
| Field | Type/Value | Description |
|---|---|---|
| active | boolean (default: false) | If true, enables query performance factor for the database |
| scaling_factor | integer (range: 0-16) (default: 0) | Scales the magnitude of the query performance factor |
See the query_performance_factor object reference for more details.
Prior to Redis Software 8
You can configure the query performance factor when you create a new database or update an existing database using the Redis Software REST API.
Create new database with the REST API
To create a database and configure the query performance factor, use the create database REST API endpoint with a BDB object that includes the following parameters:
{
"sched_policy": "mnp",
"conns": 32,
"module_list": [{
"module_name": "search",
"module_args": "WORKERS <NUMBER_OF_THREADS>"
}]
}
See Calculate performance factor to determine the value to use for <NUMBER_OF_CPUS>.
Example REST API request for a new database
The following JSON is an example request body used to create a new database with a 4x query performance factor configured:
{
"name": "scalable-search-db",
"type": "redis",
"memory_size": 10000000,
"port": 13000,
"authentication_redis_pass": "<your default db pwd>",
"proxy_policy": "all-master-shards",
"sched_policy": "mnp",
"conns": 32,
"sharding": true,
"shards_count": 3,
"shards_placement": "sparse",
"shard_key_regex": [{"regex": ".*\\{(?<tag>.*)\\}.*"}, {"regex": "(?<tag>.*)"}],
"replication": false,
"module_list": [{
"module_name": "search",
"module_args": "WORKERS 6"
}]
}
The following cURL request creates a new database from the JSON example:
curl -k -u "<user>:<password>" https://<host>:9443/v1/bdbs -H "Content-Type:application/json" -d @scalable-search-db.json
Update existing database with the REST API
To configure the query performance factor for an existing database, use the following REST API requests:
-
Update database configuration to modify the DMC proxy.
-
Upgrade module to set the search module’s query performance factor.
- Because this procedure also restarts the database shards, you should perform it during a maintenance period.
- This procedure overwrites any existing module configuration parameters.
The following example script uses both endpoints to configure a 4x query performance factor:
#!/bin/bash
export DB_ID=1
export CPU=6
export MODULE_ID=`curl -s -k -u "<user>:<password>" https://<host>:9443/v1/bdbs/$DB_ID | jq '.module_list[] | select(.module_name=="search").module_id' | tr -d '"'`
curl -o /dev/null -s -k -u "<user>:<password>" -X PUT https://<host>:9443/v1/bdbs/$DB_ID -H "Content-Type:application/json" -d '{
"sched_policy": "mnp",
"conns": 32
}'
sleep 1
curl -o /dev/null -s -k -u "<user>:<password>" https://<host>:9443/v1/bdbs/$DB_ID/modules/upgrade -H "Content-Type:application/json" -d '{
"modules": [
{
"module_name": "search",
"new_module_args": "WORKERS '$CPU'",
"current_module": "'$MODULE_ID'",
"new_module": "'$MODULE_ID'"
}
]
}'
Monitoring Redis Search
To monitor a database with a query performance factor configured:
-
Integrate your Redis Software deployment with Prometheus. See Prometheus and Grafana with Redis Software for instructions.
-
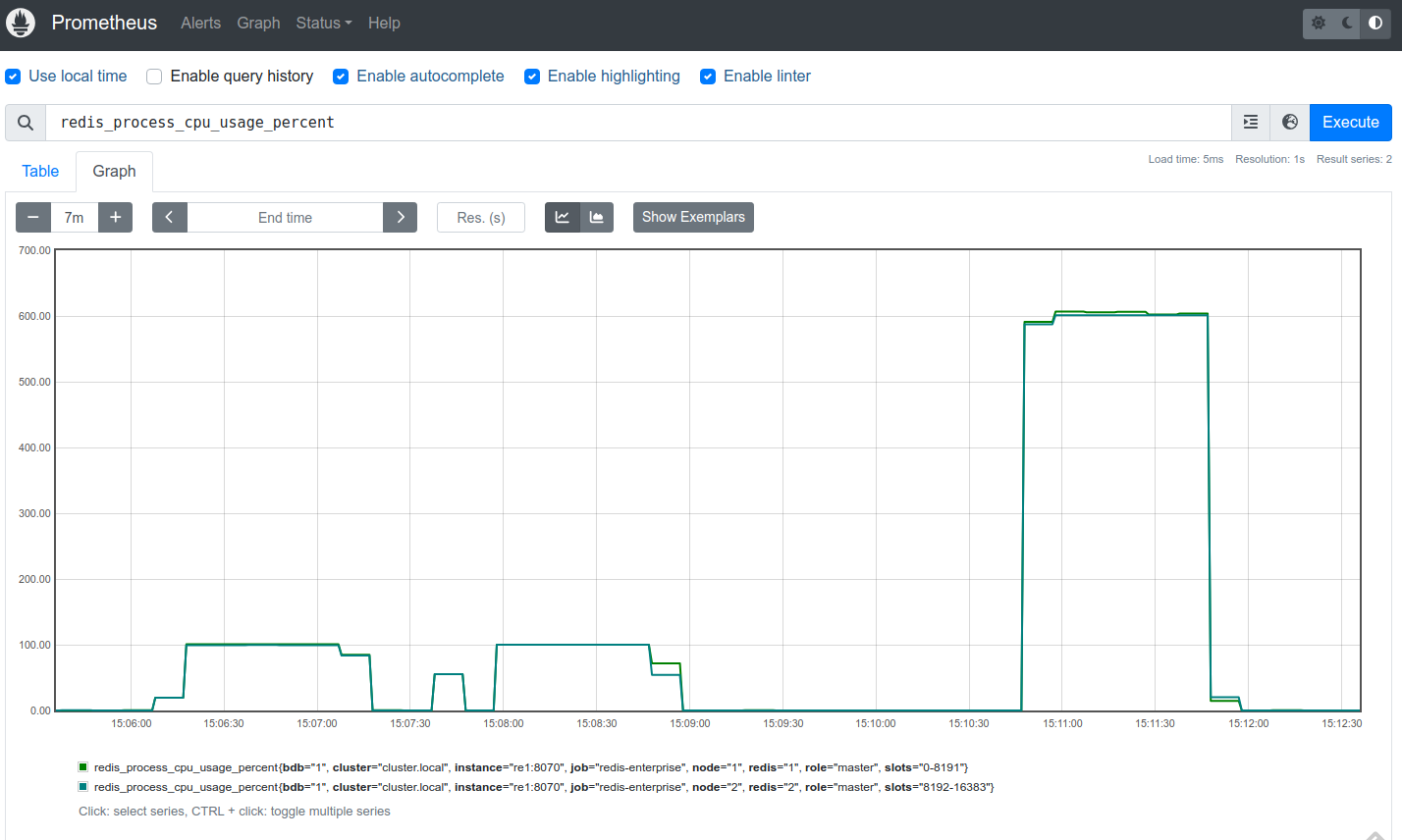
Monitor the
redis_process_cpu_usage_percentshard metric.The following Prometheus UI screenshot shows
redis_process_cpu_usage_percentspikes for a database with two shards:-
1st 100% spike:
memtier_benchmarksearch test at the default (no additional CPUs for search). -
2nd 100% spike: reconfiguration and shard restart for a 4x query performance factor.
-
3rd 600% spike:
memtier_benchmarksearch test with threading at a 4x query performance factor (6 CPUs per shard).
-