A NoSQL database for high-availability
Architected to provide automated database resilience and mitigate hardware failure and cloud outages risks
Redis Enterprise is a self-managed, real-time data platform that unlocks the full potential of Redis at scale, ensuring five-nines (5-9s) high availability.
Redis Enterprise’s high availability is built around replication, but automatic failover, backup, and recovery also impact the ability to meet the application’s high availability service level agreements.
Replication is the process of storing identical copies of your data on multiple Redis Enterprise servers. Redis Enterprise replication keeps your data safe and allows your application to run uninterrupted, without downtime, keeping it highly available, even if something happens to one or more of your servers.
Cost-effective replication
Like most NoSQL database deployments, open source Redis uses three replicas to ensure high availability. From a high-level perspective, the first replica is usually used to store your dataset, the second for failover purposes, and the third serves as a tiebreaker in case of a network split event. Because DRAM is expensive, maintaining three replicas can be extremely expensive. Redis Enterprise allows you to have a complete high availability (HA) system with only two replicas. Your tiebreaker is determined at the node level by using an uneven number of nodes in a cluster. The example below compares the infrastructure cost of running a 90GB high availability architecture with an open source Redis dataset on Amazon Web Services with three replicas as opposed to with a Redis Enterprise cluster that uses two replicas and a quorum node:
The cost of 90GB dataset HA configuration on AWS (reserved instances)

Pure in-memory replication
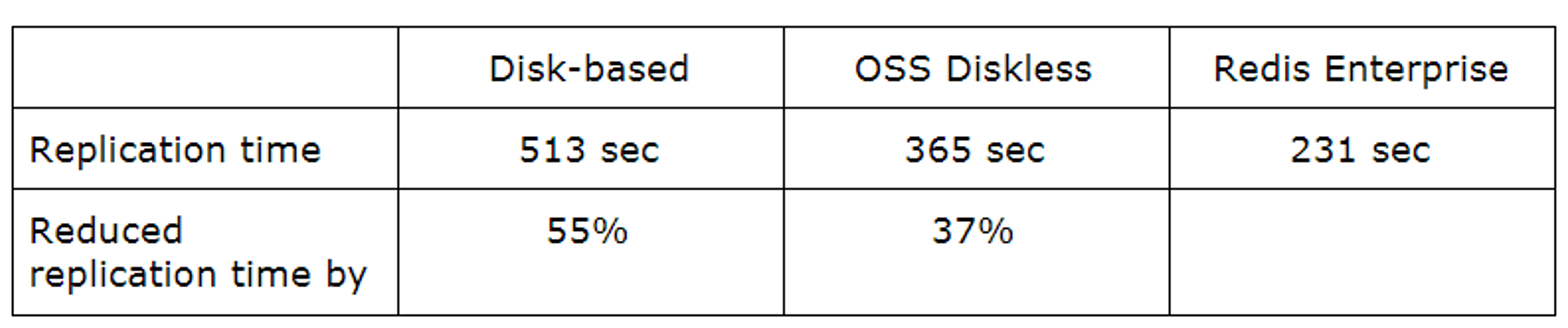
Redis Enterprise replication is based on diskless replication (pure in-memory replication) at both the primary server and replica, providing complete redundancy, as shown in the figure below:
An internal replication benchmark with 52GB DRAM (19GB RDB) showed the following results on 2x r3.2xlarge instances:

In addition, Redis Enterprise uses PSYNC2 for its core operations, so the active replication link is maintained afterwards for planned failover or shard migration operations.
Automatic failover
A Redis Enterprise cluster provides fault tolerance and resilience. In the case of a primary server or node outage, Redis Enterprise’s self-healing process automatically detects the hardware failure, elects a replica as a replacement, and promotes that replica to become the new primary server. Redis Enterprise also automatically switches all client connections. The entire failover process occurs in single-digit seconds, without manual intervention. A Redis Enterprise cluster uses two watchdog processes to detect failures:
- Node watchdog: Monitors all processes running on a given node. For example, the node watchdog triggers a shard failover event if a specific shard is not responsive.
- Cluster watchdog: Responsible for the health of the cluster nodes and uses a gossip protocol to manage the membership of the nodes in the cluster. For example, cluster watchdog triggers a node failure event or detects a network split incident.
These watchdog processes are part of the distributed cluster manager entity and reside on each node of the cluster. Failure detection needs to be managed by entities that run inside the cluster to avoid situations like that shown on the left side of the figure below. In this example, the watchdog entity is located in the wrong side of the network split and cannot trigger the failover process:

Once a failure event is detected, the Redis Enterprise cluster automatically and transparently runs a set of internal distributed processes that failover the relevant shard(s) and endpoint(s) (if needed) to healthy cluster nodes. They also reroute user traffic through a different proxy or proxies if necessary.
The Redis Enterprise cluster has out-of-the-box HA profiles for noisy (public cloud) and quiet (virtual private cloud, on-premises) environments. We have found that triggering failovers too aggressively can create stability issues. On the other hand, in a quiet network environment, a Redis Enterprise cluster can be easily tuned to support a constant single-digit (<10 sec) failover time in all failure scenarios.
Multi availability zone/rack deployment
With Redis Enterprise, you can choose from about 90 regions across AWS, Google Cloud, and Microsoft Azure. This ensures your applications are close to your user to provide a sub-millisecond response time.
Redis Enterprise is also designed to provide escalating geographic resilience in multi-zone, multi-region, and multi-cloud Redis Enterprise clusters. Redis Enterprise supports multi-availability zone/rack cluster configurations. In this mode, the cluster nodes are tagged with the zone/rack they have been deployed in, and Redis Enterprise ensures that primary server and replica Redis processes of the same shard are never hosted on nodes located in the same availability zone/rack. Running Redis Enterprise in a multi-availability zone/rack environment requires the following conditions:
- Three or more cluster nodes, with the total number being uneven
- Three or more availability zones/racks, with the total number being uneven
- The number of nodes in a given availability zone/rack should always be a minority, i.e. smaller than the number of nodes in all other availability zone/racks. This ensures that the majority of the nodes in the cluster will remain up and running if there is an availability zone/rack failure.
- Network latency between the availability zone/rack should be <10ms, guaranteeing that cluster failure detection mechanisms will operate correctly. In most cases, decisions are made when real failure events happen and are less influenced by network glitches. For cases with more than 10ms latency between availability zone/racks, Active-Passive or Active-Active deployments should be considered.
An example of Redis Enterprise multi-availability zone configuration in the cloud is shown here:
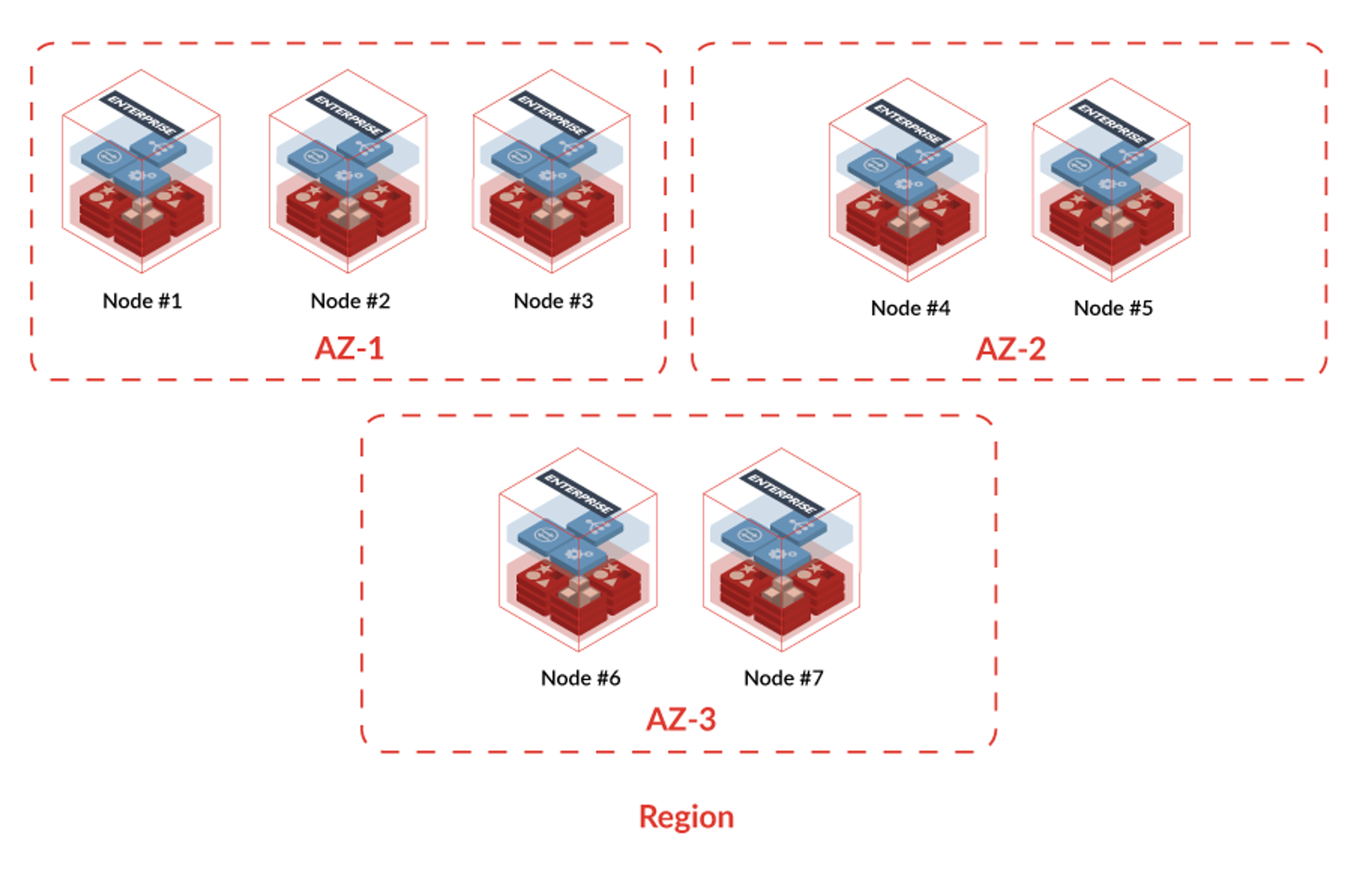
As you can see, this example meets all the conditions discussed above:
- There is an uneven number of nodes (7).
- There is an uneven number of availability-zones (3).
- The number of nodes in each zone is a minority.
- In all the major public clouds, network latency between zones in the same region is always less than 10ms.
Redis Enterprise geo-resilience with multi-cloud clusters
Cloud provider disruptions vary in severity, from temporary capacity constraints to complete outages that can devastate application deployments. By distributing data across multiple clouds, organizations can improve database and application resilience and prevent data loss. Redis Enterprise multi-cloud clusters allow your Redis Enterprise cluster distribution across multiple regions on different public cloud providers. With multi-cloud clusters, you can take advantage of unique tools and services native to AWS, Google Cloud, and Azure without the operational complexity of managing data replication and migration across clouds. You can expand your reach with low-latency access to more cloud regions and satisfy in-region data sovereignty requirements without sacrificing resilience. Redis Enterprise automatically distributes your data across clouds for increased fault tolerance to ensure highly available applications.
In addition to database resilience, you may also want a plan for maximizing application resilience and fault tolerance in multi-cloud environments. Applications should be distributed across multiple clouds to failover when necessary to meet high availability system requirements.
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.