Blog
Announcing faster Redis Query Engine, and our vector database leads benchmarks



Redis has always been built for speed. Our mission is to provide the fastest data and AI infrastructure available for enterprises at scale. Our latest enhancement to our Redis Query Engine accelerates current query, search, and vector workloads, unlocking more throughput at high speed. You can build faster apps, and scale with better performance for your end users.
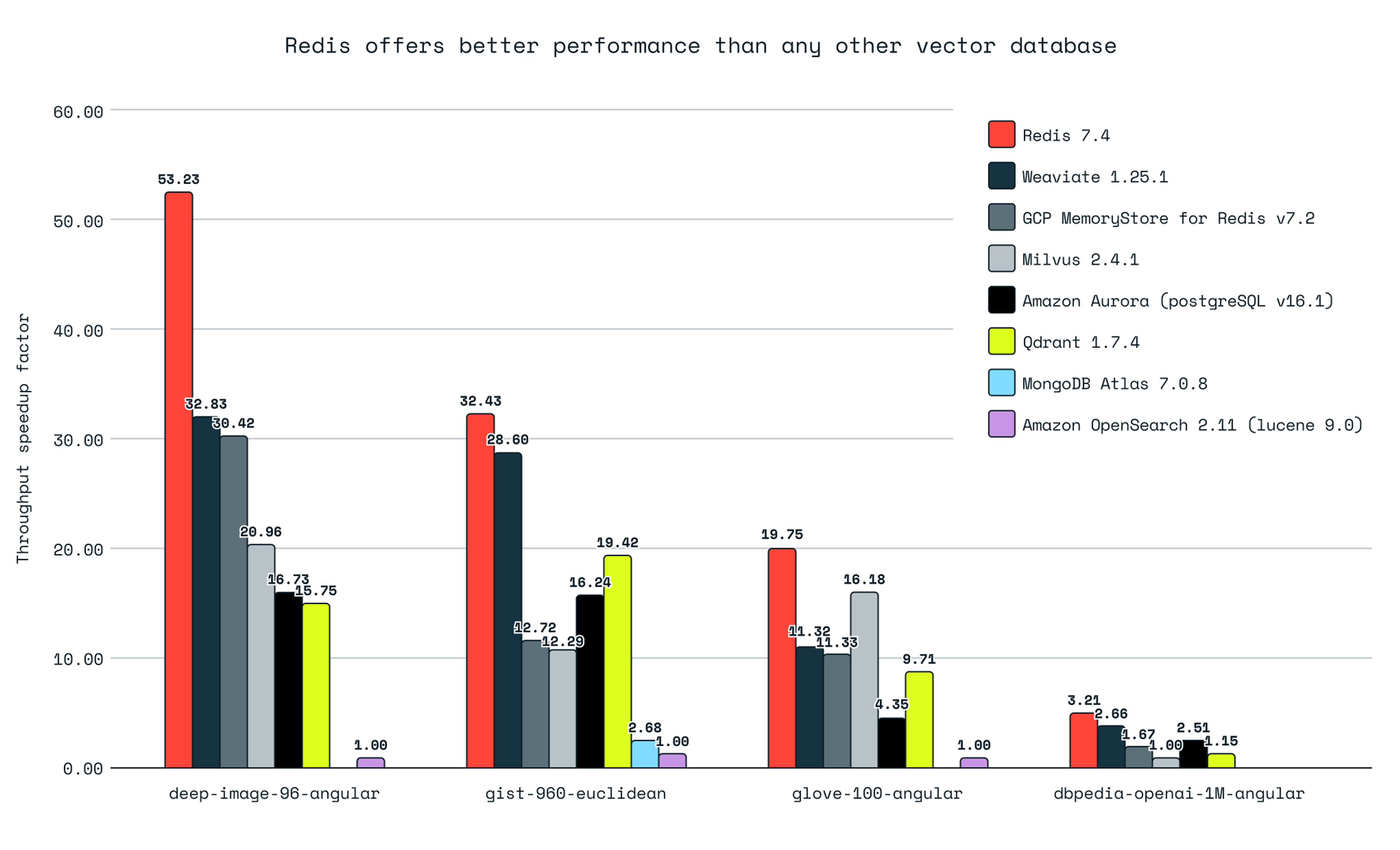
Today, we’re announcing the general availability of the faster Redis Query Engine on Redis Software. The new Redis Query Engine boosts current Redis query throughput 16X and this makes Redis faster than any other vector database we benchmarked against.
Redis offers better performance than any other vendor.
We tested the other top seven vector databases and Redis outperformed them across a wide variety of scenarios. We used industry-standard benchmarks where we used identical hardware and tested four data sets which simulate diverse use cases. Read our engineering blog to learn more about how we did it.
Our customers are building innovative apps that require more throughput while keeping the latency low. With GenAI, customers are deploying chatbots that need real-time RAG and must process multiple steps and retrieve data from vector databases, instantly. Meanwhile, Large Language Models (LLMs) continue to get faster, increasing the need for other components to be fast too. OpenAI released GPT-4o and Google introduced Gemini 1.5 Flash, to address apps’ needs for real-time performance. Apps require responses within a window of milliseconds at scale and under load, so we needed to boost throughput to support customers’ changing needs.
Redis Query Engine uses multi-threading to improve query throughput.
Redis has achieved its high performance from a few key design choices. One principle is that Redis has historically been single-threaded. Redis’ architecture uses a shared-nothing model, which avoids the bottlenecks and locking issues associated with multithreaded access to memory. Another design principle is that each operation needs to have a low time complexity. So even with a single thread, Redis delivers a very high throughput.
As customers increasingly leverage Redis for their real-time data platforms, there’s a growing demand to utilize its unique advanced query capabilities. Delivering more relevant data to fast apps requires more sophisticated and intricate queries. As the volume of data increases to hundreds of millions of documents, execution time for some queries correspondingly increases. This results in more time spent executing complex queries, reducing the availability of the main thread, and limiting throughput. While horizontal scaling can increase throughput for Redis operations, it is not the case for Redis queries. We must scale vertically.
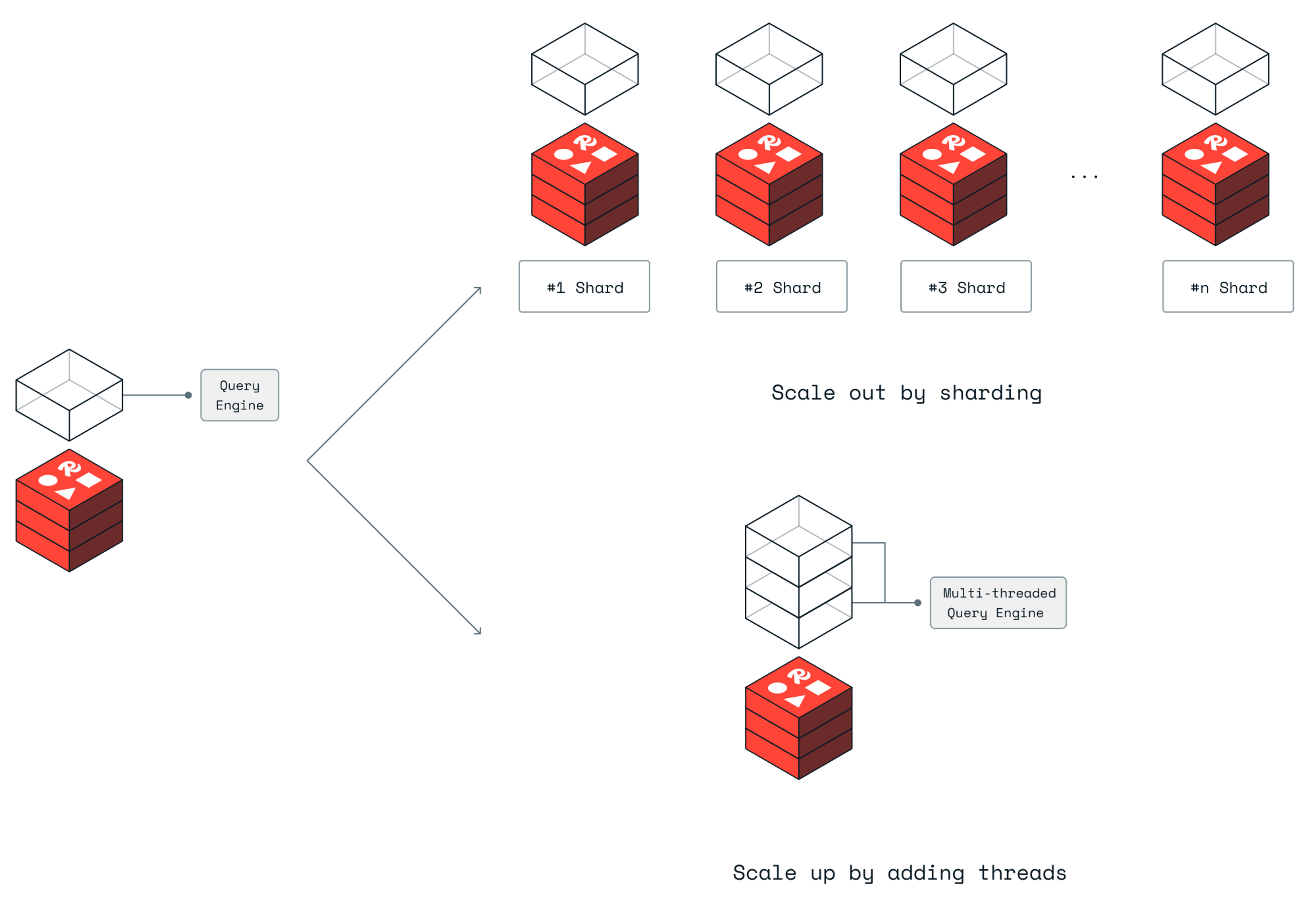
By enabling queries to access the index concurrently, effectively allowing Redis to scale vertically, we enable scaling both the throughput of Redis operations and queries. The new Redis Query Engine unlocks the next level of performance for larger datasets with higher throughput needs. In regards to speed, our latency maintains submillisecond responses like developers expect from Redis operations, and queries average latency below two-digit milliseconds.
We compared Redis with three segments of vector database providers.
Our three segments included pure vector database providers, general-purpose databases with vector capabilities, and Redis imitators. We found that the speed, extensibility, and enterprise features varied significantly across the three groups. The pure vector databases were better at performance, but worse at scaling. The general-purpose databases were much worse at performance, but better at other integrations. And Redis imitators were significantly slower without the latest improvements in speed. Many users assume that Redis imitators are equally fast, but we want to break that illusion for you, to save you time and money, by comparing them to Redis.
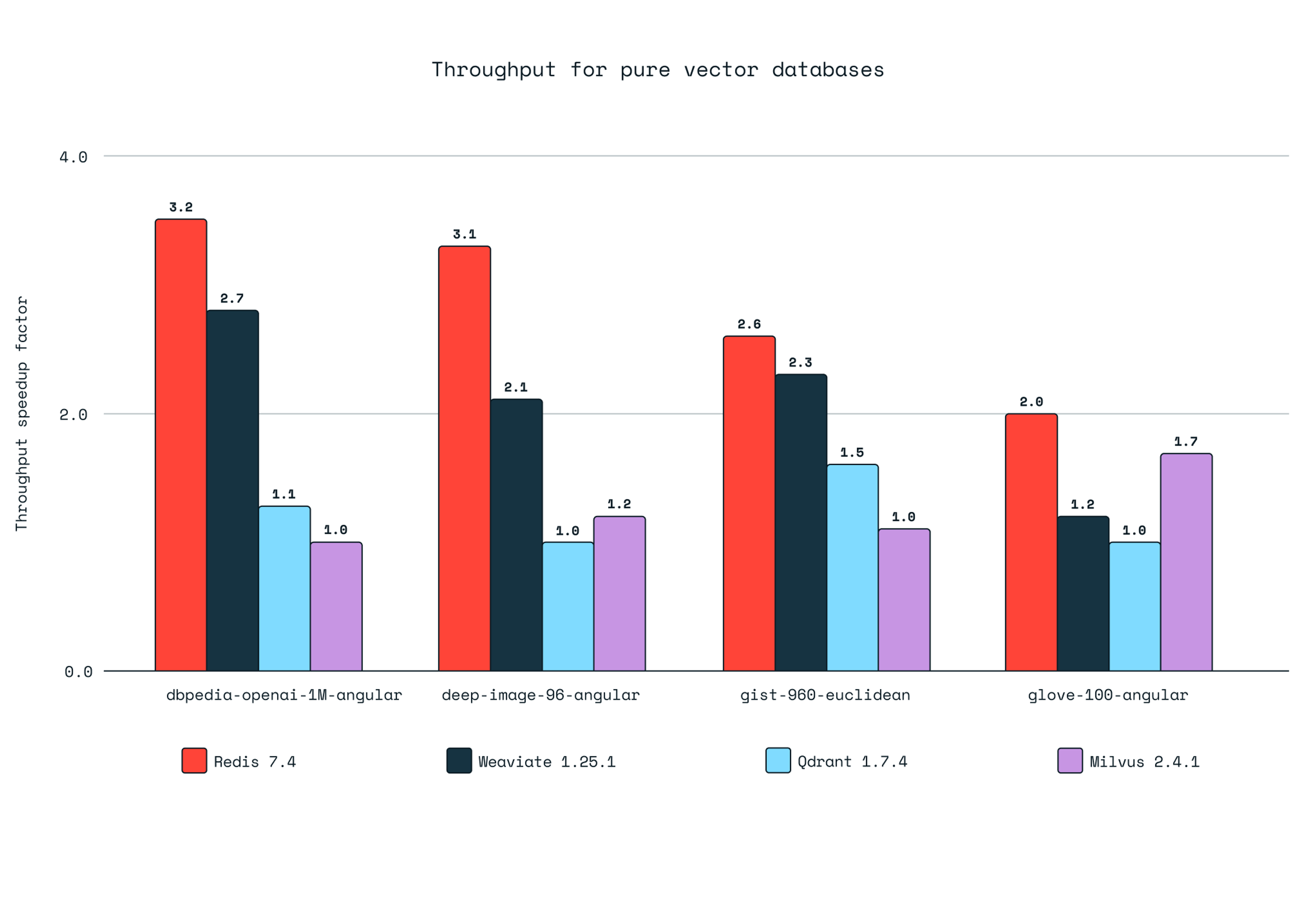
Redis is faster than pure vector databases and also scales better.
One of the challenges we hear from customers is that they need a solution that’s built for scale and provides enterprise-grade services. We experienced this ourselves when we benchmarked other pure vector databases since we had difficulties keeping availability of the service under high load. This led us to move from their cloud service to an on-premises deployment to run the benchmarks. While these vector databases came the closest in performance, in our testing, they had a few issues getting set up and running within their cloud service. We documented it in our detailed benchmark report.
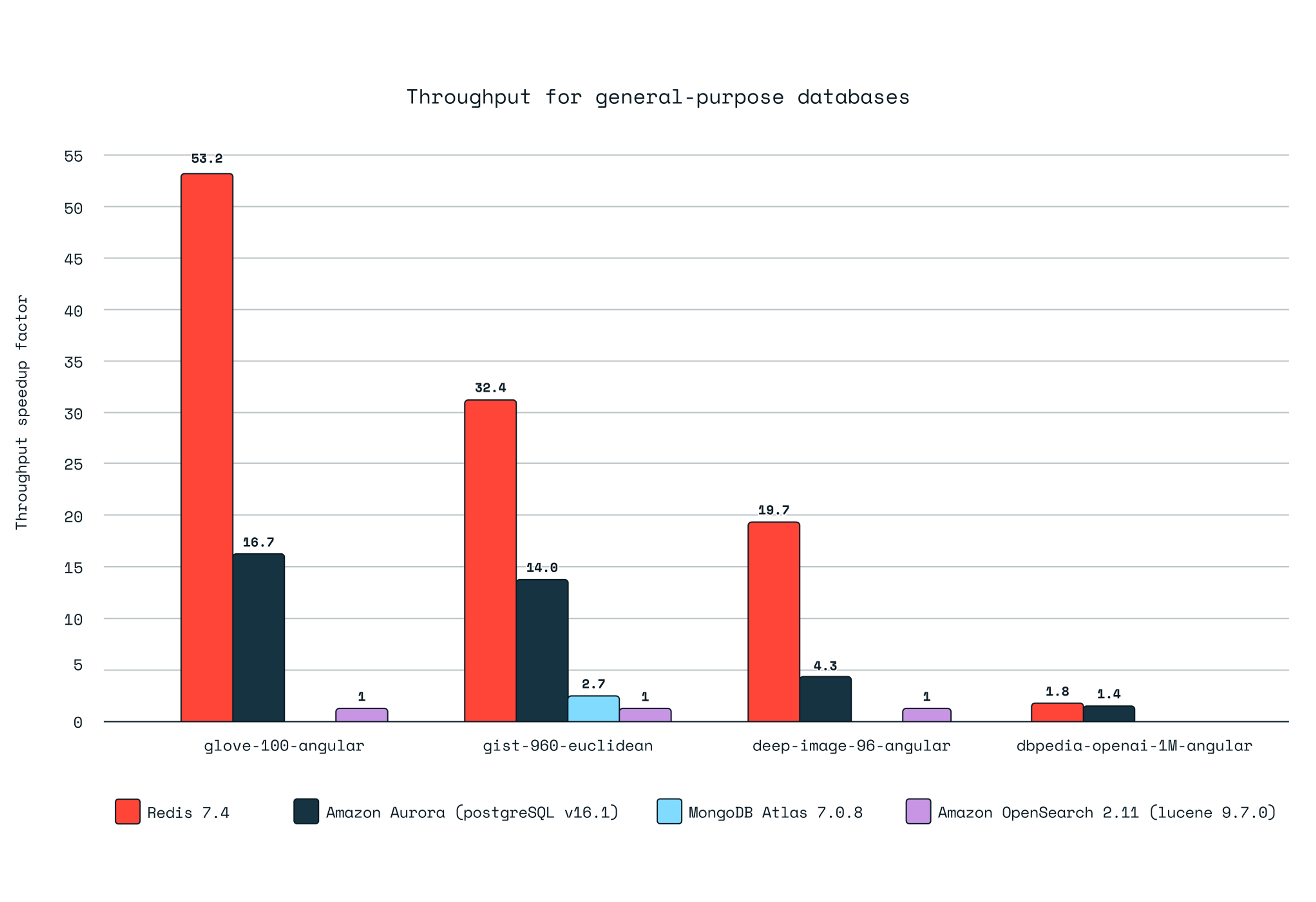
Redis is MUCH faster than general-purpose databases that added vector support.
There’s been a surge of vector database options in the last two years as RAG has become a top framework for enhancing GenAI apps. Many of these databases with new support for vectors are already widely adopted, so also using them for vectors can be easy. What we found is that Redis does here what Redis does best. We’re fast. Redis is widely used because we speed up data access from traditional databases. We find that customers also prefer Redis because we speed up GenAI apps the same way.
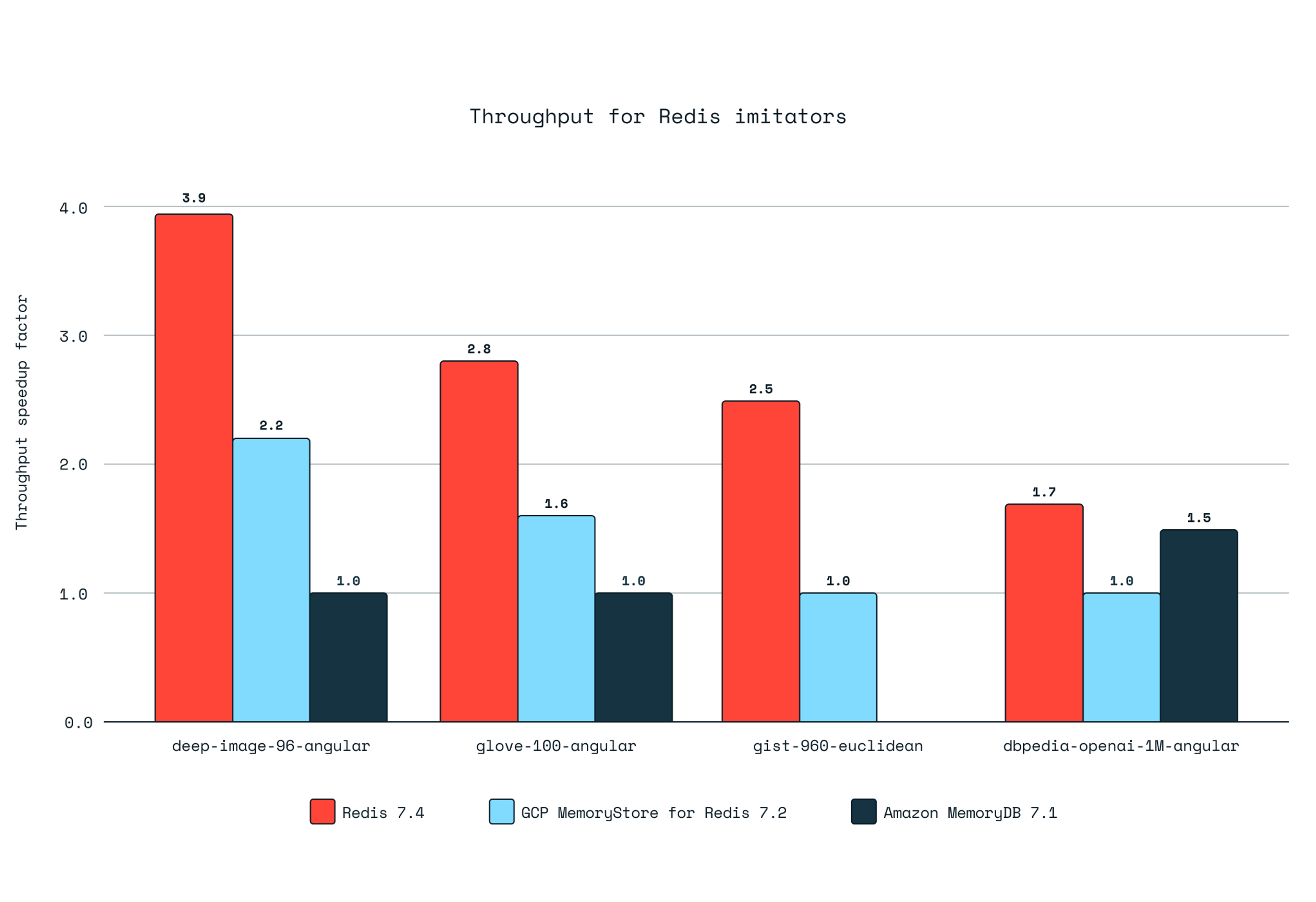
Redis imitators can’t keep up.
Compared to other Redis imitators, such as Amazon MemoryDB and Google Cloud MemoryStore for Redis, Redis demonstrates significantly higher throughput. Redis has 3.9 times more throughput for lower-dimensional datasets compared with Amazon MemoryDB and has 77% more throughput than Google Cloud MemoryStore for Redis. Don’t settle for an imitator.
See it for yourself.
Try out the higher throughput with the new Redis Query Engine. It’s now generally available in Redis Software and will be coming to Redis Cloud this fall. To learn more, check out our engineering blog. To get faster query speeds for your app today, download Redis Software and contact your rep for enterprise support.
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.