Blog
RediSearch 2.0 Lets You Build Modern Apps with Interactive Search Experiences

Today we are excited to announce the general availability of RediSearch 2.0, bringing its powerful querying, indexing, and full-text search engine to all Redis users. In public preview since September 2020, RediSearch 2.0 has already garnered a growing list of customers who rely on it for a myriad of use cases from creating modern applications to full-text search to real-time analytics. RediSearch 2.0 introduces a brand new architecture that makes it more than twice as fast as RediSearch 1.6, and RediSearch now supports Redis’ Active-Active geo-distribution and Redis on Flash.
Why RediSearch matters
Modern organizations are capturing large amounts of structured and unstructured data. Too often, however, this data is locked in slow, disk-based databases that don’t support real-time experiences for modern applications. RediSearch eliminates these performance bottlenecks by allowing users to easily index their Redis datasets and then query and aggregate the data in a fully distributed manner in real-time, at the speed of Redis.
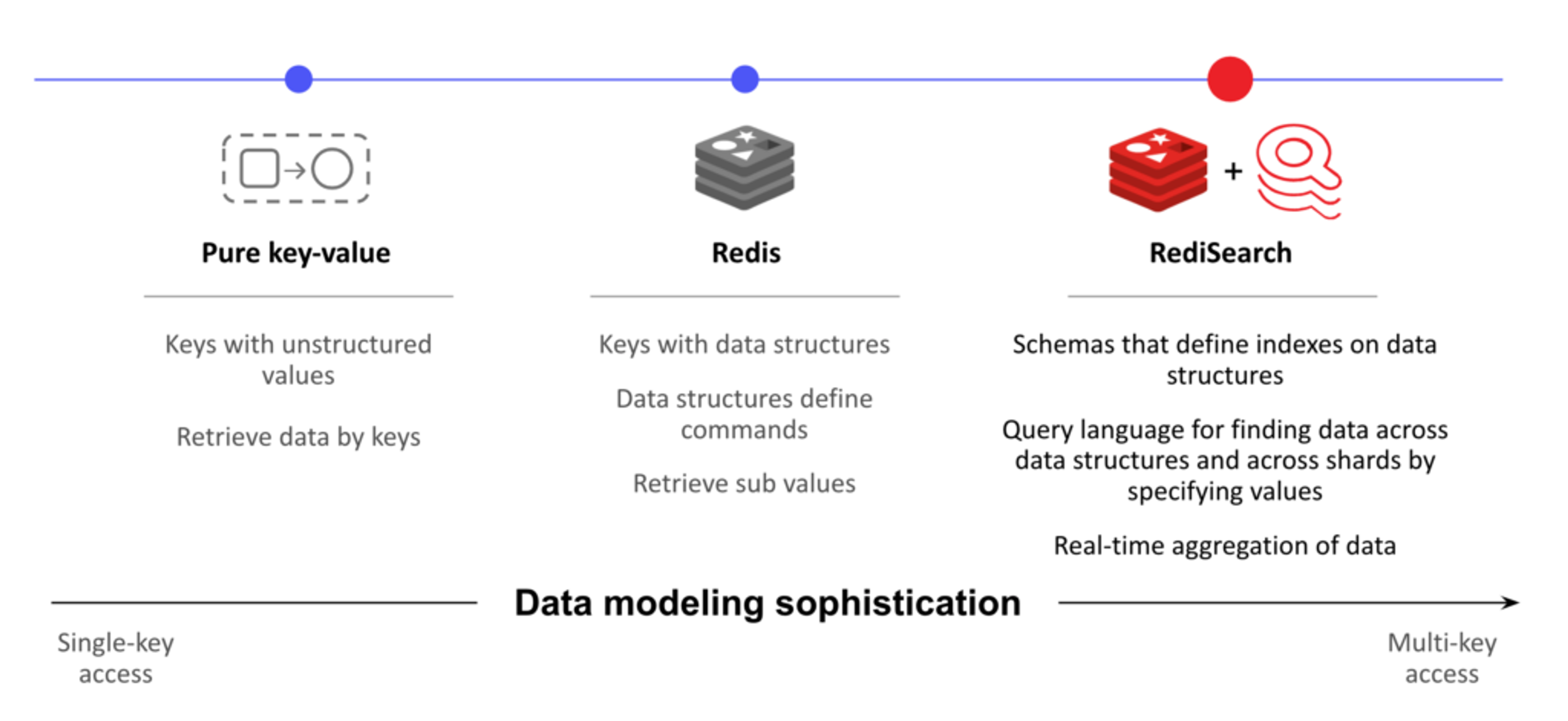
As shown in the diagram above, RediSearch brings more sophisticated data modeling to Redis by providing several indexing strategies for the value part of the key, including full-text, geo-location, numbers, and tags. Without indexes, Redis must perform a SCAN operation for every query, which can be extremely slow and inefficient. And creating and maintaining these indexes manually is complex and error-prone. RediSearch maintains these indexes for the user and allows you to query across data structures in a clustered database.
The addition of RediSearch to your technology stack simplifies the data infrastructure, extends applications with rich search experiences, and unlocks the power of analytics in Redis. Developers no longer need to flip back and forth between multiple technologies, query languages, data models, and bolt-on search engines to create modern applications.
Using RediSearch
Written in C, RediSearch is built with performance in mind using in-memory data structures such as Trie and leveraging modern distributed indexing and query algorithms. This makes it 5x – 10x faster than existing search engines (for more on RediSearch’s speed, see Search Benchmarking: RediSearch vs. Elasticsearch). RediSearch’s low-latency indexing and data querying makes it suitable for frequently updated datasets. And the new RediSearch 2.0 is 2.4x faster than the previous version.
RediSearch allows you to quickly create indexes on datasets in multiple data types in Redis. (Hashes are currently supported and we plan to release support for JSON soon, followed by Streams.) RediSearch uses an incremental indexing approach for lightweight index creation and deletion. Its rich query language lets you query your data at lightning speed, perform complex aggregations, and filter by properties, numeric ranges, and geographical distance.
RediSearch supports full-text indexing and stemming-based query expansion in multiple languages, including Chinese, Spanish, Russian, French, German, and many more. Furthermore, you can enrich users’ search experiences by implementing auto-complete suggestions using ‘fuzzy’ search technology.
This latest release also makes RediSearch easier to scale than ever before. With RediSearch 2.0, customers can now quickly grow to query and index billions of documents on hundreds of servers. And with support for Redis on Flash, that can be done in a more cost effective way than ever before. RediSearch can also be deployed in a globally distributed manner by leveraging Redis Enterprise’s Active-Active technology to deliver five-nines (99.999%) availability across multiple geo-distributed replicas, which enables read operations (like querying and aggregation) and write operations (e.g. indexing) to be executed at the speed of local RediSearch deployments without worrying about conflict resolution..
RediSearch in the real world
Enabling indexing, querying, and full-text search across different data types and data structures is essential to helping users unlock the power of their data. RediSearch’s ability to run these queries in a fully distributed manner without scaling limitations and at sub-millisecond latencies is truly a game changer.
Our customers are using RediSearch to not just accelerate their legacy applications but also to create their next-generation real-time applications. GoMechanic, for example, uses RediSearch to search across a database of 10 million spare parts (for more, see the RediSearch 2.0 press release). Many e-commerce apps are using RediSearch to provide interactive search across millions of products in their catalogs and using fuzzy search to give users auto-complete suggestions.
With RediSearch’s ephemeral search capability, creating indices is lightweight, enabling thousands of indices in the same database so developers can rapidly create and expire indices based on a customer’s purchase history, for example. A health insurance company, meanwhile, is using RediSearch to let users run geospatial queries on their websites and apps to find appropriate healthcare providers in their neighborhood. All of these uses are already deployed at scale in production environments.
Get started with RediSearch 2.0
Learn how you can use RediSearch 2.0 to accelerate your application modernization journey. Or to get started right away, visit the RediSearch Quick Start page.
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.