 Stop testing, start deploying your AI apps. See how with MIT Technology Review’s latest research.
Stop testing, start deploying your AI apps. See how with MIT Technology Review’s latest research.
Download now
A graph database is a type of database that uses a graph model to represent and store data. The data is represented as a collection of nodes and edges. Nodes represent entities or objects, and edges represent connections or relationships between them. Nodes and edges each have attributes or properties that give additional details about the data. Representing complex relationships between data in traditional databases can be challenging because they are built to manage and store data in tables and columns. Contrarily, graph databases represent data as a network of nodes and edges, making it simple to model intricate relationships between data.
Think of a person and their connections on a social network as nodes and edges, respectively. Each person has attributes such as their name, age, and location, and each connection between them (edge) may have additional properties, such as the date they became friends or the number of times they have interacted online.
Graph databases are also NoSQL systems designed to investigate correlations among complicated interconnected entities. Graph databases store, manage, and query complex data networks known as graphs. The structure of this database addresses the limitations of relational databases by emphasizing the relationship of data. Graph databases are designed to help organizations and individuals who need to manage and make sense of complex data relationships. This includes businesses in various industries such as social media, e-commerce, finance, and healthcare, as well as researchers and analysts who work with large datasets and need to discover patterns and insights.
Graph databases have evolved over several decades, with early database models supporting tree-like structures in the mid-1960s. By the late 1960s, network model databases were developed to support graph structures, and the Logical Data Model introduced labeled graphs in the mid-1980s.
In the early 1990s, commercial object databases (ODBMSs) emerged, and improvements to graph databases continued into the late 1990s with indexing of web pages. The Object Data Management Group published a standard language for defining object and relationship structures in 2000.
Commercial graph databases with ACID guarantees, such as Neo4j and Oracle Spatial and Graph, became available in the mid-to-late 2000s. In the 2010s, horizontal scalability and multi-model databases that supported graph models became available, along with cloud-based graph databases like Amazon Neptune and Neo4j AuraDB.
Graph databases have grown in popularity in recent years due to the need to effectively manage and query intricate data relationships. Representing complex relationships between data in traditional databases can be challenging because of how they manage and store data. Contrarily, graph databases represent data as a network of nodes and edges, making it simple to model intricate relationships between data.
In traditional relational databases, data is organized in tables, composed of rows and columns. Each row denotes a distinct record, and each column denotes a distinct record attribute. Foreign keys establish a relationship between two tables, allowing data from one table to be linked to data in another table.
Graph databases store data in a structure of nodes and edges, where nodes represent entities or objects, and edges represent the connections between them. Each node and edge has its own set of properties or attributes. The use of this structure in graph databases makes it easier to represent complex relationships between data, such as those found in social networks or product recommendations.
Graph databases have several benefits over conventional databases, such as:
Flexibility: Graph databases can easily adapt to new data models and schemas due to their high level of flexibility. As a result, adding or changing data is simple and never requires making major adjustments to the database schema, which is often a downside in relational databases.
Performance: Graph databases are ideal for performing complex queries on large datasets because they are designed to efficiently traverse relationships between nodes and edges. This is a common operation in many applications, and graph databases are optimized for it.
Scalability: Graph databases can often scale horizontally, meaning more nodes can be added to the cluster to boost storage and processing power. This can simplify managing large amounts of data and numerous concurrent queries. In other instances graphs can be stored in a key where it can be scaled by adding replicas.
Natural language processing: Graph databases are well suited for data science and machine learning combined with natural language processing (NLP) applications such as chatbots, virtual assistants, and sentiment analysis. They can easily be used to model relationships between words and phrases.
Data integration: Graph databases can be used to combine structured and unstructured data from various sources. This can make drawing conclusions from various data sources simpler.
Standardization: Graph databases do not currently have a standard query language, however there are several industry-standard graph data modeling languages, such as RDF (Resource Description Framework), OWL (Web Ontology Language), as well as Cypher. Additionally, there are several initiatives underway to create standard query languages for graph databases, such as GQL (Graph Query Language) and SPARQL (SPARQL Protocol and RDF Query Language).
Because of this switching between different graph databases or integrating graph databases with other technologies can be challenging due to the lack of standardization in querying. Each graph database vendor typically has its own query language and syntax, making it difficult to migrate data or integrate with other systems.
Limited developer and user communities: Graph databases have a smaller developer and user community than more well-established database technologies like relational databases. As a result, finding resources, information, and support when working with graph databases can be more challenging. However, the community around graph databases is rapidly growing (as highlighted in the study linked above).
Data Consistency: Graph databases are designed to allow for more flexible and dynamic relationships between data, which can make it more challenging to enforce strict data consistency rules. However, it’s worth noting that many graph databases do offer mechanisms for ensuring data consistency, such as through the use of constraints or validation rules. Additionally, data consistency can also be enforced at the application level, rather than relying solely on the database technology.
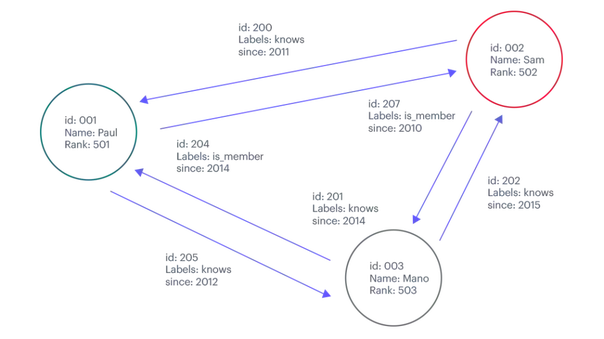
A graph database comprises several elements, such as nodes, edges, properties, and labels.
Nodes: Nodes are the fundamental building blocks of a graph database. Nodes represent entities or objects in the data, such as individuals, interests, or events, where each node has a distinct identifier used to reference and query it.
Edges: Edges represent connections or relationships between nodes, where each edge has a starting node and an ending node that specify the direction of the relationship. In addition, edges also have labels that provide additional information about the type of relationship between nodes.
Properties: Properties are key-value pairs connected to nodes and edges. They are used to store extra details about the data, such as a person’s name, a product’s cost, or an event’s date. Additionally, properties can be used to query and filter the data.
Labels: Labels categorize nodes and edges, which can be used to group them into logical sets. For instance, a social network graph database might use labels to group nodes into people, groups, or pages.
There are various categories of graph databases, each with unique characteristics. Following are some of the popular types:
| Type | Description |
| Property graph databases | Used to store data as nodes and edges, with metadata attached to each node and edge. Hence, property graph databases are well-suited for applications like fraud detection, recommendation engines, and social network analysis. |
| Hypergraph databases | A subset of graph databases with edges connecting more than two nodes. Consequently, hypergraph databases are best for simulating complex data relationships, such as those present in chemical compounds. |
| Object-oriented databases | Used to store and manage relationships between objects. Therefore, object-oriented databases are good for use cases like managing intricate data relationships in applications and modeling complex business logic. |
| Resource Description Framework (RDF) databases | Made to manage and store metadata and their connections to one another about resources, including web pages and scholarly articles. As a result, RDF databases are suitable for applications utilizing knowledge graphs and the semantic web frequently. |
| Mixed-model databases | Combine various data models, including document and graph models. Thus, mixed-model databases are well-suited for content management systems or e-commerce platforms that need the flexibility to handle various data types. |
The flexibility and versatility of graph databases make them well-suited for various use cases; some are discussed below.
Social media networks: Social media networks are one of the most popular and natural use cases of graph databases because they involve complex relationships between people and their activities. For example, graph databases can store and retrieve information about friends, followers, likes, and shares, which can help social media companies like Facebook and Instagram tailor their content and recommendations for each user.
Recommendation systems: Recommendation systems can provide users with tailored recommendations like relationships between goods, clients, and purchases. A movie streaming service, like Netflix, might use a graph database to suggest movies and TV shows according to a user’s viewing habits and preferences.
Fraud detection: Graph databases allow for modeling relationships between different entities, including customers, transactions, and devices, which can be used in fraud detection and prevention. For example, a bank could use a graph database to detect fraudulent transactions by analyzing activity patterns across multiple accounts.
Knowledge graphs: Knowledge graphs are a type of graph database that is used to represent and store domain-specific knowledge. They can be used to model relationships between concepts, entities, and attributes to provide users with recommendations and context-sensitive information. A search engine can use a knowledge graph to provide context for search queries and results.
While we have seen numerous advantages and applications of graph databases, there are some challenges that must be addressed. Some include scalability, complexity, and query performance.
Scalability: Scalability is a crucial factor for graph databases, just like it is for relational databases. It is because large amounts of data and numerous concurrent queries must be handled, which uses extensive processing and storage space. However, as discussed above, many graph databases are scaled horizontally to address this problem.
To learn more about overcoming graph database scaling challenges view the Redis webinar New Data Processing Paradigm in Graph Databases.
Complexity: The setup and administration of graph databases can be more difficult than conventional databases. It is because graph databases have a unique data model and query language, making them challenging for administrators and developers to use. However, many graph databases offer thorough documentation and support to aid users in getting started.
Query Performance: While graph databases are optimized for traversing relationships between nodes and edges, certain queries, such as aggregations and groupings, might cause them to perform inadequately. Nonetheless, multiple graph databases offer query optimization features like caching and indexing to improve performance for common query patterns.
Graph databases are an effective tool for managing and querying complex data networks. Graph databases can model complex relationships between data by representing it as a network of nodes and edges, making them ideal for use cases such as social media networks, recommendation systems, fraud detection, and knowledge graphs. However, graph databases face unique challenges such as scalability, complexity, and query performance.
Despite some challenges, graph databases have a promising future. The ability to model relationships between data will become increasingly important as data becomes more interconnected and complex. Furthermore, the growing popularity of graph-based technologies such as GraphQL and Apache TinkerPop suggests that graph databases will continue to gain traction in the coming years.

