Blog
LangCache public preview: Get fully managed semantic caching


If you’re building AI-powered apps—chatbots, agent workflows, or tackling retrieval augmented generation (RAG)—you know every LLM call adds up in cost and latency. That's why we built LangCache to eliminate redundant queries and dramatically reduce both costs and response times.
Today, we’re thrilled to announce the public preview of LangCache, Redis’s fully managed semantic caching service, now available for all Redis Cloud users as part of September’s Fall Release.
Why caching is essential for GenAI
LLMs have upended natural language applications, but the explosion in usage has exposed key challenges: slow responses, high costs, and inconsistent output quality. A recent MIT Survey found that 72% of AI leaders struggle with accuracy from their generative models, and over half still grapple with latency and integration hurdles. As token costs drop, total volume and spend are only increasing.
At Mangoes.ai, our voice app for patient care gets a lot of specific treatment questions, so it has to be absolutely accurate, and that's what LangCache does. I was worried about LLM costs for high usage, but with LangCache, we're getting a 70% cache hit rate, which saves 70% of our LLM spend. On top of that, it’s 4X faster, which makes a huge difference for real-time patient interactions.
LangCache tackles these issues head-on. By semantically caching requests and responses, it eliminates redundant calls to LLMs, dramatically speeding up responses while slashing operational expenses.
What LangCache delivers:
- Seamless speed: Cache hits yield up to 15X faster responses compared to re-querying large models.
- Major savings: Cut token usage and API bills by up to 70% by skipping unnecessary LLM calls.
- Effortless setup: LangCache is fully managed and integrated directly in Redis Cloud. Forget complex do-it-yourself semantic caching stacks.
- Reliability: Monitor cache hit ratios, latency, usage, and other metrics with out-of-the-box dashboards.
- Privacy and control: Configure scopes for users, apps, or sessions, attach custom attributes to filter cache searches by specific criteria, and manage database connections with ease.
How LangCache works
LangCache sits between your application and any repeatable AI workflow—whether that's LLM calls (like OpenAI), RAG pipelines, or other AI services that generate responses you want to reuse. When your app makes a request, LangCache automatically generates embeddings and searches for matching cached responses, serving them instantly if available. If there's no cache hit, your application proceeds with the original call (to the LLM, RAG system, etc.), and you can then store that fresh result in LangCache for future use.
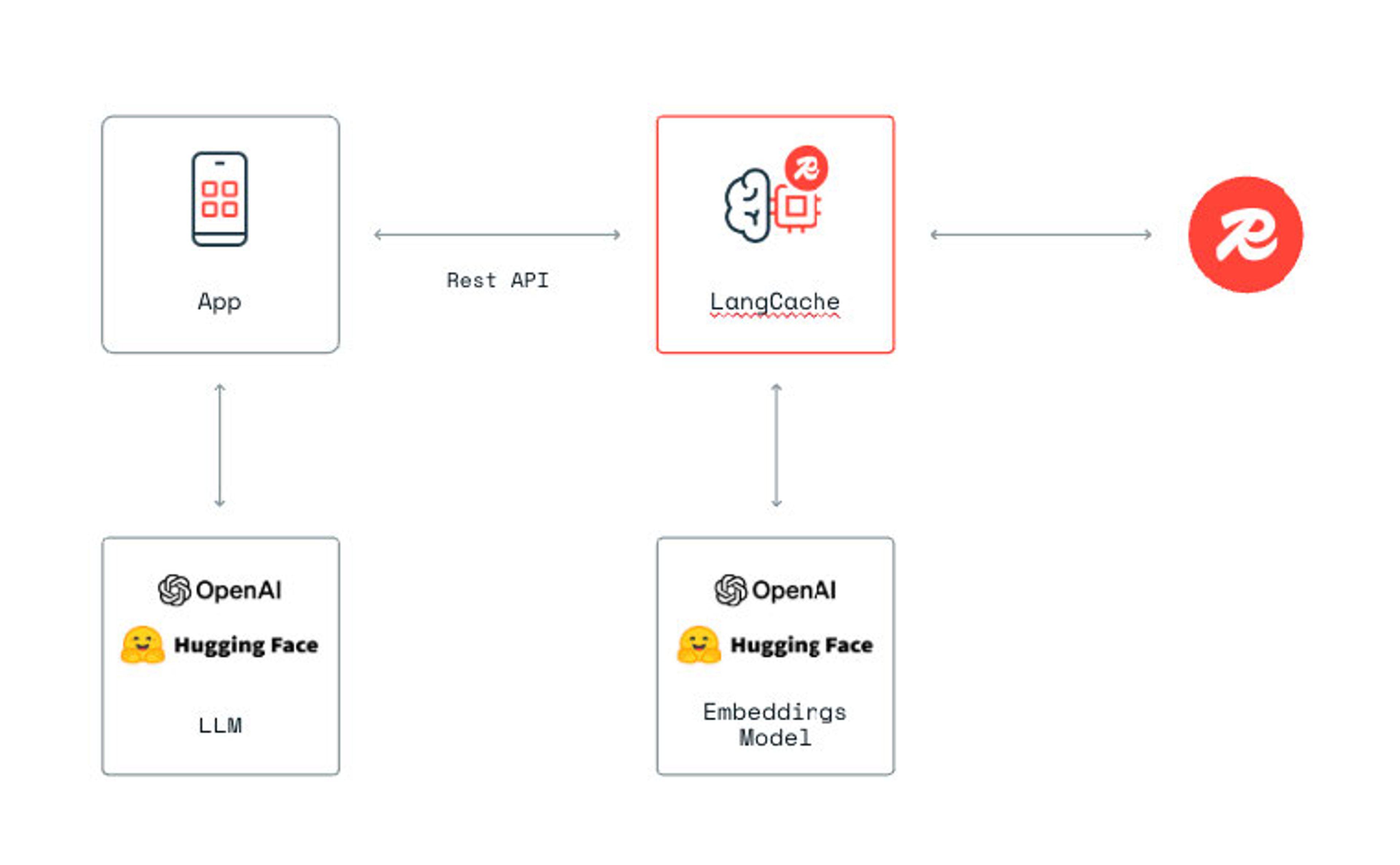
LangCache vs. DIY alternatives
Before LangCache, devs had to build semantic caching from scratch, managing vector databases, data pipelines, client logic, and reliability on their own—often a major operational burden. Competitors like GPTCache or homegrown solutions require deep technical investment and constant upkeep.
LangCache, by contrast, is built for clarity and scale:
- Comes pre-integrated with Redis vector database
- LangCache supports OpenAI embedding models, along with Redis' LangCache embedding model that delivers superior performance as validated in our research paper
- Consumption-based pricing (pay for the tokens and data you use)
- Direct access via REST API or Redis Cloud UI—no extra engineering needed
Who should try LangCache?
You might not realize how many repeat queries your AI app handles, but chances are you're paying for the same answers multiple times. LangCache is perfect for any AI-powered application—whether it's a customer support chatbot answering similar questions, a RAG system retrieving information about the same topics, or an AI agent handling common workflows. If you're building with LLMs and have more than a handful of users, you're likely seeing patterns you haven't noticed: variations of the same questions, similar document searches, or recurring conversation flows. LangCache helps you identify and capitalize on this hidden repetition, turning what you're already paying for into significant cost savings and faster response times.
What do you get for public preview?
For this public preview, users can:
- Create LangCache services with existing databases, with an upcoming option to provision new databases directly from the caching flow
- Experiment with our Redis LangCache embedding model and OpenAI embedding support (more models coming soon)
- Access cache metrics and monitoring within Redis Cloud
- Rely on robust privacy and token management controls
- Accelerate application response times for conversational AI tools, agents, and RAG systems
Get started today
You can create a LangCache service directly from Redis Cloud and start reaping the benefits today.
Getting started is simple:
- Go to Redis Cloud — if you don't have an account, create one
- Find LangCache — it’s in the left-hand navigation tab
- Create a service — provide a service name and select your desired database
- Configure settings — customize as needed or use our defaults
- Integrate with your app — and use our quickstart guide
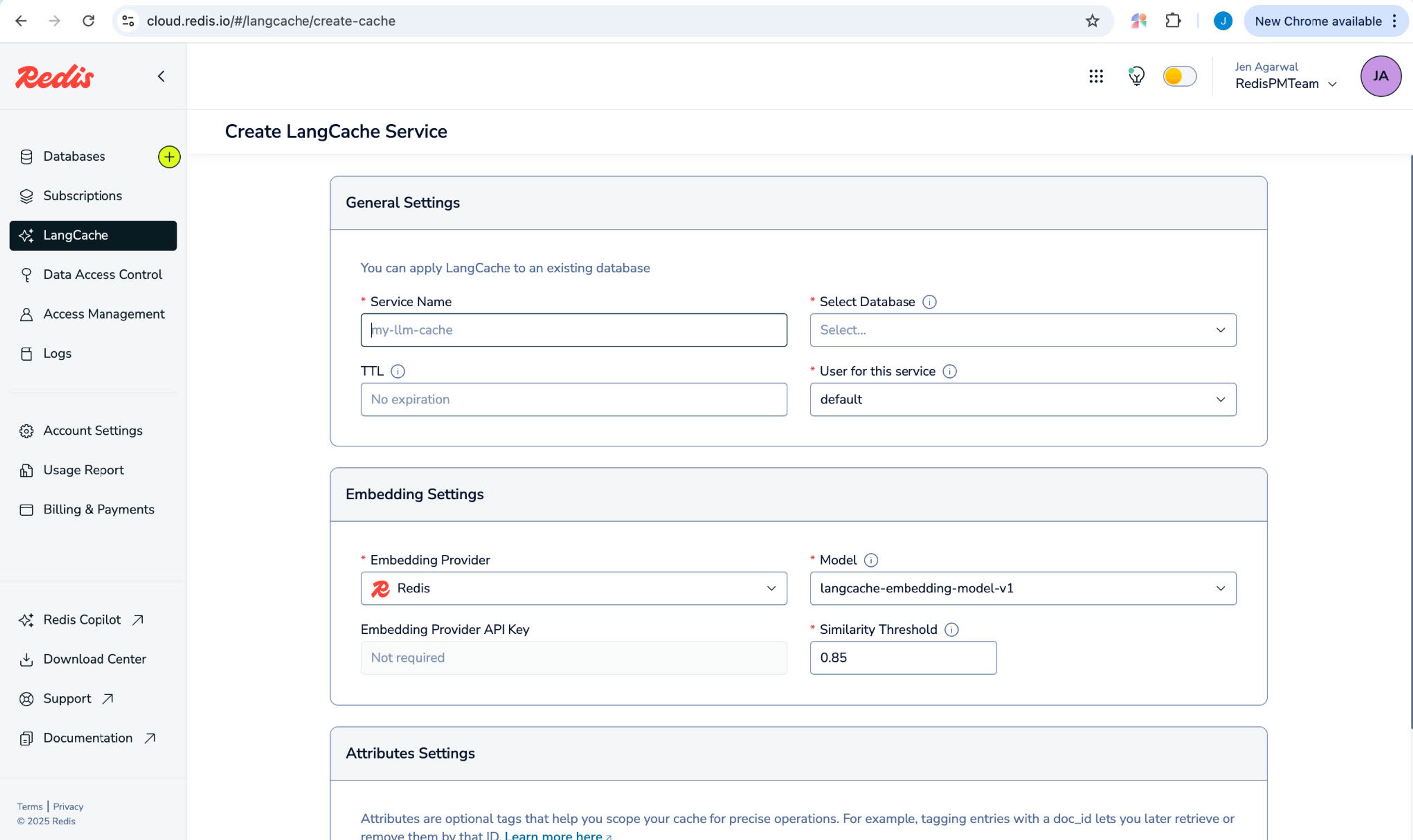
Go to our docs to get detailed instructions on how to create your service.
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.