
A few years back, I was at a conference and a small group of us were talking about scaling software. One individual in the discussion introduced the idea of a company’s “day of deluge.” The day of deluge is the day your organization, and its software systems, experiences their maximum load. If you’re an American pizza delivery chain, the day of deluge is probably Super Bowl Sunday. If you’re a florist, it’s likely Valentine’s Day. Perhaps the most famous deluge day of all is Black Friday—that special day right after Thanksgiving when consumers across America swarm stores to gobble up the goods therein.
But your day of deluge isn’t always on the calendar. For several years, I worked as a software engineer at a major financial services company—a property and casualty insurer to be specific—and our deluges were literal catastrophes. Catastrophes with names like Hurricane Sandy and Hurricane Katrina.
We had some warning. Hurricanes aren’t scheduled, but they also don’t sneak up on you any more. Even so, they put enormous strains on our organization and our claims processing systems. And our finances.
Similar events are happening to many organizations now. The COVID-19 virus is forcing hundreds of millions of people to stay home. The entire internet—and companies that offer services over the internet—are seeing unprecedented loads as many of those people work from home. We designed our software for an antediluvian world but must now deal with the flood. How can we better design it for this environment?
I don’t know that I have the answer. I’m not sure anyone has the one true answer. Software is a domain of trade-offs, choices, and consequences. However, I do have some thoughts that might help.
Up and out
The first and easiest scaling trick is scaling up your hardware. Get a more powerful machine with more processor, more memory… more of everything. While this works well if your Twitch streaming rig needs some extra oomph, it is of limited use for applications at even moderate scale. The box can only get so big. Eventually, you’ll start to see this pattern:
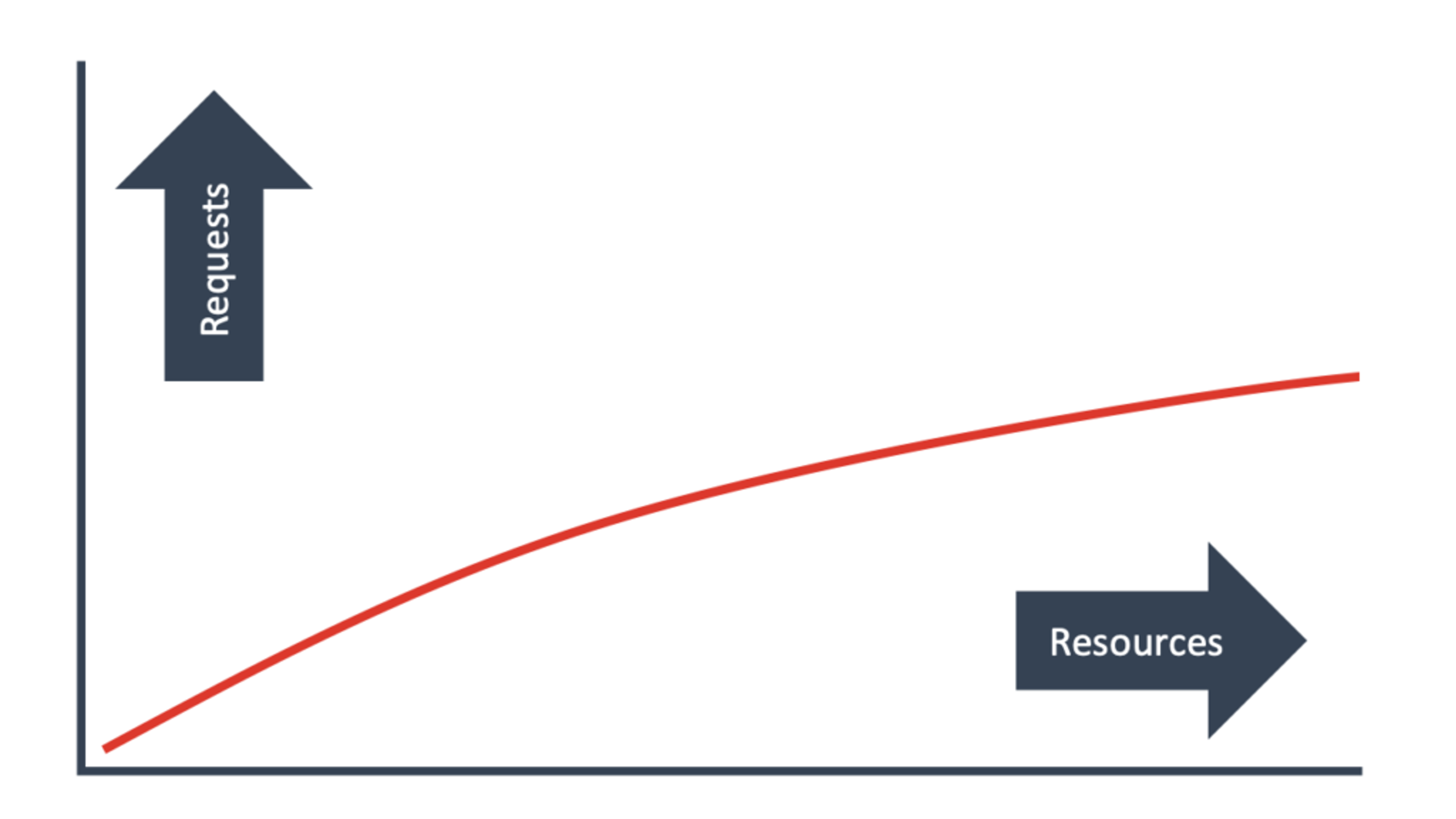
Diminishing returns and then a plateau. You keep upping the processors and the memory and the everything, but it just doesn’t get any faster. I worked at a company that had architected itself into a corner and this was its solution. It worked in the short term. But the costs increased dramatically even as less and less capability was being added.
The next solution is to scale out your hardware. Instead of buying bigger and bigger boxes, buy more boxes. By adding nodes, you can handle more requests. This common technique can carry you pretty far. If you do it right, it can carry you most of the way. But if you don’t do it right, you start running into diminishing returns and plateaus again.
What you need is a solution that allows you to scale linearly. Like this:
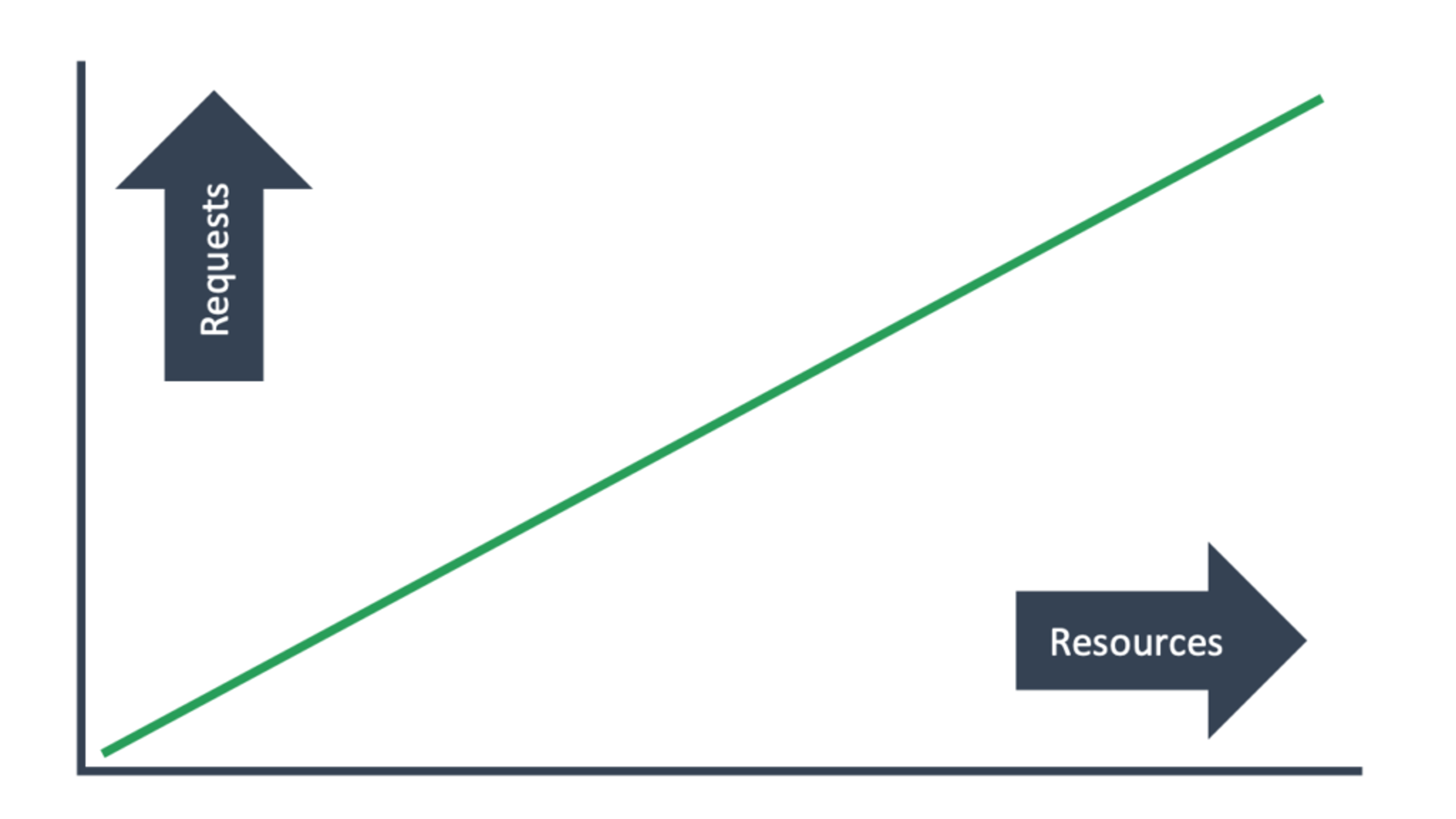
But how can we do that? Read on.
Statefulness
The secret to linear scalability is statelessness. State—whether it be on disk, flash, or in memory—is the thing that causes applications to wait. It is the thing that our threads and our processes and our servers fight over.
And this waiting is the source of the diminishing returns. If we could eliminate state, that would solve all of our problems, right? Technically, yes, but only in the way that forbidding passengers on airplanes would reduce fatalities in air crashes. State is necessary.
Every application has to store and manage state of some sort. I’m using a word processor to store my words right now. That’s state. Without state, an application is useless.
Instead of trying to achieve the impossible goal of complete statelessness, I like to flip this idea on its head and ask: how do we avoid statefulness? This lets us think about minimizing state, and handling the state we must accept in ways that don’t tie up our application. Optimizing how we manage our state lets us get closer to the goal of linear scalability.
This is something that both developers and architects must consider. As a developer, here are four simple things you can do to write less stateful code:
- Pass it in and pass it out. Don’t store state in your code. Instead, make sure that state is provided to your code and your code provides that state to other code. State flows through your code but is not kept by it.
- Use singletons. The much maligned singleton pattern comes into its own when defining stateless blocks of functionality in your application. This is the bread and butter of tools like Spring in the Java world.
- Avoid threaded code. Code needs to be thread-safe if it is storing state. If you find yourself wanting to use locks, semaphores, or mutexes, you’re likely introducing the worst kind of state. Take a pause and be sure.
- Embrace asynchronicity. Use callbacks, futures, and promises instead of blocking calls when accessing state. Blocking calls tie up threads that could be doing something else.
As a software architect, you can discourage the writing of stateful code among your developers using these three ideas:
- Go functional. Functional programming languages and metaphors treat state that is in memory as write-once, read-many. This avoids issues common with multi-threaded application development.
- Use pure functions. Pure functions discourage the development of stateful code because they can only store state external to themselves.
- Single-threaded and non-blocking. Design applications that have a single thread, are fast, and return immediately. Thread pools consume resources. Node.js has this architecture (as does Redis).
These techniques help but they’re only part of the equation. They mostly push the state out of the code. But every application has to store its state somehow. So how can we store our state and still get that near linear scalability?
Scaling storage
Scaling storage can be a bit more fiddly. Sometimes, you can get away with just scaling up your database cluster. There can be diminishing returns down that path, but your particular deluge might not encounter them.
If that doesn’t work (and for many applications it won’t), you have two basic options:
- Use distributed data types.
- Get a really, really, really ridiculously fast database.
(There’s also option 3. Use distributed data types with a really, really, really ridiculously fast database.)
Distributed data types are an interesting topic and there are a few to check out, but I’m just going to talk about one: conflict-free replicated data types, or CRDTs.
CRDTs allow updates to be replicated between nodes in a database without needing a master node. All nodes are equal and any node can accept an update. However, reads from any given node are not guaranteed to have all updates at any given time as they might not have replicated yet. But, it will have eventual consistency. This allows for some really nice scalability with the tradeoff that your reads might not be current. For many applications, this is an excellent exchange.
Redis is an obvious answer to the second option. It runs in-memory, which is orders of magnitude faster than anything stored on disk in both latency and throughput. It’s single-threaded and event-based, just like your application is if you followed the aforementioned advice. It does have state, but it’s fast enough that it takes a lot of load to cause clients to start blocking.
For the third technique—the why-not-both option—Redis Enterprise solves that neatly with Active-Active replication that uses CRDTs.
You missed something
Did I? Oh. You probably mean caching and queueing.
Caching is something we’re all familiar with. Take common reads from your database and save them in memory. Caching like this moves slow and remote disk access to fast and local memory access. It’s really just a way of taking a slow database and turning it into a faster database for certain operations. If you’re using something akin to a traditional relational database, caching is often a great option to improve your performance.
Queuing is a little different and is a notable part of dealing with peak load. Many tasks are long running—like sending an email. A common way to do this is to put a request to send an email in a queue. Then, another node will pick up that message and send the email. This keeps the user happy, as they get a faster response, and it keeps the requesting node from tying up a bunch of threads while the email is being sent.
However, this can also be effective for shorter-running processes. By breaking out applications into lots of little pieces—each on their own node—and connecting them with queues, we are able to make lots of little, linearly scalable services (i.e. microservices). These services can then be scaled out—perhaps even automatically based on load—to meet the load required.
How do you deal with your day of deluge?
There’s lots more that I could talk about here. Streaming comes to mind. Microservices is a massive topic that my peers, Kyle and Loris, wrote a book about. Autoscaling is a great tool for DevOps teams to automatically expand and contract your pool of nodes to meet demand.
The idea of a day of deluge has always fascinated me. I like what it tells me about the nature of so many businesses. Until I was introduced to this idea, it never occurred to me that pizza and wing places had to gear up for Super Bowl Sunday.
I’d love to hear about your company’s day of deluge and how you’ve addressed them. Feel free to reach out to me on Twitter and share!
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.