Blog
Why Migrate a Dynomite Database to a Redis Enterprise Active-Active Database?

Since its creation in 2009, Redis OSS has had a very vibrant open source community. Many tools and utilities have been developed around it and Dynomite, a peer-to-peer geo-distribution layer for non-distributed datastores, is one of them.
Dynomite was developed by a team of engineers at Netflix and released as open source. Although it has provided good solutions for specific needs, it hasn’t been effectively maintained in the last few years. Furthermore, some of the functionalities, commands, and data types of Redis OSS (e.g. Pub/Sub or Streams) are rendered unavailable or limited by Dynomite’s distribution model of Redis OSS instances.
For this reason, we have been helping organizations with migrating their Dynomite databases to a Redis Enterprise cluster.
Dynomite and Redis Enterprise architecture comparison
Let’s start our comparison with a quick description of both Dynomite’s and Redis Enterprise’s architectures.
Dynomite
A typical Dynomite cluster can be described as follows:
- It spans across multiple data centers
- A single datacenter is a group of racks
- A rack is a group of nodes: each rack holds the entire dataset, which is partitioned across multiple nodes in that rack
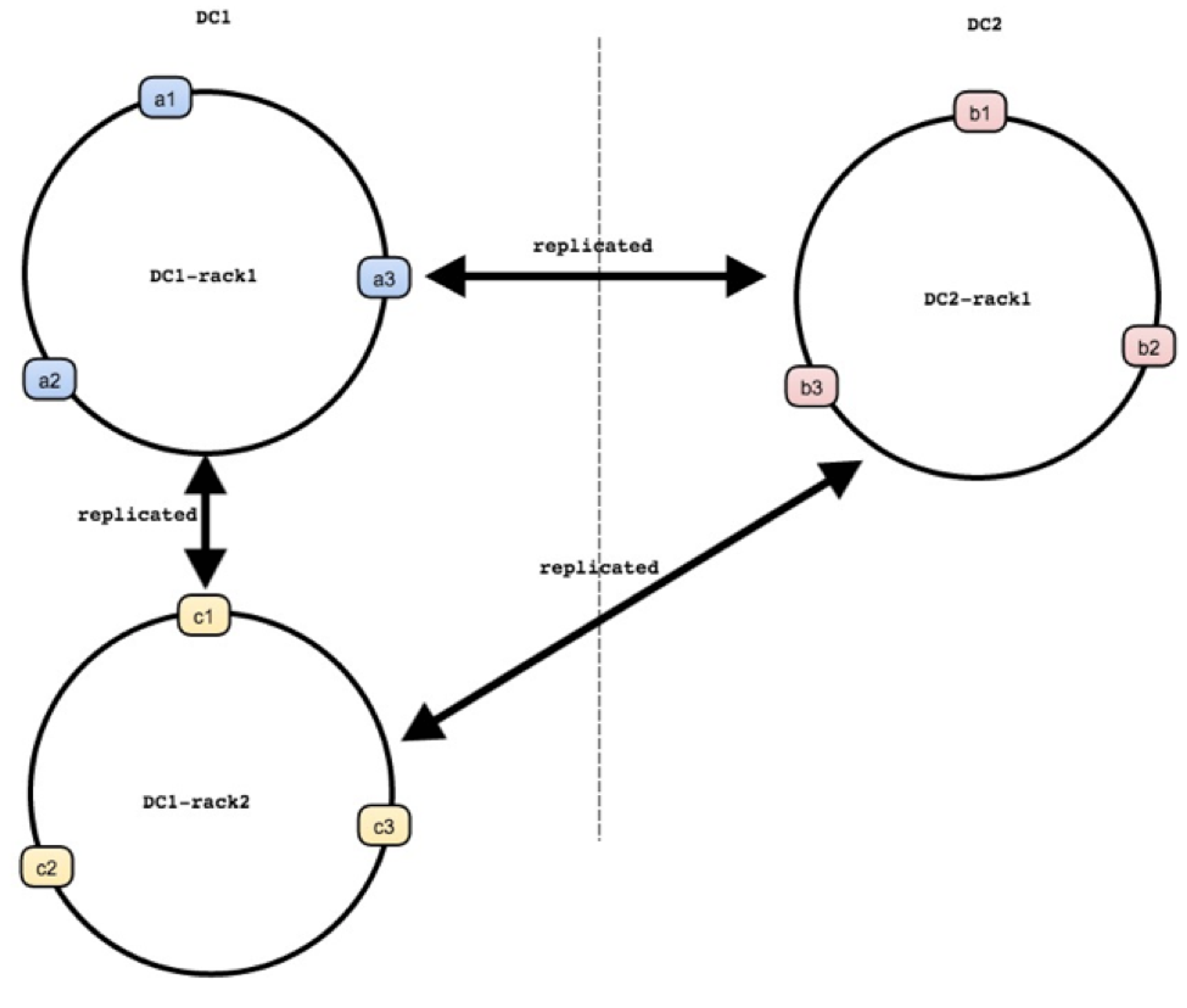
Dynomite is a peer-to-peer distribution layer, therefore a client can send write traffic to any node in a Dynomite cluster. If the node is the one responsible for the data, then the data is written to its local Redis OSS server process, then asynchronously replicated to other racks in the cluster across all data centers. If the node does not own the data, it acts as a coordinator and sends the write to the node owning the data in the same rack. It also replicates the writes to the corresponding nodes in other racks and DCs.
Redis Enterprise
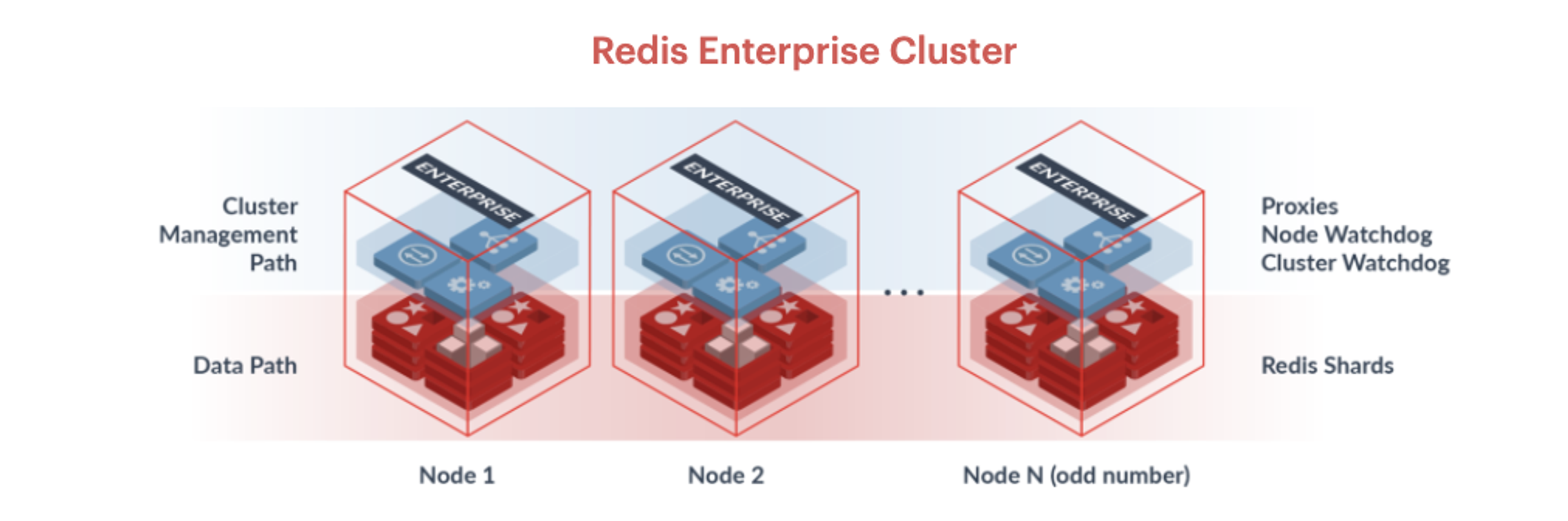
A Redis Enterprise cluster also distributes data across different Redis instances, or shards, but there are two main differences:
- There can be more than one shard on a node – but a primary and a replica cannot live on the same node, for high availability purposes.
- There is only one replica for each primary shard. Clients perform data operations on primary shards. Their respective replicas exist for high availability in case of failure of the primary shards.
Another important part of a Redis Enterprise cluster is what is called the “management path;” it includes a Cluster Manager, a Proxy, and a REST API/UI. The Cluster Manager is responsible for orchestrating the cluster, placing the database shards in highly-available nodes, and detecting failures. The Proxy hides the cluster topology of Redis Enterprise from applications by providing a single, never-changing endpoint, for each database within a cluster. It also helps scale client connections by multiplexing and pipelining commands to the shards.
Here is an illustration of a typical Redis Enterprise Cluster:
With Redis Enterprise’s Active-Active feature, you can create a global database that spans multiple clusters. Those clusters typically reside in different data centers around the world. An application that writes to an Active-Active database connects to a local instance endpoint. All writes by the application to a local instance are replicated to all other instances with strong eventual consistency.
Active-Active replication provides many advantages as a geo-distributed solution, one of which is seamless conflict resolution for simple and complex Redis Enterprise data types, which we’ll discuss below.
Now that we have an idea of the topologies of Dynomite and Redis Enterprise, let’s see what they entail for developers and for DevOps within an organization.
Dynomite or Redis Enterprise: What difference does it make for developers?
Aside from Dynomite not being actively maintained, there are three main reasons why an organization would want to migrate to Redis Enterprise from a developer’s point of view :
- Redis’ functionalities are limited and more complex when using Dynomite
- Dynomite doesn’t have an effective way to deal with geo-distributed write conflicts
- Support you can get from Redis
Let’s see the first two in more detail.
Limited and complex Redis OSS
As you probably already know, Redis OSS is not a plain key-value store, in the sense that it does not only let you associate string keys to string values. Redis OSS is a data structures server supporting different kinds of values such as lists, sets, hashes, or streams. We call those the “core data types” of Redis OSS.
Redis OSS is also extensible through dynamic libraries called “modules”. Modules allow you to rapidly implement new Redis commands with features similar to what can be done inside the core itself. Among the most popular modules are RediSearch, which provides querying, secondary indexing, and full-text search, and RedisJSON, which turns Redis OSS into a powerful document store.
As discussed in the introduction, some of Redis OSS commands and data types are rendered unavailable or limited by Dynomite. Here is a non-exhaustive comparison:
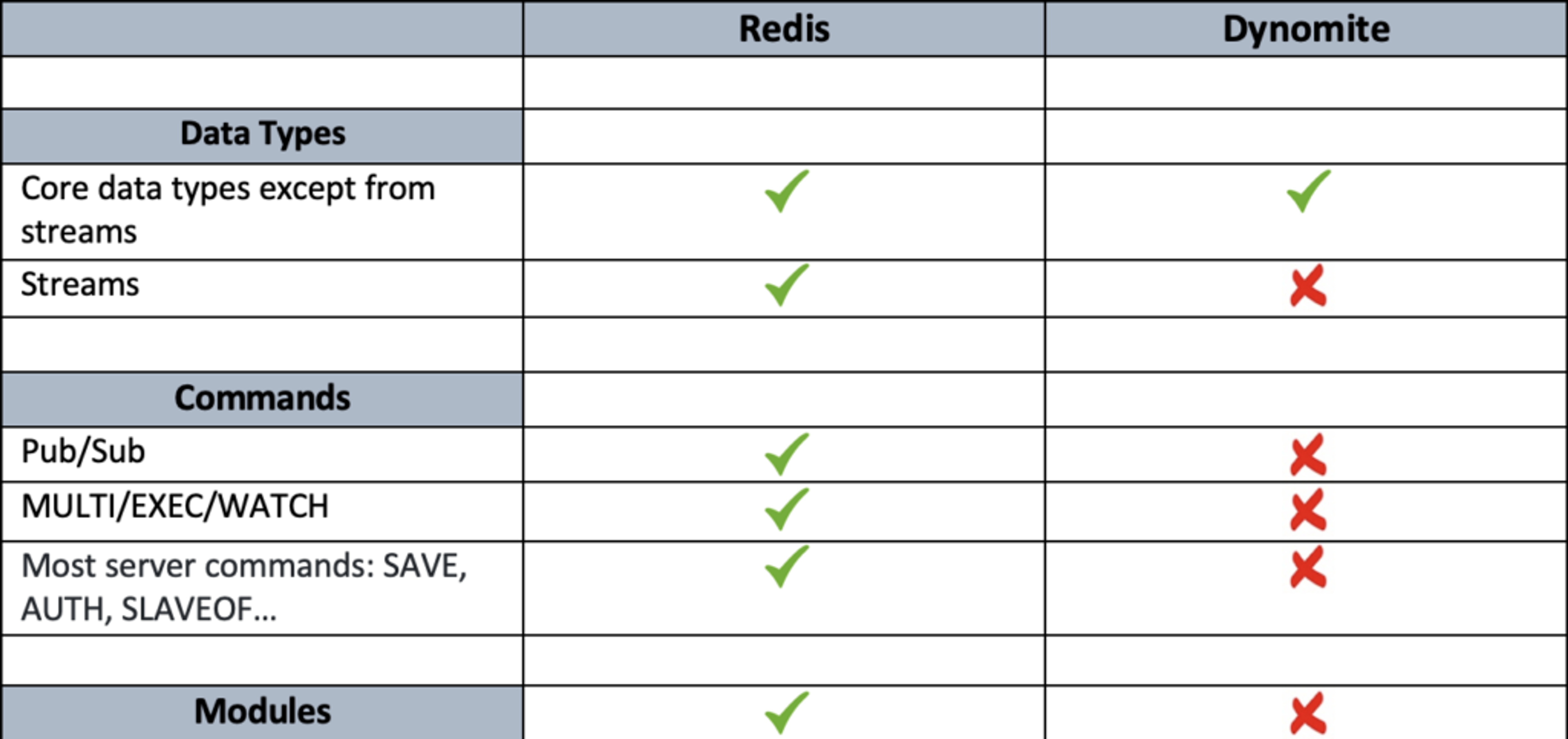
You can find a complete list of supported and unsupported commands with Dynomite here.
On the other hand, Redis Enterprise, which is maintained alongside Redis OSS, allows for multi-model operations using modules and for core Redis OSS data structures to be executed in a fully programmable and distributed manner.
Absence of conflict resolution
Dynomite is an AP system and gives you three options for consistency. Whichever option you choose, it is important to be aware that Dynomite resolves the asynchronous write conflicts by applying the Last Write Wins strategy. This can lead to lost updates due to irrelevant timestamps, especially in the context of geo-distributed writes.
On the other hand, Redis Enterprise’s Active-Active architecture is based on an alternative implementation of Redis OSS commands and data types called Conflict-Free-Replicated-Data-Types, or CRDTs. CRDTs use vector clocks for event ordering. They make sure that when any two replicas have received the same set of updates, they reach the same state, deterministically, by adopting mathematically sound rules to guarantee state convergence. Additionally, one can enable causal consistency as well.
Therefore with Redis Enterprise:
- The outcome of concurrent writes is predictable and based on a set of rules
- Applications don’t need to bother with concurrent writes and the resolution of write conflicts
- The dataset will eventually converge to a single, consistent state
If you’re up for it, you can find the rules which are implemented as well as examples of conflict resolution by following this link.
Dynomite or Redis Enterprise: What difference does it make for DevOps?
Now let’s compare Dynomite and Redis Enterprise from a DevOps point of view, by discussing the following topics:
- High Availability
- Scalability
- Deployability
High availability
When a node fails within a Dynomite rack, writing and reading to the rack becomes impossible. This means that an application writing locally needs to handle the failover to another rack by itself. Note that, if your application is developed in Java, Netflix’s Dyno client can handle failovers to remote racks when a local Dynomite node fails.
Furthermore, when the node comes back up, any data that has been written on remote racks during the failure will be missing from the failed node. If you deploy within AWS autoscaling groups, you can use Netflix’s Dynomite Manager, which does node replacement and node warm-up within an AWS auto-scaling group.
What about Redis Enterprise’s high availability?
When a node fails, a single-digit-seconds failover happens for all primary shards living on that node, and their replicas are promoted to primaries. This auto-failover mechanism guarantees that data is served with minimal interruption.
Based on this :
- The Redis Enterprise Proxy makes sure that the single-endpoint of your database, which won’t change in case of a failover, so no reconfiguration of your application is needed.
- There is a “replica_ha” option that ensures when a replica is promoted to the primary, a new synced replica shard is created automatically on any of the other nodes available.
These mechanisms allow Redis Enterprise to guarantee 99.99% uptime and 99.999% uptime for Active-Active deployments.
Scalability
Dynomite allows you to scale Redis OSS while maintaining good performance in terms of latency. You can check the benchmarks but, if you’re using Dynomite, you probably already know that.
When it comes to scalability, the main differences between Dynomite and Redis Enterprise are:
- Manageability
- Out-of-the box connection management
- Resource optimization
Manageability
If you’re not using Dynomite Manager within an AWS autoscaling group, adding hosts to a running Dynomite rack typically requires:
- Leveraging a “dual writes” technique by using the Java Dyno client; your application writes into the old/small cluster as well as the new/scaled one. After a few days, you route traffic only to the new cluster and make it become the active one.
- Migrating your database from the old/small cluster to a new/scaled one
On the other hand, Redis Enterprise allows you to:
- Scale up by adding shards to your database without adding nodes to your cluster: This scenario is useful when there is enough under-utilized capacity in the cluster. Remember: one node does not equal one Redis instance. Resharding your database can be done in a few clicks through the Redis Enterprise UI, or by leveraging the Redis Enterprise’s REST API. It is done without downtime or service interruption. It is also transparent to the application since the database’s endpoint does not change.
- Scale out by adding node(s) to the cluster. This scenario is useful if more physical resources are needed in order to add shards to your database. Note that with Redis Enterprise Cloud, which is our fully-managed DBaaS offering, organizations don’t need to worry about this step. Redis will provision and manage the infrastructure and resources for them. See more information in the Deployment section of this article.
Here is a benchmark that Redis did a few years ago, in which Redis Enterprise delivered over 200 million ops/sec, with sub-millisecond latency, on 40 AWS instances.
Connection management
When we talk about connection management with Redis, what first comes to mind is how Redis clients, like Jedis or Lettuce, handle connection pooling and pipelining. Netflix was no exception to this and implemented these features for their Dyno client.
Redis Enterprise provides such features out-of-the-box. The Proxy itself establishes persistent connections to shards in the cluster, and those connections are shared by clients. It also applies performance optimizations by scheduling requests on a number of persistent connections to the shards, doing multiplexing, and pipelining on the side of Redis.
Plus, the proxy is multi-threaded and will automatically scale to handle bursts in client connections.
Resource optimization
Firstly, let’s remember that within a Redis Enterprise cluster one machine does not equal one Redis instance and that each primary shard can only have up to one replica.
Secondly, Redis Enterprise is multi-tenant. That means that a single Redis Enterprise cluster can serve hundreds of completely isolated databases. This would be far from trivial to do using Dynomite. It is worth noting that Redis Enterprise’s multi-tenancy fits well with its multi-model capabilities. In the context of microservices, one could imagine running different fit-for-purpose databases in a single set of nodes, each with their own replication, scaling, persistence, and module configuration.
Finally, Redis Enterprise has a feature called Redis On Flash (RoF). RoF enables your databases to use both RAM and dedicated flash memory (SSD/NVMe) to handle much larger datasets with RAM-like latency and performance, but at >70% lower cost compared to an all-RAM database.
Deployment options
Dynomite can be deployed in containers or machines running Ubuntu, RHEL, and CentOS. Deployments are always self-managed, in the sense that you need to provide infrastructure and resources to manage your cluster. Furthermore, as discussed before, if you want to take advantage of the features of Dynomite Manager, you need to deploy Dynomite within an AWS autoscaling group.
On the other hand, Redis Enterprise has many deployment options, which can be divided into two groups:
- The self-managed solutions, whereby you download, install, and deploy the Redis Enterprise Software yourself. There are lots of options which include Linux installers (multiple distributions), Amazon Machine Image (AMI), Docker Containers, Kubernetes, RedHat OpenShift, Google Kubernetes Engine (GKE), Azure Kubernetes Service (AKS), or Amazon Elastic Kubernetes Service (EKS).
- The managed solutions: Redis Enterprise Cloud is offered as a fully managed cloud service (DBaaS) on all three major public cloud platforms (Google Cloud, AWS, and Azure). Redis will host a dedicated environment for you, with the necessary resources, in which you can create databases with private and public endpoints for your applications to consume.
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.