Blog
Announcing Redis Community Edition and Redis Stack 7.4


Redis’ success has always been rooted in the deep connection we have with our users. Building Redis has been, and will continue to be, a collaborative effort.
Today, we’re releasing the latest version 7.4 of Redis Community Edition and Redis Stack as Generally Available (GA). It includes the highly requested hash field expiration feature, new vector data types to significantly reduce memory usage, and time series insertion filters. We continue to work to improve the developer experience, so starting with this version, we’re also guaranteeing support for all new features in the official Redis Client libraries and Redis Insight.
Redis 7.4 Community Edition is the first version of Redis dual-licensed under RSALv2 and SSPLv1. Community Edition is available for free to the Redis community and our customers, and developers will continue to enjoy permissive use of Redis under the dual license. Redis 7.2 and prior releases will continue to be called Redis open source software (OSS). Starting with Redis 7.4, we refer to the open, freely available versions as Redis Community Edition.
You can now set an expiration for hash fields.
Our community has long been asking for better control over hash fields in Redis. Thehash data structure is one of the most popular for our users and customers. A hash holds a set of name-value pairs, named fields, and is ideal for representing data objects and is also often used for storing session data. It provides the ability to add, fetch, or remove individual fields, fetch the entire hash, or use one or more fields in the hash as a counter.
Redis already supports key expiration. For each key, users can specify a time when the key should expire, or alternatively, specify the remaining time-to-live (TTL) after which the key will expire. One very frequent request (GitHub: 1, 2, 3, 4 and Stack Overflow: 1, 2, 3) is to allow setting the expiration time or the remaining TTL for individual hash fields. This addition will make your caches, session stores, or any other use case more memory efficient and improve the performance.
As an example, one place where this can be useful is session management. Some data in a session you might want to preserve for a longer time, such as a user’s shopping basket or their preferences. But some parts you might want to expire, such as an authentication token. Previously, you had to model this in two separate keys, while logically the data belonged together. Having the ability to expire only parts of the hash will simplify session management and other use cases.
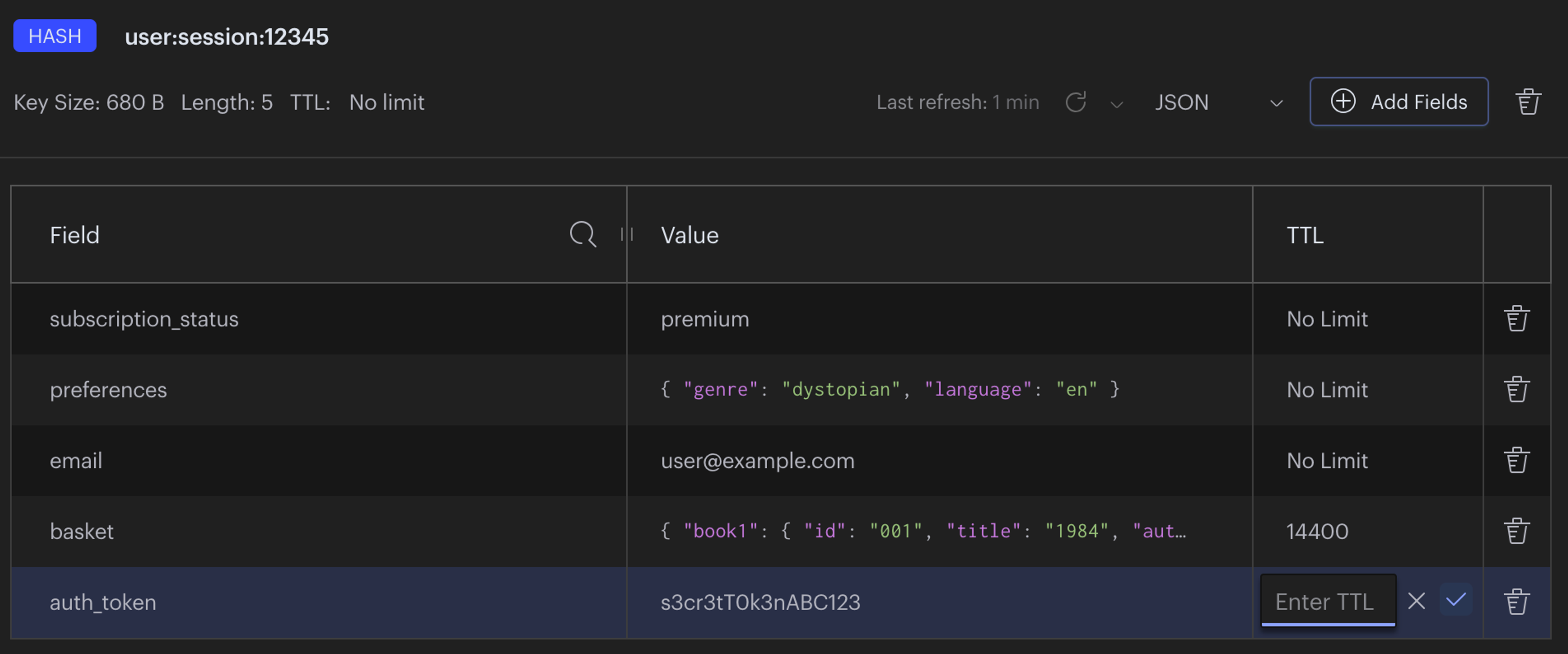
Reduce memory consumption in vector databases with new data types.
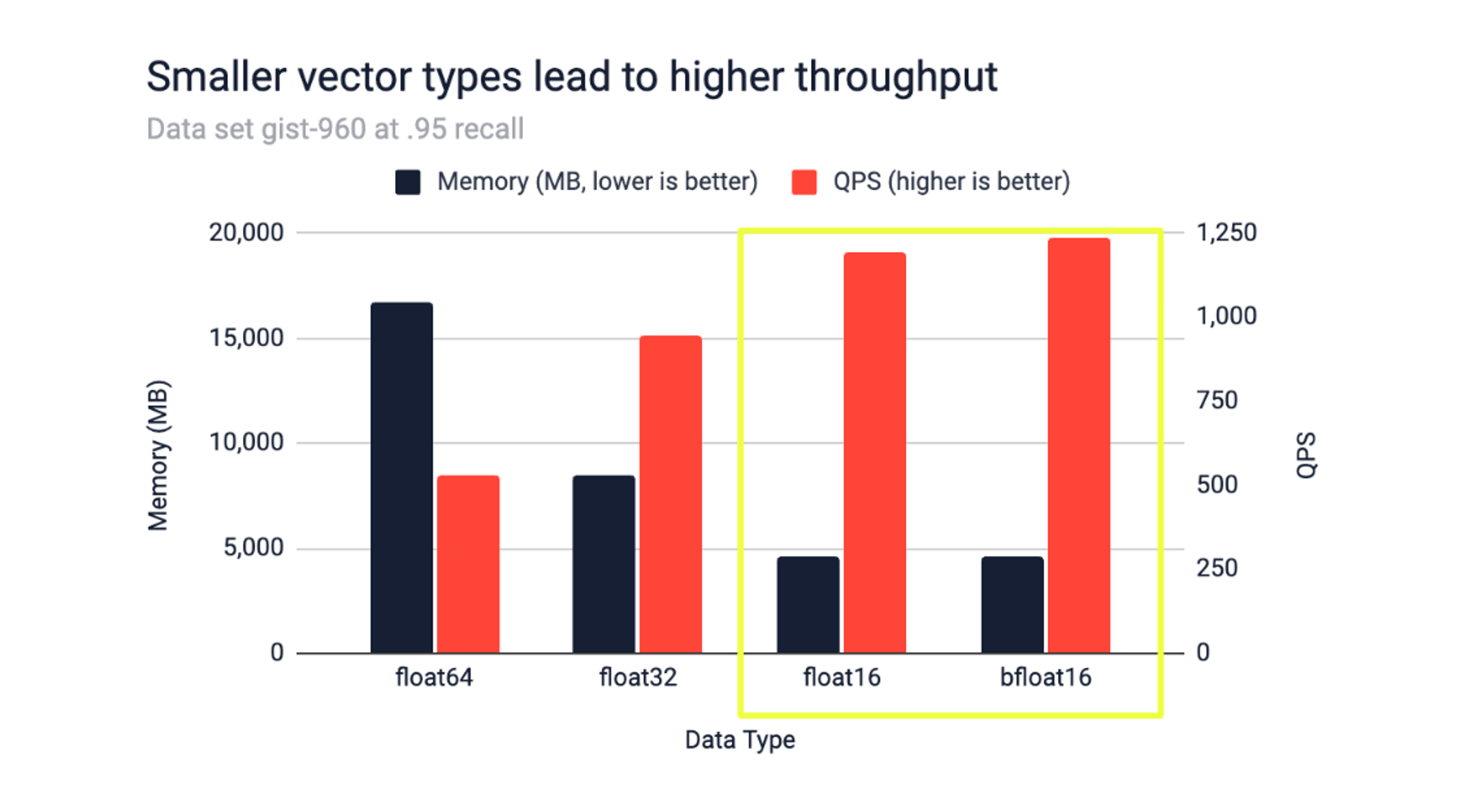
We heard from our community that you want to use memory more efficiently and that you need faster responses from your AI apps. With Retrieval Augmented Generation (RAG), real-time data retrieval and processing are crucial for augmenting LLM responses with contextually relevant data. You can now leverage the new bfloat16 and float16 data types in addition to the existing float32 and float64, to reduce memory consumption with the Hash data type by up to 47% and reduce latency under load by up to 59%.
To show the impact of these two new data types, we benchmarked them against float32 and float64 data types for four different datasets. When considering configurations for M/EF resulting at a recall of 0.95 we observed that:
- Indexing time is up to 31% lower compared to float32 and 58% lower compared to float64.
- While the dataset size is logically halved for bfloat16 and float16 compared to float32, the index size depends on M/EF configurations. We observed that the total used memory was reduced between 22% and 47%.
- For multi-client tests, we achieved 34% higher QPS and 52% lower latency compared to float32 and 134% higher QPS and 59% lower latency compared to float64.
Regarding the maximum achievable accuracy, in three out of the four datasets we benchmarked, this remained unchanged. For the DBpedia data set, the maximum accuracy loss was 0.03. It’s important to note that accuracy loss is inherently tied to the datasets themselves. Therefore, it’s important to evaluate each case individually when dealing with production-grade setups and data.
Secondary indexing is now simpler to use.
The Redis Query Engine was initially built for full-text search (hence the FT. commands), but we observed that our community and customers were often looking for simple secondary indexing. They gave us valuable feedback on how the developer experience could be enhanced and which features were missing.
For secondary indexing in the Redis Query Engine, we have an efficient index type called TAG. Previously, querying an email address stored in a TAG required escaping special characters like ‘@’ and ‘.’, making queries cumbersome to implement and giving no results or syntax errors when done incorrectly.
Now, to query a TAG containing special characters, simply wrap the query term in double quotes, eliminating the need to escape special characters. Here’s a simple code example to illustrate this enhancement. Let’s create the index and add some sample data:
To query the e-mail in the previous experience, you had to escape every special character.
7.4 also includes significant improvements in handling indexing and querying of empty and missing fields. This feature, highly requested by the community and customers, allows for more dynamic data models and supports scenarios where fields are added to documents at a later stage.
In a bank, for example, some customers’ contracts could optionally have to use an exchange rate. To index a contract without the ‘exchange_rate’ field and later query for contracts based on the presence or absence of this field, you just make the index aware using the new keyword INDEXMISSING:
When querying, you should use the syntax: FT.SEARCH contractIndex 'ismissing(@exchange_rate)' for contracts with no exchange rate property, or a negation form FT.SEARCH contractIndex '-ismissing(@exchange_rate)' for contracts with the new attribute.
Lastly, we added some additional geospatial search capabilities with new INTERSECT and DISJOINT operators and new ways to report the memory used by the index. Check out the documentation and release notes for more details and also how we are expanding.
Reduce time series size with insertion filters.
Many sensors report data periodically. Often, the difference between a new measured value and the previous measured value is negligible and related to random noise or measurement accuracy limitations. When both the time difference and the value difference between the current and the previous sample are small, you can now define an insertion filter to ignore the new measurement.
Removal of triggers and functions.
Redis Stack 7.4 no longer includes Triggers and functions. After a long period of public preview, adoption was low as devs could achieve the same functionality with existing features. We removed these to make Redis simpler.
Download Redis to get started.
To get started with these latest features, download Redis or get started for free on Redis Cloud. 7.4 will be rolled out across more regions in Redis Cloud during the upcoming weeks.
Support for the new features was added to all our official client libraries. Please check the release notes for your language of choice to get started.
Please let us know how you’re using these new features or any feedback you have on our Discord server. We’re excited to continue to release new updates to our community to help you build fast with Redis. Thanks for being an important part of the Redis community.
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.