
You have trusted Redis for over a decade because we make it easy to create powerful, fast applications that perform at scale––and we try hard to deserve that reputation. Redis is continuing that spirit with all the innovation we put into Redis 7.2.
Here’s what we are doing to increase the number of reasons you love us.
There’s an irreplaceable sort of learning that can only be gained by using a tool you’re leading the development of. Before I took up the mantle of Redis CEO, I dove headfirst into using the product as a developer. Its unparalleled performance, its scalability, and its design approach (as outlined in the Redis manifesto) inspired me, just as it has inspired millions of other developers. I saw why Redis is one of the most successful open-source databases in the world.
Among the reasons for Redis’ growth are increasing demands for faster applications, real-time inferencing, and the emerging broad adoption of generative AI and vector databases. As Redis has expanded far beyond its beginnings as a data structure server (often used for caching), new waves of developers want to enjoy Redis’ benefits. We realized that we need to expand our responsibility for the full experience for all Redis practitioners: developers, architects and operators.
As a developer, I appreciated how elegant and easy it is to use the Redis core API. So much so, in fact, that I wanted that delightful experience to be reflected in other parts of the product portfolio, such as in clients, integrations, tools, and documentation. We need to address this, I decided––and to take a more active guiding role.
I joined Redis in February. Since then, we’ve established a strategy to expand our role as the stewards of the Redis project. In that role, we embrace Redis’s community-driven beauty, while making all distributions of Redis easier to navigate, with clear directions and well-marked trails. By acting as community stewards, we help both newcomers and long-time Redis practitioners enjoy Redis’ uncompromising performance, legendary reliability, and simplicity.
Redis has always been a formidable contender in the tech industry, but the journey to becoming the best version of oneself is never-ending. We’ve been hard at work to make Redis even more rewarding for developers, architects, and operators.
Today, I’m excited to introduce Redis 7.2, a step forward in our continuing journey to refine and improve your experience.
So, let’s dive in and explore the many ways we are making technology easier for Redis users. Because at Redis, we’re committed to helping everyone build better software, faster, and with more confidence.
Introducing Redis 7.2
Redis 7.2 is our most far-reaching release. It encompasses a broad set of new features, and a significant investment in the functionality that supports AI initiatives. In each of these enhancements, you’ll notice a strong theme of making it easier for developers to use Redis, making it run even faster, and making it easier to achieve innovative results.
And we are committing to deliver all of these capabilities through every distribution channel all at once, with an approach we call the Unified Redis Release.
We make AI innovation easier to achieve
The effort to leverage large language models (LLM) and generative AI is transforming computer software at a blistering pace, and we’ve been hard at work delivering capabilities in our platform to make that effort an easy one. We’ve been powering some of the largest customers in the world (including OpenAI) and have years of investment in making machine learning (ML)–and now vector databases–seamless and easily accessible.
We also grok the concerns of the businesses that are doing their best to innovate based on them. For instance, one of my first customer visits was to a large financial services customer. The company has multiple ML workloads running exclusively on Redis, with hundreds of terabytes running at 5 9’s of availability. Enterprises are looking for a vector database that is a proven, enterprise-grade database with Active-Active geo-distribution, multi-tenancy, tag-based hybrid search, role-based access, embedded objects (i.e. JSON), text-search features, and index aliasing. We have all those built-in and battle-tested on Redis Enterprise.
Redis supports generative AI workloads in its database service through several strategies that aim to improve efficiency, reduce costs, and enhance scalability and performance. Redis’ vector database supports two vector index types: FLAT (brute force search) and HNSW (approximate search), as well as three popular distance metrics: Cosine, Inner Product, and Euclidean distance. Other features include range queries, hybrid search (combining filters and semantic search), JSON objects support, and more.
But, when people ask us how Redis can help with building and deploying LLM-powered apps? What can we really do?
- Retrieval Augmented Generation (RAG): Within the RAG framework, responses are generated using pre-trained LLMs and a customers’ own data. Many organizations want to harness the power of generative AI without building their own model or fine-tuning existing ones. Moreover, they are hesitant to share their proprietary data with commercial LLMs. This is where Redis Enterprise comes in. As a vector database, it offers powerful hybrid semantic search capabilities to pinpoint relevant data. In addition, it can also be deployed as an external domain-specific knowledge base. This ensures that general-purpose LLMs receive the most relevant and up-to-date context, thereby improving result quality and reducing hallucinations.
- LLM semantic caching: Redis Enterprise is often used as a scalable cache to store previously answered user queries and results. Redis also uses semantic caching to identify and retrieve cached responses that are semantically similar enough to the input query, dramatically improving cache hits. This significantly reduces the number of requests and tokens sent to an LLM service, which decreases costs and enhances performance by reducing the time to generate responses.
- Recommendation systems: An LLM can serve as the backbone for a sophisticated e-commerce virtual shopping assistant. Redis Enteprise’s contextual understanding and semantic search enables an application to comprehend customer inquiries, offer personalized product recommendations, and even simulate conversational interactions–all in real-time.
- Document search: In scenarios requiring an organization to analyze vast numbers of documents, an LLM-powered application can serve as a powerful tool for document discovery and retrieval. Redis Enterprise’s hybrid semantic search capabilities makes it possible to pinpoint the relevant information and generate new content from these documents.
In the past 12 months, we’ve integrated Redis with the most popular application development frameworks for creating LLM-powered chatbots, agents, and chains. Among these are LlamaIndex, Langchain, RelevanceAI, DocArray, MantiumAI, and the ChatGPT retrieval plugin. In addition, we’ve worked closely with NVIDIA on some of its leading AI projects: NVIDIA’s AI Workflows (Merlin and Morpheus), Tools (Triton and RAPIDS), and then in the works is RAPIDS RAFT–state of the art indexing provided by NVIDIA to deliver higher queries per second (QPS).
These use cases require a new level of high-performance search. With Redis Enterprise 7.2, we’re introducing a preview of scalable search capability. It allows running high-QPS, low-latency workloads with optimal distributed processing across clusters. It can improve query throughput by up to 16X compared to what was previously possible with Redis Enterprise’s search and query engine.
We make it easy to work in a larger developer ecosystem
You don’t become the most admired NoSQL database (according to the Stack Overflow 2023 survey) without some serious developer focus.
Redis 7.2 addresses one area that frustrated me at the beginning of my Redis developer journey, which was figuring out which of the hundred-plus community-developed client libraries fit my needs. Which one supports the latest Redis functionality? The right level of security and performance?
With Redis 7.2, we bring a new level of guidance and support to Redis clients. We are working directly with the community maintainers of five client libraries––Jedis (Java), node-redis (NodeJS), redis-py (Python), NRedisStack (.Net), and Go-Redis (Go)––to establish consistency in such things as documentation, user interface, governance, and security. We also support the RESP3 protocol in Redis Stack and Redis Enterprise (cloud and software).

Supported client libraries
We made Redis more powerful for developers
With this release, we also bring a new level of programmability for real-time data. The public preview of Triggers and Functions brings a server-side event-driven engine to execute Typescript/JavaScript code within the database. This feature lets developers perform complex data manipulations directly on Redis, ensuring consistency of execution across any client application.
Triggers and functions enable cross-shard read operations at the cluster level. This functionality was not available in previous generations of the Redis programmability engine, such as Lua and functions.
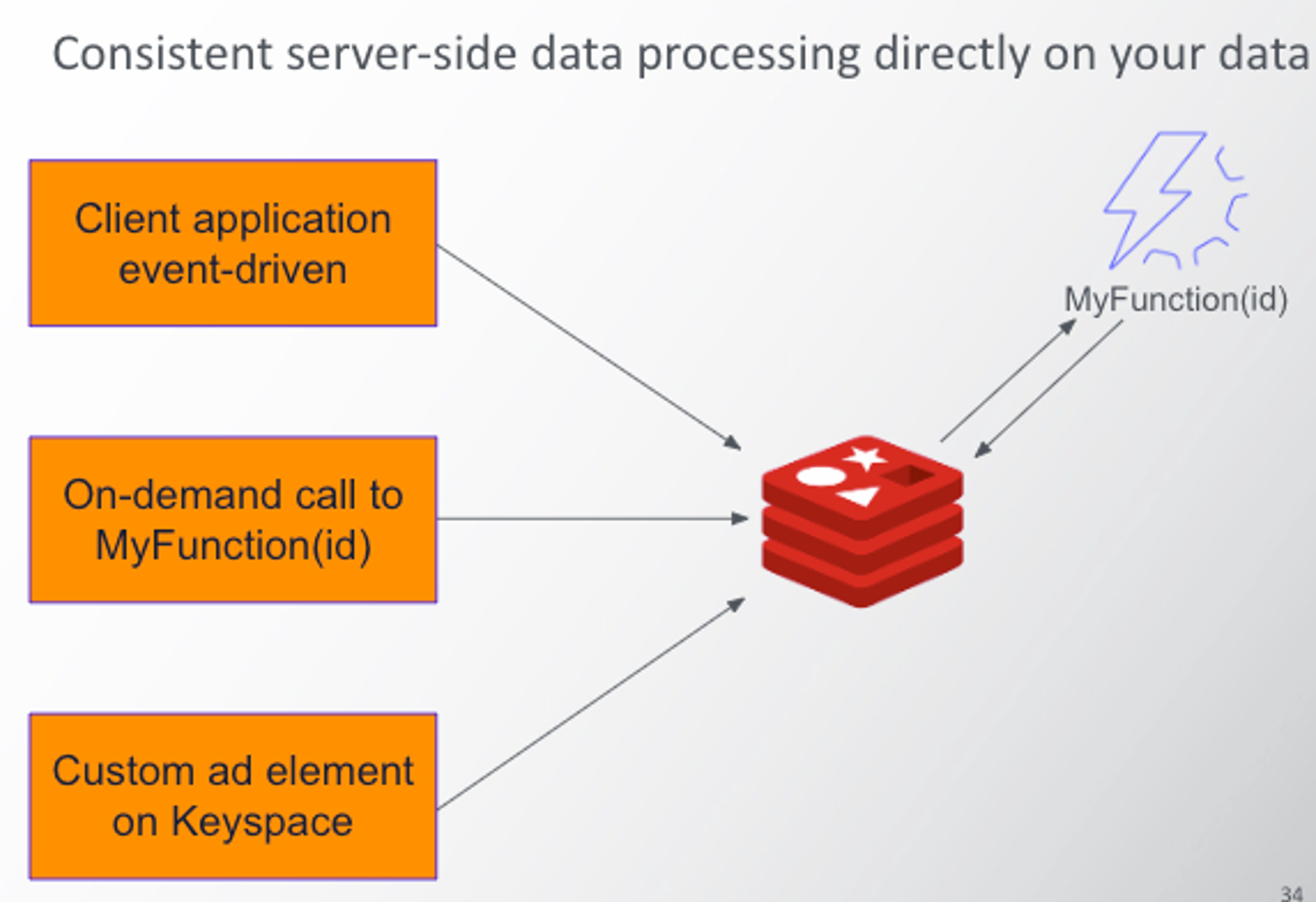
Triggers and functions
Experience it first-hand. Read the full Triggers and Functions announcement and join the public preview.
Geospatial features are improved, too. We improved polygon search in Redis Stack to facilitate the search of geospatial data to find information within a geographic area.
For example, in an application to locate taco restaurants, the geospatial information is the indexed location data of all the restaurants in San Francisco. The polygon that a user draws on a digital map is the geographic area of the search. Redis retrieves only the keys associated with the restaurants within the boundaries of the drawn polygon.
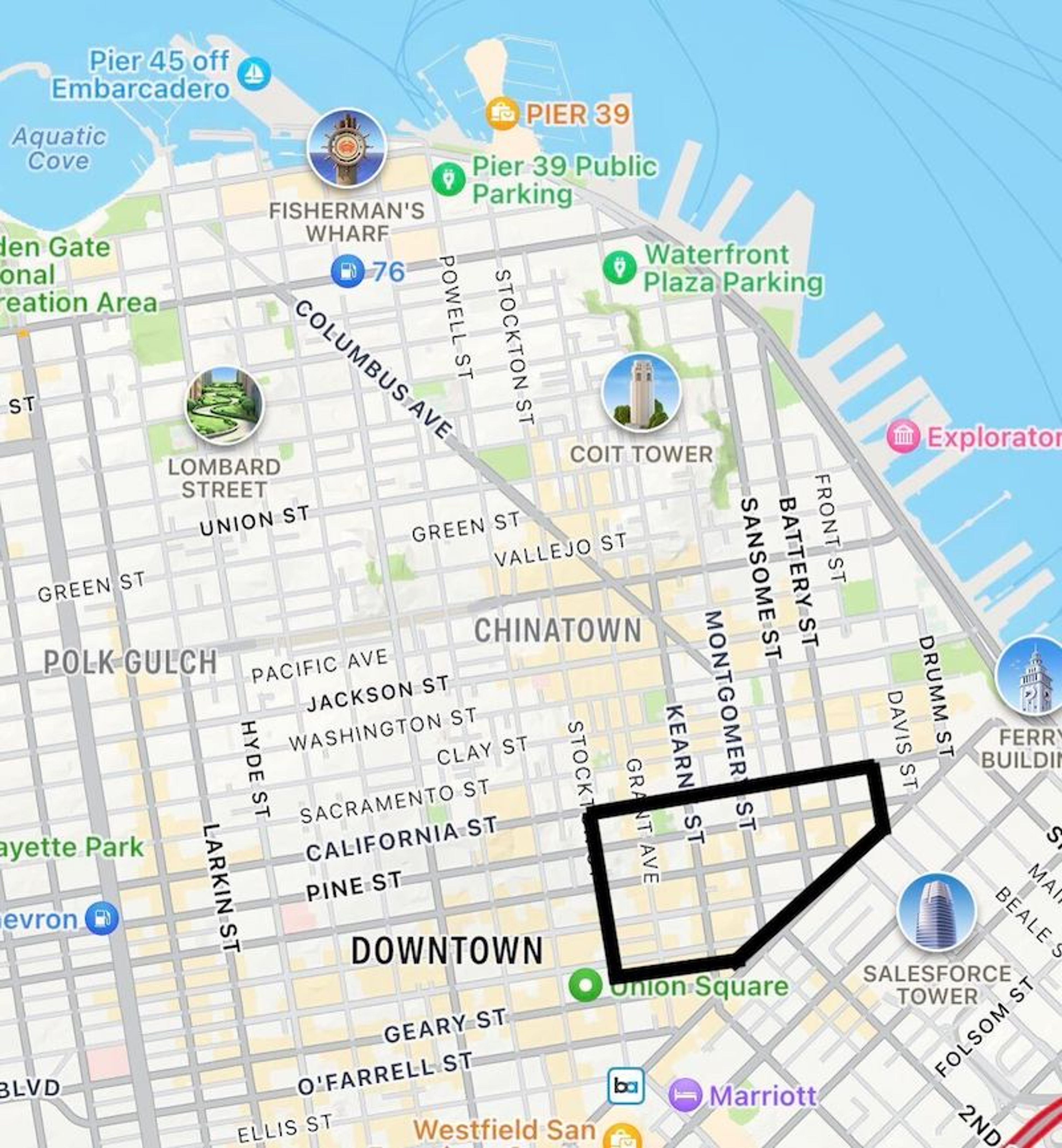
Polygon search in Redis 7.2
We also made significant performance improvements in the Redis data type of sorted sets, commonly used to create gaming leaderboards among its other uses. Our enhancements generate gains between 30% and 100% compared to Redis Enterprise Cloud 6.2.
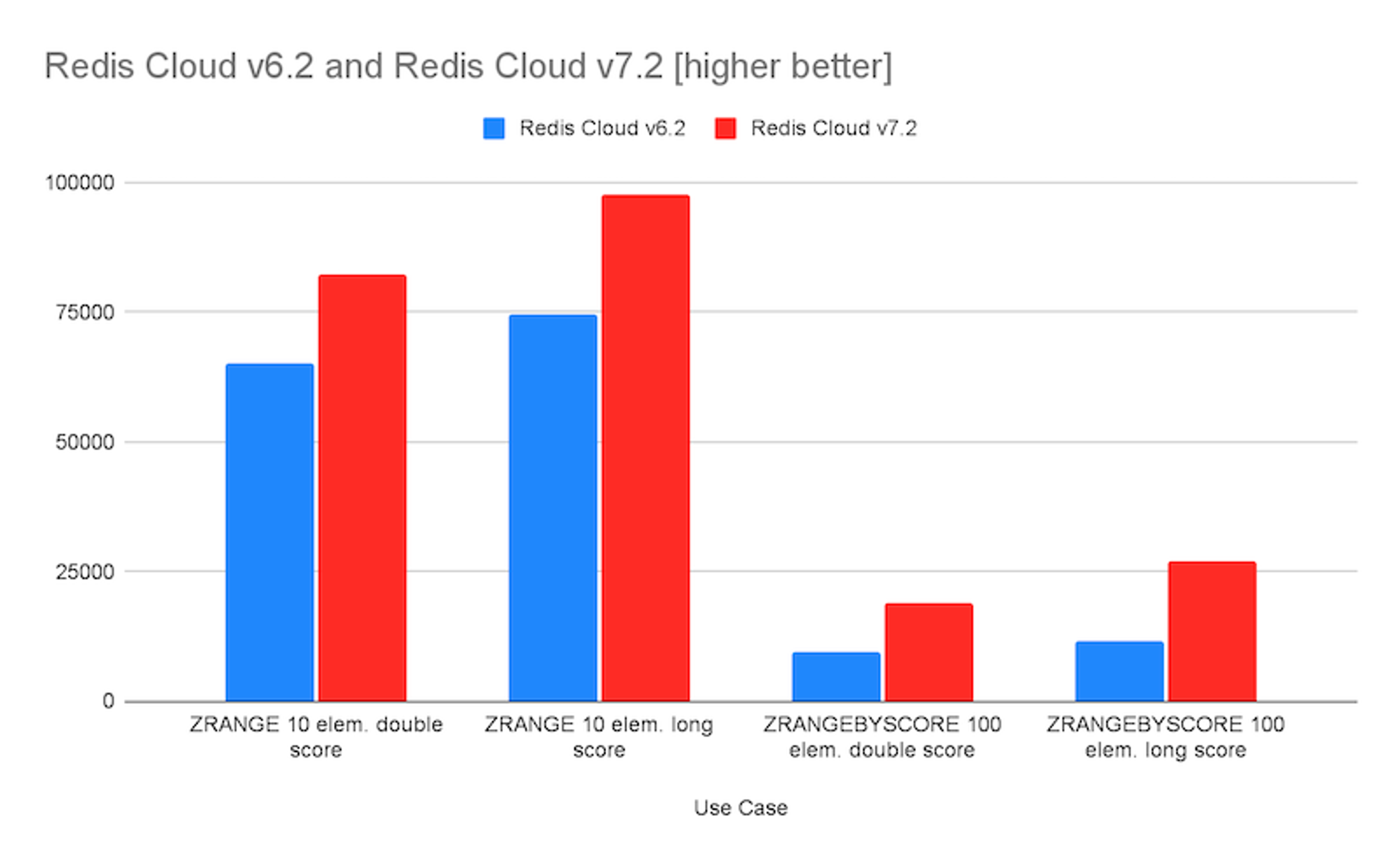
Redis Enterprise sorted sets performance comparison
We made Redis easy to integrate with corporate tools and infrastructure
You can now use Redis Data Integration (RDI), a tool that runs directly on Redis Enterprise and effortlessly transforms any dataset to Redis. We captured the most common use cases and made them available through an interface with configuration, not code.
RDI can take data from a variety of sources (such as Oracle, Postgres, or Cassandra) and functionally turn it into real-time data. Similarly, when the data is no longer “real-time,” RDI can bring downstream changes from Redis Enterprise into the system of record without having to add more code or perform arcane integrations.
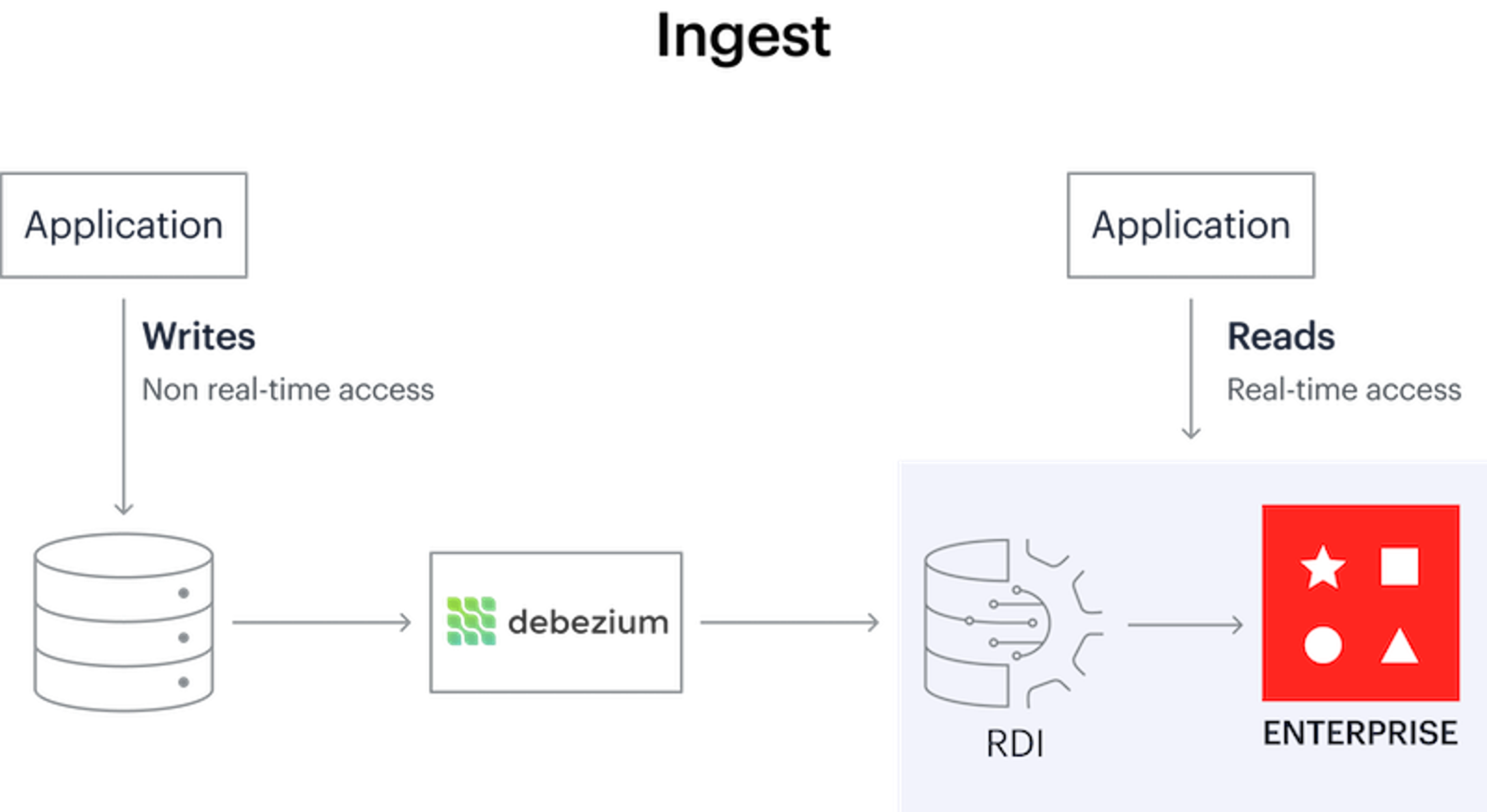
Redis Data Integration architecture
RDI (currently in public preview) streams changes from source databases directly into Redis, where they are further filtered, transformed, and mapped into formats such as JSON and Hash.
Learn how you can try Redis Data Integration and why you want to.
We make it easier and more affordable to scale
Your applications don’t always require top speed for every use case. Sometimes you don’t need to store all the data in memory. It makes more sense–and saves money–to leverage lower cost storage like SSD.
With Redis Enterprise 7.2, we introduce Auto Tiering (formerly called Redis on Flash) with a new default storage engine, Speedb. Auto tiering allows operators to extend the size of Redis databases beyond the limits of physical DRAM using solid-state drives (SSDs). This makes sense for applications with large datasets where heavily used data stays in memory and, maintaining less frequently used data in SSD. Redis Enterprise automatically manages memory based on usage.
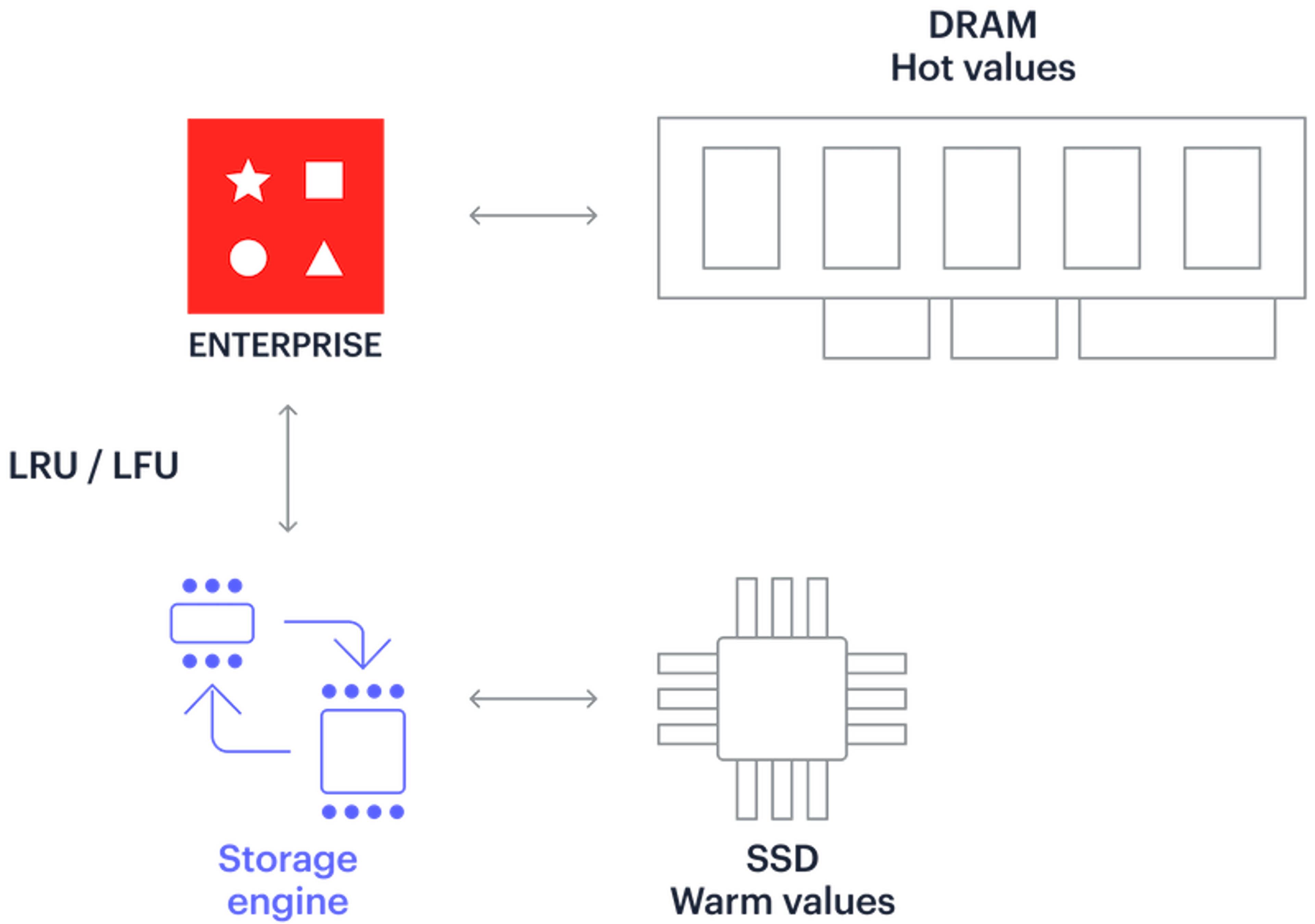
Auto tiering architecture
Auto tiering delivers significant performance improvements in terms of throughput and latency, doubling throughput at half the latency of the previous generation storage engine (RocksDB), and reducing infrastructure costs by up to 70%.
Discover the benefits of Auto Tiering in its detailed announcement.
There are two other innovations in this release that we want to highlight. Operators will find the updated cluster manager (CM) user interface of great help to speed up everyday administrative tasks. Its intuitive interface has features comparable to those of the Redis Enterprise Cloud that reduces learning curves and minimizes errors. For example, with the new CM, you can deploy a new Redis Enterprise database with only two mouse clicks.
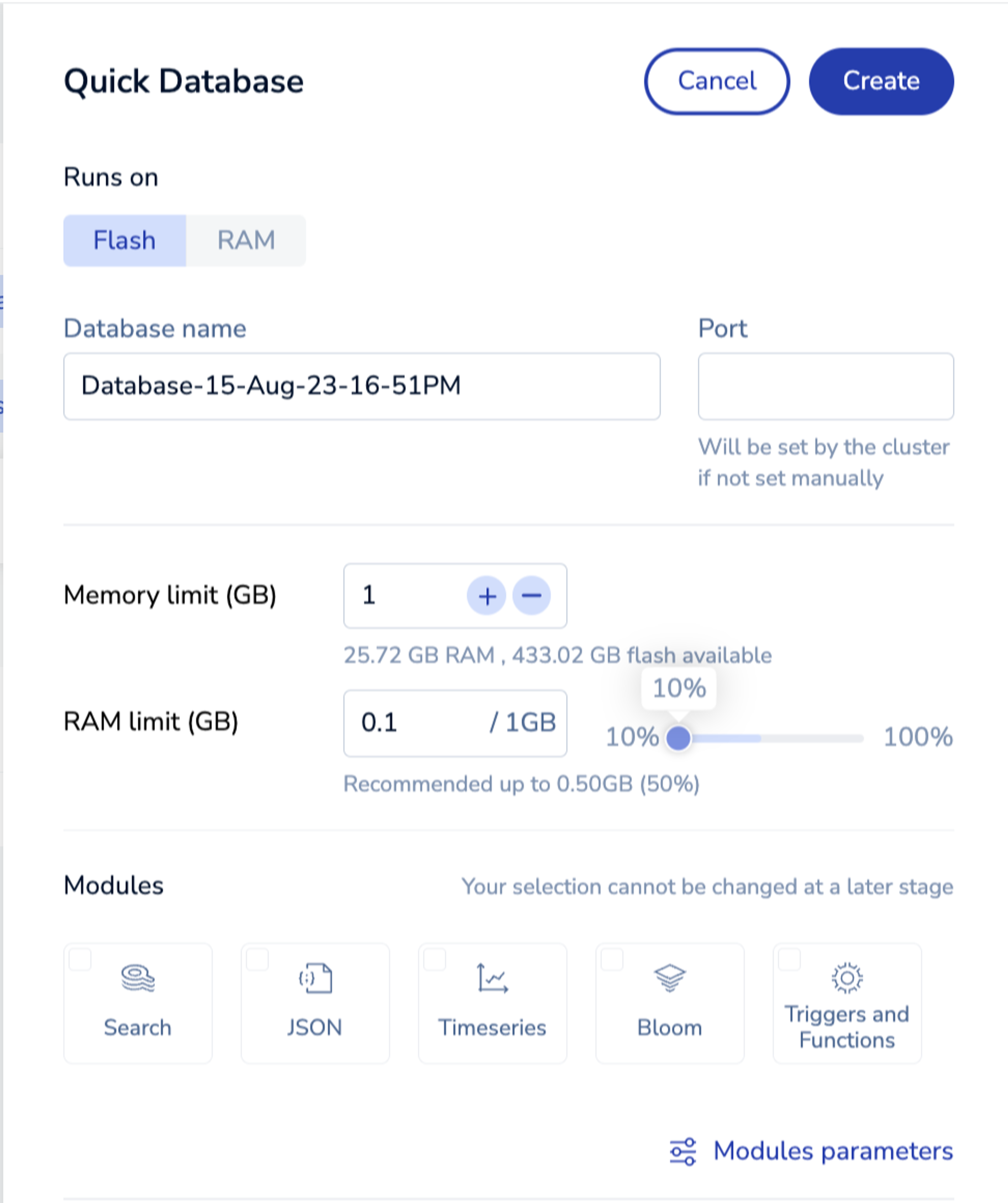
Cluster manager user interface
The other piece of good news that surely will please operators of containerized applications is the general availability of the Redis Enterprise Operator for Kuberneteswith support for Active-Active database deployments. With a few declarative lines in a YAML file, you can simplify several tasks that take time and effort, such as creating geo-distributed databases and removing, adding, and updating participating clusters from an Active-Active database.
Bringing it all together
Many developers prefer to start building on a Redis service in the cloud rather than download it to their machines. We’ve also heard from many customers about the challenges of dealing with separate delivery dates of new Redis releases for their mix of Redis OSS, Redis Stack, and Redis Enterprise instances.
Redis 7.2 is our first Unified Redis Release, and it is generally available today. We are making it easier for developers to build and port code between different Redis distributions. This is a significant boon for operators who want to streamline control over their Redis footprint. Architects will appreciate the freedom to integrate other data stores with Redis.
Our commitment to the Redis community and customers is to release all Redis products and distributions at the same time. This includes Redis OSS, Redis Stack, Redis Enterprise Cloud, Redis Enterprise Software, and Redis Enterprise on Kubernetes.
What’s next?
Redis 7.2 signals our unwavering commitment to make it easier for all of you, Redis lovers, to get started building with Redis, to more easily and cost-effectively run Redis at large scales, and to bring slow data into Redis and make it actionable in real time.
The AI revolution is here, and I cannot overstate its far-reaching effects on our work and lives in general. Our focus on our vector database and vector similarity search, make it a perfect match in helping you harness your Redis skills to jumpstart your AI projects.
We invite you to read more details on the new features in Redis Enterprise 7.2 with the specifics of Auto Tiering, Triggers and Functions, and Redis Data Integration.
Are you ready to try it for yourself? The easiest way is to use Redis Enterprise Cloud, create a free account to try the latest features using Redis Stack, or download the software for a self-managed or Kubernetes deployment.
For the features in public preview, such as triggers and functions, deploy a database on Redis Enterprise Cloud in the fixed tier within the Google Cloud/Asia Pacific (Tokyo) or AWS/Asia Pacific (Singapore) region. For a self-managed experience, visit our download center.
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.