Blog
Auto Tiering Offers Twice the Throughput at Half the Latency for Large Datasets

More and more applications rely on huge data collections – and those applications have to respond quickly. Redis Enterprise 7.2 makes it possible to create super-fast applications with no extra work on a developer’s part. What’s not to like?
Organizations have always depended on their collected data, but those datasets are growing – particularly in analysis-heavy markets such as e-commerce, finance, location-based computing, and high-end gaming. In medical image analysis research, for example, the median dataset size grew by three to ten times between 2011 and 2018.
One reason for Redis’s popularity is that it provides incredibly fast data access. It does so by storing data in memory, so applications can retrieve and manipulate data at the fastest speeds. The more data an application needs to process, the more memory it requires to store the dataset. Still, those applications have to respond at near-instant speeds, even when the data stores from which they draw are huge.
The problem: memory is finite and expensive
When the amount of data an application accesses is measured in terabytes, developers have to cope with the limitations of in-memory processing. As a result, they turn to disk-based solutions to support Redis behind the scenes. Doing so forces the developers to build an entire data management system in their applications, which means they spend their time on extraneous tasks instead of their original goal of providing a performant application.
There has to be a better option. And there is.
Using Redis Enterprise’s auto tiering, developers can extend large volume databases beyond the limits of the existing DRAM in the cluster by using solid state disks (SSD) as part of available memory. Taking advantage of some clever programming on our part, Redis Enterprise identifies what data should be in-memory and what data should stay on SSDs at any given moment, doubling the throughput and cutting latencies in half what it did with previous solutions.
Everything happens automatically. The developer doesn’t need to write extra code or learn another new technology. By combining dynamic RAM with fast external storage, Redis Enterprise makes it easy to use system resources efficiently while still providing fast access to frequently accessed data.
How auto tiering works
Auto tiering automatically manages data. It promotes data that becomes hot into DRAM and intelligently demotes unused data to SSDs. This opens new possibilities for applications that rely on large data collections.
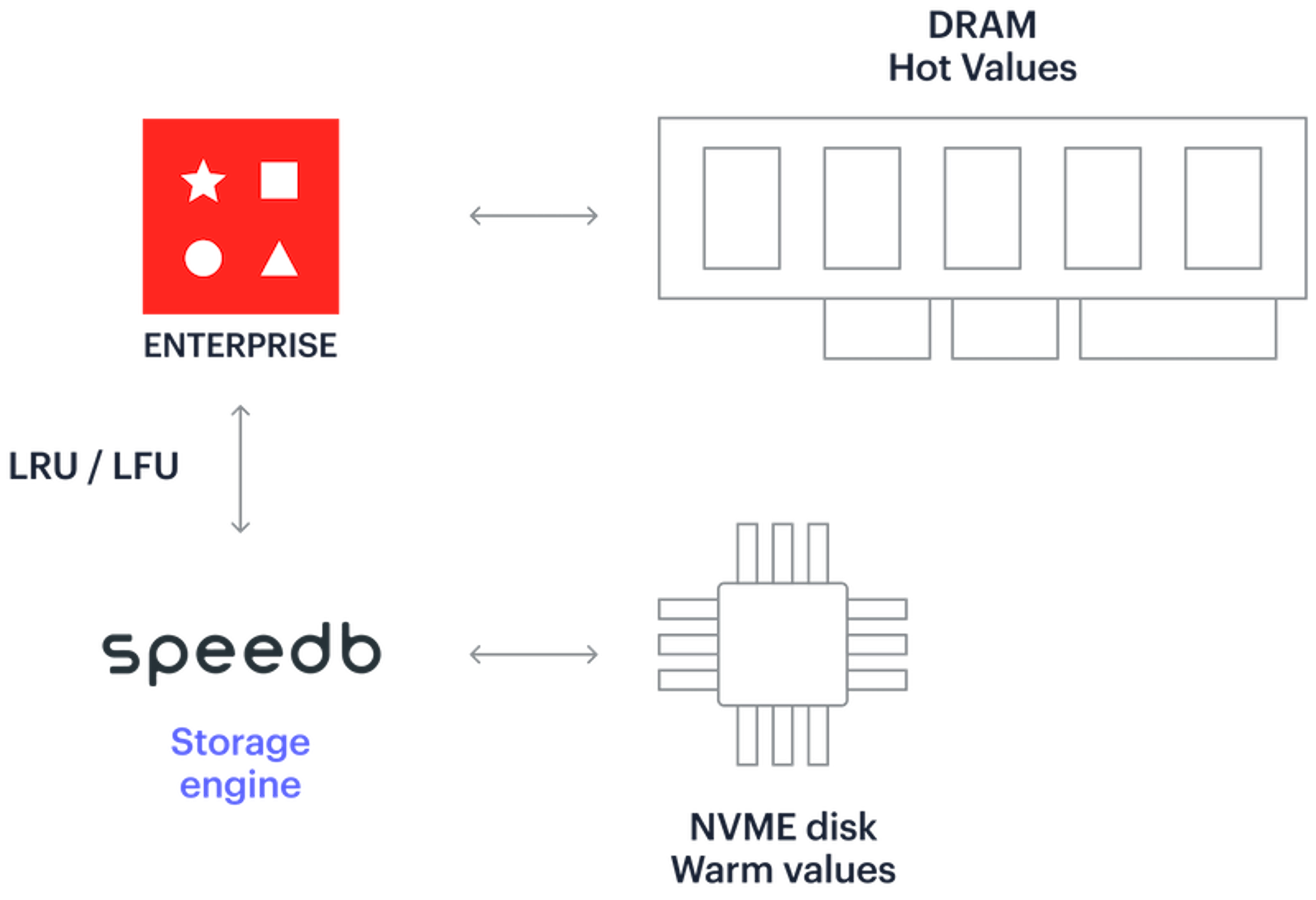
Auto tiering architecture
Fast data on large datasets is not the only benefit. Saving money is another advantage – and a reason that the finance department understands. In-memory storage can be expensive. By offloading less frequently accessed data to SSD, developers can optimize memory usage and reduce the costs associated with high-capacity memory requirements.
Practically speaking, that makes data-heavy applications run faster without extra effort on the developer’s part. It also saves up to 70% in infrastructure costs, compared to deployments only using DRAM. And because auto tiering efficiently and automatically manages data access patterns, you don’t have to spend cycles (computing or human-brain-wise) identifying hot data versus warm data.
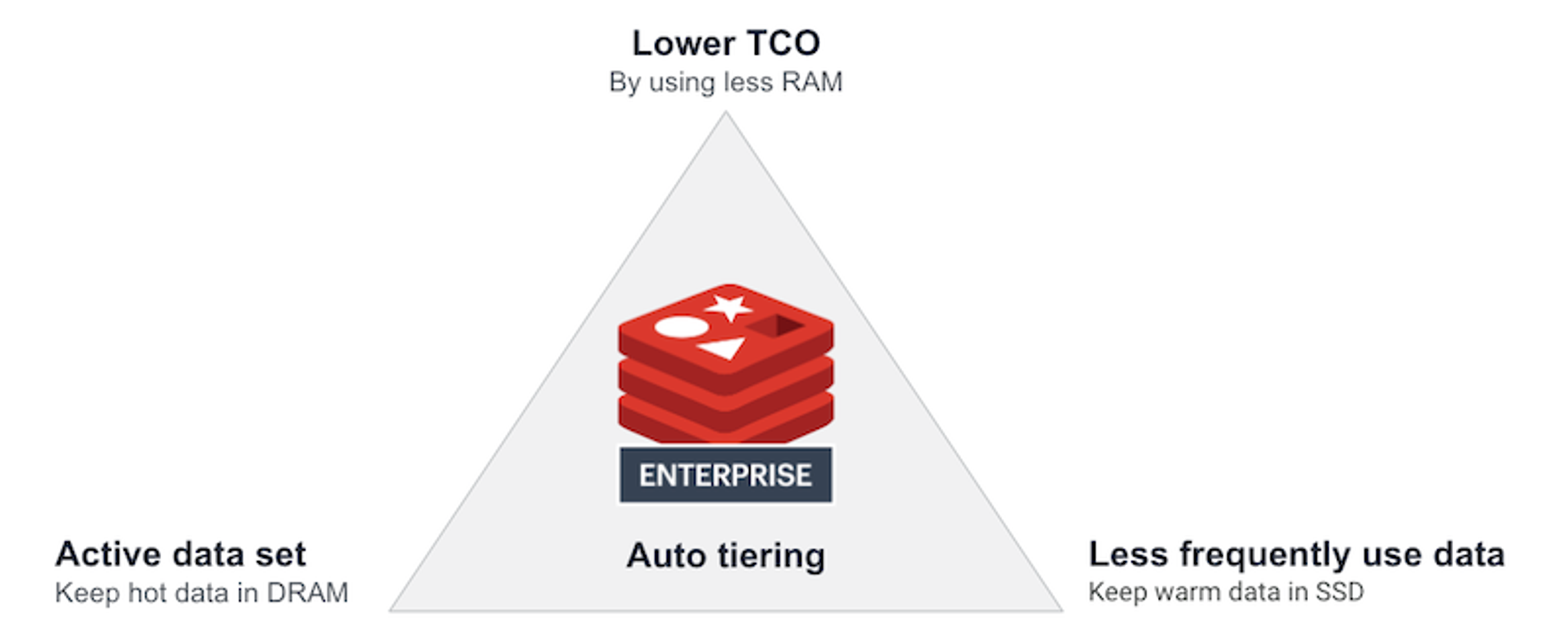
Auto tiering improves TCO by combining DRAM and SSDs
To boost this feature, Redis forged a strategic partnership with Speedb, an innovative key-value storage engine. We integrate its technology as the default auto tiering engine.
With the integration of Speedb, Redis Enterprise achieves a remarkable enhancement in performance, doubling the throughput and cutting latencies in half while using the same resources. This significantly widens the range of use cases that can leverage auto tiering’s benefits. Following this improvement, Redis Enterprise sizing for databases using Auto Tiering got increased to 10k ops/sec per core.

Double the core throughput with auto tiering
How fast is fast?
Sure, we doubled the throughput, and we cut latencies in half, but numbers tell only part of the story. Examples matter.
The following graphic shows a sample of the performance evolution of auto tiering in real workload scenarios. The blue bars represent Redis Enterprise 6.4 with the previous storage engine (RocksDB), and the red bars represent Redis Enterprise 7.2 with Speedb. For infrastructure, we used I4i.8xlarge AWS instances to host a 1TB database on 10 shards, replicated for high availability for a total of 20 shards, serving 1,024 clients.
To simulate the most standard Redis’ use case, we defined two different payloads, 1KiB and 10KiB, over a configuration with 20% DRAM and 80% SSD with three possible use patterns, balanced read/write (1:1), heavy read (1:4), and heavy write (4:1). In both scenarios we measured the throughput in operations per second, and the corresponding latency. The following charts show the results.
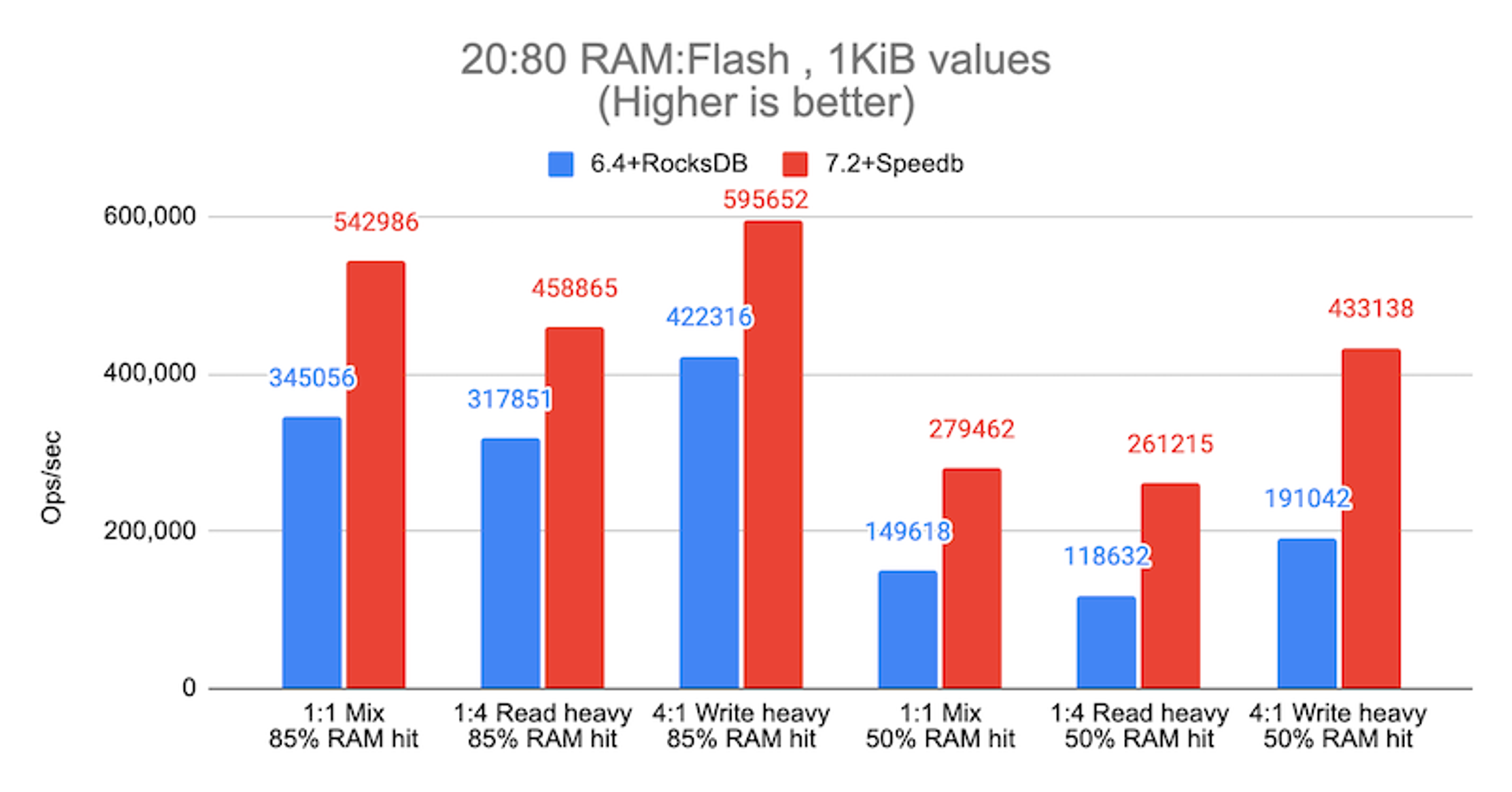
Auto tiering throughput results with 1KiB values
Compared to RS 6.4 (RocksDB), RS 7.2 (Speedb) improves:
- 85% hit rate: 1.4x to 1.6x more ops/sec, while reaching up to 2.4x lower latencies
- 50% hit rate: 1.9x to 2.3x more ops/sec, while reaching up to 3.8x lower latencies
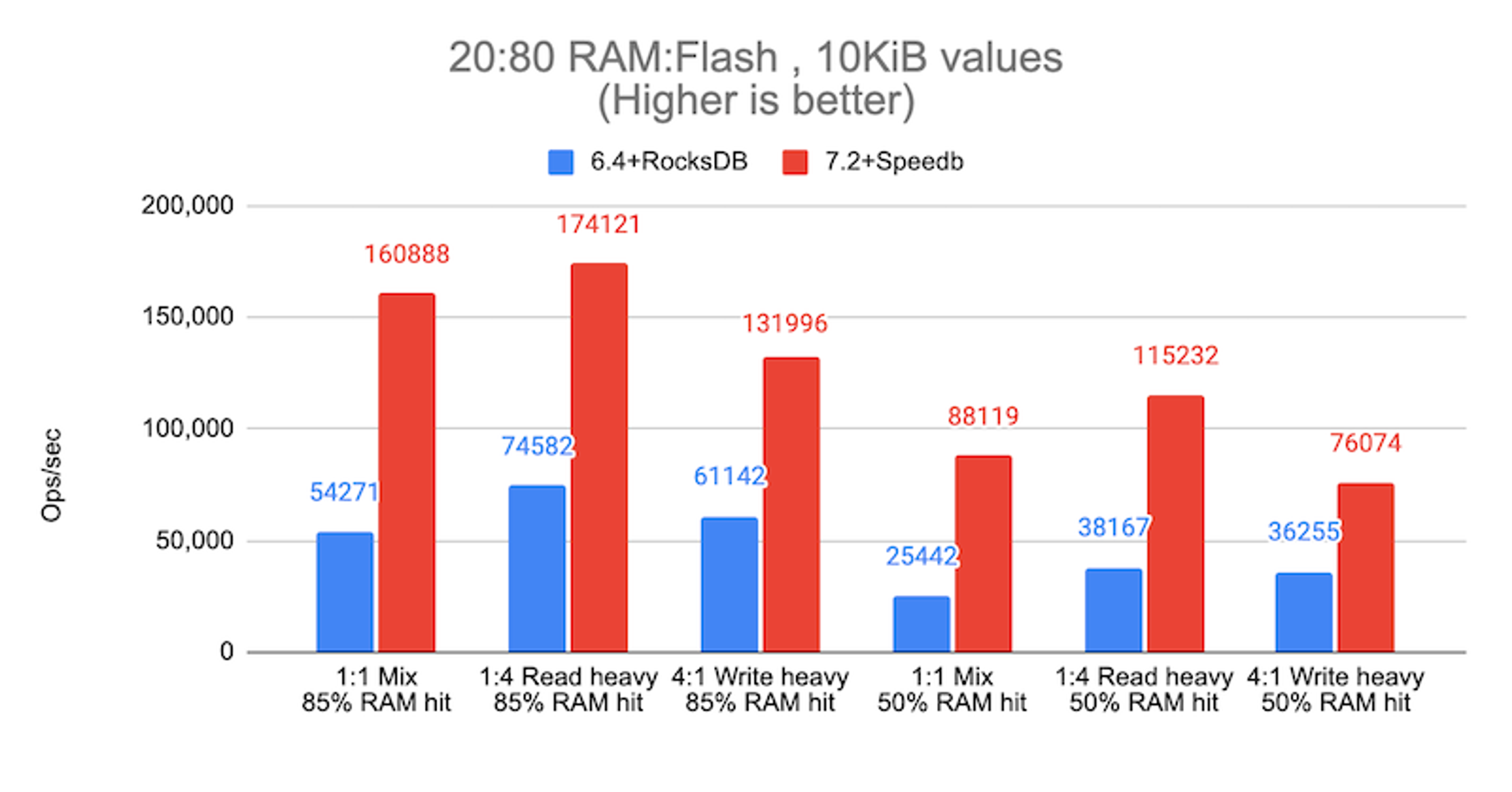
Auto tiering throughput results with 10KiB values
Compared to RS 6.4 (RocksDB), RS 7.2 (Speedb) improves:
- 85% hit rate: 2.3x to 3.0x more ops/sec, while reaching up to 3.0x lower latencies
- 50% hit rate: 2.1x to 3.5x more ops/sec, while reaching up to 3.5x lower latencies
In all cases, Redis Enterprise 7.2 with Speedb has a better throughput, which means faster applications and less infrastructure needed to sustain this level of performance.
Where auto tiering makes a difference
Auto tiering is particularly applicable in scenarios that involve segregating data into hot data and warm data. One example would be banking applications that need to access up-to-the-minute data and historical data.
Let us take a closer look at a mobile banking application example.
Nowadays, everyone has a banking application on their mobile device. Users log into the application, get their balance, check the last transaction, and obtain other relatively small and focused information. Everyone expects this process to be smooth, simple, and instantaneous. That data is our hot data, which resides on DRAM in the Redis Enterprise database.
Less frequently, users want additional information, such as a record of old transactions–perhaps a tax document from two years ago. It needs to be accessible but data access speed is less critical. This dataset is our warm data and can be kept in SSDs.
Speed matters in other industries, too. For instance, gaming applications have strict latency requirements. Plus, by their nature, games are trendy. Over time, a gaming company accumulates user data, which is stored in a profiles database. But not all users are active users. With auto tiering, the active users’ profile information can reside on DRAM, while information about the rest of the users resides on the SSD.
What’s next?
Our auto tiering product page goes into more technical details. Or if you’re ready to use it today, you can try Redis Enterprise 7.2 with auto tiering by creating a database on Redis Enterprise Cloud in the free or flexible plans or deploying a self-managed instance from our download center and following the auto tiering configuration guide.
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.