Blog
Learning agents with Redis: Feedback-driven context engineering for robust stochastic grounding





Abstract
Large Language Models (LLMs) have demonstrated remarkable capabilities in querying and interpreting unstructured text, but applying them to extract information from large-scale structured data remains expensive, error-prone, and often inefficient. This work introduces a system that combines LLMs with Redis-backed learning agents to enable accurate, scalable, and self-improving question answering (QA) over complex datasets. The architecture leverages a multi-agent system orchestrated through semantic caching and a multi-tiered caching strategy where results, executions and guidances are stored in a Redis-backed high-throughput low-latency store. The proposed system systematically learns from any user feedback or errors that occur during the course of query execution and through reflection learns nuanced understanding of business terminology and rules. These interactions, errors, and feedback through memory reflection offer stochastic grounding. We refer to such grounding as guidances for future queries. Additionally, successful executions are stored and later sampled to handle similar user questions. The executions and guidances become the basis of context engineering needed to enrich the context with critical information so that future queries incur fewer errors and retries. We validate our approach on financial and insurance datasets, highlighting use cases such as risk scoring and customer segmentation. Through iterative learning from both individual user sessions and collective behavior, the system demonstrates improved time-to-insight and query accuracy.
In short:
Learning Agents = stochastic grounding through feedback + context engineering + memory reflection
Introduction
The application of Large Language Models (LLMs) to structured data querying presents both opportunities and challenges. While LLMs have shown state-of-the-art performance in natural language processing tasks1, their deployment in structured query generation especially for tabular data remains hindered by high computational cost, failure rates in complex scenarios, and lack of long-term memory or reuse mechanisms. These limitations are particularly acute in domains such as finance and insurance, where analytical workflows involve repeated, nuanced queries over large-scale datasets.
We propose Learning Agents with Redis, a Redis-backed architecture for LLM-driven QA over tabular data, which mitigates these challenges through agent-based orchestration, multi-tiered caching for carefully engineered contexts, stochastic grounding from feedback and memory reflection. By leveraging execution traces, user feedback, and guidance from failed attempts, the system avoids redundant computation, lowers latency, and improves future performance through learned priors. Redis2, a low-latency key-value store, is utilized as the backbone for both execution and guidance caches, enabling efficient storage and retrieval of intermediate results and agent interactions.
The system comprises specialized agents including a Data Summary Agent to introspect and understand the data schema, a Filter Agent for query generation and execution, a Guidance Agent for synthesizing correction patterns, best practices, preferences and, an Interpretation Agent for result summarization all coordinated by an orchestrator. These agents collectively implement a feedback-driven loop that transforms failed executions into instructive guidance and successful executions into reusable templates. Over time, the system adapts to user preferences and query distributions, allowing for personalized and crowd-informed improvements a characteristic aligned with meta-learning paradigms3.
We demonstrate the effectiveness of our approach using real-world datasets, such as the Portuguese bank marketing dataset4 and the Insurance claim dataset5, showcasing diverse analytical queries and their progressive refinement through cached knowledge. The results highlight the potential of Redis-augmented agentic systems to make LLM based retrieval systems continually smarter and thereby more efficient.
Literature review
Semantic caching is a growing optimization strategy in Retrieval-Augmented Generation (RAG) and LLM-powered systems. It enables retrieval of responses based on semantic similarity, rather than exact textual match by leveraging embeddings and vector similarity search. This approach reduces costly LLM API calls and accelerates response time in QA workflows6. A recent paper, Semantic Caching of Contextual Summaries for Efficient Question-Answering with Language Models7 introduces a method to cache intermediate contextual summaries via embeddings. Their approach yields about 50–60% reduction in inference cost while preserving answer quality across QA datasets8 further improves cache effectiveness using fine‑tuned domain-specific embedding models, alongside synthetic training data to boost precision and recall in similarity searches9. In Building LLM Agents by Incorporating Insights from Computer Systems (Zhang et al., Apr 2025), the authors advocate for cache-style memory mechanisms within LLM agents, drawing inspiration from memory‑hierarchy design in computer systems (e.g., registers, cache, main memory). They argue that caching key agentic information and exploiting locality principles can significantly optimize performance10.
The Vicinagearth survey ‘A survey on LLM-based multi-agent systems: workflow, infrastructure, and challenges’11 on LLM‑based multi-agent systems reviews memory storage, reflection, and modular memory practices including summarization, hierarchical compression, and embedding‑based retrieval as foundational techniques for efficient agent-driven reasoning. They emphasize how structured memory enables agents to maintain context and adapt to evolving situations. The study "RecallM" explores methods of achieving the effect of long-term memory, highlighting the importance of continual learning, complex reasoning, and learning sequential and temporal dependencies for LLM-based chatbots12. Empirical investigations into memory management strategies, particularly concerning the addition and deletion of experiences, have revealed their impact on the long-term behavior and performance of LLM agents13. Augmenting LLMs with external memory has been shown to improve performance on tasks requiring long-context recall, suggesting that such architectures can effectively handle contexts much longer than those seen during training14.
With respect to extracting information from tabular data, seminal work such as TaBERT (Wang et al., 2020) introduces a pre‑training approach that jointly models tabular and natural text, significantly improving performance on tasks like WikiTableQuestions and text-to-SQL datasets (e.g., Spider). TaBERT powers semantic parsers capable of understanding questions about structured data in natural language15. Additionally, the awesome‑tabular‑LLMs collection16 highlights modern techniques such as StructGPT, TableQAKit, and DTT that integrate prompting, neural semantic parsing, and decomposed reasoning methods to enhance LLM performance on table-based QA and transformations . The recent paper ‘Cost‑Efficient Serving of LLM Agents via Test‑Time Plan Caching’17 introduces “plan caching” which stores structured plan templates derived from agent execution traces and adapting them to new tasks via lightweight matching and templating. This method reports ≈46% cost savings while maintaining performance in agentic applications. In RecMind18, an LLM-powered agent, leverages planning to break down complex recommendation tasks into manageable steps, utilizing memory and tools to enhance functionality.
Our contribution
The Learning Agents with Redis framework synthesizes these threads into a unified, practical architecture for tabular QA:
- While prior work on memory and plan caching emphasizes general agent architecture and computational reuse, this system is specialized for structured data domains
- The system introduces multi-agent orchestration with components specialized for summarization, filtering, guidance generation, and interpretation, creating a feedback-driven loop for stochastic grounding
- The system leverages meta-learning principles to incorporate business logic and semantic correctness through crowd-learning resulting in improved time-to-insight
- Unlike traditional semantic caching, the proposed system combines both execution-level caching (storing runnable query code and results) and guidance-level caching (capturing failure modes and user feedback), mediated by Redis, to support dynamic query generation and adaptation over time.
- Queries stored in the Execution Cache from past successful executions can be evolved based on parameters
Methodology
In order to reliably query large volumes of data using Large Language Models (LLMs), we propose a Redis-backed multi-agent architecture. The system is designed to incrementally learn from both successful and failed attempts through semantic caching, structured feedback, and agent coordination. Our approach is rooted in three core design principles:
- Cache results with TTL
- caching entire executions in Redis to eliminate expensive LLM calls
- cache method level calls
- Cache successful execution queries in Execution Cache for each question
- create queries to answer user question
- get user feedback to improve queries or execute if it looks OK
- successful executions get stored in the Execution Cache
- execution might fail, collect the failures into an ErrorHistory to improve query creation on the next attempt
- Execution Cache creates a new entry for each successful execution so that we can use various sampling strategies to find suitable candidates for future questions
- Cache guidances in Guidance Cache for each question
- once execution is successful, create guidances in Guidance Cache
- the guidance agent summarizes ErrorHistory as guidances for future executions
- the guidance agent also takes into account any user feedback that was provided to clarify business logic and incorporates this into the Guidance Cache entry
- unlike the Execution Cache, the Guidance Cache only stores one entry per user question where new guidances update the existing entry by reconciling and updating the Guidance Cache entry
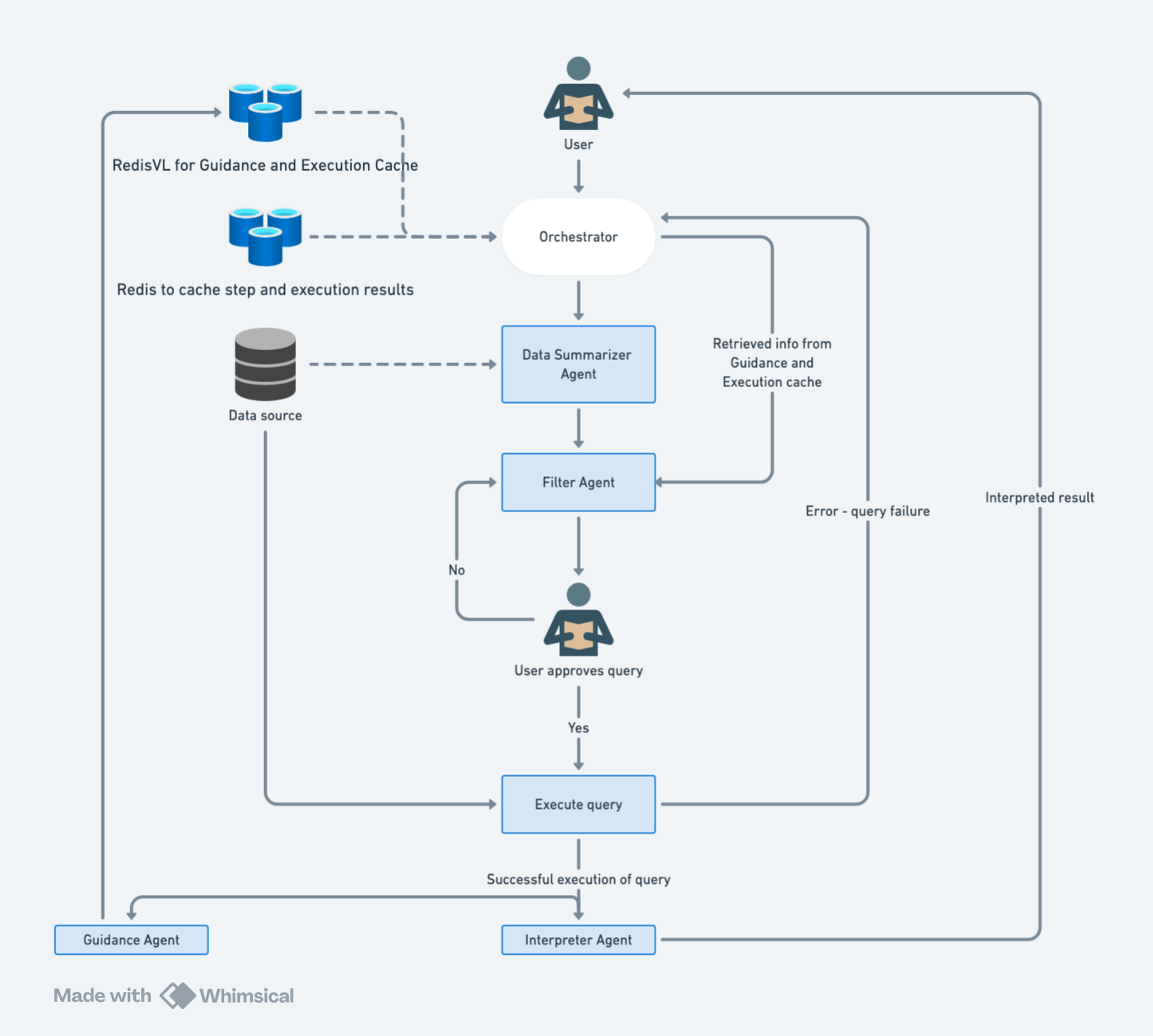
Learning Agent
Such a system learns from your feedback but also collectively learns from the crowd so that future users can leverage the wisdom of those before them. Such a system of caches stores learned population-specific guidances that is rich in business know-how and logic that can potentially even eliminate the need for LLM fine-tuning. Ideally, we want to see the following behavior as shown in the chart below.
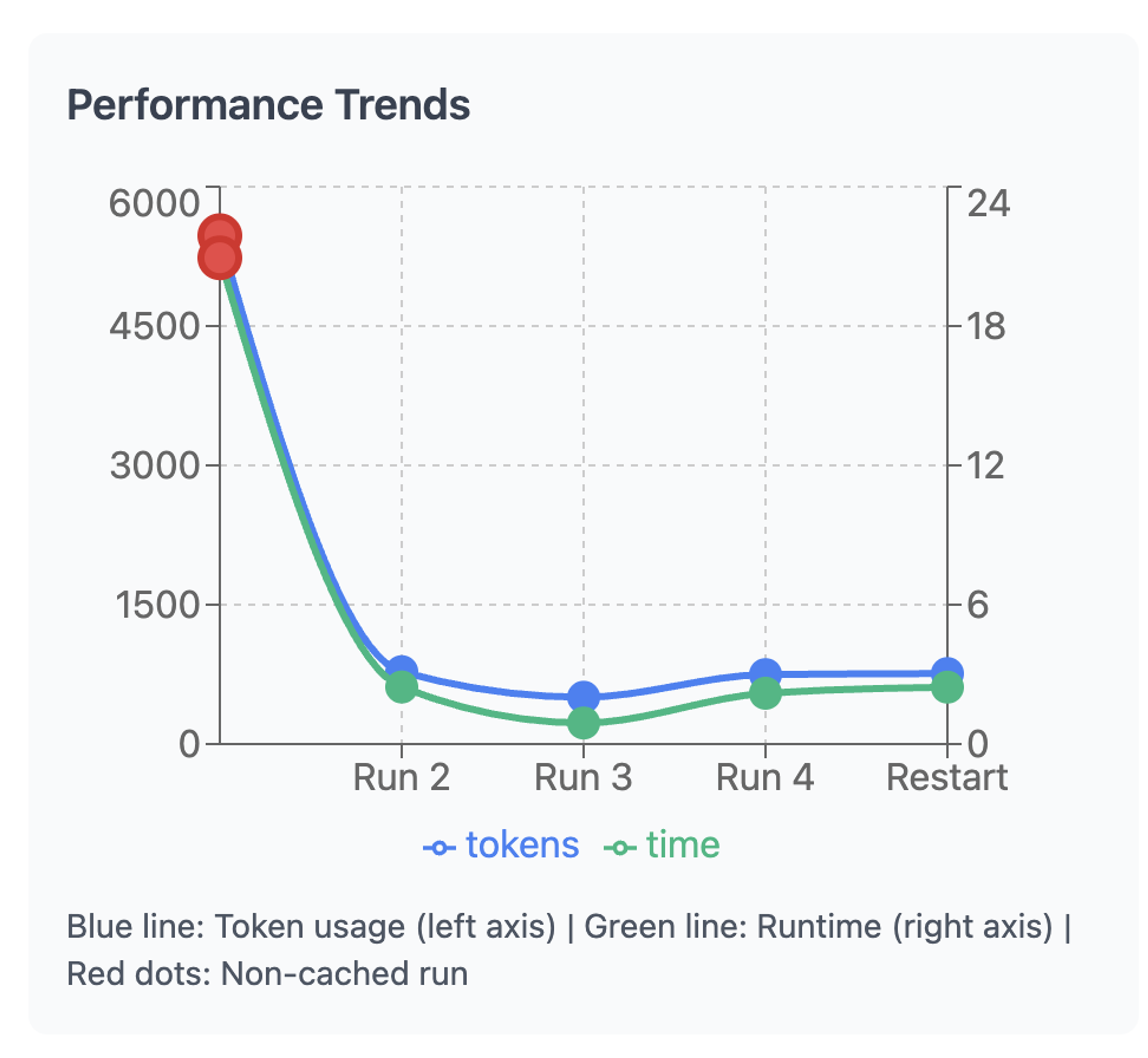
Token reduction over subsequent runs
Redis as the agentic memory layer
The architecture is composed of several Redis-backed agents, orchestrated through a planner agent. Redis serves as the memory layer for short-term memory and persistent memory:
- Redis: Short-term memory for storingstep results during the agent execution
- RedisVL: Serves as a persistent memory of past executions
- Execution Cache: Successful execution queries and their results.
- Guidance Cache: Summarized learnings from errors.
This enables both exact reuse and adaptive prompting, effectively reducing inference tokens and improving latency over time.
Agent components
Each agent is briefly described below:
Orchestrator Agent
Serves as a lightweight planner and coordinates all agent interactions and manages the control flow of the QA task.
Data Summarizer Agent
This agent inspects the dataset and provides statistical summaries of columns (e.g., value ranges, distributions) and also textual descriptions of the columns based on the name and the values contained in those columns. The user should ideally aid this summarization by describing and disambiguating the columns. If the data schema and/or the data does not change often, consider setting an appropriate TTL so that the results of this step are cached and not frequently re-executed.
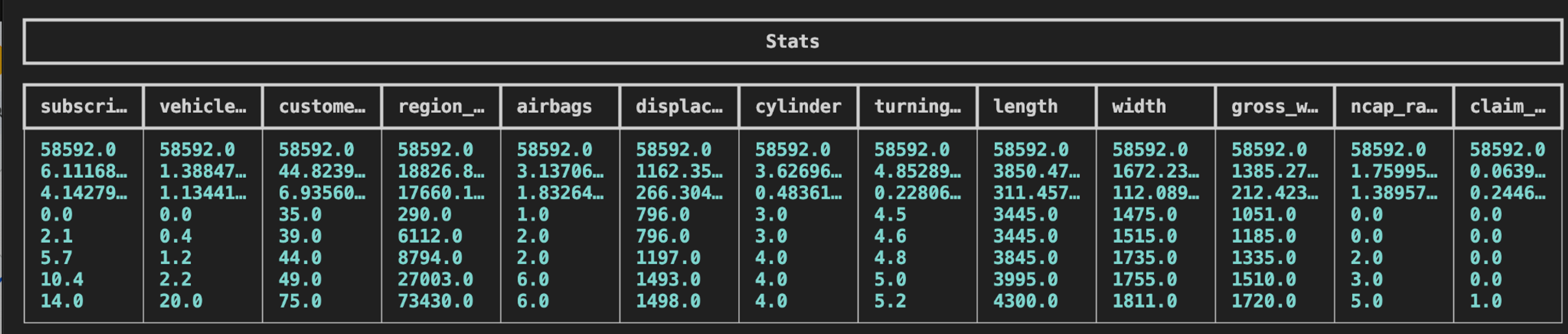
Data Summarizer Agent
Guidance Agent
The Guidance Agent observes failed executions and any user feedback if provided and summarizes them into meaningful strings. These strings represent the observations of the failures, its causes, and instructions to avoid them in the future. The guidance strings are written to the Guidance Cache at the end of successful execution of a query. If guidance already exists for a question, the entry is updated by reconciling the new guidances with the existing guidances. They are retrieved for similar questions in future executions from the Guidance Cache. A predefined threshold (hyperparameter) is used here for retrieval which is lower than the threshold used for the Execution Cache. It is possible that irrelevant guidances may be retrieved, as limitation of embedding-based retrieval systems, however the LLMs are instructed to use guidances if they are appropriate and relevant. Some experimentation is needed to balance true helpful guidances matches against false positives that may pollute the context.
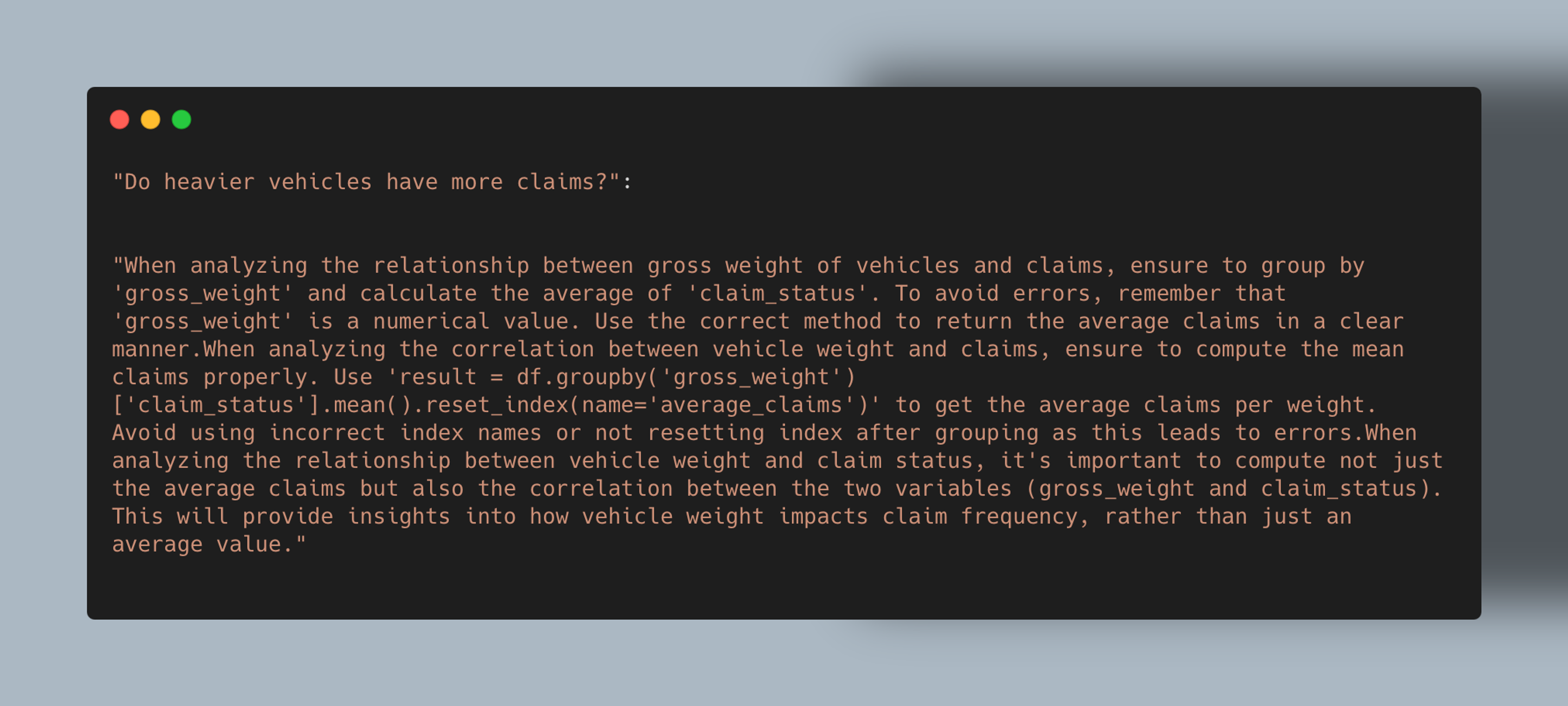
Example of a retrieved guidance
Filter Agent
The Filter Agent is responsible for generating and executing queries. It takes as input:
- A user question
- Column and data summaries
- Possible retrieved guidance strings from the Guidance Cache
- Possible reuse or adaptation of past executions from the Execution Cache
- Error history and retry count since this agent is called in a loop until successful completion or until a condition ‘max_retries’ is met.
- It is helpful to prune large error histories to avoid endless loops
Using this context, prompts are created for the LLM to generate executable queries. If the execution fails, the agent updates the error history, and the orchestrator retries with improved context.
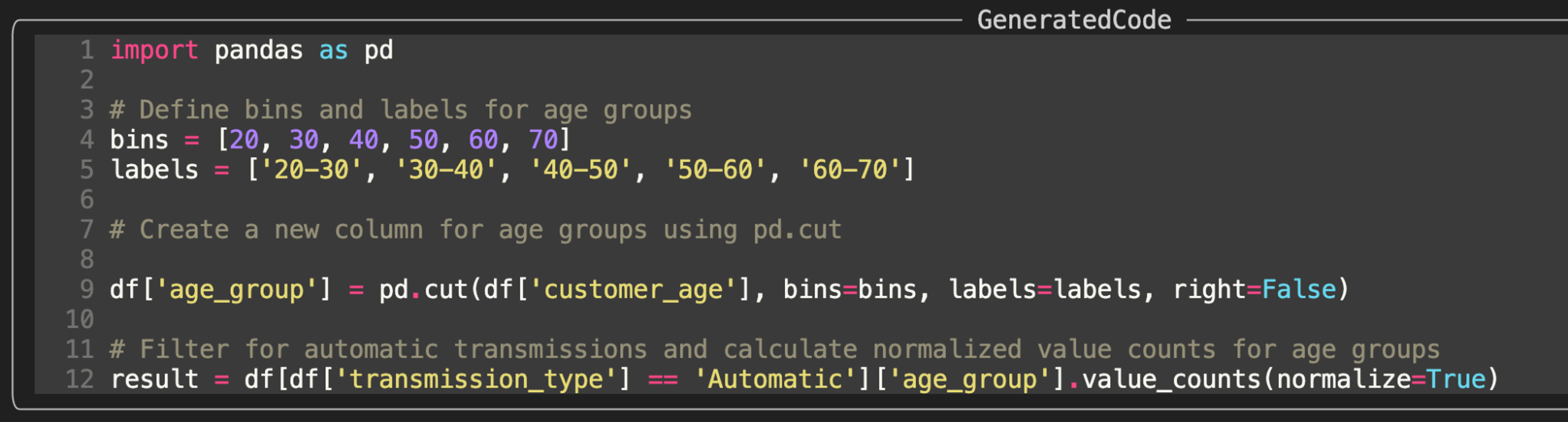
Example of a generated query
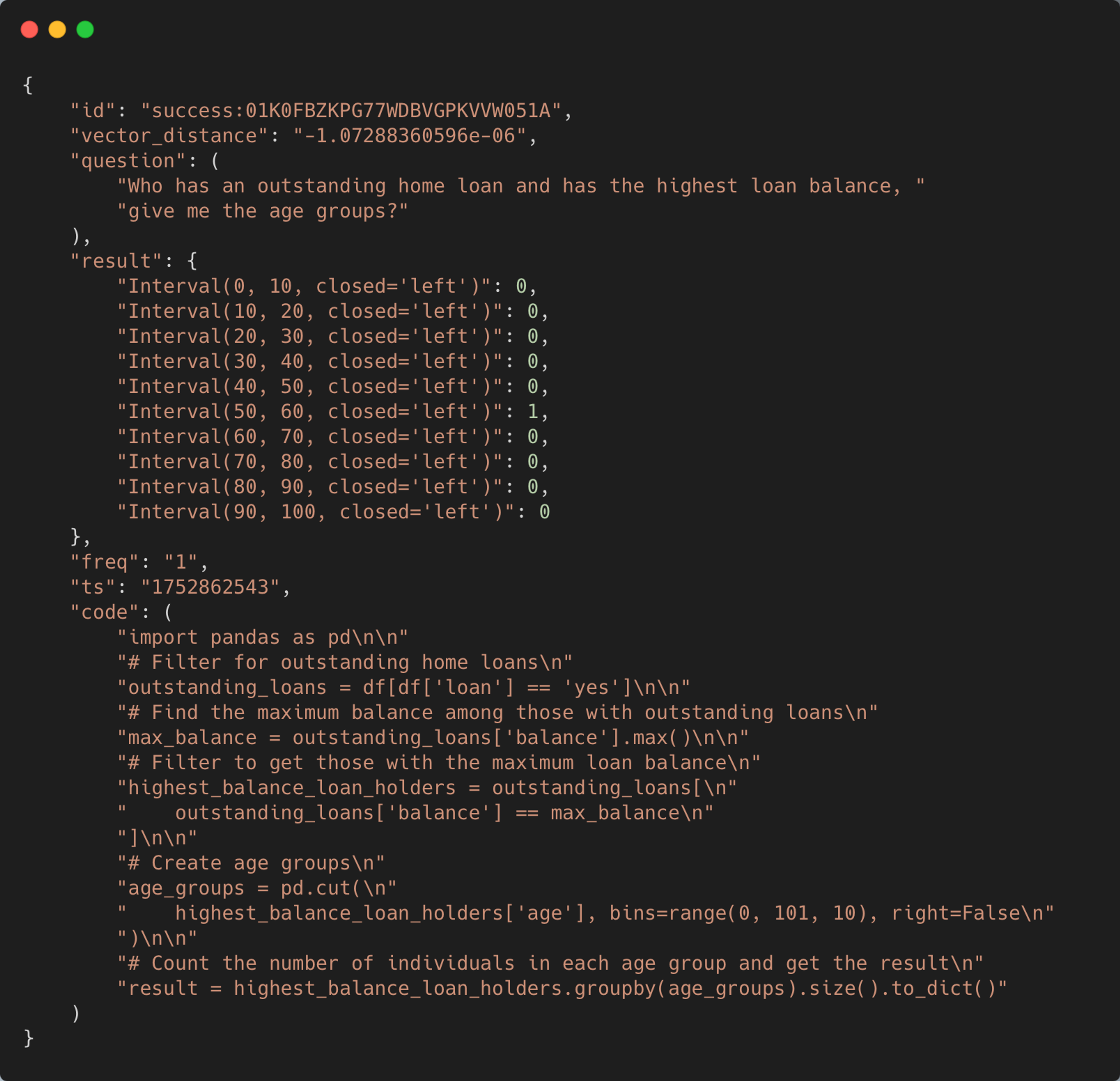
Example of a retrieved execution from the execution cache - this one has only a single execution corresponding to a user question
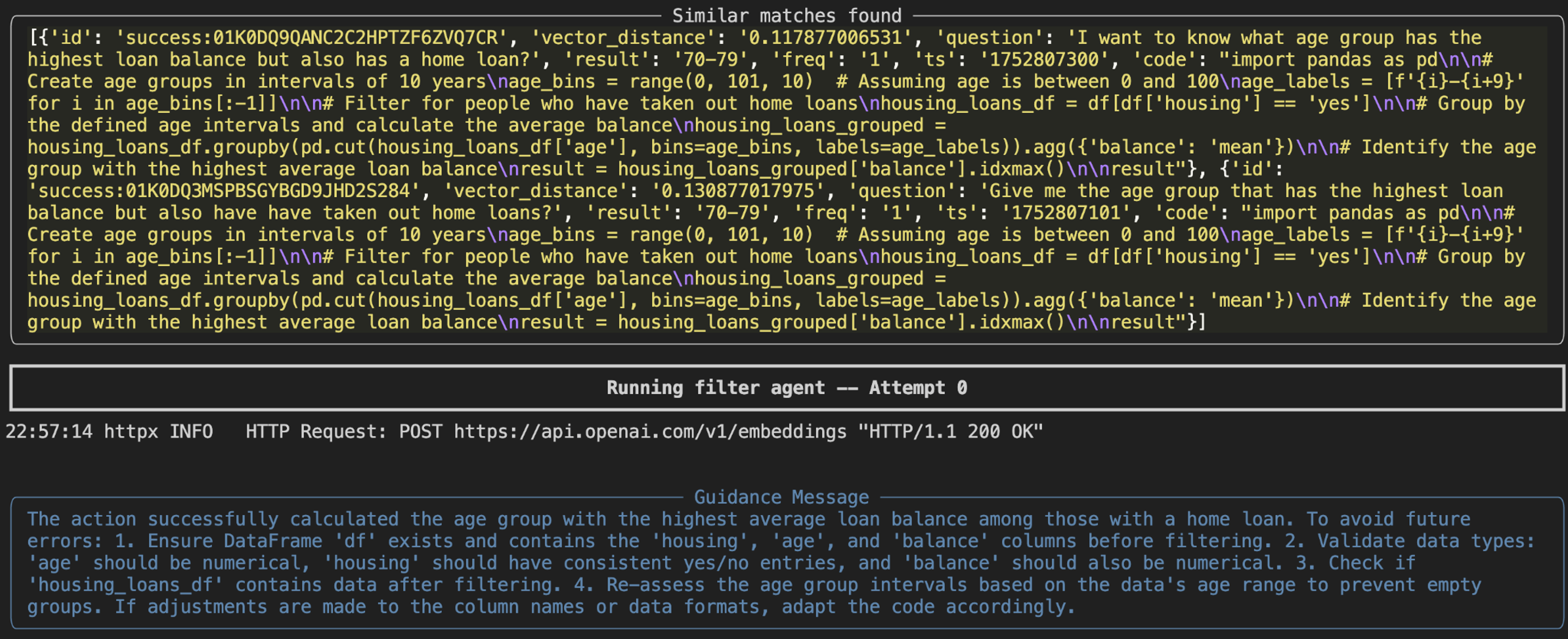
When there is not an exact match these executions may have to be modified by the LLM for the current question
Interpretation Agent
After a successful query execution, the results may be scalar or a dataframe which in itself may not be particularly useful to the end user since users of decision making tools are looking for insight as opposed to data. The Interpretation Agent interprets and translates the result within the context of the original question into a human-readable summary. It returns this to the user and updates the system state with a final confirmation of success.
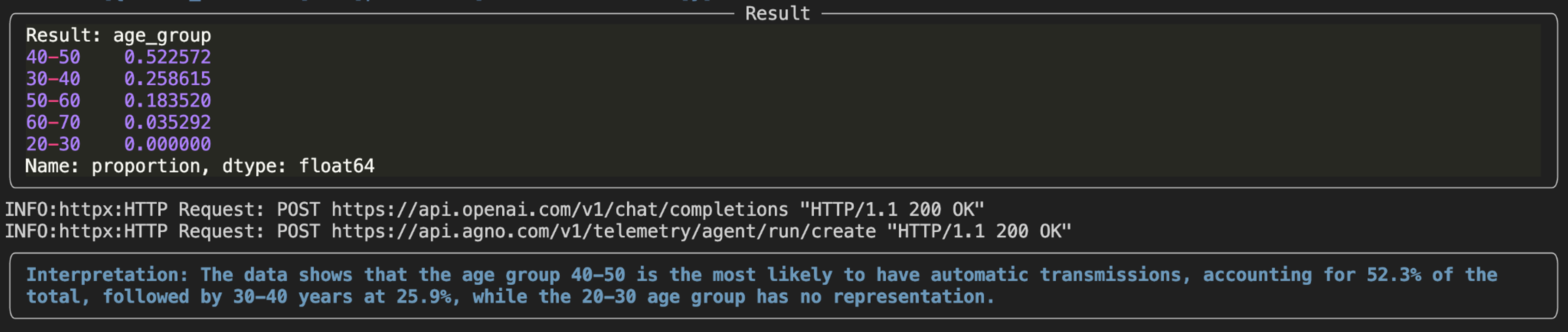
Interpreted result
Putting it all together
The execution flow, which can be split into 2 stages, is summarized below.
Cache population stage
- When a new user question comes in and no match is found (irrespective of TTL), a query is created for the user question
- Data Summarizer Agent provides a summary of the columns
- Filter Agent generates a query which may or may not succeed.
- Error handling and retry: If the query fails (e.g., due to syntax or semantic mismatch), the system logs the error and retries with improved prompts.
- Query success: Once the query succeeds, the result is stored in the Execution Cache, and the related error history is converted into a guidance entry in Guidance Cache.
- Execution Cache: caching of successful queries that can be adapted for similar queries
- for any given query, all previously successful executions are stored in the Execution Cache because they represent variations in user preferences
- this provides a distribution of successful executions to sample from for future user requests
- Guidance Cache: guide query creation for all future queries that are similar
- error history is converted into a guidance entry in Guidance Cache
- this uses reflection to learn from failures that are either
- in the form of user feedback for preferences
- in the forms of user feedback for semantic errors or errors in business logic, e.g. feature A instead of feature B to compute the metric
- syntax errors in the code such as applying string operations to numerical data
- These help with progressive query refinement
- Execution Cache: caching of successful queries that can be adapted for similar queries
- The Interpretation Agent interprets the data returned back from the query and returns the result to the user.
Cache retrieval stage
- Given a user question with an exact match cache hit and t < TTL: retrieve result directly from Redis.
- this can be cached results of individual steps
- or the cached end-to-end result
- Given a user question with t > TTL
- the Orchestrator checks to see if there is an exact match (exact_threshold) in the Execution Cache, if yes execute it with user permission
- if the Orchestrator determines that it is not an exact match but it is similar (based on a similarity threshold) - use prior query and guidance as a template for adaptation
- find entries in theExecution Cache and possibly also in the Guidance Cache
- if available, use the Guidance Cache entry to guide query creation
- use this retrieved successful execution for the match as a template to guide query generation for the current user question
- This builds upon the hypothesis that for complex queries, it is easier to modify an existing query than to create an entirely new query
Learning from feedback
Learning forms an important aspect of this system, and it does so using feedback from the user and its own experiences. A few things to note:
- user acceptances validate an execution and makes it available for reuse. Executions that receive more acceptances are more likely to be sampled again in the future.
- rejections update error history and guide refinement of query generation.
- frequent failure patterns are abstracted into guidance templates via the guidance agent.
This approach aligns with the principles of meta-learning, allowing the system to generalize improvements across users and questions.
Results
The system was evaluated on two datasets described below, selected to cover distinct domains and for the non-trivial complexity inherent in their features.
Dataset 1
This dataset, derived from a Portuguese bank’s direct marketing campaign (UCI Machine Learning Repository ) contains approximately 45,000 data points. It includes information on telephone interactions and client demographics, such as age, job, marital status, education, and account details. It is widely used19 for predictive analytics and machine learning applications, including logistic regression, decision trees, and ensemble methods.
Dataset 2
This dataset contains approximately 58,000 historical insurance claim records (Insurance Claims Dataset ) spanning a wide range of claim types, such as auto and health. It offers a feature set of around 40 attributes, making it highly suitable for predictive modeling tasks including fraud detection, claim frequency forecasting, and risk assessment.
A typical scenario
The experiments below illustrate a typical scenario where a database is queried by multiple users. It is reasonable to expect variation in the wording of questions that express the same intent across different users. We show examples below of such variations of the ‘original' question.
Assume the following question is posed by user 'A'. Admittedly, this is an open-ended and challenging question but a very plausible scenario in decision support.
Question: What profile should I avoid if am running a personal loan campaign?
It goes through the following chain of events before it successfully answers the question:
- No hits (first run)
- Filter Agent generates code that simply filters, misunderstands user intent
- User requests modification 'Do not use filters, I want to determine the ideal profile'
- Filter Agent generates code based on feedback
- User requests modification providing explicit feedback now 'create an algorithm to predict the ideal profile, use colums job, marital status and education as features'
- Filter Agent now generates a prediction code based on feedback history but creates a dataframe instead of running it on provided data
- User requests modification 'dataframe exists so do not create one'
- Filter Agent generate code based on feedback but encounters a JSON parser error
- Filter Agent uses error history and feedback history to generate code based on feedback
- User approves
- Code is executed and results returned
- Interpretation Agent interprets results and returns to user
- Executions and Guidances are both cached
Actual code execution is shown below.

Original run
Now once the above has completed, user 'B' might have the following question which is similar but directionally different from the question above.
User question: What profile should I target if am running a personal loan campaign?
In this scenario, the prior experiences are useful for answering this question, resulting in a significantly reduced time to result and token count. The following steps are taken here:
- (Non-exact) Success cache hit
- Guidance Cache hit
- Filter Agent uses info and generates code
- User accepts
- Results generated
- Interpreted and returned to user
Note the retrieved entries in both execution and guidance caches in the trace shown below.
Subsequent run with a warmed cache
How did Learning Agents help here?
Notice that both similar matches and guidance were retrieved here. The system was able to use both pieces of information to understand the desired logic and preferences underlying the question “What profile should I avoid if I am running a personal loan campaign?“ and adapt that to the question “What profile should I target if am running a personal loan campaign?”. The result is a noticeable reduction in token consumption, the number of retries and subsequently the time-to-result.
| User question | Original question: What profile should I avoid if am running a personal loan campaign? | Subsequent question: What profile should I target if am running a personal loan campaign? |
|---|---|---|
| Type | First run | Second run (cache warmed) |
| Total number of tokens consumed | 6022 | 1143 |
| Number of attempts | 6 | 1 |
What type of improvements can you expect?
We illustrate, with some examples, the benefits over various lexical variations of the original user question. There are three scenarios here where learning can be advantageous:
- a non-exact hit in the Execution Cache and no hit in the Guidance Cache (no guidance found), this is essentially semantic caching
- hits in both the Execution Cache (non-exact) and the Guidance Cache - the LLM adapts both for the current question
- a hit in the Guidance Cache but no hit in the Execution Cache - the LLM uses guidance alone to create a query for the current question
Below is one such ensemble of questions expressing the same ‘intent’. Every question following the original question that expresses the same intent is denoted a variation of that question.
| Original | Give me the age group that has the highest loan balance but also have taken out home loans? |
|---|---|
| Subsequent variations | I want to find the age group that has a home loan with the highest loan balance? |
| Subsequent variations | I want to know what age group has the highest loan balance but also has a home loan? |
| Subsequent variations | Who has an outstanding home loan and has the highest loan balance, give me the age groups? |
Below are two sets of runs:
- In order to demonstrate the token usage without learning, 3 runs (red) for the original question were made. This was done with the cached cleared after each run, i.e. with learning turned off
- 1 run each (teal) for each of the variation listed in the table above. This was done after the cache was warmed and learning enabled
The total number of tokens consumed and the total number of attempts are shown below for both cases. With learning disabled, the original question ‘Give me the age group that has the highest loan balance but also have taken out home loans?’ takes 3 attempts to form the correct query and consumes 3x the total number of tokens.
Reminder: as noted before, user feedback isparticularly useful for semantic errors since the agent is designed to self-learn from syntactic errors.
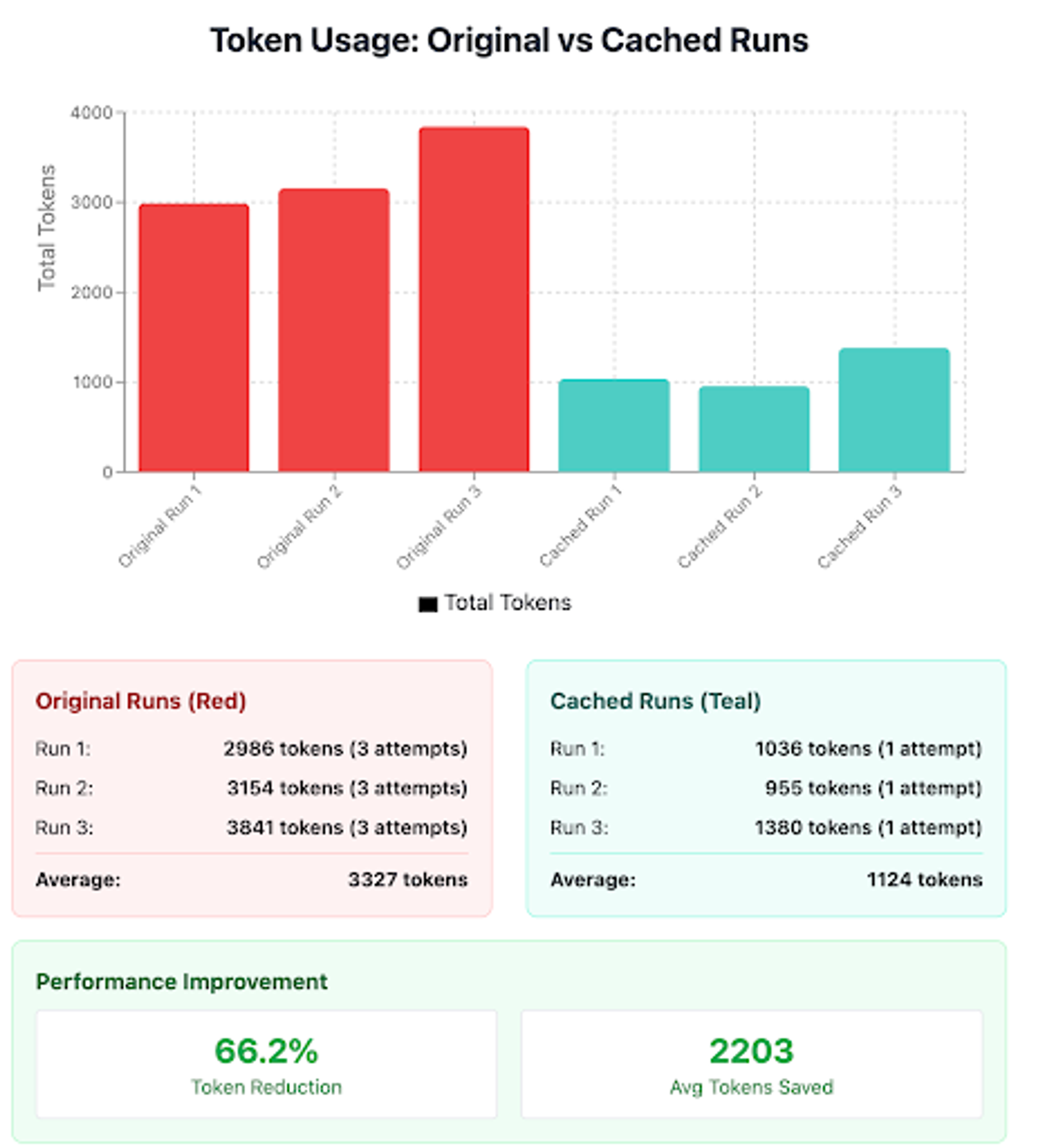
Token usage comparison for question 1
Similarity and intent: a few more examples
Two sentences can be semantically similar yet convey different intents, because intent, as humans define it, depends on both similarity and relevance. Many systems, however, rely solely on similarity to retrieve matches. Here, we examine both scenarios to understand how Learning Agents handle them.
We revisit the question ‘Who is my ideal target for a loan campaign?’, but this time follow up with 3 variations of that question. As seen before, the benefits of imparting the domain knowledge and its subsequent reuse is clear in the reduction in the number of attempts from 2 to 1.
| Original | Who is my ideal target for a loan campaign? |
|---|---|
| Subsequent variations | If I wanted to run a loan campaign, who should I target? |
| Subsequent variations | Who should I target if I want to run a loan campaign? |
| Subsequent variations | How do I optimize my loan campaign? Who do I target? |
Once feedback is provided by the user, subsequent runs (in teal) can use the guidance/grounding generated from the user feedback resulting in predictable and correct results as shown below.
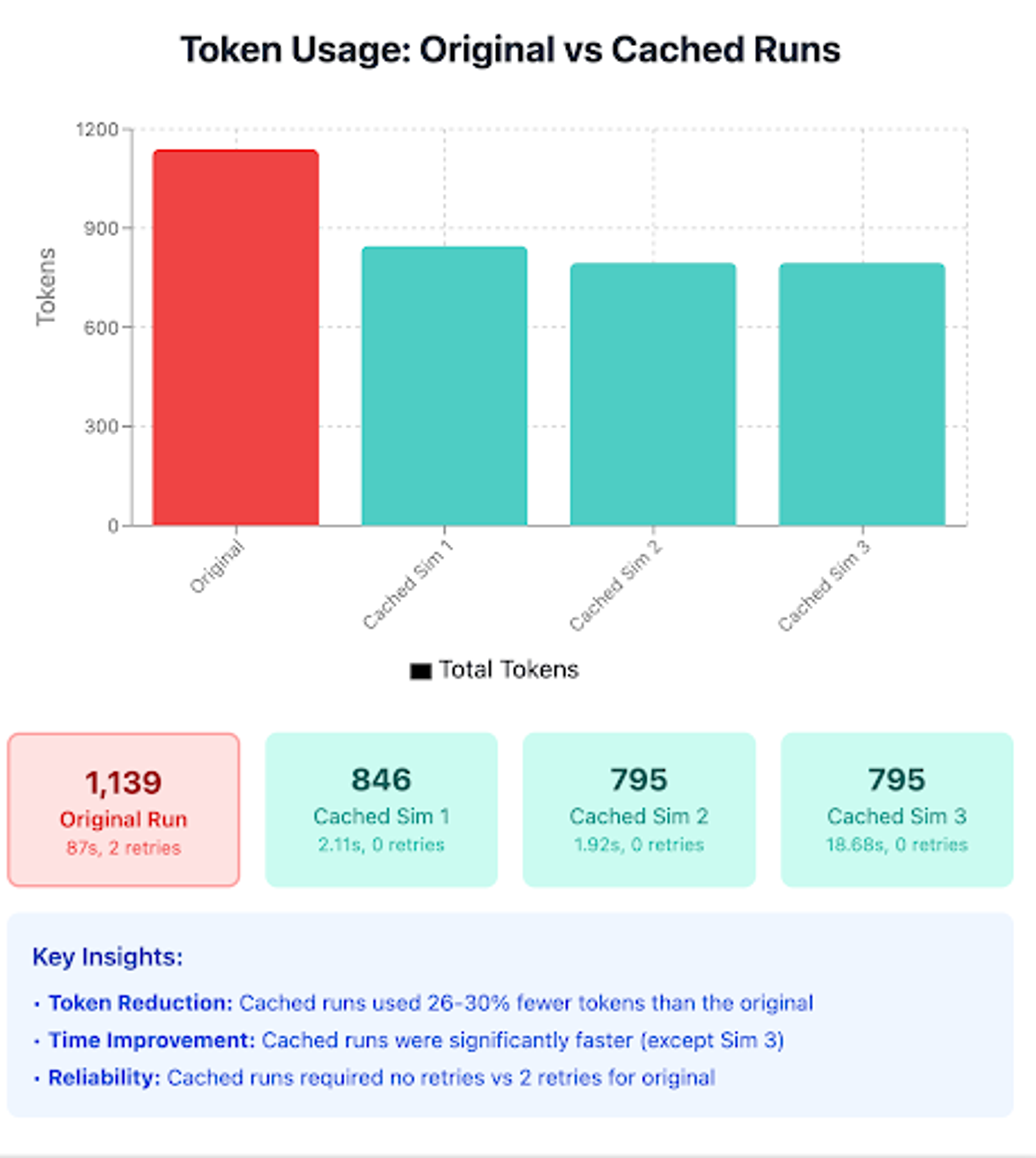
Token usage comparison for question 2
The following demonstrates queries and execution over the insurance dataset. In the example below, similar behavior is observed with respect to the reduction in token count, run time and retry elimination resulting in more predictable and reliable responses.
| Original | What age groups are likely to have automatic transmissions? |
|---|---|
| Subsequent variations | Which age groups are most likely to drive cars with automatic transmissions?” |
| Subsequent variations | Identify age groups that tend to use automatic transmissions |
| Subsequent variations | Determine which age ranges prefer automatic transmissions |
| Subsequent variations | Find out which age groups commonly have automatic transmission variables |
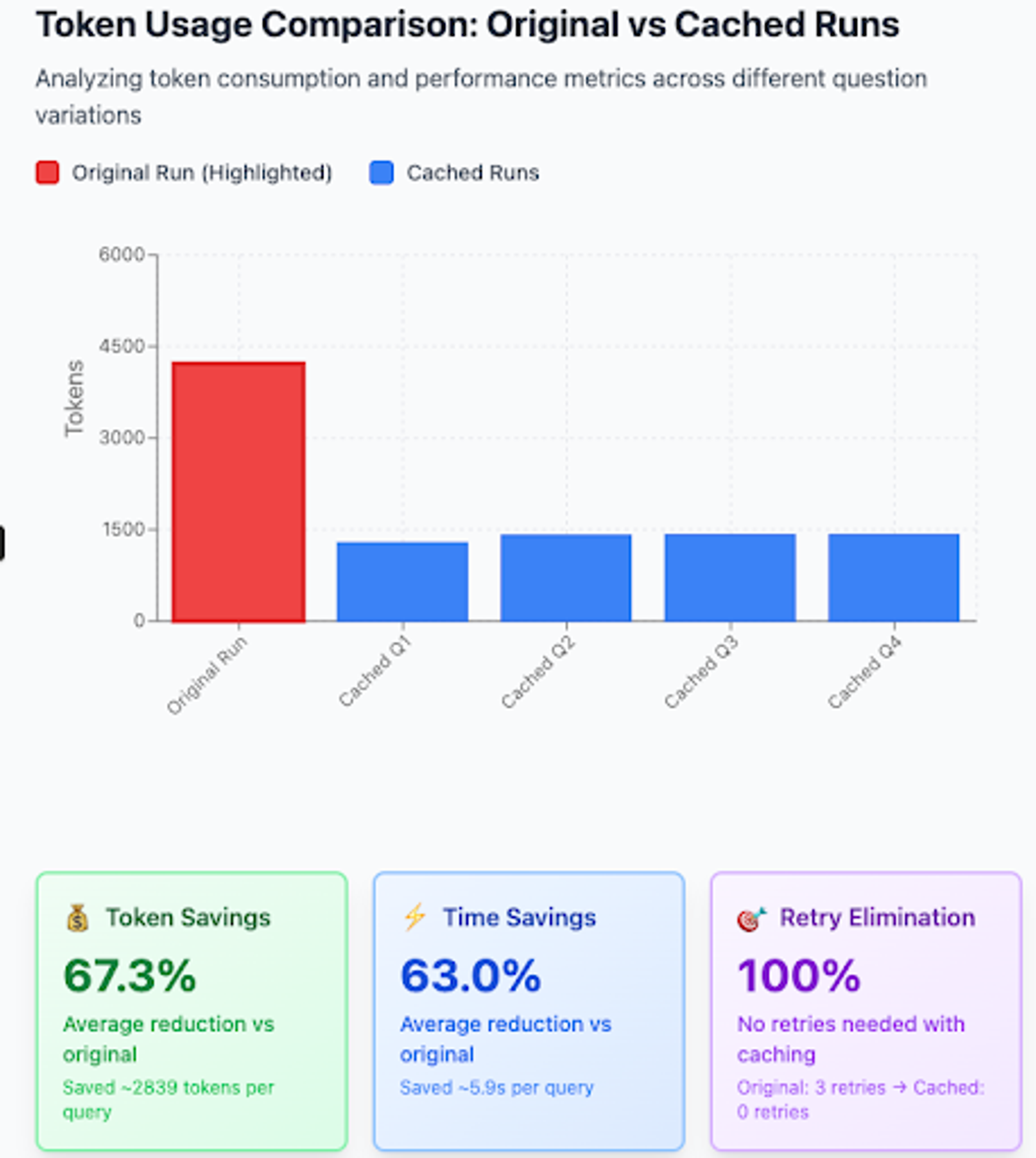
Token usage comparison for question 3
What happens when the variations have intents that differ from the original question. Here, the original question is “What age groups are likely to have automatic transmissions?” but the questions that follow would like to know about age groups that prefer manual transmissions. Once again, similar savings are observed in the metrics of interest.
| Original | What age groups are likely to have automatic transmissions? |
|---|---|
| Negated variation | What age groups are likely to have manual transmissions? |
| Negated variation | Determine which age ranges prefer manual transmissions |
| Negated variation | Find out which age groups commonly drive manual transmission vehicles |
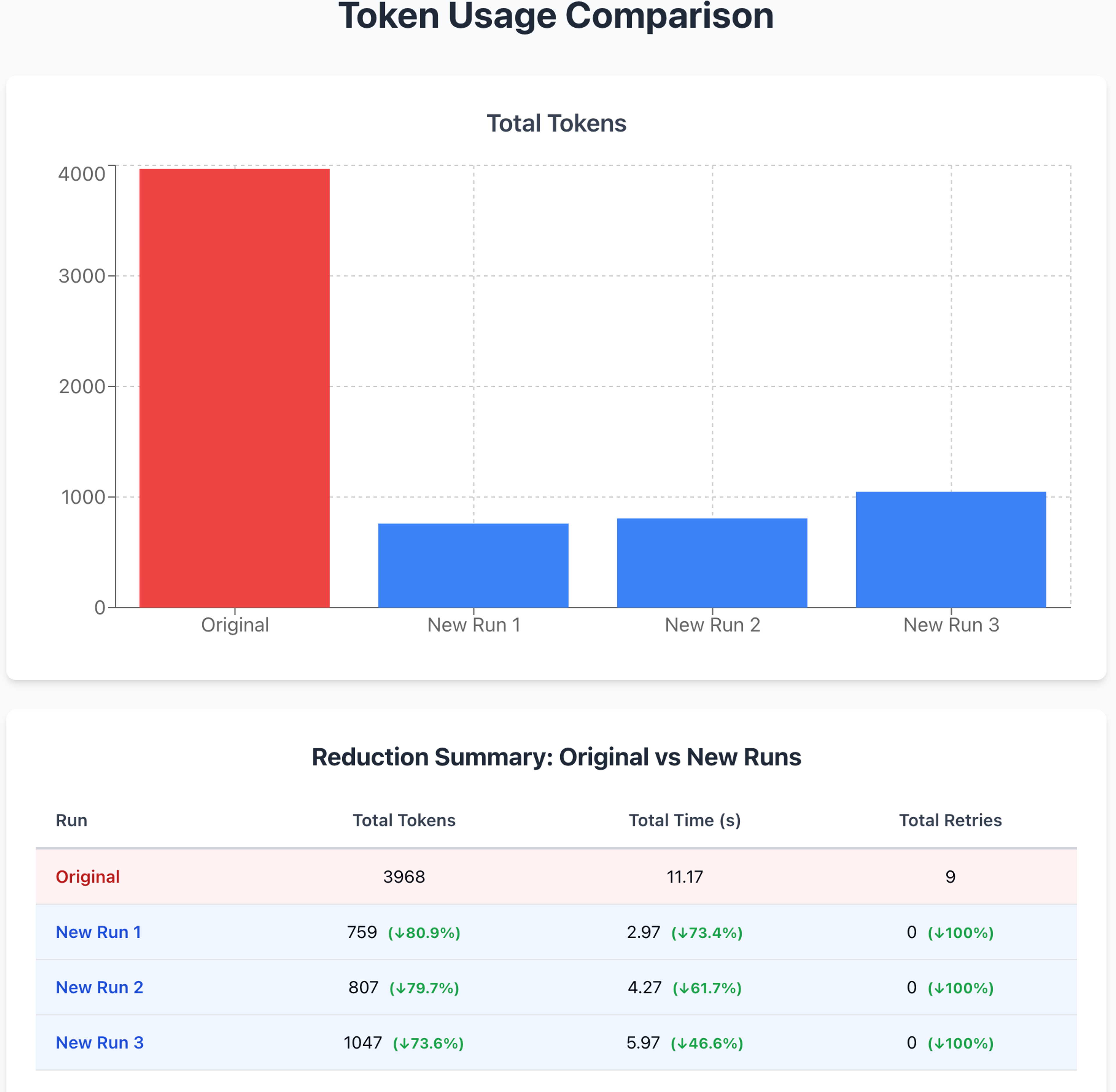
Token usage for variations where intent differs from the original
Discussion and conclusion
In summary, the Learning Agents with Redis framework presents a solution for enabling Large Language Models to effectively learn how to query and interpret structured data. The architecture captures business logic, user preferences, and error pattern and demonstrates advancements over traditional LLM-based QA systems, particularly in complex domains like finance and insurance. By utilizing a multi-tiered caching strategy that incorporates not only past successes but also failures and user feedback, the system follows a path of continuous improvement thereby reducing computational costs and latency and ultimately time-to-insight. By synthesizing principles from meta-learning, semantic caching, and memory reflection, this approach lays the groundwork for next-generation intelligent systems that are not only more efficient but also self-improving and contextually aware.
References
1 Brown, T. et al. (2020). Language Models are Few-Shot Learners. NeurIPS., OpenAI. (2023). GPT-4 Technical Report.
2 Redis Ltd. (2023). Redis Documentation.
3 Finn, C., Abbeel, P., & Levine, S. (2017). Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks. ICML.
4 https://archive.ics.uci.edu/dataset/222/bank+marketing
5 https://www.kaggle.com/datasets/litvinenko630/insurance-claims
6 https://artsen.h3x.xyz/blog/integrating-reasoning-and-agentic-frameworks-for-llms-a-comprehensive-review-and-unified-proposal/?utm_source=chatgpt.com https://arkapravasinha.medium.com/supercharging-llm-applications-with-semantic-caching-boost-speed-cut-costs-and-maintain-accuracy-11f302464dff?utm_source=chatgpt.com
7 Couturier et al., May 2025
8 https://arxiv.org/abs/2505.11271?utm_source=chatgpt.com. Advancing Semantic Caching for LLMs with Domain‑Specific Embeddings and Synthetic Data (Gill et al., Apr 2025)
9 https://arxiv.org/abs/2504.02268?utm_source=chatgpt.com
10 Building LLM Agents by Incorporating Insights from Computer Systems
11 https://link.springer.com/article/10.1007/s44336-024-00009-2
12 Kynoch & Latapie, 2023
13 Xiong et al., 2025
14 Chaudhury et al., 2024
15 https://arxiv.org/abs/2005.08314
17 Zhang et al., Jun 2025
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.