Blog
Machine Learning on Steroids with the New Redis-ML Module

Redis’ in-memory architecture is well known. When you need “fast at high throughput,” Redis is the obvious choice.
Redis is also well known as a “structure store.” While other databases model data in tables/columns, documents or key/value pairs, Redis accommodates all of these structures at once. You can combine tables, documents, key/value pairs and other data types into a single database and assign each entity the data type that best suits it. If you “lift the hood” and look into the other available engines, you will see that documents you save in the database are typically shredded and stored in some underlying native data type that the system understands. Redis has no such abstractions! Each data type is stored natively in the engine, and come with its own “verbs” to perform the actions natively on the data type. With modules (introduced in May 2016), you can now embed your own complex data types in Redis without sacrificing performance.
Here at Redis, we have been working with modules for a while. A month ago, we unveiled the RediSearch module, which delivers the fastest search engine by combining the inverted full-text index with an in-memory architecture. This week, we unveiled another ground-breaking module: Redis-ML, which works with the popular Apache Spark MLlib and other machine learning libraries.
Why Redis-ML?
With Spark + Redis-ML, you can save Spark-generated ML models directly in Redis and generate predictions for interactive, real-time applications. We developed this approach with the Databricks folks because we were impressed by Spark’s ability to train the ML models. However when it comes to generating predictions in real-time, Redis is the engine! With Redis’ Enterprise Cluster you can:
- Get high availability and failure protection
- Generate low-latency predictions in real-time with the in-memory architecture
- Generate predictions as user load scales under high throughput
- Improve your model’s precision (~model size) without worrying about slower responses
- Access the model from Redis client libraries concurrently from applications in different languages.
How Does Redis-ML Work?
The typical machine learning flow for Apache Spark is shown below:
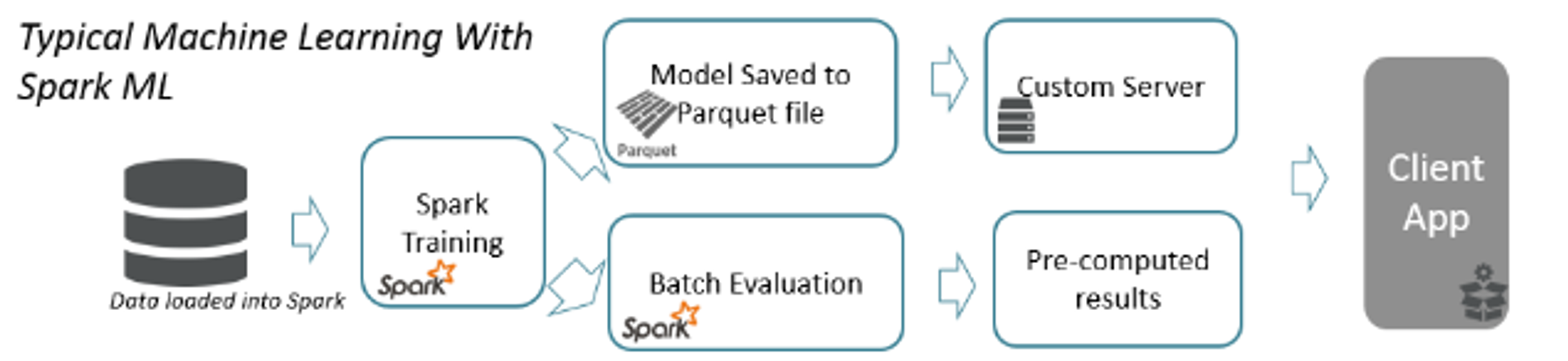
Spark trains the model using your historical data. The model is typically saved to disk and loaded later for generating predictions. However Spark is not particularly ideal for end user applications.
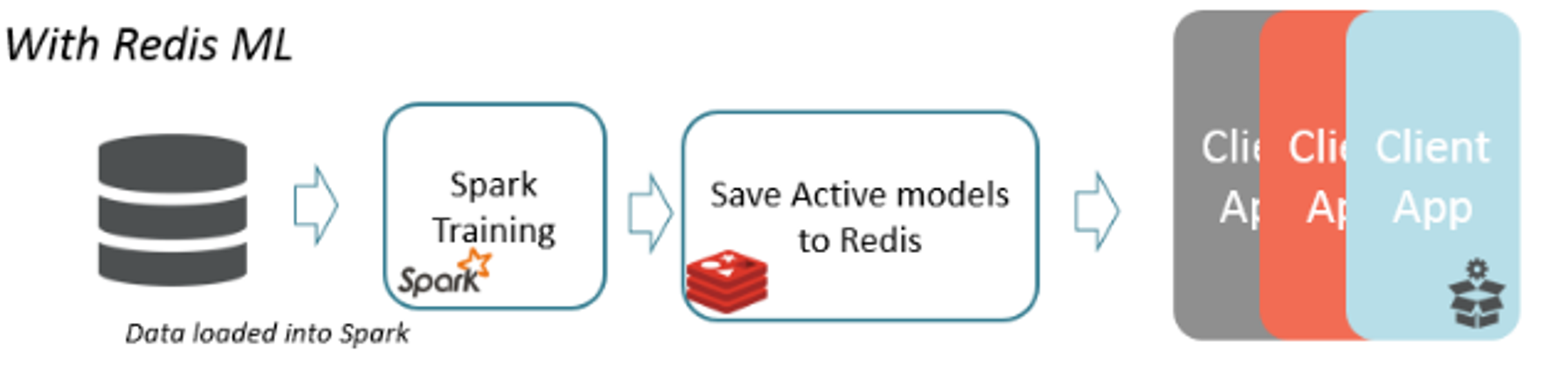
By combining the strengths of both Spark and Redis, you can greatly simplify the flow: (1) after using Spark for training, you save the ML models directly in Redis using Redis-ML, then (2) y use the Redis-ML “verbs” to generate predictions in real time for interactive applications.
Redis’ team ran a benchmark with about 1000 models, each with about 15,000 trees generated by Spark ML using the Random Forest algorithm. . The usage of Redis ML with Spark ML reduces model classification times by a factor of 13X, without using any additional memory and while reducing model save and load times!
| Model Save Time | 3785 ms | 292 ms | 13X |
| Model Load Time | 2769 ms | 0 ms (model is in memory) | ∞ |
| Classification Time (AVG) | 13 ms | 1 ms | 13X |
There are a few reasons why Redis-ML can do this. Redis’ in-memory architecture is one of the reasons. Redis is built for real-time, interactive applications. Modules like Redis-ML also avoid layers of abstraction that other databases are encumbered by. ML structures are served with their native “verbs” directly from memory, without going through additional layers of translation.
As machine learning is becoming a key component of user experience in most next-generation applications (including recommendation engines, fraud detection, risk evaluation, demand forecasting, sentiment analyses, robotics and self driving cars), you will need a machine-learning-capable database that can deliver these models reliably to your applications. Redis-ML will be a critical component in putting your ML models into production.
For more details:
- Visit Redis announcement on Redis-ML here.
- Visit our github repo here: https://github.com/RedisLabs/spark-redis-ml
- Visit Redis open source page for latest Redis builds: http://redis.io/
- Visit Redis Redis Cloud for the top Redis DBaaS: /redis-cloud
- Visit Redis Enterprise Cluster for the top Redis clustering in your own data-centers: /redis-enterprise
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.