Blog
Redis Copilot: Generating database queries from natural language

Over the past few months, we’ve been working on something exciting for developers: Redis Copilot. This AI-powered assistant boosts productivity and makes learning Redis easy. Redis Copilot offers two key features: a general knowledgebase chatbot and a context-aware chatbot that creates and runs queries to answer questions about your data in a Redis database. Access Redis Copilot in the latest Redis Insight GUI dev tool, and the general chatbot in our public docs. We’re eager to share some insights from developing the natural language query builder chatbot.
Our approach
We humans love to create and use tools, but not all tools are created equal. Some are easy to learn, and others, aren’t. When it comes to databases, structured languages like SQL are the go-to for querying, but writing these requires expertise.
Take this Redis query, for example:
This query returns the number of documents indexed by the database. It’s a straightforward query to find out, “How many bikes are in the database?” But even this simple query requires learning syntax and knowing the data’s representation. With Redis, the querying language is unique and less widely known than SQL, which can be a challenge for new users.
Large Language Models (LLM) have shown they can follow instructions in natural language, leading to a wave of new GenAI apps. The most exciting ones, in my opinion, are those that let me “talk” about my data. Instead of learning a new query language (or relearning one I already forgot), I can get answers by asking questions. Redis Copilot makes this possible.
Customizing LLMs
Many code-generating LLMs exist, including ones trained explicitly to generate SQL queries from free text. Since Redis’ query language is almost entirely unlike anything else, existing models can’t generate its queries, so we needed something new.
Creating a new LLM from scratch is a resource-intensive process that demands extensive domain experience. We might never have completed the project if we took that route. Instead, we used prompting and fine-tuning to get the required results from a pre-trained model.
Prompting is like meta-programming—you give the model plain text instructions, and it follows them. If you’ve used ChatGPT or something similar, you already know how it goes. Depending on the task at hand, different prompts produce different results. A solid prompt goes a long way in guiding an LLM in performing the task. Still, prompts alone aren’t enough for state-of-the-art LLMs to teach complex new subjects like our querying language.
Fine-tuning teaches a pre-trained LLM new things. It tweaks the model’s parameters to get the responses we want. The process relies on data, a.k.a. the dataset, to train and evaluate the model during the process. The dataset is specifically built to teach the LLM the new task. In our case, we fine-tuned a pre-trained LLM to understand and generate Redis queries by feeding it a large dataset of questions and their matching queries, and adjusting its parameters based on performance.
Data is everything
In Redis Copilot’s case, each item in the LLM’s fine-tuning dataset includes a question, an answer, and some context. The question is a plain text string in English, and the answer is the corresponding Redis query that answers it when executed. The context contains information about the documents in the database and the index’s schema used by the query.
Fine-tuning yields promising results even with a small dataset, but we needed a much larger one for our task. Given the robustness of the querying language, the dataset had to be diverse enough and include multiple examples of its many features and their respective uses. Plus, the fine-tuned model’s output queries had to be correct, both in terms of syntax and results, so we needed even more data.
Preparing the dataset was the team’s most demanding and time-consuming task. Since no existing corpus of the data existed, we had to create one. Because synthetic and LLM-generated data didn’t help solve our challenge, we crafted each dataset item individually.
Fine-tuning an LLM makes it repeat what you teach it, so the data had to be assembled by engineers who know their Redis queries well. Otherwise, we’d get sub-par results—(“garbage in, garbage out.”)
As we built and refined the dataset, we used it to fine-tune the model and test its accuracy. By fine-tuning the model on evolving versions of the dataset, we could measure improvements and identify problem areas in the data.
Testing models is far from easy, especially when it comes to making sure their answers are correct and accurate. This is a notoriously hard problem, which is why model hallucinations are still common. But, because of the formal nature of the problem we’re trying to solve, we could test our model more effectively.
When our model generates malformed queries, like ones containing syntax errors and made-up commands, they’re easy to catch because the server returns an error message when you try to run them. You can also spot the incorrect ones by comparing the results of a generated query to what you expected. Analyzing erroneous and wrong queries helped us fix the dataset and focus on areas that needed more work.
The dataset we’ve built, along with the fine-tuned model, form the core of Redis Copilot query builder, but there’s one more thing to mention: the quantity and quality of items in your dataset are irrelevant as long as there are many of them and all are good.
Divide and conquer
Our fine-tuned LLM was getting better at generating legitimate and meaningful queries, but it started “forgetting” how to do other stuff. That’s a well-known issue with fine-tuning—you’re reinforcing the behavior you want, but at the expense of what the LLM already knows. We still needed a way to carry out a conversation, which is a task that requires more than just generating queries.
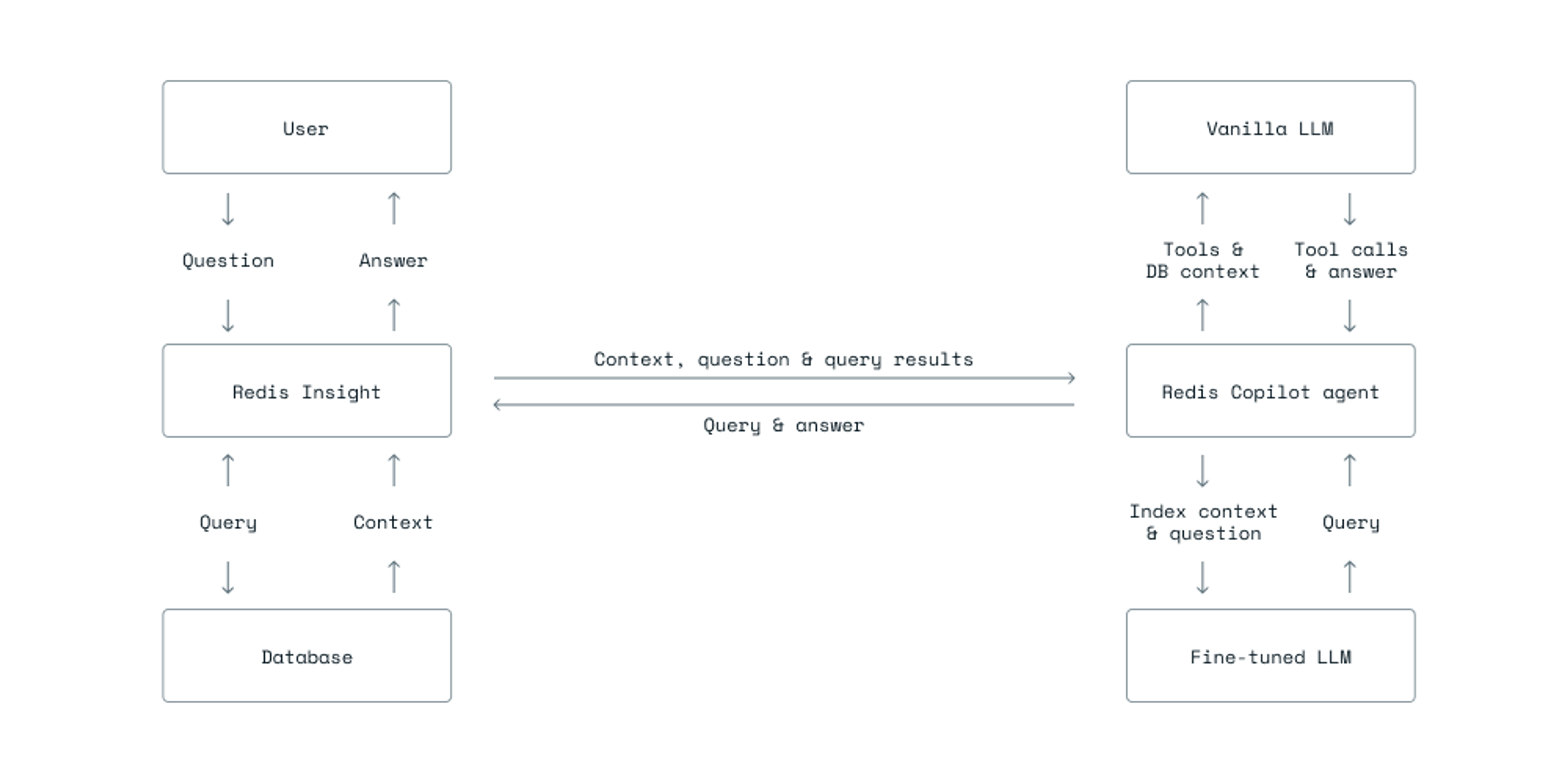
Some problems can be solved by breaking them into smaller ones. The fine-tuned LLM solved the problem of query generation, and we turned to another LLM to address the remaining challenge of conversing. We’ve set up an AI agent with a generic LLM that chats with the user and can call the fine-tuned model to generate queries.
“AI agent” can mean a lot of things, but for us, it’s a system where a language model controls a looping workflow and takes actions. The agent’s tasks and instructions come from the LLM’s prompt. In addition to the prompt, the agent can use other tools to accomplish the tasks.
Tools can do anything that’s possible with code. The agent is oblivious to their implementation and only knows their intended usage and expected inputs. For example, one of our Redis Copilot tools expects a single string as input, and its description is “use this tool to evaluate a mathematical expression.”
The tool is aptly named “evaluate_math_expression.” The LLM’s prompt has specific instructions on using it for calculations, especially since LLMs can fail at basic math. This tool ensures accurate results regardless of the model’s capabilities.
Our agent has another tool called “query.” Its description is: “Use this tool to generate and execute a database query.” It expects two inputs: a question and an index name. And you guessed it right—all the tool does is call on the fine-tuned LLM to do the heavy lifting.
The last piece of the puzzle is the agent’s context. In addition to the chat history, we give the agent summarized information about the database. This includes the names of indices and document properties, which helps the LLM to “understand” what data the user’s questions refer to.
Here’s how everything ties in together:
GenAI’s siren song
It’s impressive when GenAI accomplishes a task correctly. Seeing our fine-tuned model start spitting out its first legitimate, though basic, queries was awe-inspiring. And when we hooked up the query generation and execution with the conversational agent to complete the cycle, the results were jaw-dropping.
GenAI and AI agents are everywhere, and they keep improving daily. I can hardly remember the time before GitHub’s Copilot sat patiently in my IDE, fixing my typos, suggesting snippets, helping me reformat walls of code with a simple press of the tab key, and generally just being so helpful. These smart features, and my recent involvement with the tech behind them, almost made us miss an obvious truth.
The fine-tuned model generates queries in idiomatic Redis CLI syntax during the conversation. That syntax is used in Redis’ docs and can be copy-pasted for execution in Redis Insight. But the CLI syntax isn’t suitable for running the query in any given programming language using one of Redis’ clients. Each language has its syntax, and each client provides its API.
Wouldn’t it be great if Redis Copilot could provide the generated queries in the user’s preferred programming language and client of choice? The answer was an easy yes, and given all the work we put in, it seemed simple to accomplish.
Everybody knows that LLMs are good at generating code, especially those trained for it. Fine-tuning an LLM on a dataset with code snippets in different languages should give us the results we were looking for. All we needed was to translate our dataset to the target languages we wanted to support. Technically, this was possible, but with such a big dataset and the number of translation targets, it’d take serious effort from devs with expertise in each language. It wasn’t going to be easy. Wait a second, we thought. How hard could it be to write code that takes a well-formed, syntactically correct CLI-encoded query and transforms it into another well-defined syntax? With relatively simple code, we can parse the query and output it in any syntax we need. This would make translating the fine-tuning dataset much easier, and help us build an LLM army.
At this point, we realized that an LLM wasn’t always the right solution for every problem—even problems that have code generation written all over them. Once the query parser was ready, it made sense to just call it ad-hoc with the generated query whenever the user asked for its translation—without involving the LLM. It’s cheaper, faster, and infinitely more reliable than any output generated by an AI.
Looking ahead with Redis Copilot
There’s still a lot to share about this journey and the work we’re doing on Redis Copilot. If the post could be any longer, we’d tell you about the time we caught it cheating and being lazy. But those stories will have to wait for upcoming posts.
Learn more about Redis Insight and try Redis Copilot here.
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.