
At RedisDays NY 2022, we announced the public preview of our new Vector Similarity Search (VSS) capability. VSS is part of RediSearch 2.4 and is available on Docker, Redis Stack, and Redis Enterprise Cloud’s free and fixed subscriptions.
In this article, I’ll walk you through the basics of vector similarity, and its applications and share resources to get you started with Redis VSS!
In simple terms, it is a measure of how different (or similar) two or more vectors are. Think of a vector as a list of numbers.
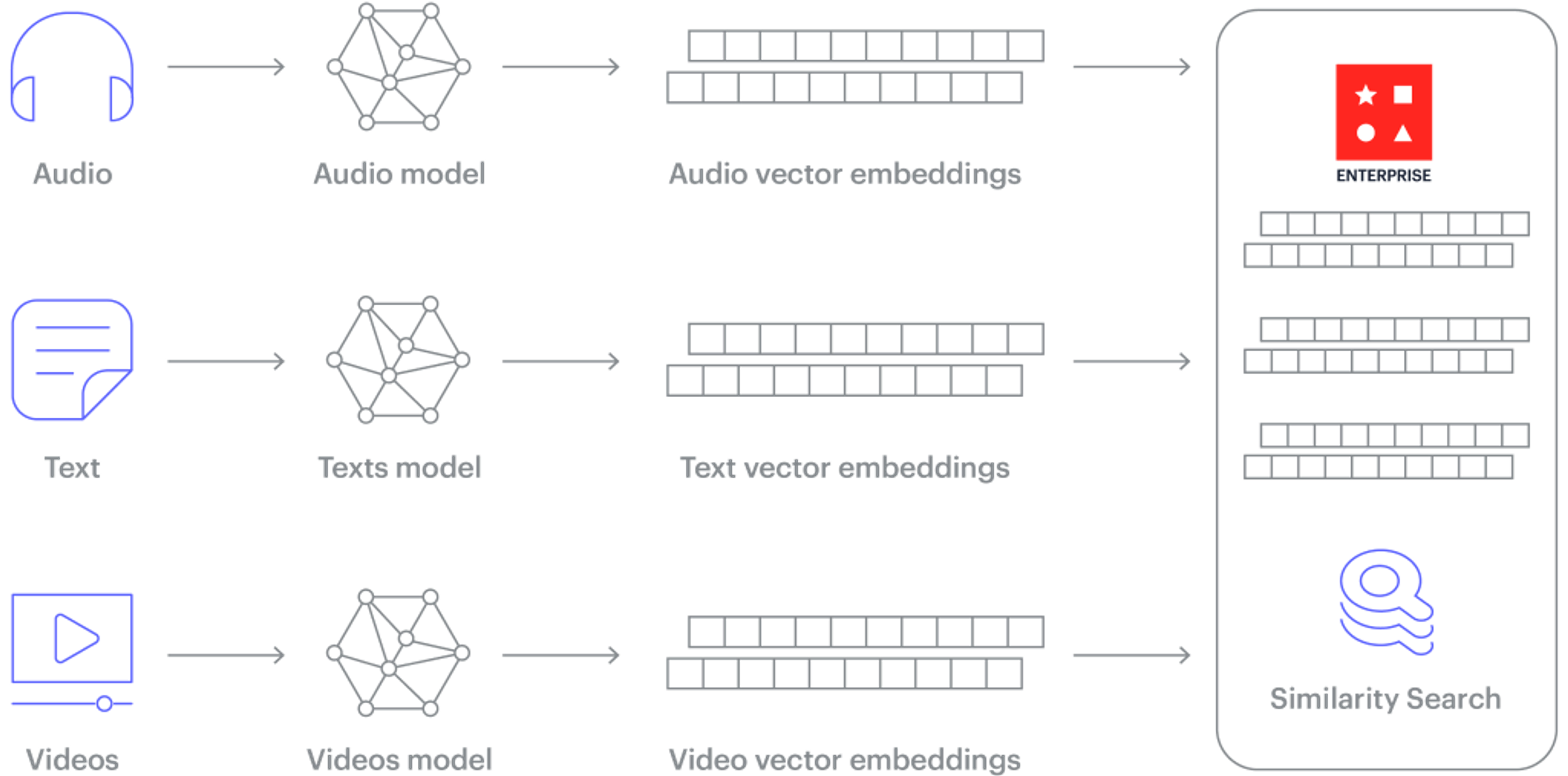
At its core, vector search allows developers to retrieve information based on audio, natural language, images, video clips, voice recordings, and many more types of data. Searching over unstructured data makes VSS a foundational technology to build advanced similarity search experiences.
With advances in AI, data scientists can build models that can transform almost any data “entity” into its vector representation. An entity here could be a transaction, a user profile, an image, a sound, a long piece of text (sentence or paragraph), a time series, or a graph. Any of these can be turned into its “feature vector,” also known as “embedding.”
Vector embeddings are numerical representations of data. They capture the most essential features of an entity in a way that computers and databases can easily compare. The interesting part here is that if a model generates two similar embeddings (vectors) for two entities, you can infer that the two original entities are similar in some fundamental way.
Not at all! There are several freely available AI models and libraries that allow developers to generate embeddings from text, image, or time-series data. For example, you can use HuggingFace Sentence Transformers to generate embeddings for sentences, Img2Vec to generate embeddings for images, and Facebook Kats to generate embeddings for time-series data. AI/ML practitioners are familiar with the concept of generating “dense” feature representations (a.k.a embeddings) for their data entities. They can now store these feature vectors in Redis and perform similarity searches on them.

There are several everyday applications that you interact with that rely on vector similarity search.
From visual search on an e-commerce website to automated chatbots / Q&A systems and multiple types of recommendation systems. More generally, you will find VSS useful on any app where spotting similarity in real-time is essential to unlocking value. Some common use cases are listed below:
– E-commerce recommendations: Use visual similarity and/or semantic similarity to power advanced search experiences and product recommendations
– Semantic similarity: Build sophisticated search experiences, chatbots, or even question and answering systems
– Similarity in time-series data: Discover similarities of disease spread patterns or opportunities to trade based on similarities in historical patterns
– Similarity in graph data: Reveal similar patterns of connections across different (possibly unrelated) sets of actors or networks.
– Similarity of transactions: Detect potential fraud or threats based on similarity to previously detected fraud/threat attempts
– Similarity of user profile or products: Generate personalized recommendations; refine your customer segmentation based on patterns revealed by embeddings data
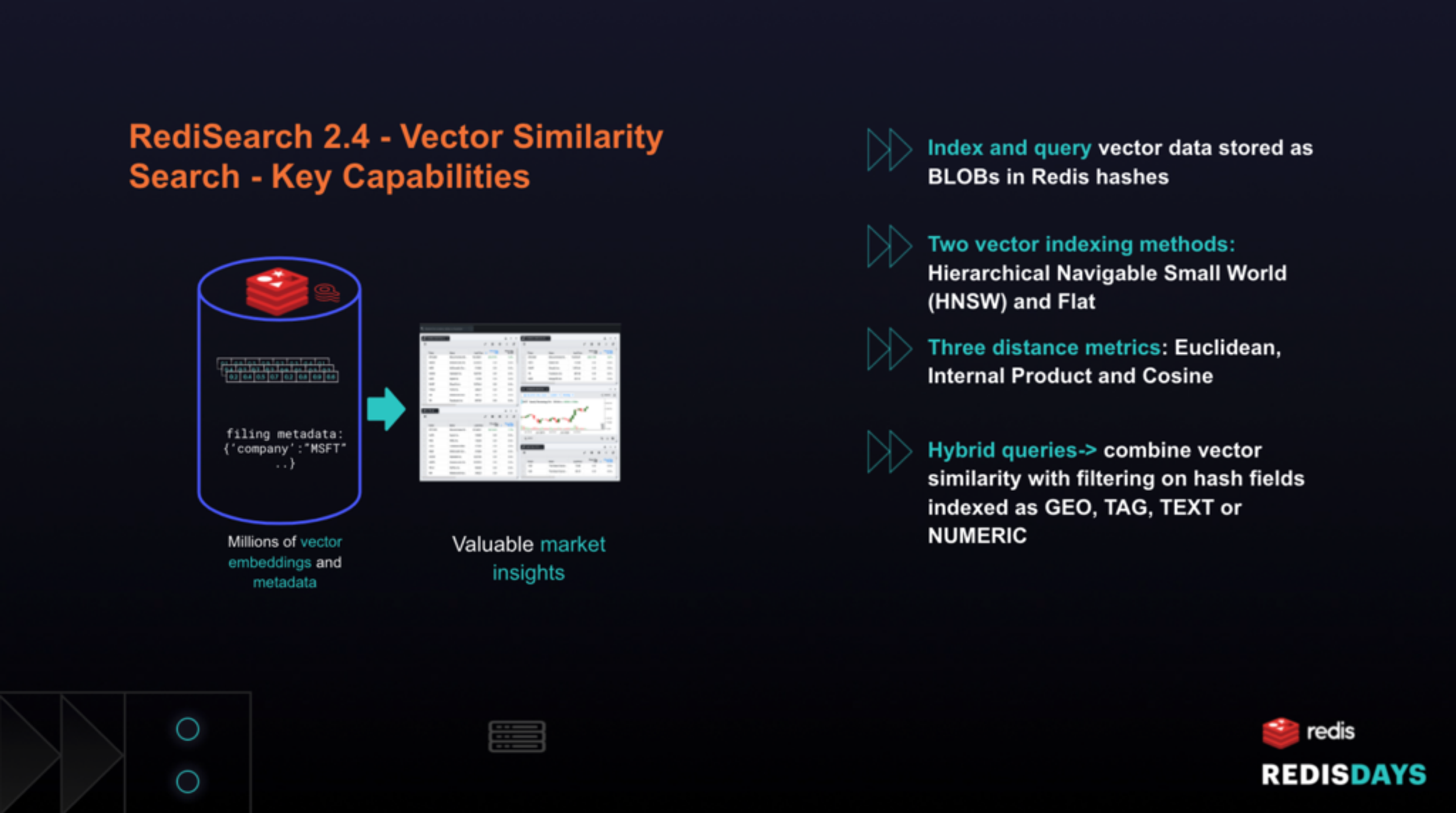
RediSearch is a Redis module that provides query ability, secondary indexing, and full-text search for Redis data stored as Redis hashes or JSON format. With Redis 2.4, Redis introduced support for vector similarity search.
With RediSearch 2.4, Redis developers can:
– Index and query vector data stored as BLOBs in Redis hashes
– Use two popular indexing methods: FLAT and HNSW
– Use three common vector distance metrics: cosine, internal product, and euclidean distance
– Perform hybrid queries which combine vector similarity with traditional RediSearch filtering capabilities on GEO, NUMERIC, TAG, or TEXT data. A common example of a hybrid query in an e-commerce setting is “find items visually similar to a given query image limited to items available in a GEO location and within a price range”.
If you are handy with Python, try these out:
– Visual and Semantic Similarity on a public Amazon Dataset
– Sentiment analysis and Semantic similarity in Financial News articles
For Java, you can try this basic demo which shows how to create an index, load data, and query.
Try watching replays of these two RedisDays 2022 sessions:
– Keynote: Infuse Real-Time AI Into Your “Financial Services” Applications
– Behind the Scenes: Using AI to Reveal Trading Signals Buried in Corporate Filings
The sessions are now available to watch on-demand. You can always check RediSearch documentation on “Working with Vectors.”

There are three easy ways to create a Redis database with RediSearch 2.4.
From your Terminal, you can get it with either of the following:
1) Docker – “docker run -p 6379:6379 redislabs/redisearch:2.4.5”
2) Redis Stack – “brew install redis-stack” (from Mac OS). For other operating systems, try “Getting started with Redis Stack”
3) Finally, you can also create a free subscription with Redis Enterprise Cloud
If you go down the Redis Enterprise Cloud subscription route, make sure to use the “Redis Stack” option as it includes RediSearch 2.4.
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.