Blog
How to Use Redis as an Event Store for Communication Between Microservices

In my experience, certain applications are easier to build and maintain when they are broken down into smaller, loosely coupled, self-contained pieces of logical business services that work together. Each of these services (a.k.a. microservices) manages its own technology stack that is easy to develop and deploy independently of other services. There are countless well-documented benefits of using this architecture design that have already been covered by others at length. That said, there is one aspect of this design that I always pay careful attention to because when I haven’t it’s led to some interesting challenges.
While building loosely coupled microservices is an extremely lightweight and rapid development process, inter-services communication models to share state, events and data between these services is not as trivial. The easiest communication model I have used is direct inter-service communication. However, as explained eloquently by Fernando Dogio, it fails at scale—causing crashed services, retry logics and significant headaches when load increases—and should be avoided at all costs. Other communication models range from generic Pub/Sub to complex Kafka event streams, but most recently I have been using Redis for communication between microservices.
Redis to the rescue!
Microservices distribute state over network boundaries. To keep track of this state, events should be stored in, let’s say, an event store. Since these events are usually an immutable stream of records of asynchronous write operations (a.k.a. transaction logs), the following properties apply:
- Order is important (time-series data)
- Losing one event leads to a wrong state
- The replay state is known at any given point in time
- Write operations are easy and fast
- Read operations require more effort and should therefore be cached
- High scalability is required, as each service is decoupled and doesn’t know the other
With Redis, I have always easily implemented pub-sub patterns. But now that the new Streams data type is available with Redis 5.0, we can model a log data structure in a more abstract way—making this an ideal use case for time-series data (like a transaction log with at-most-once or at-least-once delivery semantics). Along with Active-Active capabilities, easy and simple deployment, and in-memory super fast processing, Redis Streams is a must-have for managing microservices communication at scale.
The basic pattern is called Command Query Responsibility Segregation (CQRS). It separates the way commands and queries are executed. In this case commands are done via HTTP, and queries via RESP (Redis Serialization Protocol).
Let’s use an example to demonstrate how to create an event store with Redis.
OrderShop sample application overview
I created an application for a simple, but common, e-commerce use case. When a customer, an inventory item or an order is created/deleted, an event should be communicated asynchronously to the CRM service using RESP to manage OrderShop’s interactions with current and potential customers. Like many common application requirements, the CRM service can to be started and stopped during runtime without any impact to other microservices. This necessitates that all messages sent to it during its downtime be captured for processing.
The following diagram shows the inter-connectivity of nine decoupled microservices that use an event store built with Redis Streams for inter-services communication. They do this by listening to any newly created events on the specific event stream in an event store, i.e. a Redis instance.
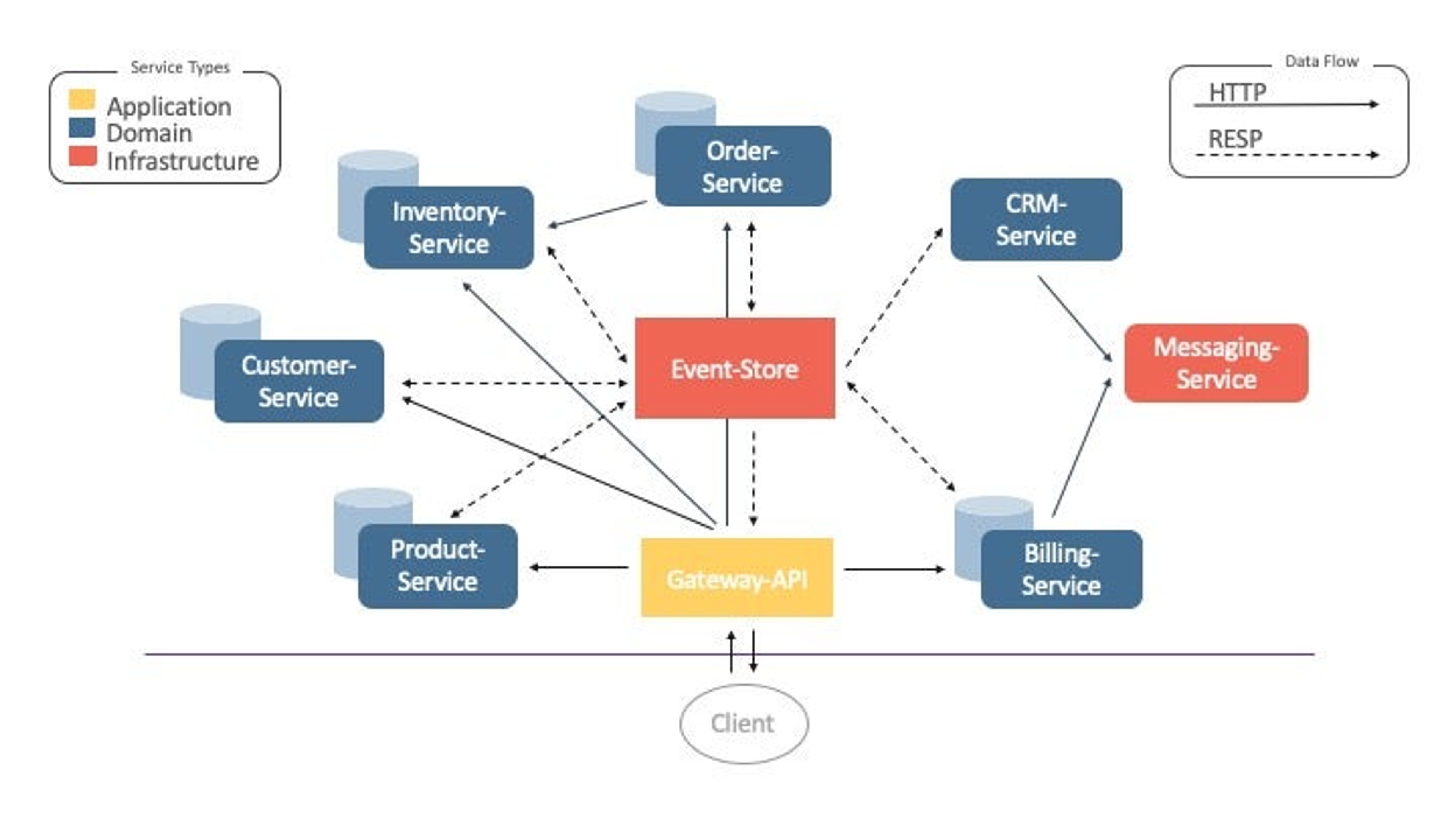
Figure 1: OrderShop Architecture
The domain model for our OrderShop application consists of the following five entities:
- Customer
- Product
- Inventory
- Order
- Billing
By listening to the domain events and keeping the entity cache up to date, the aggregate functions of the event store has to be called only once or on reply.
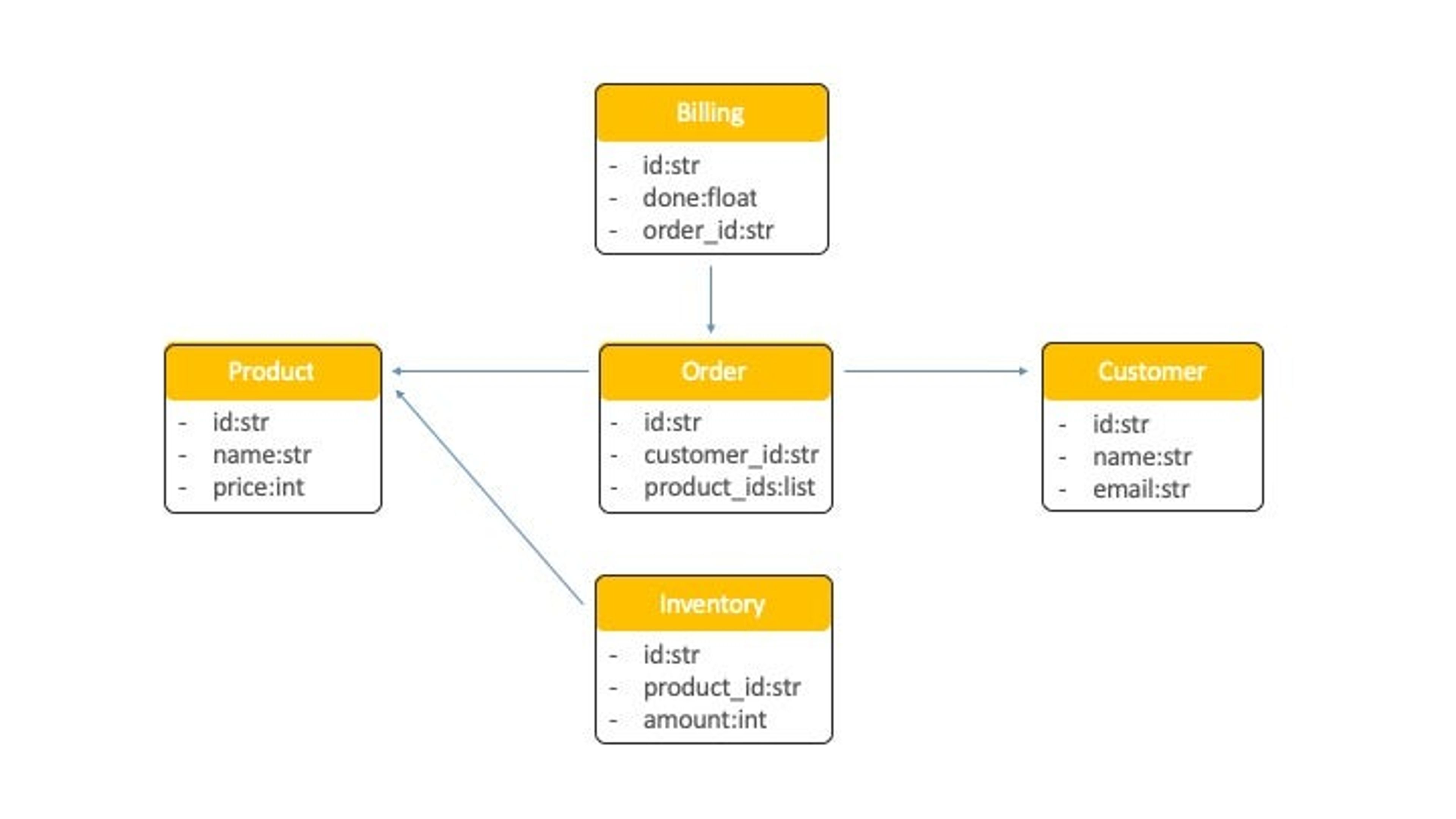
Figure 2: OrderShop Domain Model
Install and run OrderShop
To try this out for yourself:
- Clone the repository from https://github.com/Redislabs-Solution-Architects/ordershop
- Make sure you have already installed both Docker Engine and Docker Compose
- Install Python3 (https://python-docs.readthedocs.io/en/latest/starting/install3/osx.html)
- Start the application with docker-compose up
- Install the requirements with pip3 install -r client/requirements.txt
- Then execute the client with python3 -m unittest client/client.py
- Stop the CRM-service with docker-compose stop crm-service
- Re-execute the client and you’ll see that the application functions w/o any error
Under the hood
Below are some sample test cases from client.py, along with corresponding Redis data types and keys.
| Test Case | Description | Types | Keys |
|---|---|---|---|
| test_1_create_customers | Creates 10 random customers | Set Stream Hash | customer_ids events:customer_created customer_entity:customer_id |
| test_2_create_products | Creates 10 random product names | Set Stream Hash | product_ids events:product_created product_entity:product_id |
| test_3_create_inventory | Creates inventory of 100 for all products | Set Stream Hash | inventory_ids events:inventory_created inventory_entity:inventory_id |
| test_4_create_orders | Creates 10 orders for all customers | Set Stream Hash | order_ids events:order_created order_product_ids:<> |
| test_5_update_second_order | Updates second order | Stream | events:order_updated |
| test_6_delete_third_order | Deletes third order | Stream | events:order_deleted |
| test_7_delete_third_customer | Deletes third customer | Stream | events:customer_deleted |
| test_8_perform_billing | Performs billing of first order | Set Stream Hash | billing_ids events:billing_created billing_entity:billing_id |
| test_9_get_unbilled_orders | Gets unbilled orders | Set Hash | billing_ids, order_ids billing_entity:billing_id, order_entity:order_id |
I chose the Streams data type to save these events because the abstract data type behind them is a transaction log, which perfectly fits our use case of a continuous event stream. I chose different keys to distribute the partitions and decided to generate my own entry ID for each stream, consisting of the timestamp in seconds “-” microseconds (to be unique and preserve the order of the events across keys/partitions).
I choose Sets to store the IDs (UUIDs) and Lists and Hashes to model the data, since it reflects their structure and the entity cache is just a simple projection of the domain model.
Conclusion
The wide variety of data structures offered in Redis—including Sets, Sorted Sets, Hashes, Lists, Strings, Bit Arrays, HyperLogLogs, Geospatial Indexes and now Streams—easily adapt to any data model. Streams has elements that are not just a single string, but are objects composed of fields and values. Range queries are fast, and each entry in a stream has an ID, which is a logical offset. Streams provides solutions for use cases such as time series, as well as streaming messages for other use cases like replacing generic Pub/Sub applications that need more reliability than fire-and-forget, and for completely new use cases.
Because you can scale Redis instances through sharding (by clustering several instances) and offer persistence options for disaster recovery, Redis is an enterprise-ready choice.
Please, feel free to reach out to me with any questions or to share your feedback.
ciao
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.