View and edit data pipeline
Observe and change your data pipeline.
| Redis Cloud |
|---|
To view or manage your data pipeline, select it from your workspace from the Data Integration page or from the Data Integration tab in your subscription or database.
The pipeline page has the following tabs:
The following sections describe each of these tabs, as well as related diagnostic views and actions.
Dashboard
The Dashboard tab shows an overview and high-level statistics for the data pipeline.
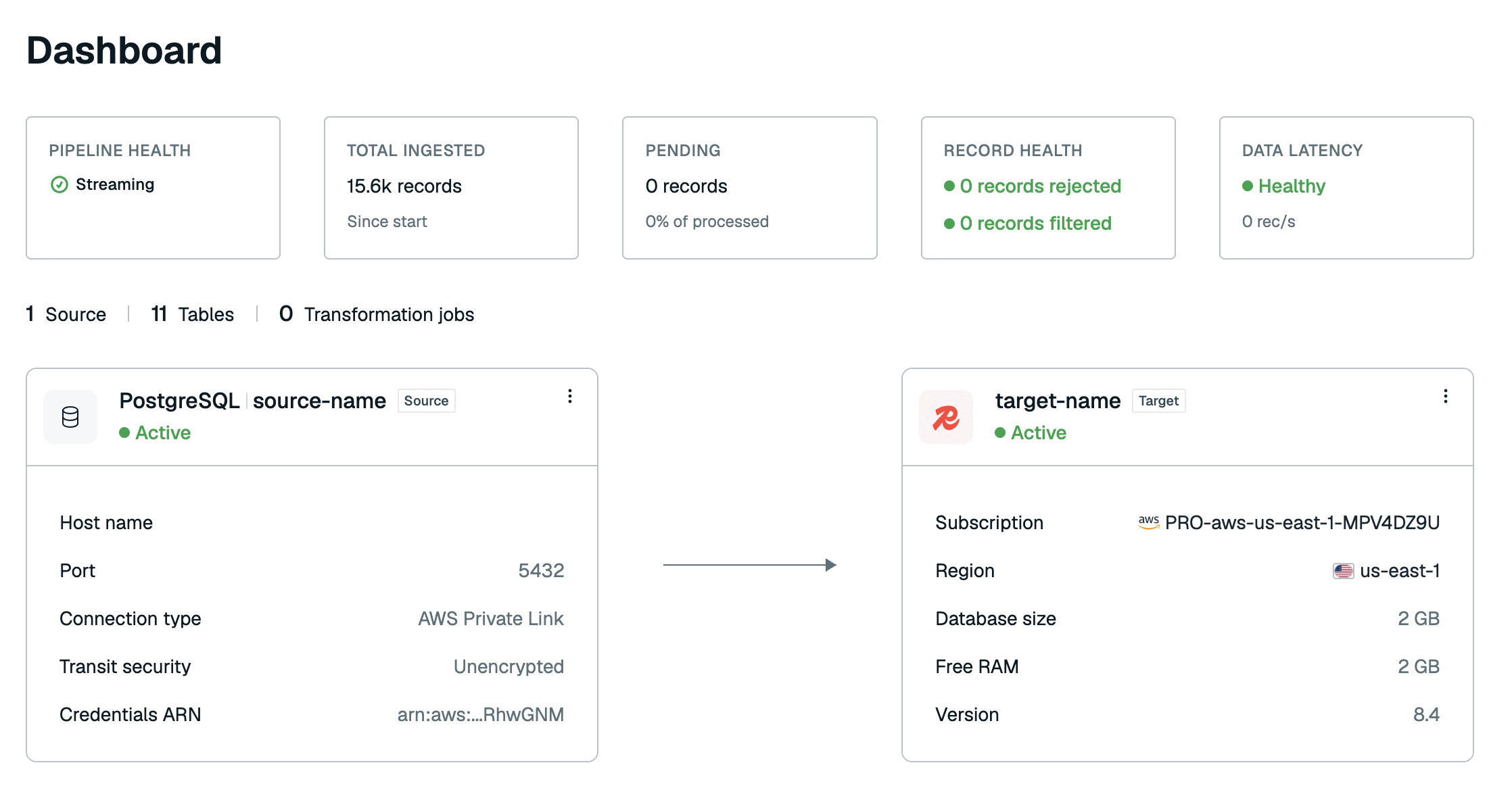
- Pipeline health: The status of the data pipeline. Possible statuses include:
Status Description Streaming The data pipeline is capturing new changes from the source database as they happen. Changes in the source database are added to the target database within a few seconds. Stopped The data pipeline has been stopped. Error There is an error in the data pipeline. Reset the pipeline and contact support if the issue persists. - Total ingested: Total number of records ingested from the source database.
- Pending: Total number of records that are being processed and have not been inserted into the target database.
- Record health: The number of records that were rejected from the database, and the number of records that were filtered from being inserted into the database. If there are rejected records, select the rejected count to open the Rejected records view.
- Data latency: How long it takes for a new record to be ingested from the source database.
Change target database
You can change the target database for your pipeline if the new target database is in the same subscription of the current target database. To do this:
- From the Dashboard tab of your pipeline, select More Actions > Change pipeline target next to the target database of the pipeline.

- Select the new target database from the list.
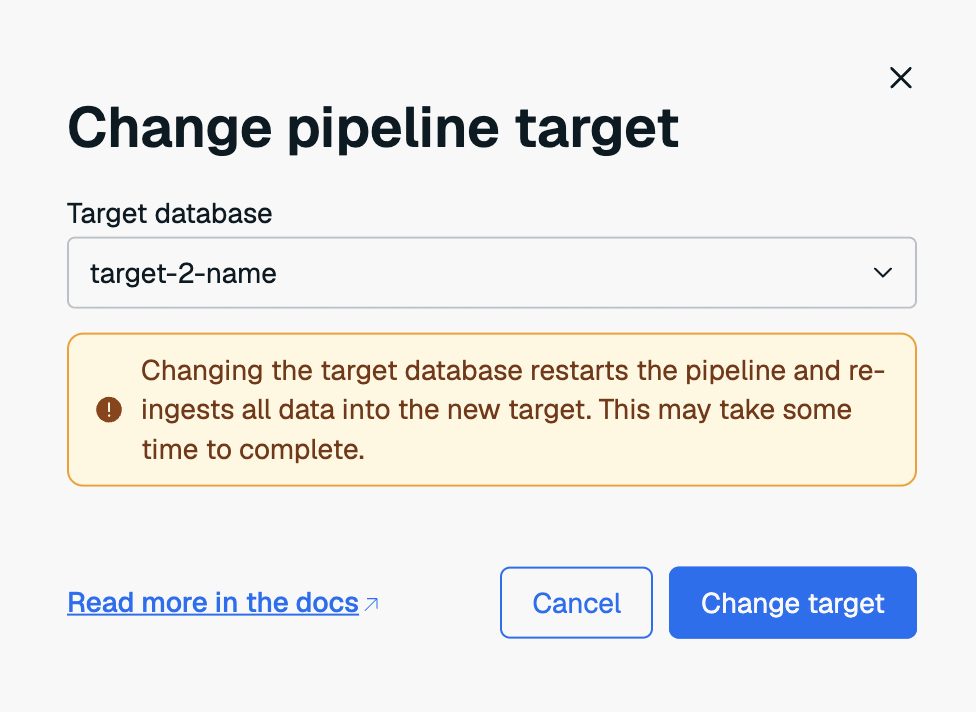
- Select Change target to continue.
Changing the target database restarts the pipeline, but it does not automatically re-ingest all data into the new target database. If you want the existing data re-ingested after the change, manually reset the pipeline.
Metrics
The Metrics tab shows the following metrics for each data stream:
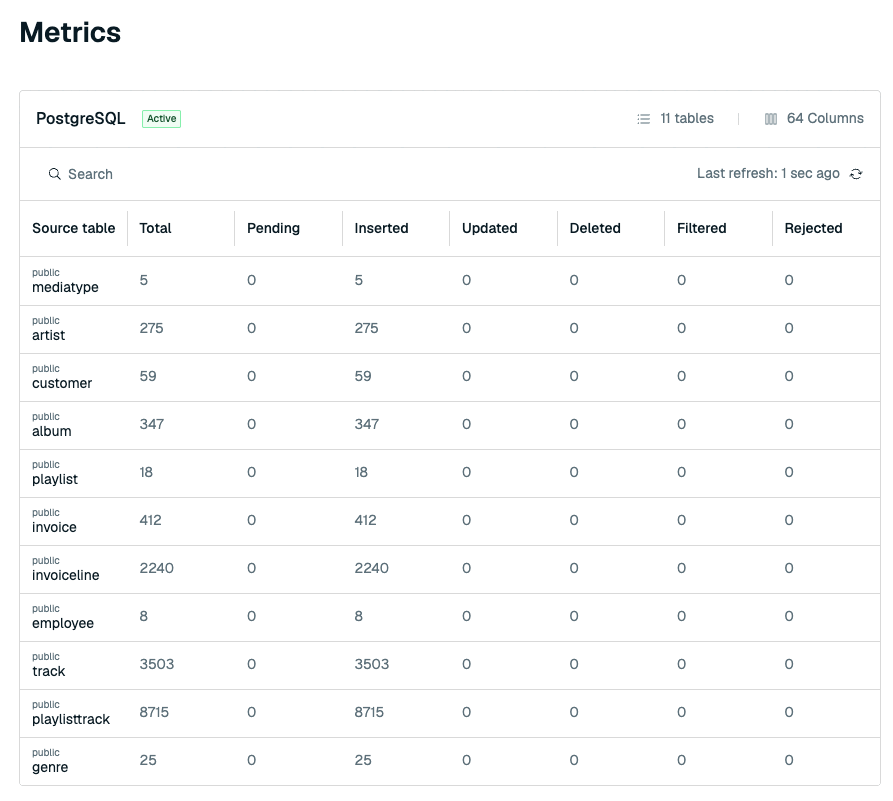
| Metric | Description |
|---|---|
| Name | Name of the data stream. Each stream corresponds to a table from the source database. |
| Total | Total number of records that arrived from the source table. |
| Pending | Number of records from the source table that are waiting to be processed. |
| Inserted | Number of new records from the source table that have been written to the target database. |
| Updated | Number of updated records from the source table that have been updated in the target database. |
| Deleted | Number of deleted records from the source table that have been deleted in the target database. |
| Filtered | Number of records from the source table that were filtered from being inserted into the target database. |
| Rejected | Number of records from the source table that could not be parsed or inserted into the target database. Select a rejected count to open the Rejected records view for that table. |
Rejected records
The Rejected records view shows records that RDI sent to the dead letter queue (DLQ) because processing failed. Open it from the rejected count on the Dashboard tab or from a table-level rejected count on the Metrics tab.
The view shows:
- The total number of rejected records.
- The number of affected tables.
- The affected tables and their rejected counts.
- Rejected record IDs and rejection times.
- Safe troubleshooting metadata, such as the rejection reason, operation, affected table, and transformation job details when available. See Using the operation code for the operation labels.
Redis Cloud uses the RDI DLQ API to show a sanitized view of rejected records. It does not show the original source record payload or every field stored in the DLQ stream. To inspect the full DLQ entry, connect to the RDI database and read the corresponding DLQ stream directly.
For more information about why records are rejected and how RDI stores them, see Rejected records.
Configuration
The Configuration tab shows your source connectivity, secrets, and collector configuration properties.
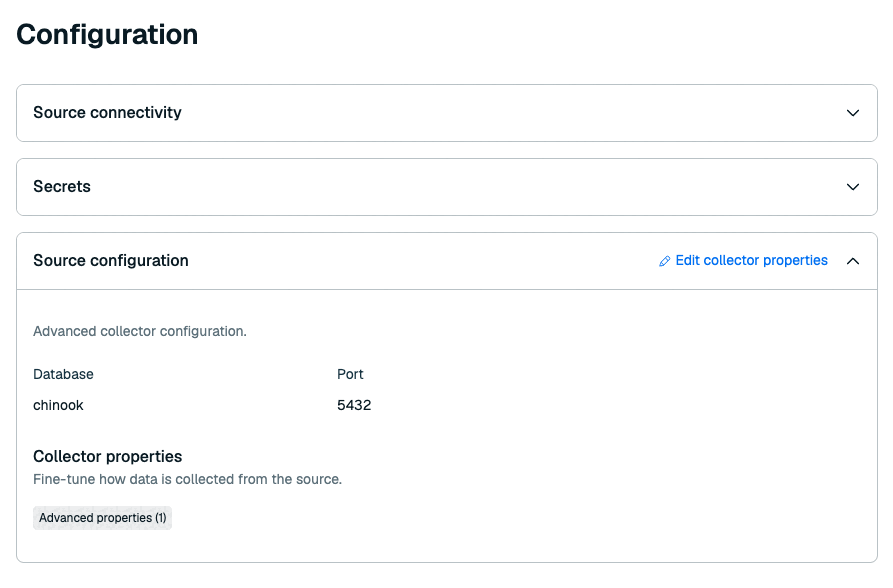
If you accidentally overwrite the access for your load balancer or secrets, you can find the required ARNs in the Source connectivity or Secrets section of this tab.
Edit collector properties
From the Configuration tab of your pipeline, select Edit collector properties to change your collector properties.
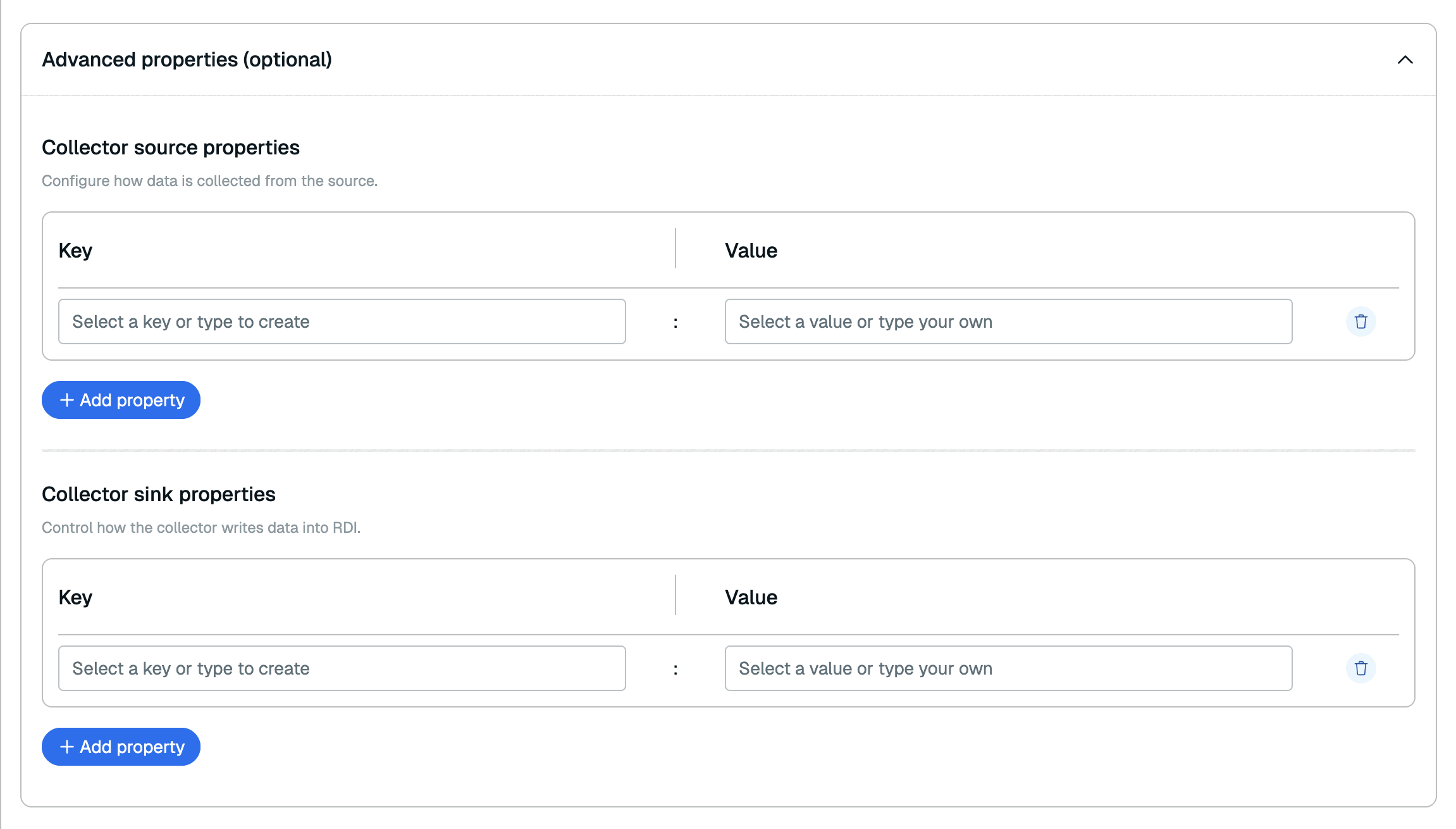
You can add collector source properties in the Collector source properties section and collector sink properties in the Collector sink properties section. See the RDI configuration file reference for all available collector source properties and collector sink properties. Select Save properties to save the collector properties.
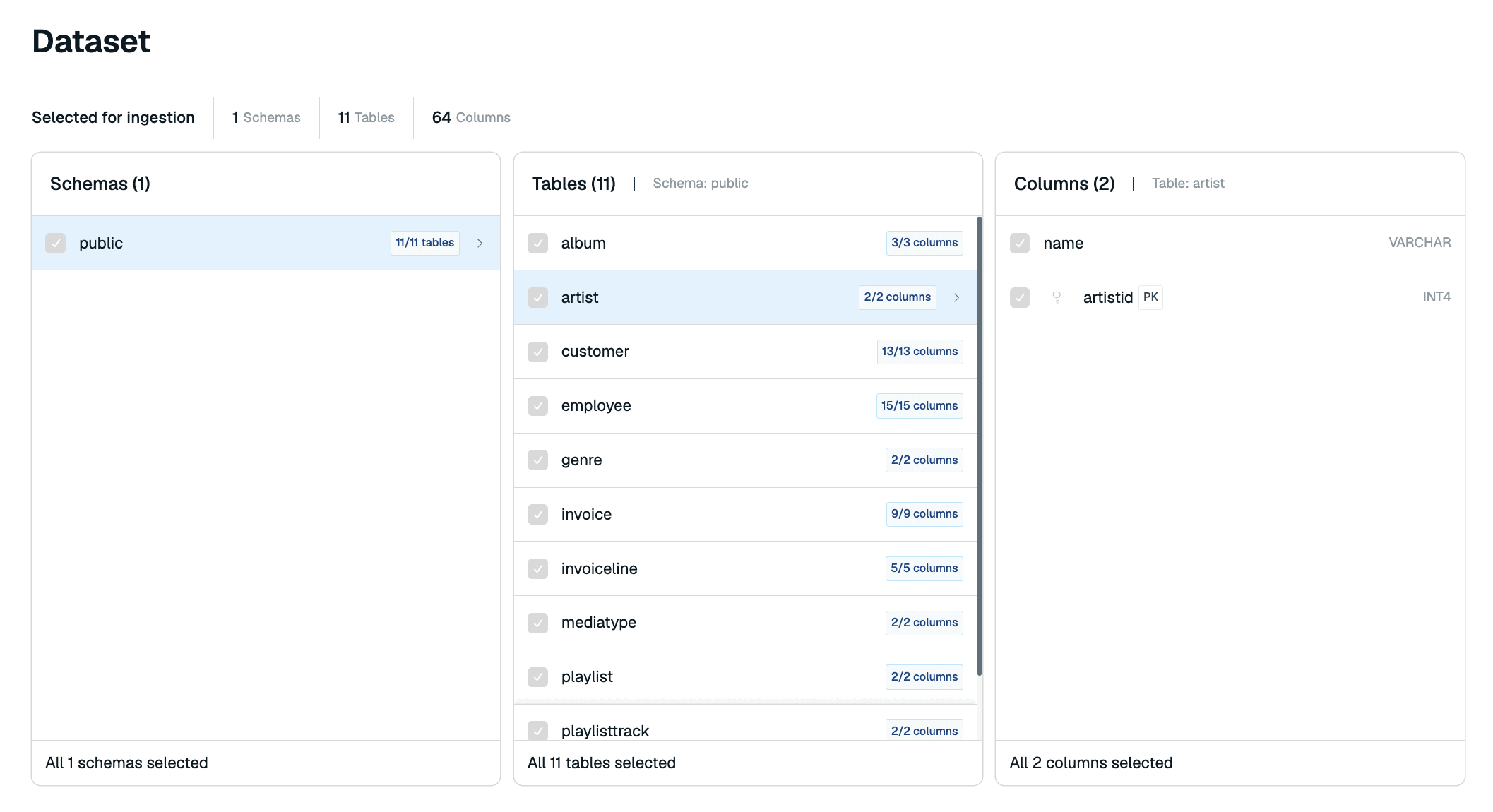
Dataset
The Dataset tab shows the data from your source database that is ingested into your target database.
Edit dataset
To change the dataset for your data pipeline:
-
From the Dataset tab of your pipeline, select Edit.

-
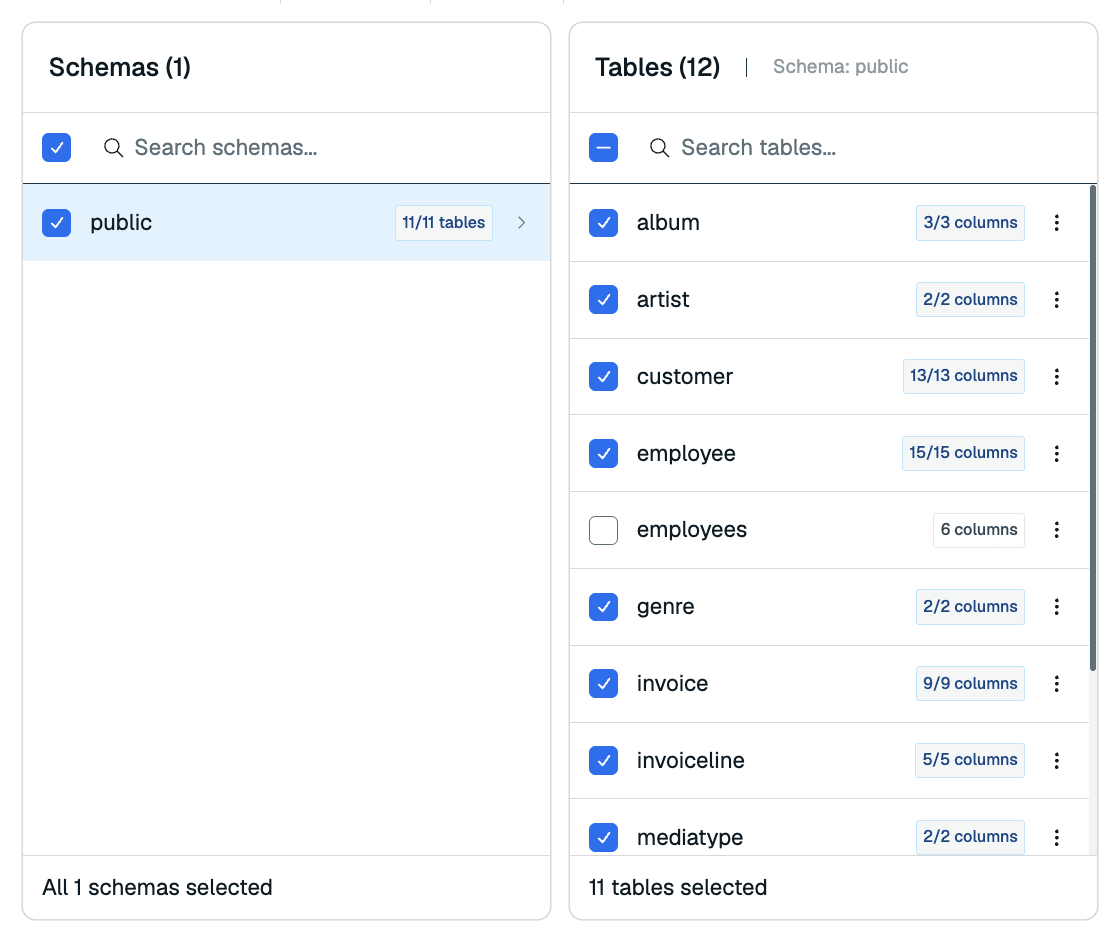
In the Schemas section, select the schema(s) you want to migrate to the target database from the list.
-
When you select a schema, you will see its tables in the Tables section. Redis Cloud will automatically select all tables for import. You can de-select any columns you do not wish to import to your Redis database.
-
Select a table to view its columns in the Columns section. You can de-select any columns you do not wish to import.
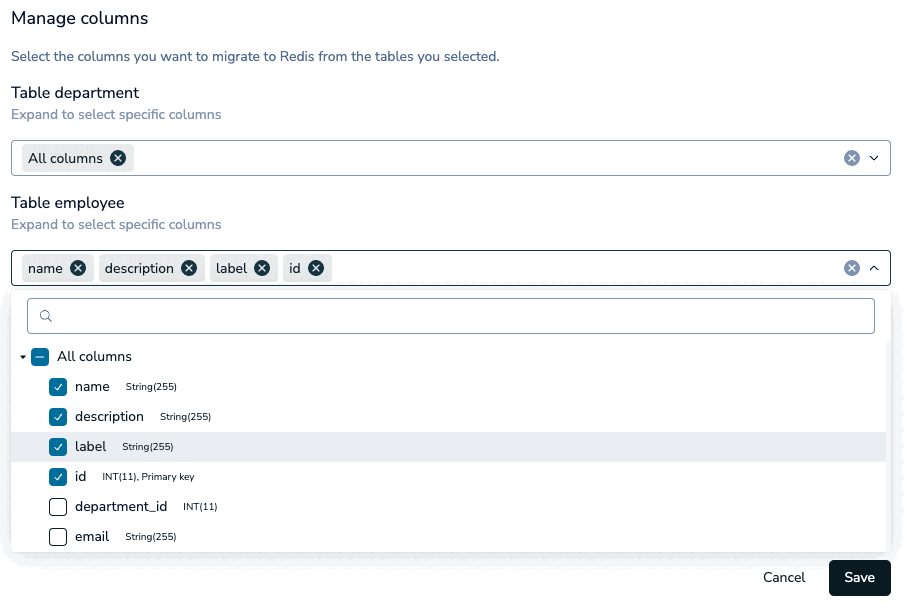
If any tables are missing a unique key, a warning will appear in the Data modeling section. Select Show affected to filter the Tables section to the tables without a unique key.
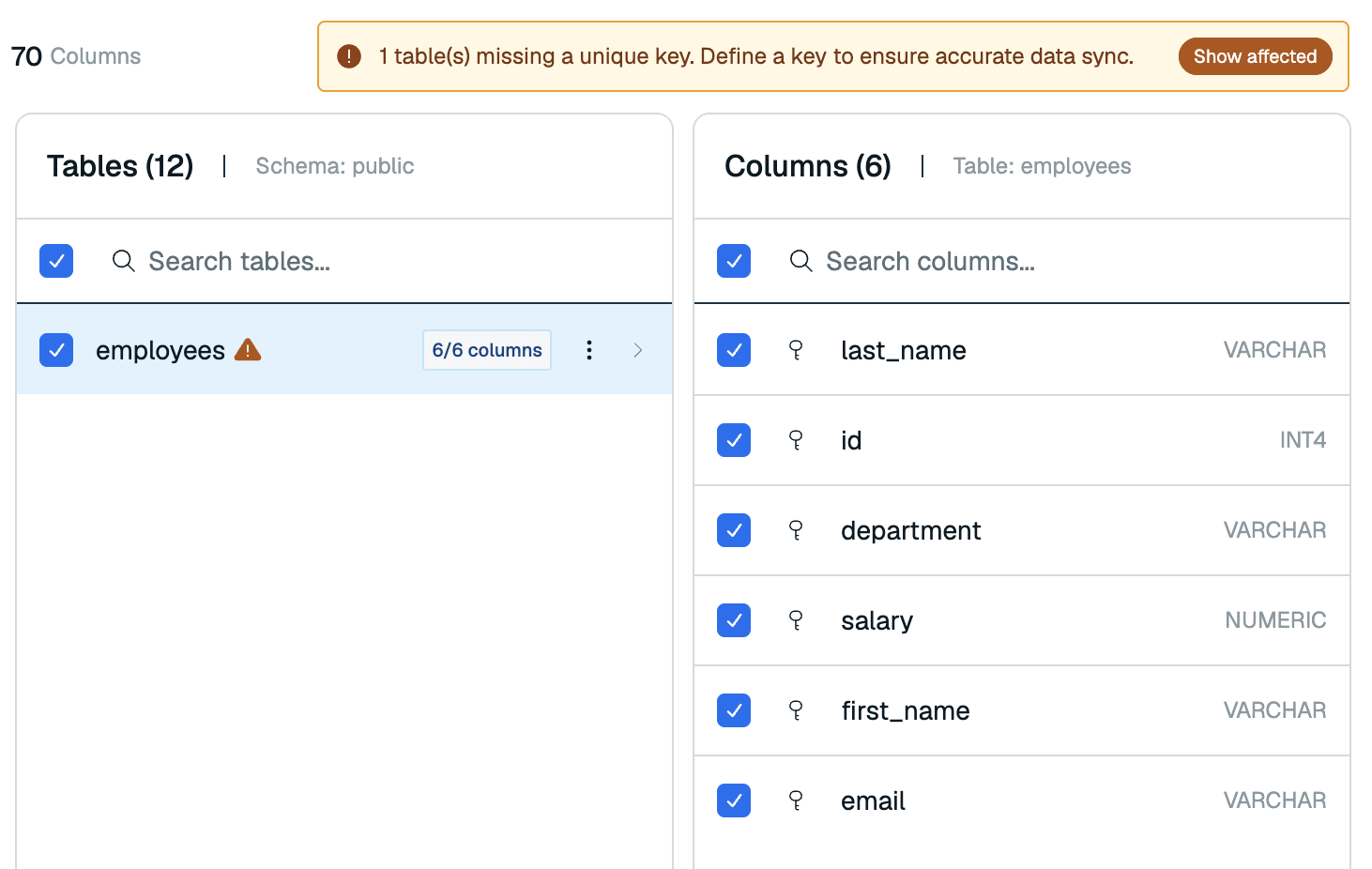
For these tables, select the key icon next to the column that defines a unique key.

-
Select Save changes to save your changes.
-
Redis Cloud will display a warning that the data pipeline will restart. Select Apply and restart to proceed.
At this point, the data pipeline will apply the changes. The data pipeline will re-ingest data from the source database to the target database. After this initial sync is complete, the data pipeline enters the change streaming phase, where changes are captured as they happen.
Transformations
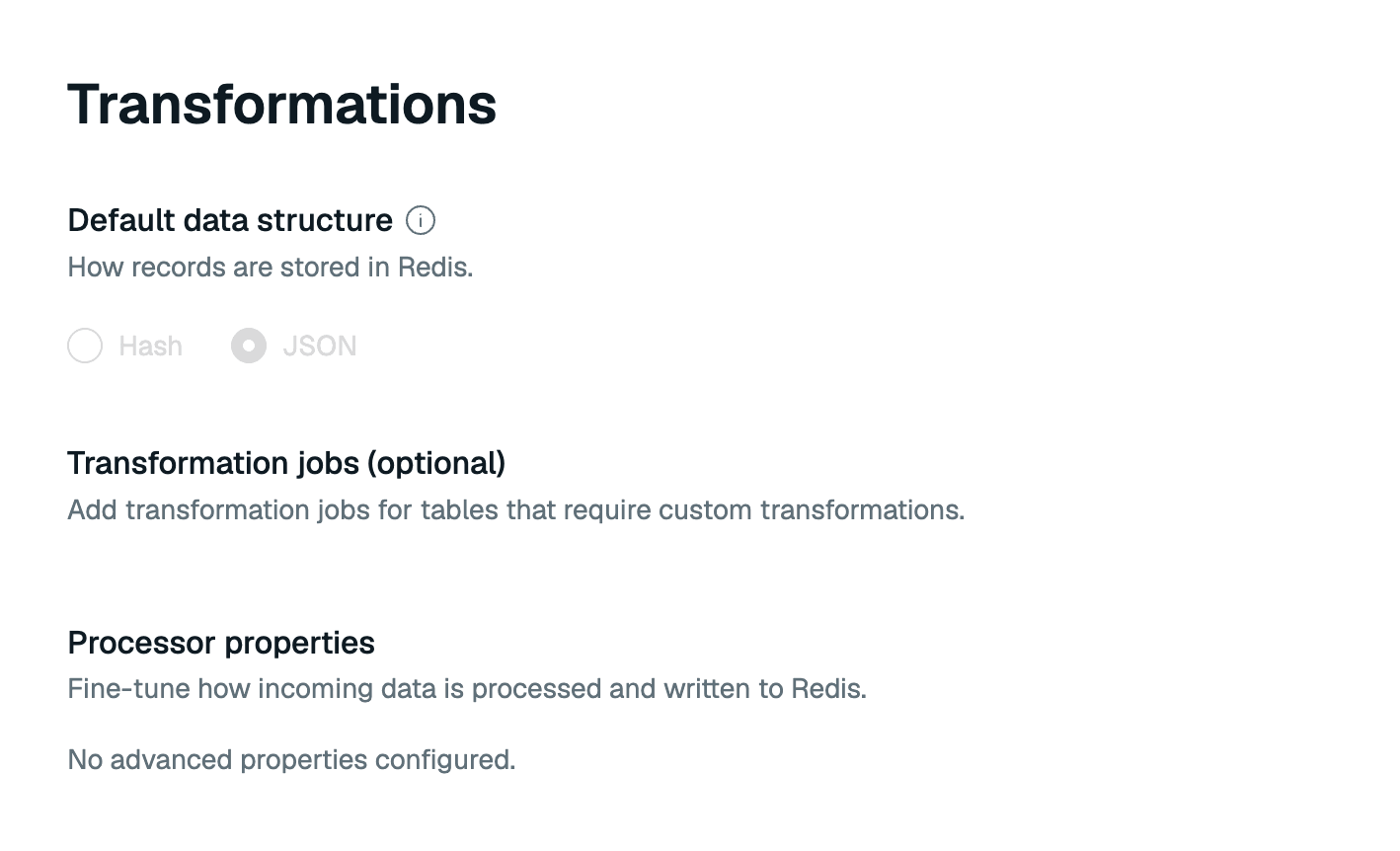
The Transformations tab shows the default data structure for records in your target database and any transformation jobs or processor properties you've set for your pipeline.
Edit transformations
To edit any of the information in the Transformations tab:
-
From the Transformations tab of your pipeline, select Edit.
-
Select how your records will be stored in Redis. You can choose Hash or JSON.
-
Under Transformation jobs, you can supply one or more transformation job files that specify how you want to transform the captured data before writing it to the target. Select Upload jobs to upload your job files. When you upload job files, Redis Cloud will validate the job files to check for errors.
-
Select Edit advanced properties to add any processor properties to control how the data is processed.
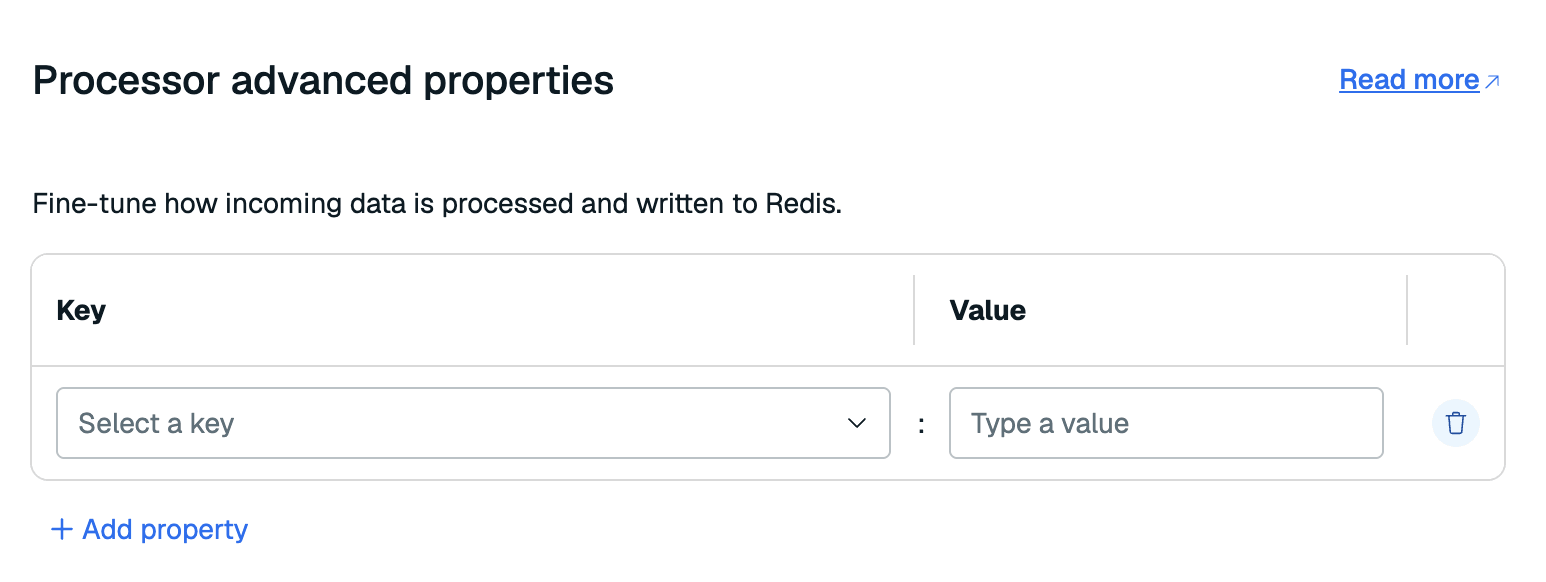
See the RDI configuration file reference for all available processor properties.
-
Select Save changes.
-
Redis Cloud will display a warning that the data pipeline will restart. Select Apply and restart to proceed.
At this point, the data pipeline will apply the changes. The data pipeline will re-ingest data from the source database to the target database. After this initial sync is complete, the data pipeline enters the change streaming phase, where changes are captured as they happen.
Reset data pipeline
Resetting the data pipeline creates a new baseline snapshot from the current state of your source database, and re-processes the data from the source database to the target Redis database. You may want to reset the pipeline if the source and target databases were disconnected or you made large changes to the data pipeline.
To reset the data pipeline and restart the ingest process:
-
From your pipeline, select More actions, and then Reset pipeline.
-
If you want to flush the database, check Flush target database.
-
Select Reset data pipeline.
At this point, the data pipeline will re-ingest data from the source database to your target Redis database.
Stop and restart data pipeline
To stop the data pipeline from synchronizing new data:
-
From your pipeline, select More actions, and then Stop pipeline.
-
Select Stop data pipeline to confirm.
Stopping the data pipeline will suspend data processing. To restart the pipeline from the Data pipeline tab, select More actions, and then Start pipeline.
Delete pipeline
To delete the data pipeline:
-
From your pipeline, select More actions, and then Delete pipeline.
-
Select Delete data pipeline to confirm.
Deleted data pipelines cannot be recovered. You may also want to delete your workspace.