Database Architecture
Database architecture refers to the design and structure of a database system. A database’s architecture dictates how an organization can store, access, manage, and secure data.
Choosing the wrong architecture inevitably leads to future issues and likely rebuilds. In this article, we’ll help you avoid that fate by guiding you through the basics, including what a database architecture is and what it’s composed of. We’ll also show you some of the practical elements of database architecture, including the importance of uptime and the role databases play in microservices.
What is database architecture?
Database architecture refers to how a company and its developers have set up and configured database systems to support their apps, websites, and infrastructures.
The database design dictates entirely different ways to store, secure, manage, and access data, making it an important decision to make early on – one that can have lasting effects on the functionality of your systems.
Four components primarily comprise a database architecture, but each component can vary depending on the database in question.
- Data model: The data model structures how data is organized, stored, and manipulated.
- Types/layers: Databases come in three types or layers – 1-tier, 2-tier, or 3-tier.
- Database Management System (DBMS): Software for managing the database.
- Schemas: Logical or physical ways of structuring the tables, fields, and relationships within a database.
In a complex system, companies often adopt multiple databases with different versions of these components and different data management methodologies.
For example, a company might use Snowflake as an analytical database for storing analytical data and supporting the writing of long, complex queries, Redis as an in-memory database for quick operations to support microservices, Kafka as a streaming database to support streaming data from location to location, and a range of production databases, such as MySQL, for application data storage.
Types of database architecture
When people are searching for the right database, they often get caught up in nuance and overcomplicate the questions they should ask.
You might know, for instance, that the right database needs to be able to structure data in a granular way to make for efficient retrieval or that the right database needs to support numerous ways to query it. But when you’re starting your search, it’s best to first rewind, look at the basic typology, and filter options from a high level down to lower, more nuanced levels.
Before you get into the weeds, determine whether the database architecture you need is relational or non-relational and whether it should be one-tier, two-tier, or three-tier.
Relational vs. non-relational databases
The choice between relational databases and non-relational databases (the latter more commonly known as NoSQL) comes down to a few major factors:
- Data structure: Relational databases tend to be better suited for structured data with well-defined relationships between entities, whereas NoSQL databases tend to be best for unstructured or complex data that requires flexible schema.
- Scalability: Relational databases tend to be better at vertical scaling, whereas NoSQL databases tend to be better at horizontal scaling.
- Data consistency: Relational databases offer strong consistency through ACID (Atomicity, Consistency, Isolation, Durability), whereas NoSQL databases offer eventual consistency through BASE (Basically Available, Soft state, Eventual consistency).
- Performance: Relational databases tend to have predictable performance levels for structured data use cases but slow down with write-heavy operations, whereas NoSQL databases tend to be a better fit for use cases that require high-performance read/write operations.
- Flexibility: Relational databases require a fixed schema, so changing the data structure can be difficult, whereas NoSQL databases are flexible or schema-less, making them a better fit for most companies with evolving data models.
The usage of each database type is particularly different because, in relational databases, you write SQL queries to relate data across and between tables; in NoSQL databases, there aren’t any tables, and the database doesn’t define or enforce a particular way of relating data.
1-Tier Architecture
In a one-tier architecture, all the components of the database—including the data itself, the user interface, and the application logic—reside on the same server.
Databases with single-tier architectures are rare in enterprise environments. These databases are more common for applications that only need to run on a small scale or by people who need to prioritize saving on costs.
2-Tier Architecture
In a 2-tier architecture (also known as client-server architecture), the database is split into two. The client (or, more often, multiple clients) directly connects to the server where the database resides, but the two are logically and physically separated.
Two-tier architectures are also not common in modern enterprise environments. In the past, these architectures were common when use cases were as simple as connecting a desktop application to a database hosted on an on-premises server. Now, however, long after the rise of the cloud, SaaS, and microservices, 2-tier architectures aren’t as popular.
3-Tier Architecture
In a 3-tier architecture, the database is split into three. Multiple clients connect to a backend, and the backend connects to the database. Three-tier architectures use a backend as an intermediary, which has numerous advantages, making it the most common type in enterprise environments.
For example, enterprises can limit access and make breaches less likely by ensuring the database only connects to a single backend. Similarly, by designing their databases with this level of separation as a first principle, enterprises can ensure developers can operate the layers independently, making scalability easier.
Why do keys matter in database architecture?
If you’re designing a database architecture, understanding keys – and the nuances of how they work within different architectures – is essential to building a database that supports your needs. In short, keys are how databases identify records within a table and create links between tables.
Keys matter for three primary reasons:
- Keys provide data integrity because they are unique. This ensures that each record in a table is unique and no two rows have the same primary key.
- Keys improve database performance by creating an index for the corresponding columns. With these indexes, the database can efficiently locate rows without scanning the entire table, making queries faster.
- Keys organize database structure by providing ways for tables to relate to other tables. This allows users to rely on more efficient joins and better query planning. Keys also enable hierarchical data organization, which allows databases to be organized into clear parent-child relationships.
Keys come in several different types, including primary keys, which uniquely identify each record; foreign keys, which create links between tables; and composite keys, which combine multiple columns in a single table.
Why is uptime important in a database system?
Today, users expect levels of uptime that can only be described with numerous decimal points (“high nines” or 99.999% of uptime). Even though software has become much more complex and interdependent, companies that want to maintain user trust must build uptime and availability considerations into their earliest database decisions.
The CAP theorem and its implications for uptime
You won’t be searching for database options for long before you hear about the CAP theorem. CAP is an acronym for Consistency, Availability, and Partition tolerance. The theory is simple on the surface but complex once you dig into the details.
In short, the CAP theorem is a classic “three options, but you can only pick two” problem: A distributed system cannot simultaneously be consistent, available, and partition tolerant.
Here, consistency means that read operations that start after write operations must return that value; availability means every request received by a node in the system must result in a response; and partition tolerance means the network will be allowed to lose messages sent from one node to another.
Eric Brewer, now vice-president of infrastructure at Google and a professor emeritus of computer science at the University of California, Berkeley, formulated the original theorem and presented it in 2000. Even decades later, the theorem remains an important anchor point for people thinking through their database needs.
Each choice among the three poses tradeoffs, and companies building databases need to embrace the harsh reality that having all three is impossible.
The costs of downtime
For most companies, availability – the lack of which can result in downtime – stands out as the part of the theorem that’s too costly to deprioritize.
Splunk research shows, for example, that the global 2000 companies lose $400B annually to downtime and service degradation. Major companies, such as Meta and Amazon, which lost $100 million in revenue and $34 million in sales during downtime events, respectively, have also faced this issue.
Businesses invest a lot of effort and money into scale, but if their infrastructure and the databases that support them can’t handle that scale, increased customer reach can turn into increased customer disappointment. Early-stage companies often have more flexibility, but enterprises, which have become essential tools for so many businesses and users, need to prioritize availability to maintain the trust their customers depend on.
How databases maintain uptime
The essential puzzle of database availability is figuring out how to ensure databases have enough resources available to complete requests and enough resources at any one time to quickly complete a new request.
As new users and requests pour in, a database has two options: Scale vertically or horizontally. Scaling vertically means, in short, that enterprises make their servers bigger or faster. Scaling horizontally means enterprises distribute the database in question across multiple, smaller servers.
There is no “best way” here because each direction poses tradeoffs. There are nuances, but Justin Gage, author of the Technically newsletter, summarizes the tradeoffs like this: “Scaling vertically is easy, but scaling horizontally is efficient.”
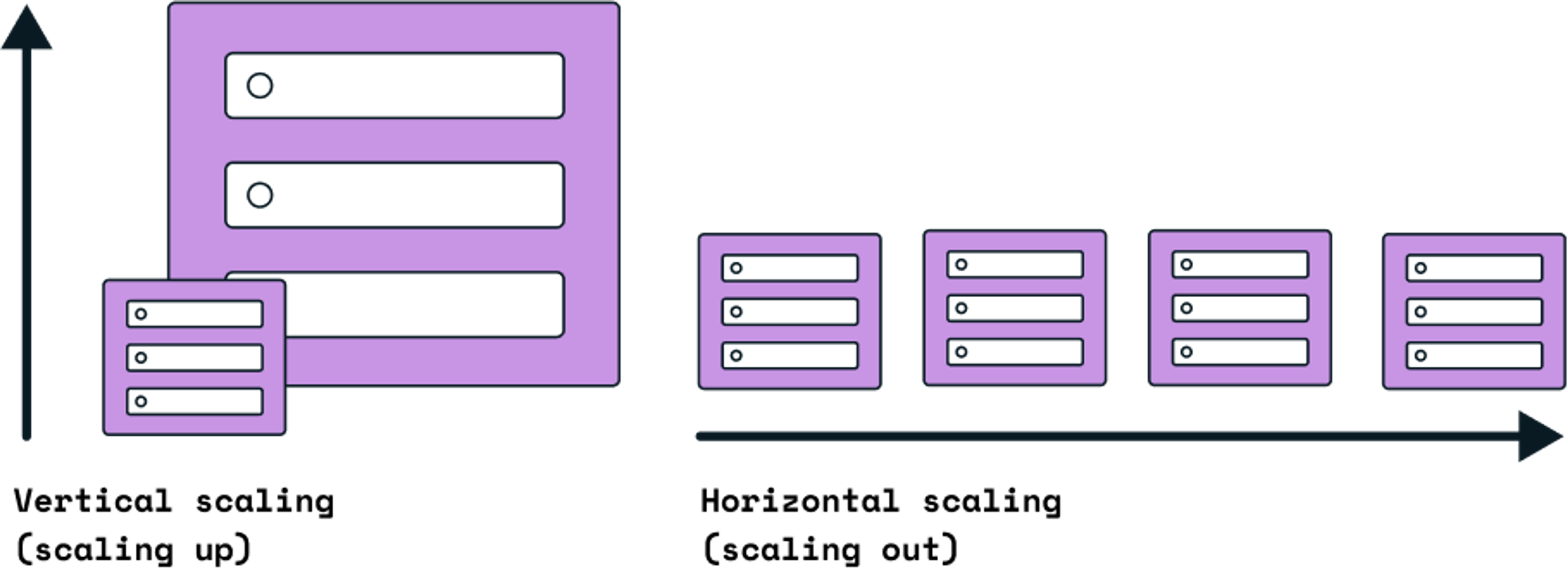
(Source)
Swapping from one server to a bigger, faster one is relatively easy, but you’ll also inevitably hit limits. Adding new servers allows you to get around those limits, but every additional server adds complexity and coordination costs. If you’re scaling a database horizontally, patching, traffic distribution, and server synchronization, for example, all become thorny questions.
With very large databases, scalability becomes even more difficult. Redis Cloud uses clustering to distribute database data to different cloud instances to address this. If data exceeds the power of a single server’s RAM, performance will degrade, but with clustering, numerous database shards (partitions in separate database server instances) spread the load.
Redis addresses the same challenge with replication, which adds a “leader-follower” pattern to Redis instances. In this pattern, replicated Redis instances are always exact copies of the leader instances, ensuring that an exact copy will be ready no matter what happens to the leader.
How the right database architecture supports API scalability
APIs (or Application Programming Interfaces) run the modern Internet.
APIs can be small, such as the internal protocols connecting a company’s components in a microservices environment or large, company-defining protocols. Stripe and Twilio, for example, offer their primary products via API (payment processing and communication services, respectively), allowing users to write a few lines of code, call the API, and access world-class functionality.
The very functionality that makes APIs compelling, however, can make them fragile if they can’t scale.
The right database and the right database architecture can make all the difference in enabling the scalability APIs need. By looking at what Redis offers API developers as an in-memory database, you can see how important database architecture decisions can become.
Unscalable APIs are risky
Scalability is a requirement whether your end-user is a non-technical consumer reliant on the data an API returns or a professional user depending on internal APIs to ensure their systems remain performant.
- Performance degradation: If APIs can’t scale well, an enterprise’s systems will have increased latency and more frequent timeouts and failures as the number of users and requests grows.
- Downtime: If APIs can’t scale well, surges in traffic—during peak hours, special events, holidays, and more—can crash the API. Because APIs are often single points of failure, a crashed API can often mean a nonfunctional feature or system.
- Lost revenue and increased operational costs: Enterprises can lose money from both ends if APIs can’t scale well. While services are down, they can’t generate revenue, and as services keep failing, enterprises will need to continuously redeploy developers to fix them.
The three risks above combine to create the biggest risk of all: a bad user experience. Users expect consistent service, and latency and downtime can not only lead to frustration but to abandonment of the service altogether.
Even for professional users like developers, who might not have the same ability to just switch applications, poor performance can lead to a bad developer experience, which has consequences far beyond sheer annoyance. Recent Atlassian research shows, for example, that 97% of developers lose significant time to inefficiencies.
As a result, a majority of developers think about leaving the companies they work for due to the poor developer experience.
How Redis reduces the load
Redis is an in-memory database that enterprises can use to reduce the load on a primary database. With Redis, enterprises can cache session data so that requests don’t get routed to the production database, which is one of the most common ways production databases can become overwhelmed.
This ability is especially useful in a microservices context. Microservices architectures, which split monolithic applications into a series of services connected by API, depend on the scalability of those APIs. Without reliable APIs, a formerly functional web of microservices can become a line of falling dominos. With Redis, teams can cache common API calls and speed the entire system up – improving scalability without sacrificing performance.
Why do so many data systems use Redis?
Redis is a popular choice among companies building data systems because it’s fast at retrieving values, easy to use, and flexible across a variety of common data models.
Unlike other databases, which tend to store data on disk, Redis stores data in RAM (or in memory). As a result, writes Animesh Gaitonde, a tech lead at Amazon, “Fetching the data from memory is orders of magnitude faster than getting it from the disk.” Instead of using time-consuming I/O calls, he continues, “Redis is able to bypass the I/O call and serve the data directly from the memory.”
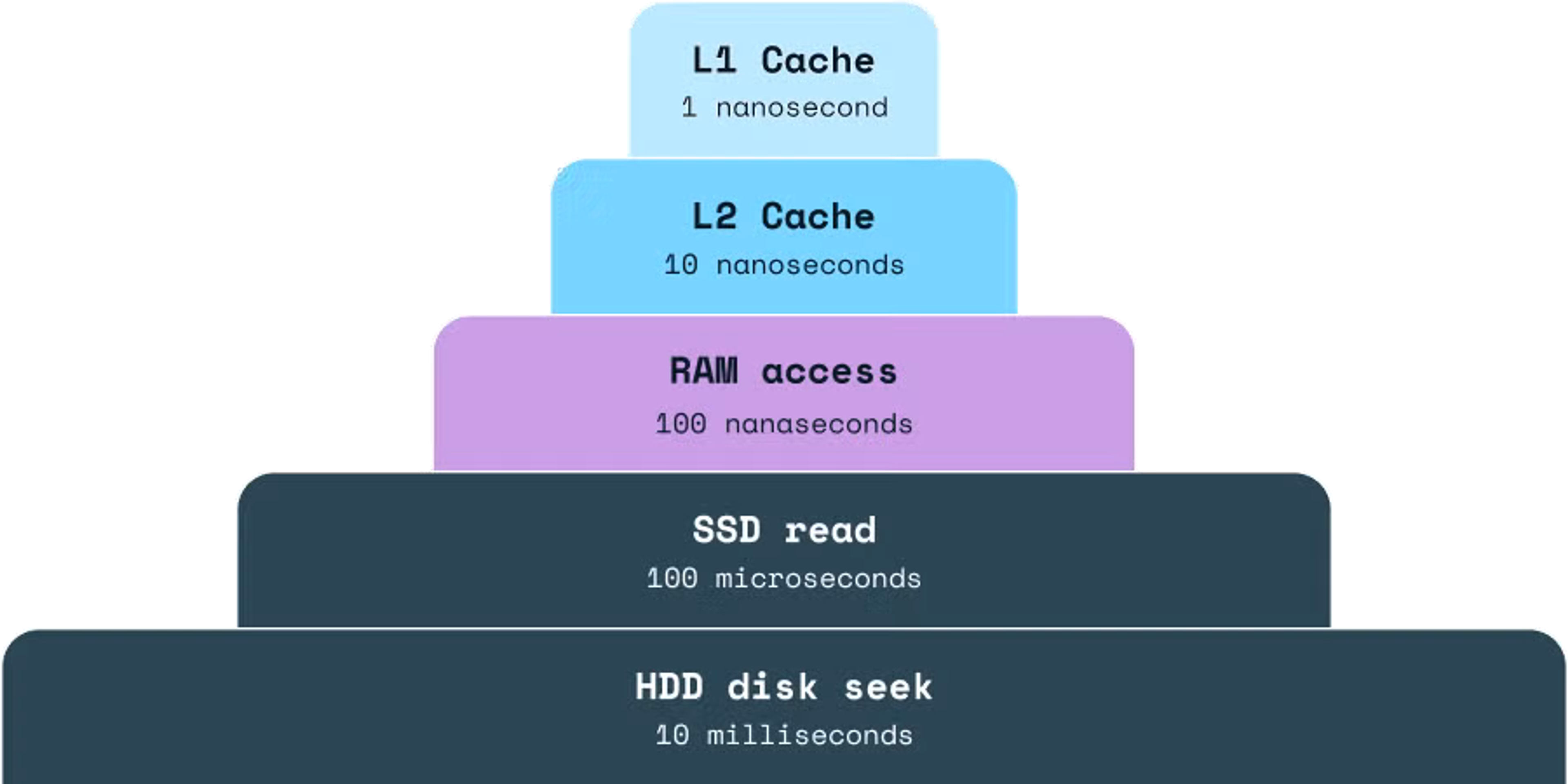
(Source)
This speed is especially useful when applications need to store and query extensive user session data—another reason so many data systems use Redis. Applications frequently use session stores to track user identity, shopping cart items, personalization information, and more. Redis Enterprise provides session stores that support the scale, speed, and durability necessary to support the needs of applications that depend on user session data.
Many technology options require a tradeoff between speed and flexibility, requiring users to choose between a solution that works slowly in numerous contexts or a solution that works quickly in a single context. However, Redis, supported by decades of open-source development since its beginning in 2009, supports a wide variety of data models, including key:value, hash, JSON, sets, sorted sets, strings, and streaming data.
The best way to test a Redis database’s capabilities is to set up and start using one. Redis provides numerous quick-start guides to help you get started, whether you want to build a data structure store, document database, or vector database.
Once you have a Redis account, you can connect to a Redis server in a few ways, such as by connecting to a Redis server that runs on localhost (-h 127.0.0.1) and listens on the default port (-p 6379).

You can then use the same data types you use in your local environment with Redis. Redis strings store sequences of bytes (such as text and binary arrays), and you can easily get a string value.

As covered earlier, each item within Redis has a unique key, and each key lives in a Redis keyspace. In the example below, you can scan your Redis keyspace with a simple SCAN command.

The first building blocks are simple, but the database systems you can build with Redis are complex enough to handle a wide variety of use cases. To learn more, book a meeting with a Redis expert.
The right architecture supports you, and the wrong architecture slows you down
When you work or live in a well-designed building, you don’t think about the architecture too much. Even when you’re relishing the way a courtyard in a well-built apartment complex lets in the outside air or enjoying how a well-designed office building facilitates collaboration, you likely won’t pause to appreciate the architectural design supporting those experiences.
And for good reason: Architecture, designed well, fades into the background and allows you to do what you need to do. You’re more likely to think about architecture when it causes issues – when it announces its bad design by getting in your way.
Database architecture works the same way. The right database architecture reduces friction, so you can focus on product development and delivery. All the while, it gives you the support necessary for growth and experimentation, ensuring you can run your core business and think about growth, too.
The wrong database architecture, in contrast, can impose restrictive limits – often earlier than you expect – and make it difficult to build up product development momentum. Eventually, friction can predominate, and you might need to replace the database entirely, which can be expensive.
Instead, weigh your options carefully from the outset, consider your use cases, and pick the database that works for you today and promises to scale with you tomorrow.