Blog
How To Use Google Cloud Dataflow to Ingest Data From Google Cloud Pub/Sub to Redis Enterprise

Google Cloud Dataflow provides a serverless architecture that you can use to shard and process very large batch datasets or high-volume live streams of data in parallel. This short tutorial shows you how to go about it.
Many companies capitalize on Google Cloud Platform (GCP) for their data processing needs. Every day, millions of new data points, if not billions, are generated in a variety of formats at the edge or in the cloud. Processing this massive amount of data requires a scalable platform.
Google Cloud Dataflow is a fully-managed service for transforming and enriching data as a stream (in real time) or in batch mode (for historical uses), using Java and Python APIs with the Apache Beam software development kit. Dataflow provides a serverless architecture that you can use to shard and process very large batch datasets or high-volume live streams of data, and to do so in parallel.
A Dataflow template is an Apache Beam pipeline written in Java or Python. Dataflow templates allow you to execute pre-built pipelines while specifying your own data, environment, or parameters. You can select a Google-provided template or customize your own. The Google Cloud Dataflow pre-built templates enable you to stream or bulk-load data from one source to another such as Pub/Sub, Cloud Storage, Spanner, SQL, BigTable, or BigQuery with an easy-to-use interface accessible via the Google Cloud console.
Redis Enterprise is used extensively across the Google Cloud customer base for many purposes, including real-time transactions, chat/messaging, gaming leaderboards, healthcare claims processing, real-time inventory, geospatial applications, and media streaming. As an in-memory database, Redis Enterprise consistently delivers millions of operations per second with sub-millisecond latency. Thus, Redis Enterprise perfectly complements many of the native Google Cloud managed services that drive real-time user experiences.
To give you a practical introduction, we introduce our custom template built for Google Cloud Dataflow to ingest data through Google Cloud Pub/Sub to a Redis Enterprise database. The template is a streaming pipeline that reads messages from a Pub/Sub subscription into a Redis Enterprise database as key-value strings. Support for other data types such as Lists, Hashes, Sets, and Sorted Sets will be built over time by Redis and Google experts, and perhaps by open-source community contributors.
Our motivation: Let’s make this easy
We want developers to have a great experience with Google Cloud Dataflow and Redis Enterprise.
Using a pre-built template offers many benefits:
- You can run pipelines without the development environment and associated dependencies that are common with non-templated deployment. This is useful for scheduling recurring batch jobs.
- Runtime parameters allow you to customize the way a pipeline runs.
- Templates separate pipeline construction (performed by developers) from running the pipeline (which may be the responsibility of other personnel). Hence, there is no need to recompile the code every time the pipeline is run.
- Non-technical users can run templates using the Google Cloud Console, Google Cloud command-line interface, or the REST API.
- You can extend templates with user-defined functions.
How to use the Dataflow template: step-by-step
It helps to see how the process works, so here we walk you through the high-level workflow to show you how to configure a Dataflow pipeline using our custom template.
In this example, we process a message arriving at a pre-defined Pub/Sub subscription and insert the message as a key-value pair into a Redis Enterprise database.
From the Dataflow GCP console, enter a pipeline name and regional endpoint, and then select Custom Template. Enter gs://redis-field-engineering/redis-field-engineering/pubsub-to-redis/flex/Cloud_PubSub_to_Redis for the template path.
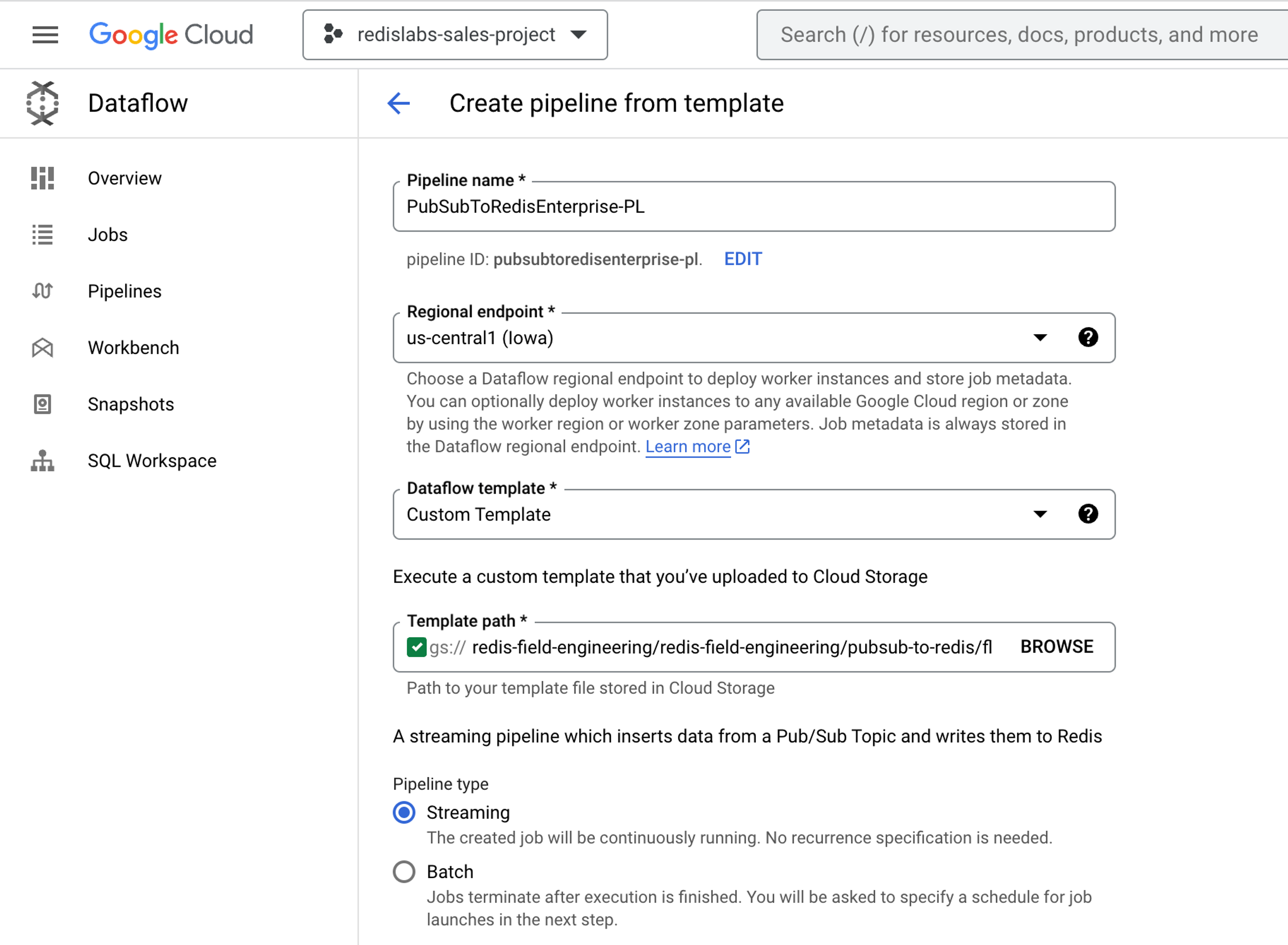
Next, enter the Pub/Sub subscription name that holds the incoming messages. Add the Redis Enterprise database parameters (e.g., Redis database host, Redis database port, and the Redis default user authentication password).
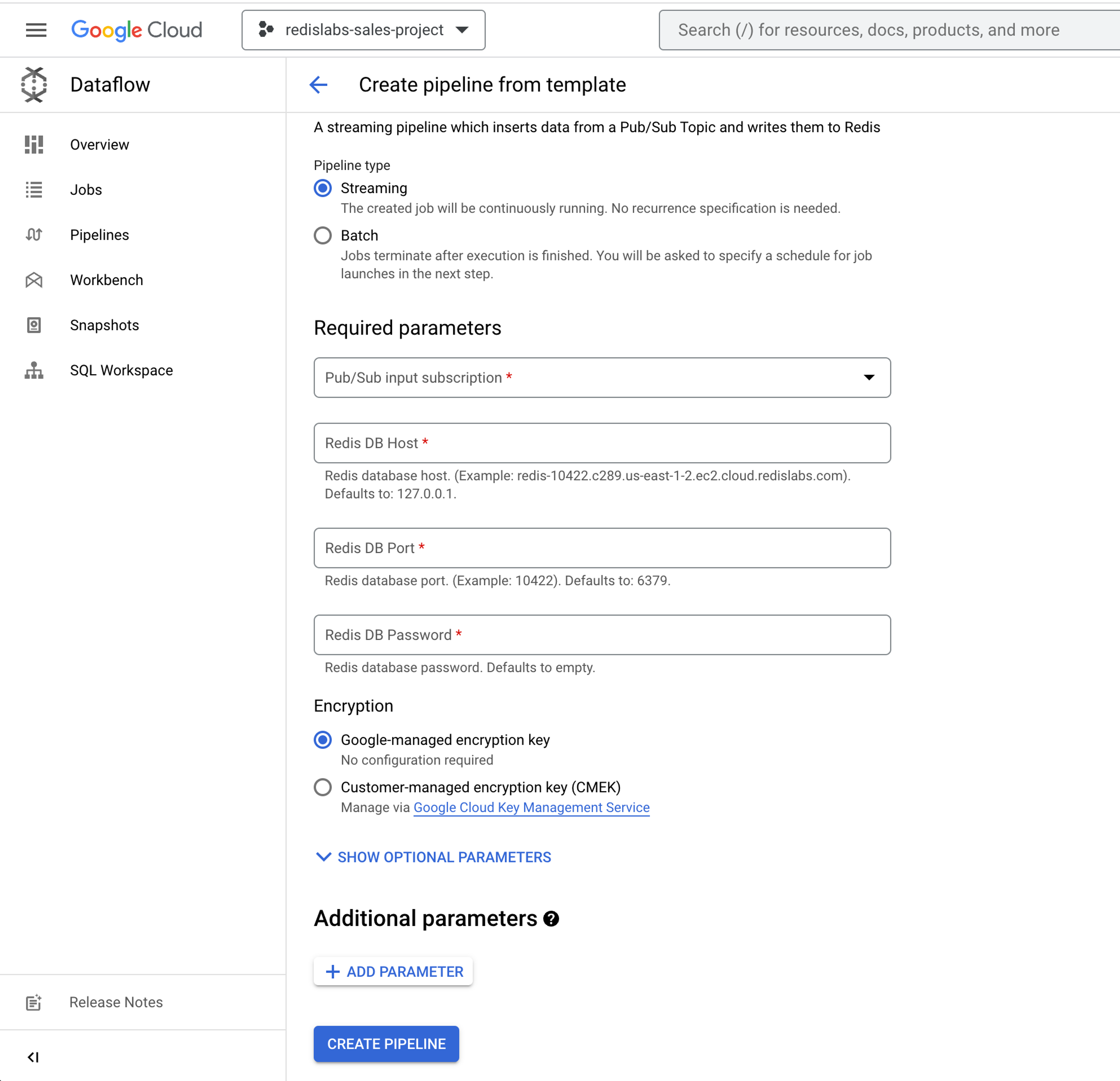
Choose Create Pipeline. The pipeline is now set to receive incoming messages. You may cheer, if you like to celebrate small victories.
You’re ready to publish a sample message to the Pub/Sub topic. Type in some sample data, and choose Publish.
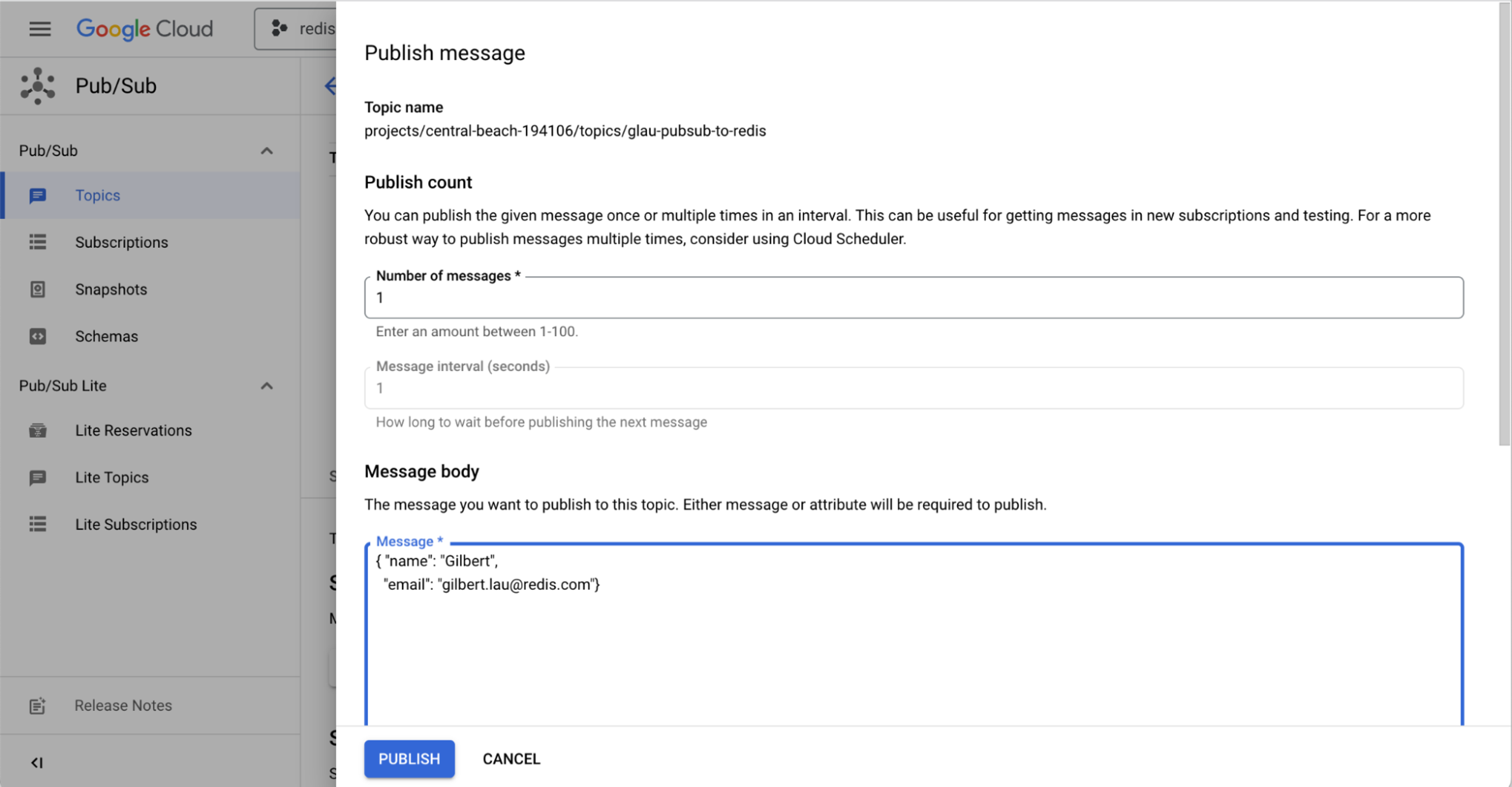
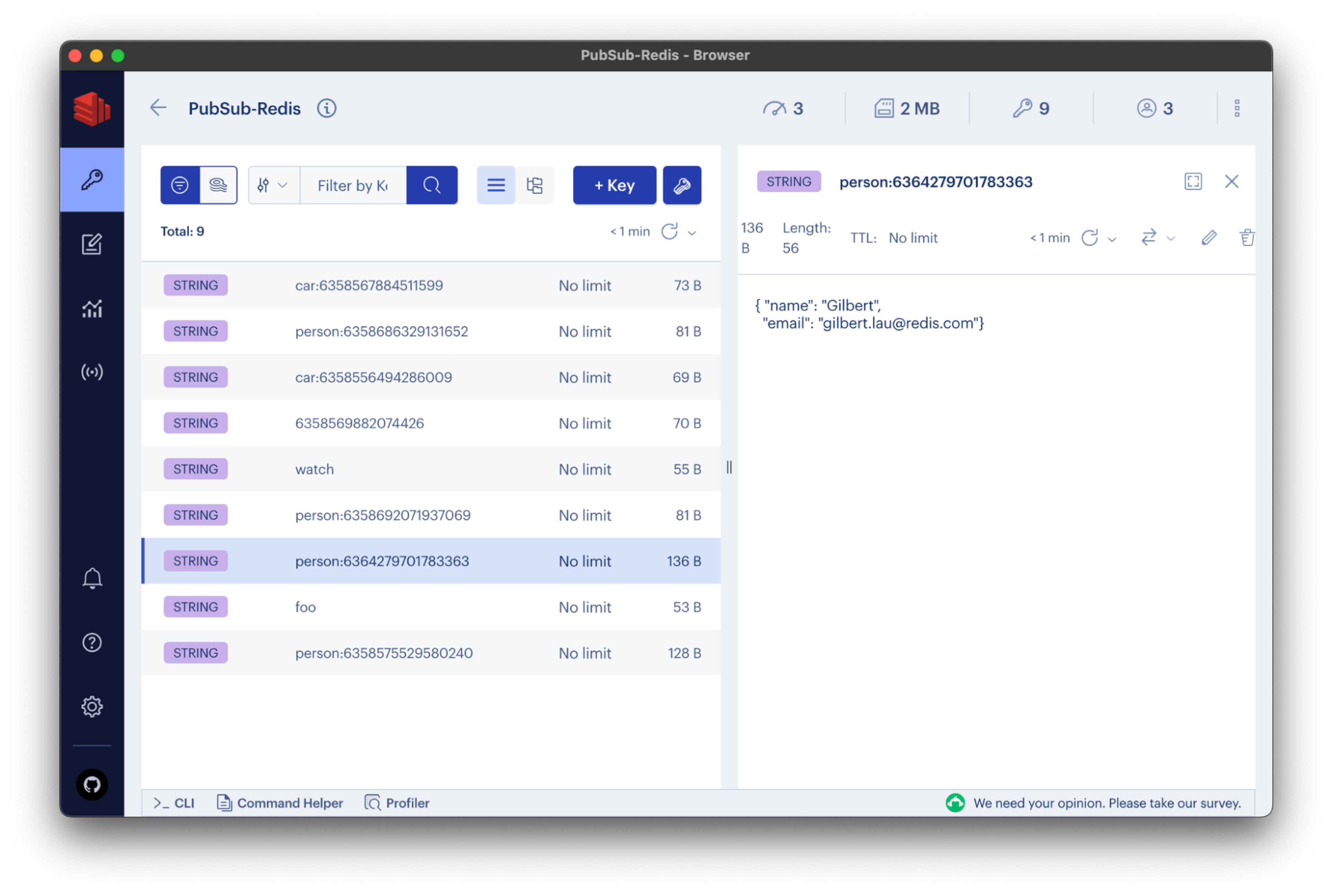
Confirm that your sample data was published, if only for your own reassurance. To verify that the data was inserted into the Redis Enterprise database, you can use Redis Insight, a Redis GUI that supports command-line interaction in its desktop client.
That’s just the start
The support model for this custom Dataflow template currently uses a community-based support mechanism. This means it is supported by the open source community on its GitHub repo.
You are welcome to check out the open-source code and provide your feedback. We encourage you to add new features. Fork our GitHub repo and create a pull request when you are ready to contribute. Your support will make this project far more successful and sustainable.
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.